

2D Transformer 可以帮助3D表示学习吗?
描述
与2D视觉和NLP相比,基于基础的视觉计算在3D社区中发展滞后。提出以下问题:是什么使得3D表示学习比2D视觉或NLP更具挑战性?
深度学习的成功在很大程度上依赖于具有全面标签的大规模数据,在获取3D数据方面比2D图像或自然语言更昂贵且耗时。这促使我们有可能利用用于不同模态知识转移的以3D数据为基础的预训练模型作为教师。
本文以统一的知识蒸馏方式重新考虑了掩码建模,并且展示了基于2D图像或自然语言预训练的基础
Transformer模型如何通过训练作为跨模态教师的自编码器(ACT)来帮助无监督学习的3D表示学习。本文首次证明了预训练的基础
Transformer可以帮助3D表示学习,而无需访问任何2D、语言数据或3D下游标注。
笔者个人体会
这篇论文的动机是解决3D数据表示学习中存在的挑战,即3D数据与2D图像或语言具有不同的结构,使得在细粒度知识的关联方面存在困难。作者希望通过自监督学习的方式,将来自图像领域的丰富知识应用于3D数据的表示学习中,从而提高3D任务的性能。作者提出一种自监督学习框架,用于跨模态的知识传递和特征蒸馏,以改善3D数据的表示学习和下游任务性能。
核心创新点是框架中的ACT(Autoencoding Cross-Transformers),它将预训练的基础Transformer模型转化为跨模态的3D教师模型,并通过自编码和掩码建模将教师模型的特征蒸馏到3D Transformer学生模型中。
作者通过以下方式设计和实现ACT框架:
-
首先,使用3D自编码器将预训练的基础
Transformer转化为3D教师模型。这个自编码器通过自监督训练从3D数据中学习特征表示,并生成语义丰富的潜在特征。 -
接着,设计了掩码建模方法,其中教师模型的潜在特征被用作3D
Transformer学生模型的掩码建模目标。学生模型通过优化掩码建模任务来学习表示,以捕捉3D数据中的重要特征。 -
使用预训练的2D图像
Transformer作为教师模型,因为它们在2D图像领域表现出色,并且作者认为它们可以学习迁移的3D特征。
ACT框架包括以下主要部分:
-
预训练的2D图像或语言Transformer:作为基础
Transformer模型,具有丰富的特征表示能力。作者选择了先进的2DTransformer模型作为基础模型,例如VisionTransformers(ViTs) 或者语言模型(如BERT)。训练:使用大规模的2D图像或语言数据集进行预训练,通过自监督学习任务(如自编码器或掩码建模)来学习模型的特征表示能力。
-
3D自动编码器:通过自监督学习,将2D图像或语言Transformer调整为3D自动编码器,用于学习3D几何特征。作者将预训练的2D图像或语言
Transformer模型转换为3D自动编码器。通过将2D模型的参数复制到3D模型中,并添加适当的层或模块来处理3D数据。使用3D数据集进行自监督学习,例如预测点云数据的遮挡部分、点云重建或其他3D任务。通过自监督学习任务,3D自动编码器可以学习到3D数据的几何特征。
-
跨模态教师模型:将预训练的3D自动编码器作为跨模态教师模型,通过掩码建模的方式将潜在特征传递给3D
Transformer学生模型。特征传递:通过掩码建模的方式,将3D自动编码器的潜在特征传递给3D
Transformer学生模型。教师模型生成的潜在特征被用作学生模型的蒸馏目标,以引导学生模型学习更好的3D表示。 -
3D Transformer学生模型:接收来自教师模型的潜在特征,并用于学习3D数据的表示。
特征蒸馏:学生模型通过特征蒸馏的方式,利用教师模型的潜在特征作为监督信号,从而学习到更准确和具有丰富语义的3D表示。
这种设计和实现带来了多个好处:
- ACT框架能够实现跨模态的知识传递,将来自图像领域的知识应用于3D数据中的表示学习,提高了3D任务的性能。
-
通过使用预训练的2D图像
Transformer作为教师模型,ACT能够利用图像领域已有的丰富特征表示,提供更有语义的特征编码。 - 自编码和掩码建模任务使得学生模型能够通过无监督学习捕捉3D数据中的重要特征,从而更好地泛化到不同的下游任务。
总的来说,ACT框架的核心创新在于将自监督学习和特征蒸馏方法应用于3D数据中,实现了知识传递和表示学习的改进,为跨模态学习和深度学习模型的发展提供了新的思路和方法。
摘要
深度学习的成功在很大程度上依赖于具有全面标签的大规模数据,在获取3D数据方面比2D图像或自然语言更昂贵且耗时。这促使我们有可能利用用于不同模态知识转移的以3D数据为基础的预训练模型作为教师。
本文以统一的知识蒸馏方式重新考虑了掩码建模,并且展示了基于2D图像或自然语言预训练的基础Transformer模型如何通过训练作为跨模态教师的自编码器(ACT)来帮助无监督学习的3D表示学习。
-
预训练的
Transformer模型通过使用离散变分自编码的自监督来作为跨模态的3D教师进行转移,在此过程中,Transformer模型被冻结并进行提示调整,以实现更好的知识传承。 -
由3D教师编码的潜在特征被用作掩码点建模的目标,其中暗知识被提炼到作为基础几何理解的3D
Transformer学生中。
预训练的ACT 3D学习者在各种下游基准测试中实现了最先进的泛化能力,例如在ScanObjectNN上的 %整体准确率。
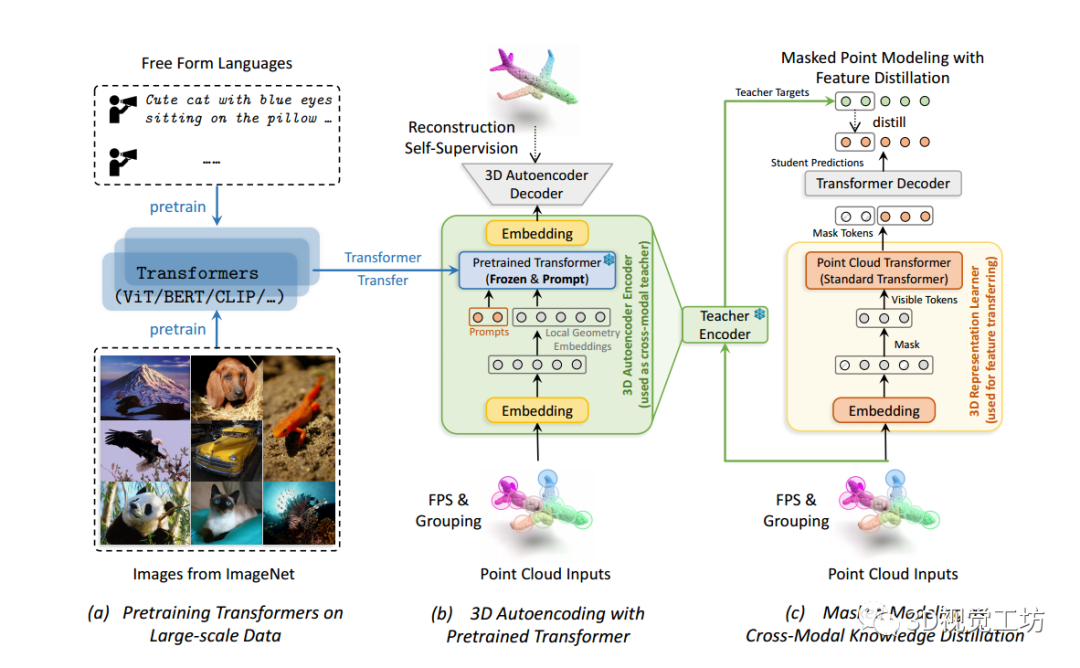
图1
ACT框架的概述。
- (a)
ACT利用在大规模数据上预训练的Transformer模型,例如使用2D图像预训练的ViT或使用语言预训练的BERT。- (b)
ACT的第一阶段(第4.1节),预训练的Transformer模型通过带提示的自监督3D自编码进行微调。- (c)
ACT的第二阶段(第4.2节),3D自编码器编码器被用作跨模态教师,将潜在特征编码为掩码点建模目标,用于3DTransformer学生的表示学习。
一、引言
近年来,数据驱动的深度学习在人工智能系统中得到广泛应用。计算硬件的进步极大地推动了机器智能的发展,并促进了一种新兴的范式,即基于广泛数据训练的模型的知识转移。
- 自然语言处理 (NLP) 取得了巨大的成功,其中的模型旨在通过对极大规模数据进行自监督学习来获取通用表示。
-
自从
Transformer在视觉领域取得成功后,人们已经做出了许多努力,将这种趋势从NLP领域扩展到基于2D视觉理解的基础模型中。
与2D视觉和NLP相比,基于基础的视觉计算在3D社区中发展滞后。提出以下问题:是什么使得3D表示学习比2D视觉或NLP更具挑战性?
从以下三个角度提供一些分析性答案:
i. 架构不统一。先驱性架构如PointNet只能对3D坐标进行编码,而无法应用于在NLP和2D视觉中取得成功的掩码去噪自编码(DAE)。然而,Transformer架构现在已经弥补了这种架构上的差距,实现了跨所有模态格式的统一表示,并为扩展3D中的DAE带来了巨大潜力。
ii. 数据稀缺。与图像和自由形式语言相比,收集和标注3D或4D数据更加困难,通常需要更昂贵且密集的工作。此外,考虑到数据规模,3D数据严重匮乏。这促使了跨模态知识转移的使用。最近的研究要么与其他模态一起进行联合训练以实现更有效的对比,要么直接对在图像数据上预训练的2D Transformers进行微调。
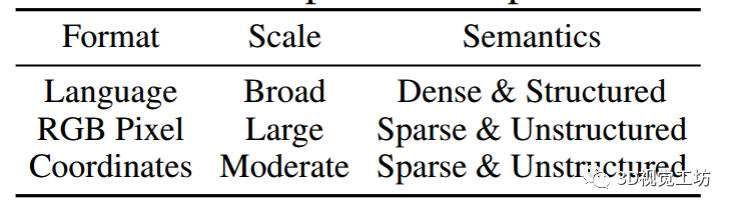
iii. 模式差异。表1显示了语言、2D图像和3D点云的数据模式比较。可以观察到:
- (i)3D点云通常是非结构化的,包含稀疏语义,不同于语言。这导致在点云上进行掩码去噪自编码更加困难;
- (ii)2D图像在网格上均匀分布,而3D点云则是从对象表面不规则采样。这种结构上的差异导致了单模态增强和跨模态对应的对比目标构建的困难;
- (iii)如何设计具有丰富语义的更好表示成为自监督3D理解的主要目标。
在上述分析的推动下,作者提出了将Autoencoders作为跨模态教师进行训练。
-
ACT利用基于2D图像或自然语言预训练的基础Transformers作为跨模态教师,具有丰富的知识和强大的表示能力。通过这种方式,3D中的数据稀缺问题得到缓解。 -
Transformer被用作通用的3D学习器,弥补了掩码建模表示学习方面的架构差距。通过以自监督的方式在3D数据上微调预训练的
Transformers作为自编码器,Transformers可以将3D点云转化为具有丰富语义的表示形式。为了保留和继承预训练的基础知识,使用了提示微调。
因此,ACT使预训练的Transformers成为自发的跨模态教师,为3D点云提供了语义丰富的掩码建模目标。
-
由于预训练的
Transformers被微调为3D自编码器,在这种跨模态Transformer转移过程中不需要任何图像、语言数据或3D下游标注。 -
此外,由于调整后的
Transformers仅用作3DTransformer学生的教师,该方法在下游特征转移过程中不会引入额外的计算或存储成本。
此外,进行了各种任务的大量实验证明了ACT预训练3D Transformers具有出色的泛化性能。
-
例如,在
ScanObjectNN数据集上实现了平均准确率提高%。
据知,本文首次证明了预训练的基础Transformer可以帮助3D表示学习,而无需访问任何2D、语言数据或3D下游标注。ACT是一个自监督的框架,可以推广到其他模态和任务,期望这能够推动更多类似ACT风格的表示学习的探索。
表1: 数据模式比较
二、相关背景
自监督的3D几何处理表示学习
自监督的3D几何处理表示学习目前在学术界引起了极大的兴趣。
-
传统方法是基于重建的几何理解预任务构建的,例如点云部分重排序,方向估计,局部和全局重建,流一致性,变形和遮挡。
-
与此同时,Xie等人在
PointContrast中提出了学习增强点云之间的区分性视角一致性的方法。在这个方向上,还提出了许多相关工作。
最近,许多工作提出了应用点云Transformer的自编码器(DAE)预训练的方法,并取得了显着的成功。
-
Yu等人通过扩展
BERT-style预训练的思想,结合全局对比目标,开创了这个方向。 - Liu等人提出了添加一些噪声点,并对每个掩码位置的掩码标记进行真假分类的方法,这与Selfie的模式相似,后者对掩码图像块进行真假分类。
- Pang等人提出了通过对3D点云坐标进行掩码建模,在点云上探索MAE的方法。
作者遵循这种DAE-style表示学习范式,但与之前的方法不同,工作旨在使用由预训练基础Transformer编码的潜在特征作为掩码建模目标。
跨模态的3D表示学习
跨模态的3D表示学习旨在利用除了3D点云之外的更多模态内在的学习信号,例如,2D图像被认为具有丰富的上下文和纹理知识,而自由形式的语言则具有密集的语义信息。主流方法基于全局特征匹配的对比学习进行开发。
- 例如,Jing等人提出了一种判别性中心损失函数,用于点云、网格和图像的特征对齐。
- Afham等人提出了一种在增强的点云和相应渲染的2D图像之间进行的模态内和模态间对比学习框架。
通过利用几何先验信息进行密集关联,另一项工作探索了细粒度的局部特征匹配。
- Liu等人提出了一种对比知识蒸馏方法,用于对齐细粒度的2D和3D特征。
- Li等人提出了一个简单的对比学习框架,用于模态内和模态间的密集特征对比,并使用匈牙利算法进行更好的对应。
最近,通过直接使用经过监督微调的预训练2D图像编码器取得了很大的进展。
- Image2Point 提出了通过卷积层膨胀来传递预训练权重的方法。
- P2P 提出了将3D点云投影到2D图像,并通过可学习的上色模块将其作为图像主干网络的输入。
一些工作也探索了预训练基础模型是否可以帮助3D学习。然而,本文作者的方法:
(1)不使用预训练的2D或语言模型作为推断的主干模型;
(2)在无下游3D标注的自监督预训练过程中探索使用来自其他模态的预训练基础模型;
(3)不需要成对的点-图像或点-语言数据。
除了2D图像之外,还有一些工作提出利用自然语言进行对比的3D表示学习,零样本学习,以及场景理解。
三、预备知识
3.1 基于Transformer的3D点云表示
与规则网格上的图像不同,点云被认为是不规则和结构较弱的。许多工作致力于为点云数据设计深度学习架构,利用点集的排列和平移不变性进行特征学习。
-
不仅仅依赖于这样的专门主干,还利用
Transformer主干,这样更容易与其他模态(如图像和语言)统一,并促进跨模态的知识传递。 -
使用专门的点网络计算局部几何块嵌入,并将其馈送给
Transformer以输出更有效的几何表示。
局部几何块嵌入
假设有一个点云 ,其中N个坐标编码在 笛卡尔空间中,
- 按照Yu等人(2022)的方法,首先使用最远点采样(FPS)选择个种子点。
- 然后将点云 P 分组为 个邻域 ,其中种子点集 的中心作为组的中心。每个邻域包含 K 个点,这些点是通过搜索对应种子点的K个最近邻点生成的。
- 在每个种子点 周围计算局部几何特征 ,通过在邻域内对每个点的特征进行最大池化得到:
其中:
- 是一个具有参数 的点特征提取器,例如中的逐点MLP,是邻域 中第 j 个邻点 的特征。
-
将邻域特征作为标记特征,用于输入接下来的
Transformer块。
Transformer点特征编码
使用标准的Transformer块作为编码器,进一步转换局部块嵌入 ,其中C是嵌入大小。
按照Yu等人的方法,使用一个具有可学习参数ρ的两层MLP 作为位置嵌入,应用于每个块以实现稳定的训练。
式中,MSA表示多头自注意的交替层,LN表示分层范数,MLP为两层,其中GELU为非线性。 是一种可学习的全局表示嵌入,以 作为其可学习的位置嵌入。
3.2 知识蒸馏:掩码建模的统一视角
掩码建模可以看作是经典自编码器(DAE)的扩展,其中采用了掩码损失,最近已经在语言模型和视觉领域进行了探索。
- 形式上,给定一个由 个 token 组成的序列 ,例如RGB图像或点云数据的标记嵌入。
- 目标是训练一个学生编码器 来预测/重建来自教师编码器 的输出,其中教师可以是离散变分自编码器(dVAE)或简单的恒等映射。
通过这种方式,学生在教师的指导下学习数据中的深层知识。
-
为了损坏输入数据,为每个位置生成一组掩码 ,指示标记是否被掩码。
-
使用可学习的损坏嵌入 来替换被掩码的位置,将损坏的表示 输入到编码器或解码器。这里,表示Hadamard乘积, 是指示函数。
在某个度量空间 中定义了距离函数 ,作为解码器,目标是最小化以下距离:
解码器随着建模目标的不同而变化,例如,它是BERT的非线性投影,带有softmax ,其中度量函数变成交叉熵。可以看作是掩模建模的统一公式。
因此,考虑如何在掩码3D建模中建立一个知识渊博的老师是很自然的。作者的想法是利用2D或语言基础模型中的跨模式教师。
四、ACT: 自编码器作为跨模态教师
目标是通过预训练的2D图像或语言Transformer来促进3D表示学习,该模型具备从大规模数据中吸收的深层知识。
然而,3D点云与2D图像或语言具有不同的结构,这使得细粒度知识的关联变得困难。
为了解决这个问题,采用了一个两阶段的训练过程。ACT框架的概述如图1所示。
-
阶段I:调整预训练的2D或语言
Transformer作为3D自编码器,通过自监督的提示调整来学习理解3D几何。 -
阶段II:使用预训练的3D自编码器作为跨模态教师,通过掩码建模将潜在特征蒸馏到3D点云
Transformer学生中。
4.1 3D自编码与预训练基础Transformer
Transformer是最近在各个领域中主导的架构,可以以统一的方式对任何模态的序列数据进行建模。
- 因此,可以直接使用预训练的Transformer块,将顺序标记与输入点云的3D位置嵌入一起进行输入。
- 本文使用轻量级的DGCNN对点云进行处理,其中的边缘卷积层通过参数 表示。
跨模态嵌入与提示
- 首先,使用DGCNN风格的补丁嵌入网络对点云进行编码,产生一组标记嵌入:。
-
然后,通过提示这些标记嵌入,并将其输入到预训练且冻结的
Transformer块的D层中,例如2DTransformer:。在这里,使用 来表示 2DTransformer的第 层。
使用 个可学习的提示嵌入 ,应用于Transformer 的每一层。具体来说,Transformer的第 层 将隐含表示 从第 层转换为 ,如下所示:
使用这种参数高效的快速调整策略,能够调整预训练的基础Transformer,同时保留尽可能多的预训练知识。
点云自编码
另一个DGCNN网络 用于从基础Transformer嵌入的隐藏表示中提取局部几何特征。然后,利用FoldingNet 对输入点云进行重构。
将以上3D自编码器作为离散变分自编码器(dVAE)进行训练,以最大化对数似然 。这里 表示原始和重构的点云。
整体优化目标是最大化证据下界(ELBO),当时成立:
其中:
- 表示离散的3D dVAE tokenizer;
- 是给定离散点标记的dVAE解码器;
- 以自编码方式重构输入点云。
4.2 掩码点建模作为跨模态的知识蒸馏
通过训练3D自编码器,预训练Transformer的强表示被转化为3D特征空间,使自编码器自动成为一个跨模态教师。
将在4.1节中介绍的预训练点云编码器作为教师 ,将3D Transformer 作为学生。
通过掩码建模作为跨模态知识蒸馏,最小化编码后的教师特征与学生特征之间的负余弦相似度 :
五、实验
5.1下游任务迁移学习
迁移学习设置
在分类任务中使用迁移学习的三种变体:
(a) FULL: 通过更新所有骨干和分类头来微调预训练模型。
(b) MLP- linear: 分类头是单层线性MLP,只在微调时更新该分类头参数。
(c) MLP-3: 分类头是一个三层非线性MLP(与FULL中使用的相同),只在微调时更新这个头的参数。
3D真实数据集分类
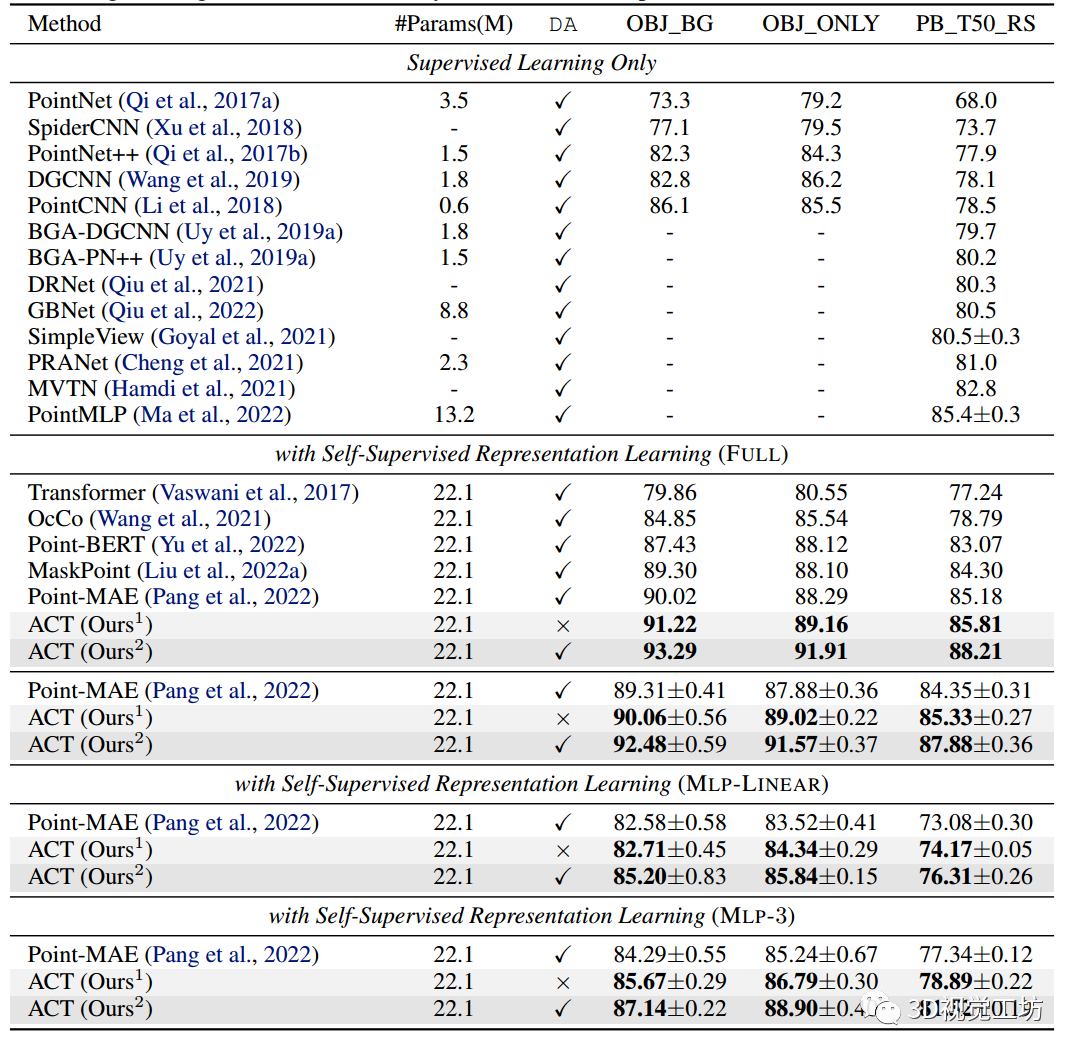
首先展示了在具有挑战性的现实数据集ScanObjectNN上对3D形状识别的评估。结果如表2所示,其中可以观察到:
(i) 与FULL调优协议下从头开始的Transformer基线相比,ACT在三个不同的ScanObjectNN基准测试上平均获得了+10.4%的显着改进。此外,通过简单的点云旋转,ACT实现了+11.9%的平均改进;
(ii) 与明确以三维几何理解为目的设计的方法相比,ACT`始终取得更好的结果。
(iii) 与其他自监督学习(SSL)方法相比,在ScanObjectNN上,ACT在所有方法中实现了最好的泛化。此外,在ScanObjectNN上使用纯3D Transformer架构的方法中,ACT成功地达到了最先进(SOTA)的性能,例如,在最具挑战性的PB_T50_RS基准测试中,ACT比Point-MAE的准确率高出+3.0%。
表2:
ScanObjectNN上的分类结果。our1:没有数据增强的训练结果。Ours2:简单点云旋转训练的结果。DA:在微调训练期间使用数据增强。报告总体精度,即OA(%)。
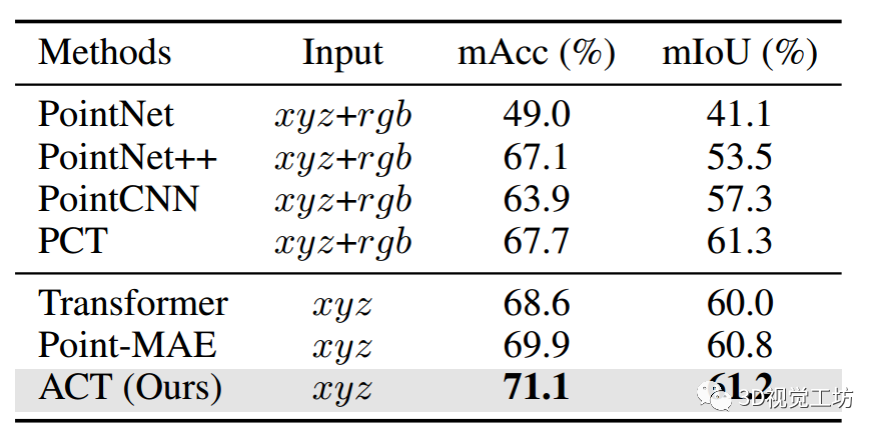
3D场景分割
大规模3D场景的语义分割具有挑战性,需要对上下文语义和局部几何关系的理解。在表4中,报告了S3DIS数据集的结果。可以看到:
(i) ACT显著提高了从零开始的基线,mAcc和mIoU分别提高了+2.5%和+1.2%。
(ii) ACT比SSL对应的Point-MAE分别高出+1.2%和+0.4%的mAcc和mIoU,在大场景数据集上显示出优越的传输能力。
(iii) 仅使用几何输入xyz, ACT可以实现与使用xyz+rgb数据进行细致设计的架构相当或更好的性能,包括3d特定的Transformer架构。
表4:
S3DIS区域5上的语义分割结果。报告了所有类别的平均准确性和平均IoU,即mAcc(%)和mIoU(%)。使用Xyz:点云坐标。xyz+rgb:同时使用坐标和rgb颜色。
3D合成数据集分类
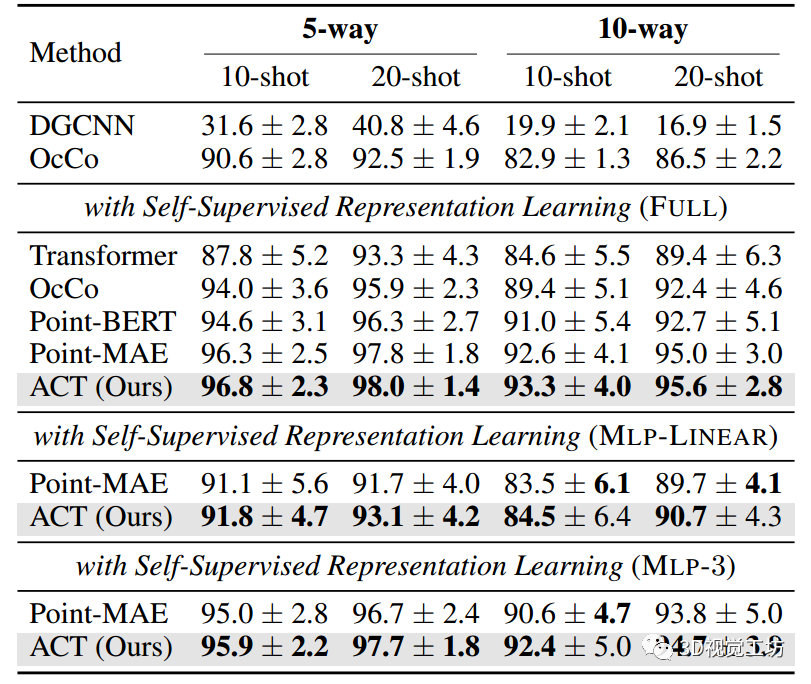
展示了在合成数据集ModelNet40上对三维形状分类的评估。为了证明在有限的训练样例下ACT的数据效率特性,首先遵循Sharma & Kaul(2020)来评估 few-shot 学习。
从表5中,可以看到:
(i) 与从头开始的FULL转移基线相比,ACT在四种设置下分别带来了+9.0%,+4.7%,+8.7%,+6.2%的显着改进。
(ii) 与其他SSL方法相比,ACT始终实现最佳性能。
然后,在表3中展示了完整数据集上的结果,在表3中我们观察到,与FULL协议下的从头基线相比,ACT实现了+2.5%的准确率提高,并且结果与所有协议中的其他自监督学习方法相当或更好。
表3:
ModelNet40数据集上的分类结果。报告总体精度,即OA(%)。[ST]:标准Transformer架构。
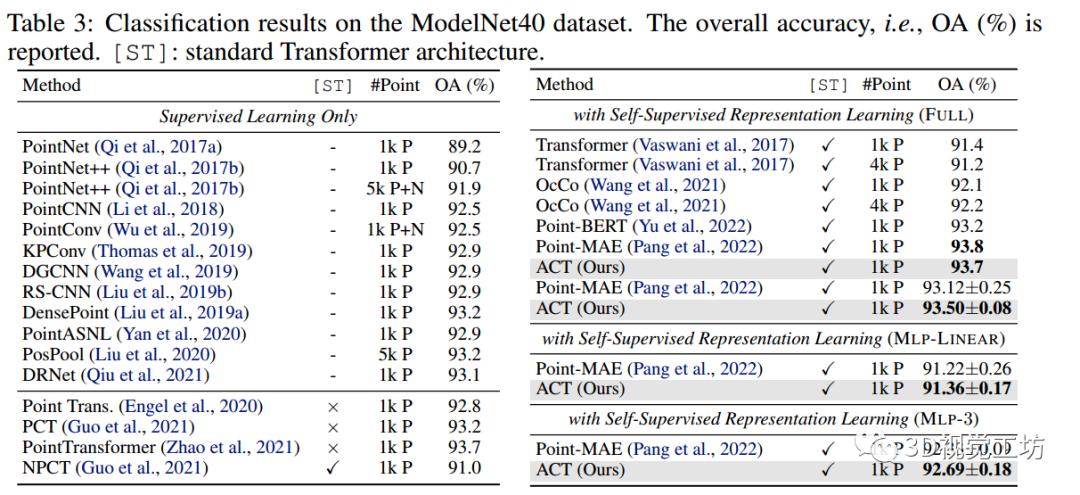
表5:在
ModelNet40上的Few-shot分类,报告了总体准确率(%)。
5.2 消融研究
解码器深度
表6展示了使用不同解码器深度的ACT在ScanObjectNN上的平均微调准确率。可以看出,性能对解码器深度不敏感,我们发现具有2个块的解码器取得了最高的结果。
-
需要注意的是,当解码器深度为0时,我们采用了类似BERT的掩码建模架构,其中没有解码器,编码器可以看到所有的标记,包括被掩码的标记。
-
我们发现这导致了较差的结果,与在2D上观察到的数据的低语义性需要一个非平凡解码器的观察一致。
表6: 预训练解码器深度的消融研究。
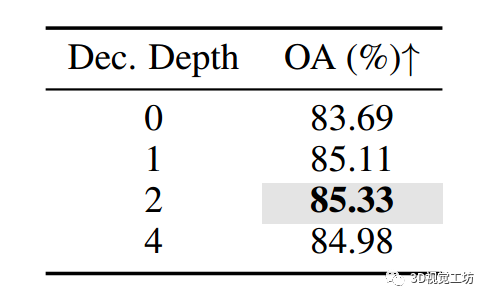
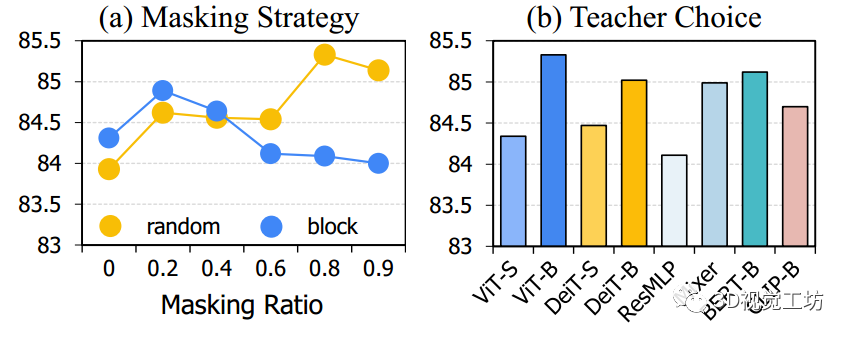
图2: 掩码比 消融研究和跨模
Transformer教师选择。
掩码策略和教师选择
图2(a)展示了使用不同掩码策略在ScanObjectNN上的平均微调准确率。
- 可以观察到,使用随机掩码的较高掩码比例会产生更好的结果,而块掩码则对较低掩码比例更为适用。
- 需要注意的是,当掩码比例为零时,对所有标记使用基准知识蒸馏,并且导致性能较差。
-
图2(b)展示了使用不同教师
Transformer的ACT在ScanObjectNN上的平均微调准确率,包括VisionTransformers、全MLP架构、语言模型和视觉语言模型。观察到较大的教师模型始终能够获得更好的性能。
此外,令人惊讶的是,ACT使用语言模型BERTB(即BERTbase)作为跨模态教师,可以达到平均准确率85.12±0.54%(最高可达85.88%),这表明ACT可以推广到任何模态。
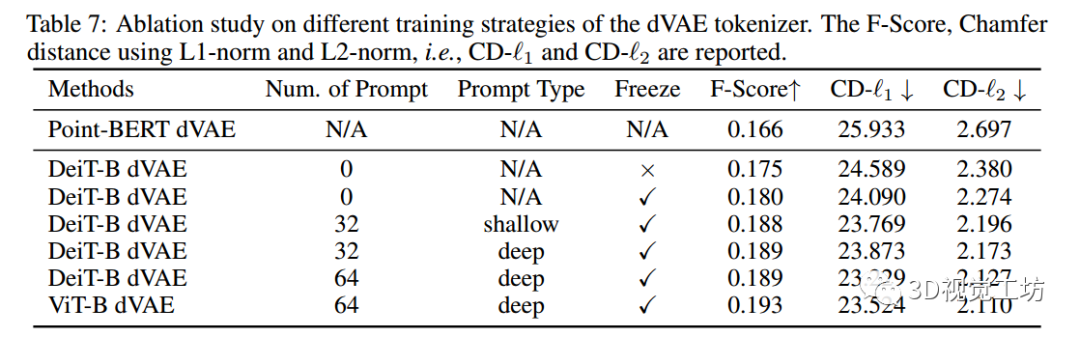
表7: dVAE标记器不同训练策略的消融研究。
- 报告了F-Score,使用l1范数和l2范数的倒角距离,即CD- l1和CD- l2
3D自编码器训练
表7展示了使用预训练的2D图像Transformer进行不同训练配置的3D自编码器的重构结果。观察到:
(i)带有预训练图像Transformer的3D dVAE模型在重构结果上明显优于Point-BERT。这表明预训练的2D图像Transformer具有强大的对3D的表示能力。
(ii) 提示调整或冻结模型可以获得比完全调整更好的结果,我们认为这是因为某些预训练的2D知识被遗忘了,而提示调整有效地解决了这个问题。重构可视化结果可以在附录D中找到。
六、讨论
6.1 是所需要更强大的标记器吗?
为了了解预训练的2D图像Transformer在3D dVAE模型中的必要性,我们用不同的dVAE教师和掩模建模配置进行了实验。
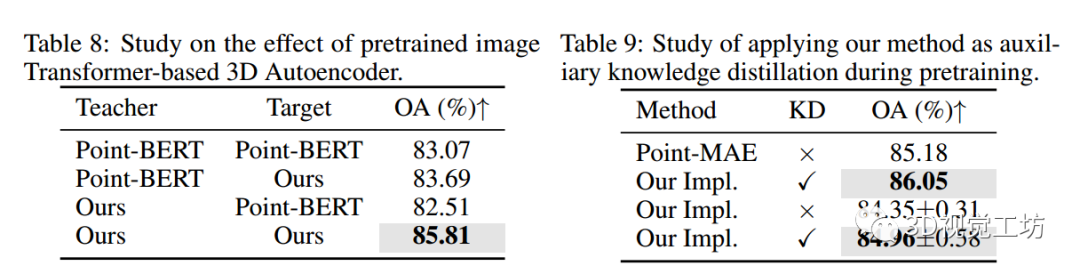
从表8中,可以看到:
(i) 当使用没有预训练的2D图像变压器的Point-BERT dVAE模型时,通过提取潜在特征而不是离散令牌,可以实现+0.62%的改进。分析认为,离散令牌识别学习起来更具挑战性3D数据。
(ii) 当使用Point-BERT离散标记作为掩码建模目标时,通过应用带有预训练2D图像Transformer的dVAE模型,得到了最差的性能。这表明,无论标记器有多强大,离散标记都不适用于语义稀疏的点云数据。
(iii) 当使用ACT时,性能显著提高。这表明,带有预训练2D图像Transformer`的3D dVAE能够编码具有丰富语义的特征,更适合于掩码点建模。
表10: 二维图像转换器在dVAE模型中不同位置嵌入的研究。
(a)无:不使用位置嵌入。(b) 2D/z:仅使用2D xy平面坐标的位置嵌入。
(c) 3D:所有3D xyz坐标的位置嵌入。
报告了F-Score,使用l1范数和l2范数的倒角距离,即CD- l1和CD-l2,以及
ScanObjectNN上的OA。

6.2 ACT是否可以用作辅助知识蒸馏方法?
由于ACT使用编码特征作为掩码建模目标,它具有将我们的方法作为辅助特征蒸馏的潜力。
表9显示了在Point-MAE模型中,使用ACT作为中间特征的辅助深度监督训练的结果,其中ACT编码的潜在特征被蒸馏到Point-MAE的编码器特征中。
可以观察到,ACT能够显著提高Point-MAE在ScanObjectNN上的准确率,提高了0.87%,表明ACT作为一种知识蒸馏方法具有可扩展性和有效性。
6.3 2D Vision Transformer如何理解3D点云?
为了更好地理解2D图像Transformer如何通过自编码器训练理解3D输入,研究了ViT-B在我们的ACT dVAE模型中使用的位置嵌入的效果。从表10可以看出:
(i) 在没有任何位置嵌入的情况下,预训练的ViT仍然可以学习可迁移的3D特征(准确率为84.21±0.45%)。我们认为这是因为位置几何信息已经包含在输入的3D坐标中,预训练的2D Transformer可以通过几何特征纯粹处理3D数据,而不需要显式的位置提示。
(ii) 当仅使用2D xy平面坐标的位置嵌入时,准确率显著提高了0.89%。我们认为2D位置嵌入是为了适应冻结的图像Transformer而学习的,使图像Transformer能够将3D输入编码为具有高语义的预训练2D特征空间。
(iii) 当使用所有3D坐标进行位置嵌入时,2D图像Transformer成功利用了附加坐标信息来进行更好的特征编码。
七、总结
本文提出了一种自监督学习框架ACT,通过预训练的基础Transformer进行掩码建模,将特征蒸馏传递给3D Transformer学生模型。ACT首先通过自监督的3D自编码将预训练的基础Transformer转化为跨模态的3D教师模型。
然后,来自调整后的3D自编码器的语义丰富的潜在特征被用作3D Transformer学生模型的掩码建模目标,展现了在各种下游3D任务上卓越的泛化性能。作为一种通用的自监督学习框架,相信ACT可以轻松扩展到除3D数据之外的其他模态。
这种自监督方式展示了跨模态知识转移的巨大潜力,这可能在数据驱动的深度学习时代极大地促进了基础建模的发展。
附录:
可视化
图3比较了基于2D图像Transformer的3D dVAE和Point-BERT 3D dVAE模型的重建结果。
- 实验结果表明,所设计的三维自编码器能够高质量地重建物体细节。
- 对于一些相对简单的物体,如第二行矩形表,我们的方法和Point-BERT都可以很好地重建它们。然而,对于细节相对复杂的点集,如第三排的薄架子和扶手椅,我们的方法仍然可以用详细的局部几何信息重建物体。
- 这些定性观察结果与表7中的定量结果一致。
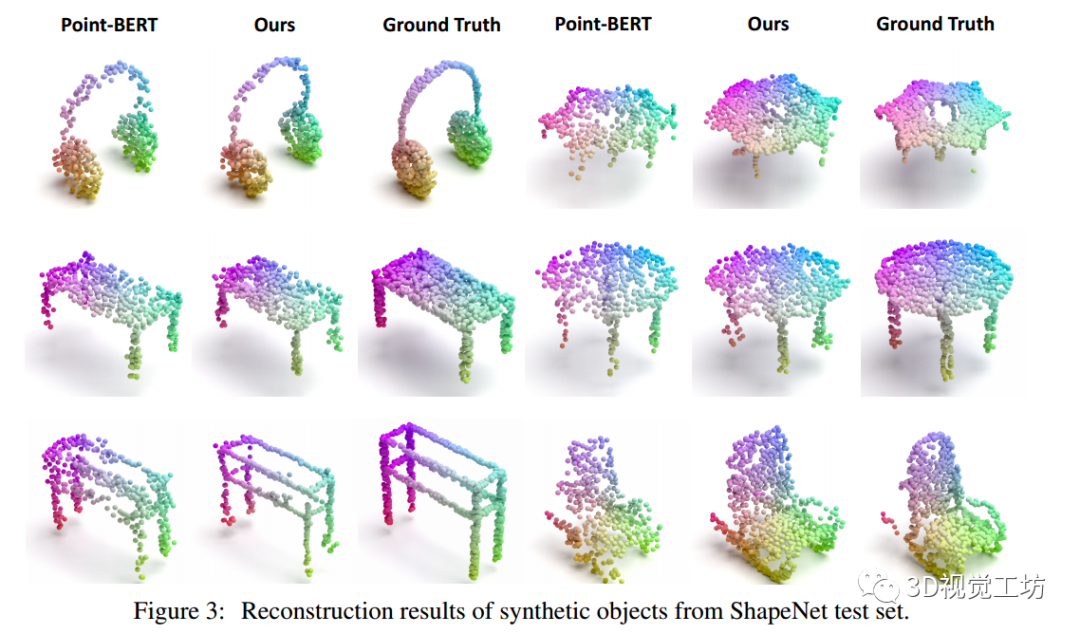
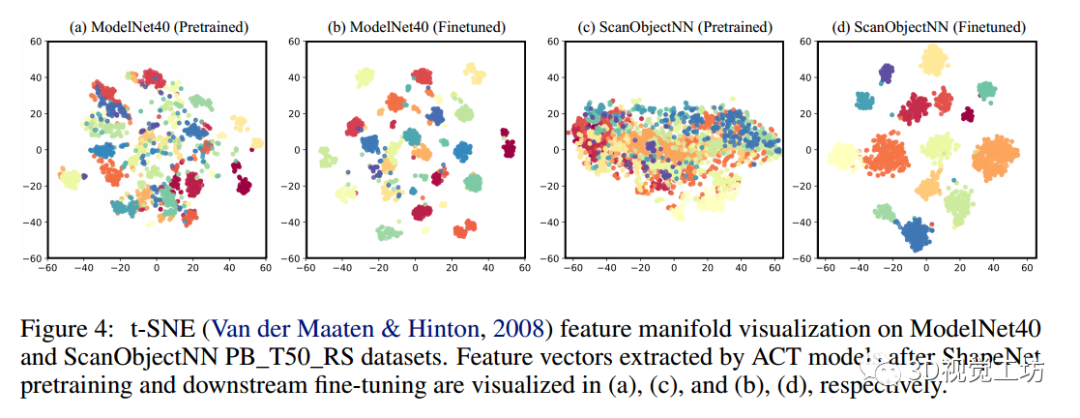
图4显示了t-SNE在ShapeNet上进行预训练并在ModelNet40和ScanObjectNN PB_T50_RS数据集上进行微调后的模型特征可视化。
可以观察到:
(i) 在ShapeNet上进行预训练后,由于相对较小的域间隙,模型已经可以在ModelNet上产生判别特征。
(ii) 在对下游数据集进行微调后,在ModelNet40和具有挑战性的ScanObjectNN数据集上都获得了判别特征。
(iii) Shapenet预训练ACT在ScanObjectNN上提取的特征分布看起来不那么判别性。我们认为有两个原因导致它: (i)合成的ShapeNet和真实的ScanObjectNN数据集之间的大域差距,以及(ii) ACT使用的不是对比损失,例如区分(例如,Point-BERT使用的MoCo损失)。有趣的是,这在ScanObjectNN上产生了更好的泛化性能(ACT的OA为88.21%,而Point-BERT为83.07%)。
- 相关推荐
- 热点推荐
- 模型
- 数据集
- Transformer
-
针对显示屏的2D/3D触摸与手势开发工具包DV1020142018-11-07 2196
-
如何同时获取2d图像序列和相应的3d点云?2018-11-13 3036
-
为什么3D与2D模型不能相互转换?2019-09-20 2452
-
2D到3D视频自动转换系统2018-03-06 1783
-
适用于显示屏的2D多点触摸与3D手势模块2018-06-06 6343
-
如何把OpenGL中3D坐标转换成2D坐标2018-07-09 9403
-
阿里研发全新3D AI算法,2D图片搜出3D模型2020-12-04 4778
-
3d人脸识别和2d人脸识别的区别2022-02-05 54383
-
基于神经网络的2D到3D的机器学习2022-10-11 1229
-
探讨一下2D和3D拓扑绝缘体2022-11-23 5041
-
基于深度学习的3D点云实例分割方法2023-11-13 3959
-
2D与3D视觉技术的比较2023-12-21 3275
-
一文了解3D视觉和2D视觉的区别2023-12-25 5670
-
介绍一种使用2D材料进行3D集成的新方法2024-01-13 2401
-
英伦科技:2D/3D可切换显示技术未来应用场景有哪些?2026-05-08 276
全部0条评论

快来发表一下你的评论吧 !
