

小鹏汽车新一代感知架构XNet信息解读
电子说
描述
在刚刚过去的CVPR会议上,作为国内唯一一家被邀请登台演讲的造车新势力,小鹏汽车向参会者介绍了小鹏汽车在国内量产辅助驾驶系统的经验。
作为小鹏汽车最新一代的感知架构,XNet在量产中发挥的作用不容小觑。
笔者有幸采访到小鹏汽车自动驾驶中心感知首席工程师 Patrick,更进一步得了解XNet的性能、架构,以及小鹏的自驾团队为搭建XNet所做的努力。
1. XNet实现的性能提升
XNet实现了感知结构的升级,拥有更好的性能,主要包括3个方面。
1.1超强环境感知能力,实时生成“高精地图”

XNet可以根据周围环境实时构建“高精地图”。从上图我们可以看到,车辆正在经过一个环岛,图中显示的车道线不是来自于高精地图,而是来自于XNet的感知输出。XNet不光可以输出车道线,还有停止线、人行道、可行驶区域等。这是将来小鹏汽车应对无图场景,做高级别城市辅助驾驶的最核心的能力之一。
1.2更强的360度感知,博弈更强、变道成功率更高
在上一代感知架构中,盲区问题很难解决。在最靠近本车的地方,尤其是车辆的下边界,感知系统的检测效果往往不好。XNet采用多相机多帧、前融合的感知方案,可以根据图像内的车身信息推测车辆在BEV视角下的3D位置信息,解决了相机上下视野受限的问题;还可以更加有效地同时融合多相机的信息,尤其是分节到两个相机视野中的物体,从而避免盲人摸象式的物体感知。
另外,输入包含时序信息的视频流后,XNet对近车物体的识别能力有大幅提升,可以更加稳定地检测到近车物体。那么,自动驾驶系统的博弈能力就更强,汽车变道的成功率更高。
1.3更精准识别动态物体速度和意图,博弈能力大幅提升;运动感知冗余,在城市场景安全性更高
XNet不仅能够检测物体的位置,还能够检测物体的速度甚至是完成对物体未来运动轨迹的预测。毫米波雷达通常很难检测在本车前横跨车道的车辆的速度,而XNet可以很容易地检测到这个速度,对毫米波雷达有明显的增强作用。在毫米波雷达比较擅长的场景,XNet也可以提供冗余,从而提高城市场景整体的安全度。
2. XNet的架构
XNet为什么可以实现更好的性能呢?Patrick介绍了XNet的具体架构和工作流程。
XNet采用多相机多帧的方式,把来自每一个相机的视频流,直接注入到一个大模型的深度学习网络里,进行多帧时序前融合,输出BEV视角下的动态目标物的4D信息(如车辆,二轮车等的大小、距离、位置及速度、行为预测等),以及静态目标物的3D信息(如车道线和马路边缘的位置)。
如下图所示。
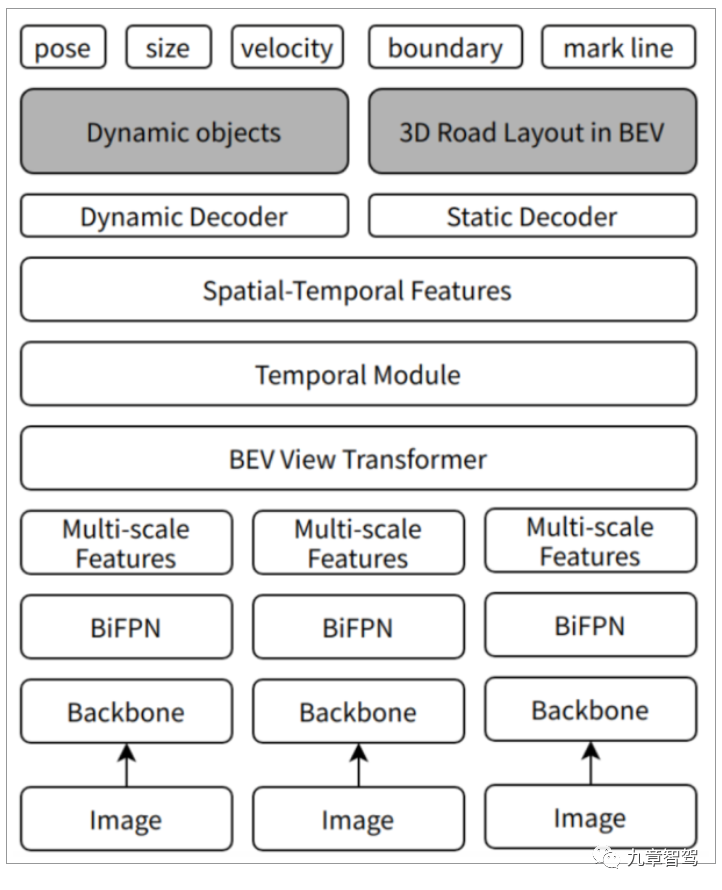
每张输入的摄像头图像经过网络骨干(backbone)和网络颈部(neck,具体来讲是BiFPN网络)后生成图像空间的多尺度特征图。
这些特征图经过XNet最关键的部分—BEV视图转换器(BEV view transformer)后,形成BEV下的单帧特征图。
不同时刻的单帧特征图在BEV视角下,根据自车的位姿进行时空融合,形成BEV下的时空特征图。
这些时空特征图是进行BEV解码推理的基础,在时空特征图后接两个解码器,完成动态XNet和静态XNet的结果解码和输出。动态结果包括pose、size、velocity等,静态结果包括boundary、mark line等。
至此,感知部分基本就完成了。
3. 团队为搭建XNet所做的努力
要实现上述架构并不容易,在采集、标注、训练、部署四个方面,小鹏的自驾团队都做了大量的工作来优化整个流程。
3.1采集
实车数据和仿真数据是数据的两大来源。
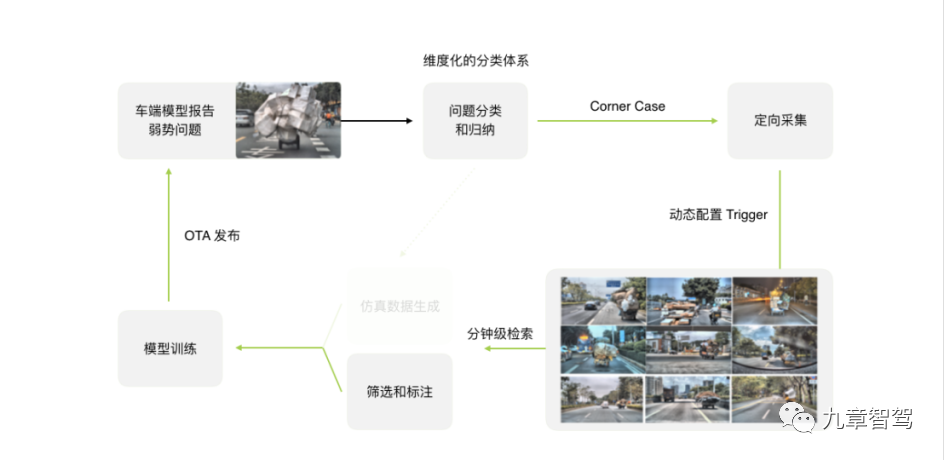
小鹏有接近十万辆用户车,这些车都可以用来完成数据采集的任务。如下图所示,车端模型会报告自动驾驶系统目前处理得不够好的问题,针对这些问题,小鹏的自驾团队会在车端设置相应的触发器来定向采集相应的数据。然后,这些数据会被上传到云端,经过筛选和标注后用于模型训练和后续的OTA升级。
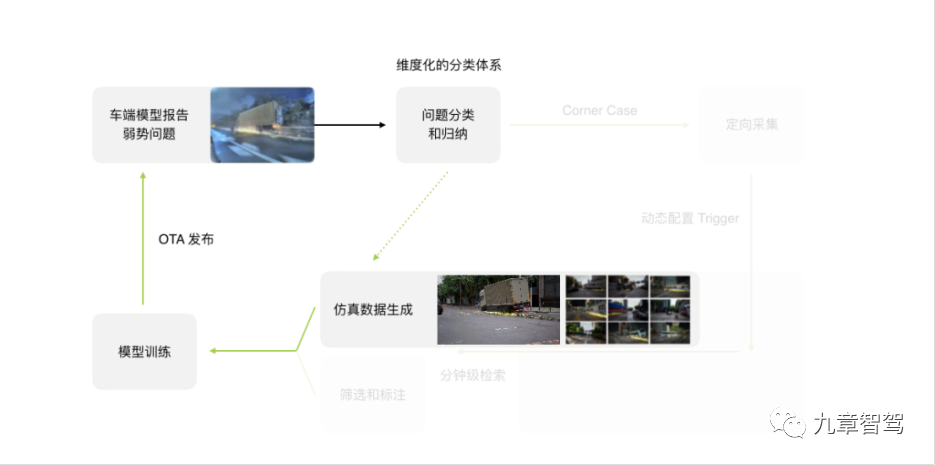
此外,仿真数据也是数据的重要来源。吴新宙在1024科技日上举了一个例子—行车过程中,前面一辆大卡车因为轮胎脱落与地面摩擦起火,这种情形在实际生活中是极为罕见的。对于这样出现频率极低的情形,实车采集很困难,即使小鹏已经有了近十万辆量产车,收集到足够多的数据可能也需要数年时间。
对于这样的情形,仿真数据可以起到很好的辅助作用。如下图所示,小鹏的自驾团队可以根据实车数据,采用unreal5引擎产生成千上万个类似的case ,模拟各种各样车轮脱落的情形。
当然,仿真数据不能滥用,需要尽可能地贴近现实。小鹏的自驾团队主要从光影真实和场景真实两方面来尽量保证仿真数据的真实性。
小鹏的自驾团队采用了技术上领先的unreal5作为渲染引擎,这样通过仿真生成的图片看起来比较真实,没有卡通感,保证了“光影真实”。
此外,生成仿真数据时,是先找到模型的弱势场景,然后对这些场景做数字孪生(digital twin),再在此基础上进行定向修改。具体来说,可以先用4D自动标注从真实场景里提取4D结构化信息—包括动态物体的4D轨迹、和静态场景的3D布局等,然后用渲染引擎对结构化信息进行渲染填充,形成仿真图片。这样,生成的场景就是在模拟真实世界可能发生的场景,保证了“场景真实”。
3.2标注
要训练XNet,需要50万到100万个短视频,其中的动态目标的数量可能是数亿级甚至十亿级的。按照当前人工标注的效率,需要1000人的团队花两年时间才能完成训练XNet所需数据的标注。
小鹏汽车打造了全自动标注系统,此系统的标注效率是人工的近45000倍,全自动标注系统仅需16.7天就可以完成标注工作。此外,全自动标注系统质量更高,信息更全(包含3D位置、尺寸、速度、轨迹等信息),产量更大(峰值日产 30000 clips,相当于 15个NuScene数据集 )。
全自动标注系统是如何做到高效的呢?
首先,从人工标注到自动标注,人的角色发生了很大的变化。人工标注场景下,人是标注员;在自动标注场景下,人是质检员,只是去判别和纠正自动标注系统做的不好的地方,人效会有数量级的提升。
其次,在自动标注场景下,占数据集大多数的训练数据是自动化质检的,只有评测数据集是人工质检,需要人工操作的数据量有数量级的减少。
最后,自动标注让产出瓶颈从人力资源转到了计算资源。在云端,计算资源可以很方便地拓展,可以灵活地按需部署大量资源进行生产。
3.3训练
小鹏与阿里云合作打造了中国最大的自动驾驶计算中心—“扶摇”,“扶摇”的算力可达600PFLOPS,相当于成千上万个Orin组成的训练平台。借助扶摇的强大算力,小鹏的自驾团队采用云端大规模多机训练的方式,把XNet的训练时间从276天缩短到了11个小时,实现了602倍的训练效率的提升。
如下图所示,假如采用单机全精度方式,训练整个XNet需要276天。小鹏的自驾团队通过优化训练scheme从而减少epoch、优化网络结构和算子、为Transformer定制混合精度训练的方式,将单机训练时间从276天缩短到了32天。然后,团队充分利用云端算力,将单机训练改为80机并行训练,训练时间从32天缩短到了11小时。

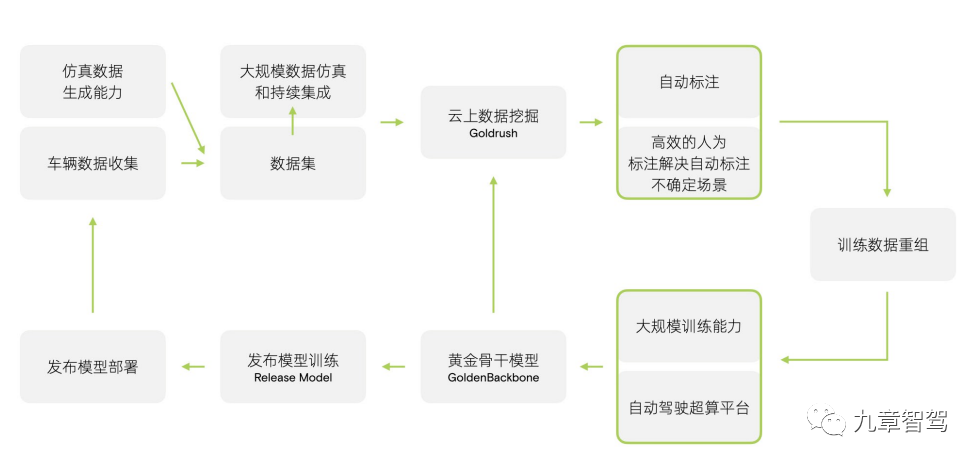
此外,团队引入了Golden Backbone模型,将基础网络能力的提升和模型的发布解耦,实现了训练效率的提升。具体来说,如下图所示,Golden Backbone可以和数据挖掘、自动标注、自动驾驶超算平台等形成一个闭环。在这个环里,只要有持续的数据输入,Golden Backbone的能力就可以持续地得到优化。需要发布模型的时候,只需在Golden Backbone的基础上做一些优化,而无需从头开始训练。
3.4部署
在部署层面,小鹏的自驾团队有很多积累。经过团队优化后,Transformer的运算时间减少到了原来的5%。此外,原本需要122%的Orin-X算力才能运行的模型,现在只需9%的Orin-X算力就能运行。
在部署上,小鹏的自驾团队有哪些亮点呢?根据Patrick的介绍,主要是分三步走。
“首先是Transformers层的重写。经过对模型板端运行时间的分析,我们发现原版的Transformers层占用时长是大头。于是,我们尝试了很多种Transformers的变种构建方法,找到了一个模型效果好,在板端运行快的版本。”
“然后是网络骨干的剪枝。我们重写了Transformers以后发现,网络骨干(backbone)是我们的性能瓶颈。于是我们对网络骨干进行了剪枝,降低了骨干部分的运行时间。”
“最后是多硬件的协同调度。在我们的基于Orin-X的计算平台上,有三种计算单元—GPU、DLA还有CPU。这三种硬件对网络的不同算子的支持度各有不同。我们把网络的不同构件放到最适合它运行的地方,然后统一调度三种计算硬件,让三者协同完成网络推理。”
-
新一代汽车产品发展趋势2010-03-10 2573
-
2016汽车与信息通信融合发展论坛2016-07-07 2922
-
新一代音频DAC的架构介绍2019-07-22 3109
-
德州仪器(TI)推出新一代KeyStone II架构2021-05-19 2625
-
HDC技术分论坛:HarmonyOS新一代UI框架的全面解读2021-11-22 1820
-
新一代Arm汽车解决方案中,一台车的搭载的内存DRAM跟现在相比大概会差了几倍2022-08-30 2531
-
新一代音频DAC的架构设计2011-04-20 3504
-
新一代音频DAC的架构分析与设计2012-09-29 1749
-
Imagination宣布推出新一代GPU架构2017-03-10 1280
-
新一代信息基础设建设工程重点解读2017-11-30 4651
-
小鹏汽车宣布下一代自动驾驶架构将包括激光雷达技术2020-11-20 3463
-
大众与小鹏签署电子电气架构技术战略合作框架协议2024-04-22 1498
-
小鹏汽车与大众汽车宣布签署E/E架构技术合作框架协议2024-04-23 1480
-
小鹏汽车与大众汽车达成电子电气架构技术战略合作2024-07-22 1900
-
宝马发布全新一代智能电子电气架构2025-03-13 966
全部0条评论

快来发表一下你的评论吧 !
