

浅谈AI算力基础设施的架构和平衡设计
人工智能
描述
AI在各种各样的实际场景中都有相关的应用。比如以卷积网络为核心的图像检测,视频检索技术可应用于下游的安防、医疗诊断、自动驾驶等场景;以强化学习为基础的博弈决策技术,可应用于交通规划等领域;以Transformer为核心的自然语言处理技术,可以应用于搜索推荐、智能人机接口等场景。
AI 算力基础设施的重要性
目前,人工智能(AI)是中美科技竞争的重要领域。2020年4月,国家发改委明确将人工智能纳入新基建范围,AI是新基建之一。而在2019年2月,美国发布了《维护美国人工智能领导力的行政命令》(Execution Order On Maintaining American Leadership in Artificial Intelligence),此命令可视为美国国家AI战略的里程碑。而在2020年10月,美国国家AI安全委员会又指出:“必须不惜一切代价在AI上击败中国”。可见,AI对于中美未来综合国力的竞争是非常重要的。此外,中美两国在人工智能领域各有优势。从AI技术三驾马车:算法、数据、算力来看,中国在大数据领域处于优势地位,但在算法和智能算力领域,中国落后于美国。智能算力的不足严重制约了我国在AI领域的创新能力。可以看到,智能AI算力在中美科技竞争中占据非常重要的战略地位。
那么,AI算力究竟为何如此重要呢?除去前面提及的中美竞争的大背景,AI算力对于我国经济建设、科技建设都有着非常积极的意义。
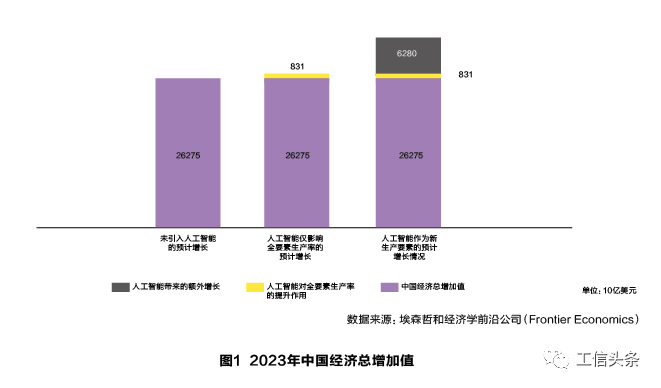
首先,算力即生产力,算力能够推动经济发展方式变革。据埃森哲和经济学前沿公司分析,预计到2035年,AI将推动我国GDP增长21%。由此可见,算力将成为智能经济的发动机。
其次,AI算力正在改变基础科学和智能领域的创新模式。比如,AlphaFold2解决了结构生物学50年的难题,AI+HPC将高能物理计算加速数百倍。
AI在各种各样的实际场景中都有相关的应用。比如,以卷积网络为核心的图像检测,视频检索技术可应用于下游的安防、医疗诊断、自动驾驶等场景;以强化学习为基础的博弈决策技术,可应用于交通规划等领域;以Transformer为核心的自然语言处理技术,可以应用于搜索推荐、智能人机接口等场景。其中最典型的自然语言处理模型,比如GPT-1、GPT-2、GPT-3,BERT的发展非常迅速,模型规模从几亿到几千亿再到几万亿参数。以上一切技术都需要AI算力来提供支持。
综上所述,AI算力影响了我们社会的方方面面。因此,构建AI算力的基础设施非常重要。
AI 算力基础设施的架构和平衡设计
AI算力非常重要,对AI算力基础设施的架构进行设计,是提升AI算力的第一步。
现有算力体系,比如超算系统,主要针对的是HPC的应用,而AI和HPC存在着一些区别。比如,HPC主要应用于科学和工程计算,像天气预报、核聚变模拟、飞行器设计等,而AI主要用于分类、回归、自然语言处理,下游任务主要是安防、互联网搜索推荐、金融风控、智能制造;从运算精度角度来说,HPC主要为双精度浮点运算,而AI主要为半精度浮点运算或者低精度整数运算;从编程角度来看,HPC主要是基于MPI来做并行计算,而AI基于Pytorch、TensorFlow、 MindSpore、Oneflow、DeepSpeed等机器学习框架;HPC的性能指标主要是HPL、HPCG,而AI的性能指标是MLPerf、AIPerf。传统超算系统对于AI系统的支持性不佳。因此,需要针对AI的特性来设计新的超算系统。目前,代表性的HPC和AI系统主要有以下几个:天河2号、神威太湖之光、Summit、富岳、Frontier、鹏城云脑2等。
其中,鹏城云脑2是新一代AI HPC系统。该系统包含4套华为Atlas900系统,4套系统节点间用200Gbps网络互连。鹏城云脑的总半精度计算性能可达1E flops,双精度可达1P flops。那么,设计AI系统的系统结构要素有哪些呢?我们先来看一下一般大规模计算机系统中是什么样的。一般来说,大规模计算机系统包括四个部分,即处理器、内存、存储与互联网络。
具体来说,AI算力系统和传统HPC系统在各个要素上存在一些联系和区别。
在处理器上,AI算力系统着重半精度计算性能,面向神经网络运算的优化(如nVidiaGPU的TensorCore);HPC系统双精度性能优先,兼顾低精度计算,更大规模机器甚至需要采用80位或128位高精度。
在互联网络上,AI算力系统需要高性能参数平面网络(如nvlink)连接训练单一模型的加速器组(nVidia 8或16卡,华为4096卡);HPC系统一般从全系统角度考虑网络拓扑和通信需求。
在存储系统上,AI算力系统局部高性能存储(NVMe SSD)存放训练数据集(如GPT-345TB),避免从全局文件系统读取数据造成瓶颈;HPC系统一般采用Lustre等全局并行文件系统,支持MPI-IO。
结合以上分析,在设计新型AI系统时,要重视系统平衡性原则。
计算平衡设计
鹏城云脑2原有设计中主要考虑半精度运算性能,双精度运算能力过低,双精度与半精度运算性能之比为1:1000。
根据科学计算和大模型训练的发展趋势,要改变精度平衡设计的思想, 建议增加通用算力,为云脑适应科学计算和更广泛的AI算法和应用提供保障。
网络平衡设计
鹏程云脑2原有网络设计主要针对CNN等算法,未考虑极大规模预训练模型对系统的需求;原有数据平面网络的顶层网络裁剪比为1:4,对训练数据读取和大规模科学计算支撑不足;建议数据平面顶层网络裁剪比改进为1:1,华为相应修改了网络连接方式,并增加了顶层交换机,为IO500测试多次名列世界第一打下了基础。
IO子系统平衡设计
鹏程云脑2原有系统的本地NVME SSD仅通过本地文件系统访问,限制了其应用范围;应将每台服务器上的快速本地NVME整合成应用为可见的全局分布式文件系统,并开发高性能MADFS并行文件系统,在多次IO500测试中获得世界第一。现在,已经有越来越多的城市陆续启动人工智能计算中心建设,让算力无处不在、触手可及!
AI 算力的评测方法
前面介绍了AI算力基础设施的设计,除此之外,AI算力的评测(AI Perf)也是非常重要的。
为什么需要AI算力评测呢?
首先,公众需要一个评价指标来回答:哪套系统的人工智能算力更强?
其次,我们需要知道,整个领域的发展状况如何?显然,一个好的指标能够引领领域的健康发展。然而,传统高性能计算机的测试结果与人工智能需要的性能不完全一致。
正如前面所述,HPC和AI所采用的数据精度不同,需要针对AI来设计基准评测程序。而现有AI基准评测,面临以下几个问题:DeepBench测试底层人工智能芯片计算的效率,不能反映超大规模系统性能,针对单个芯片,不适用于整机评测;Mobile AI Bench针对移动端硬件上的模型训练评测,无法体现超算对大规模AI应用的性能;MLPerf,采用单一人工智能网络模型,百张加速卡以上规模测试下可扩展性明显下滑,难以支撑在千卡以上级别的系统评测。
为了克服AI基准评测的问题,需要实现以下四个目标。
1.一个统一分数。AIPerf需要能够报告一个统一分数作为被评测集群系统的评价指标。AIPerf目前的评价指标是AIops,即平均每秒处理的混合精度AI操作数。使用一个而不是多个分数能方便进行不同机器的横向比较,以及方便向公众宣传。
2.可变的问题规模。人工智能计算集群往往有着不同的系统规模,差异性体现在结点数量、加速器数量、加速器类型、内存大小等指标。因此,为了适应各种规模的高性能计算集群,AIPerf 能够使用AutoML进行问题规模的变化来适应集群规模的变化,从而充分利用人工智能计算集群的计算资源来体现其算力。
3.具有实际的人工智能意义。具有人工智能意义的计算,例如神经网络运算,是人工智能基准测试程序相较于传统高性能计算机基准测试程序的重要区别,也是能够检测集群人工智能算力的核心所在。
目前,AIPerf在ImageNet数据集上训练神经网络来运行计算机视觉应用程序。在将来,AIPerf计划将自然语言处理等其他人工智能任务加入评测范围。
4.评测程序包含必要的多机通信。网络通信是人工智能计算集群设计主要指标之一,也是其庞大计算能力的重要组成部分。作为面向高性能计算集群的人工智能基准测试程序,AIPerf包括必要的多机通信,如任务的分发、结果的收集与多机训练,从而将网络通信性能作为最终性能的影响因素之一。
为了实现以上目标,需要设计完善的AIPerf机制。目前AIPerf主要流程包含5个步骤:
1.主节点持续分配计算任务(包含历史信息);
2.计算节点根据历史信息生成新的神经网络训练模型;
3.计算节点调用后端深度学习框架(MindSpore、Keras、Tensorflow)训练神经网络;
4.新模型训练完成后,工作节点返回新模型及其精度;主节点更新历史信息;
5.计算任务异步执行。
深圳鹏城实验室研制的基于ARM架构和华为加速处理器的鹏城云脑2,主机以194,527 Tops的AIPerf算力荣登榜首。其性能是排名第二的联泰集群Nvidia系统性能的12倍以上。
百万亿参数超大预训练模型的训练
当前,学术界形成了共识,模型规模与模型效果呈现正相关关系。模型参数达到千亿的大模型,已经能在美国SAT考试题目中,实现60%左右的正确率。
现有语言大模型已经达到了万亿甚至百万亿的规模。如美国的GTP是11亿参数(2018年),GTP2.0是15亿参数(2019年),GTP3.0是1.75万亿参数(2021年),GTP4.0是1.7万亿参数。国内的BaGuaLu是174万亿。因此,探索更大参数量模型的效果具有重要科学意义。预训练模型的计算结构的核心是Transformer模型,模型的计算主要集中在:嵌入层(Embedding)、注意力层 (Attention)、前馈网络 (FFN)。
Transformer的计算核心为矩阵乘法,因此我们可以利用并行训练技术来加速训练。随着模型规模扩大,训练数据增多,单机训练无法满足参数规模和数据吞吐的需求,并行训练成为大模型的训练“标配”。
比如在国产的新一代神威高性能计算机中,包含了96,000个节点、37,440,000个核心,以及互连网络。神威采用的是新一代体系结构芯片—神威26010pro,以及支持MPI通信的国产自主高速网络,契合了大规模预训练模型的需求。
我们团队在国产E级高性能计算机上训练了一个170万亿参数的超大规模预训练模型,模型参数与人脑中的突触数量相媲美。在训练这一超大规模预训练模型中,面临四个关键系统的挑战:一是如何选取高效并行策略;二是如何进行高效数据存储;三是如何选取合适数据精度;四是如何实现动态负载均衡。

挑战1:如何选取高效并行策略
不同的并行策略的通信需求和计算模式不同,比如数据并行、模型并行、流水并行、MoE并行。底层不同的网络拓扑结构会对性能有很大的影响,如何选择合适的并行策略组合是非常大的挑战。
挑战2:如何进行高效数据存储
以万亿参数的模型为例,如果模型精度是32位,模型的参数就有4T,模型的梯度也有4T,优化器的更新参数有8T,计算中间值也有8T。如果用V100训练这个模型,并且把这些数据存储下来,就需要768块V100。那么这些数据如何划分?不同的划分方式对底层的计算和通信也会产生不同的影响,即高效存储相关数据来支持高效训练非常有挑战性。
挑战3:如何选取合适数据精度
选择合适的数据精度能够有效提高计算性能,降低内存占用。越低精度选取,性能越好,但模型准确度越差,如何选择最优的混合精度策略非常有挑战性。
挑战4:如何实现动态负载均衡
MoE训练中,样本通过网关 (gate) 选取合适专家进行计算,存在负载不均衡问题,影响计算性能,受欢迎的专家会收到几百倍,甚至上千倍的输入数据。
针对上述挑战,我们团队提出相应的解决方案,实现在国产系统的高效并行训练——八卦炉:百万级预训练模型系统。
在上面的基础上,我们团队同时完善神威高性能计算机的基础软件库:实现高效算子库;完善 swTensor,支持混合精度算子优化深度学习框架;深度优化 swPyTorch、优化内存分配器等支持复杂模型;实现分层混合精度策略、支持负载均衡方法。我们团队训练的阿里巴巴图文数据集M6-Corpus,数据集总规模约2TB,包含科学、体育、政治、经济等各方面,同时将我们的工作开源成相应的分布式系统FASTMOE。
如何培养系统人才
算力非常重要,会使用算力的人才同样非常重要。那么,如何培养系统人才呢?
学好课程
两门理解计算机系统基本原理的基础课程。
一门是CMU(15-213):Introduction to Computer Systems教材,A Programmer’s Perspective中文版,深入理解计算机系统(其实只能算简单理解)介绍了程序表示、编译链接、内存层次、内存分配等基础知识,其中的实验有很多精华内容。
另一门是MIT(6.003):Computer System Engineering教材,Principles of Computer System Design介绍了计算机系统设计的复杂性,抽象、模块化等基本原理,主要以概念为主,实验比较简单。
两门构建操作系统和分布式系统模块的进阶课程。
一门是MIT(6.828):Operating System Engineering学习一个类似Unix的代码(xv6)实验——构建一个小操作系统(JOS),包括启动、内存管理、用户环境、抢占式多任务、文件系统、网络驱动等。
另一门是MIT(6.824):Distributed SystemsRPC,分布式一致性协议(Raft/Paxos),分布式事务,并发控制实验——实现MapReduce系统,分布式、可容错的KV存储系统等。
阅读优秀的开源代码和相关的论文
一是学习新的系统构建语言现代C++,Rust,Go,Scala等。
二是阅读优秀的开源代码,能为一些开源项目贡献代码,重复造一些轮子。
三是阅读相关的论文,确定感兴趣的方向,阅读相关的论文(SOSP,OSDI,Usenix ATC, EuroSys,SoCC等)确定要做的系统。
动手实践举例——系统类竞赛
第一个是国际大学生超算竞赛,可以5~6人组队参加任务。自行设计搭建计算集群(或使用云计算集群),对于给定的应用进行测试和优化,还包含面试、海报、论文复现、口头报告等环节。使用英语作为工作语言的三大比赛:ASC、ISC、SC。
第二个是“英特尔杯”全国并行应用挑战赛。
第三个是CCF CCSP 大学生计算机系统与程序设计竞赛。个人可以参赛,通过 CCF CSP 能力认证入围任务,算法题与系统题特点:12小时5题;系统题的得分与选手程序的运行时间相关,性能最高的取得满分。
参加科研项目
“MadFS分布式文件系统”“千万核可扩展全球大气动力学全隐式模拟”“非线性大地震模拟”“神图”图计算框架等。
人工智能算力是当前人工智能领域发展的关键。我们团队最近几年在AI算力基础设施的架构平衡设计,AI算力的评测方法,百万亿参数超大预训练模型的并行加速都做出了非常大的贡献。我国需要加快AI算力基础设施的构建,以及加快系统方面人才的培养。
编辑:黄飞
-
联想算力基础设施的“火种台”,让千行万企智能化不再凛冽2023-12-25 1924
-
DeepSeek推动AI算力需求:800G光模块的关键作用2025-03-25 1203
-
直播预告|玄铁 x Canonical:从本地推理到 AI 工厂,基于 RISC-V 的 AI 基础设施创新路径探讨2026-05-15 133
-
刚性转子动平衡设计与实验2009-03-13 6249
-
曙光将用5A定义新时代新要求 智算基础设施的核心价值2021-12-13 2138
-
算力基础设施关键技术2023-05-24 1185
-
余晓晖:推动算力基础设施高质量发展2023-12-20 1623
-
卫星通信序幕拉开,AI算力浪潮澎湃2024-01-03 1279
-
DPU技术赋能下一代AI算力基础设施2024-04-20 2750
-
《北京市算力基础设施建设实施方案(2024—2027年)》正式印发2024-05-17 1684
-
联想发布全栈算力基础设施新品2024-06-15 1710
-
企业AI算力租赁模式的好处2024-12-24 2240
-
RAKsmart智能算力架构:异构计算+低时延网络驱动企业AI训练范式升级2025-04-17 991
-
AIGC算力基础设施技术架构与行业实践2025-05-29 1251
-
轨道计算基础设施:太空光伏为太空AI算力供电的电源架构演进2026-01-27 1614
全部0条评论

快来发表一下你的评论吧 !
