

Sonicverse:用于训练同时能够看和听的家居智能体的多感官仿真平台
描述
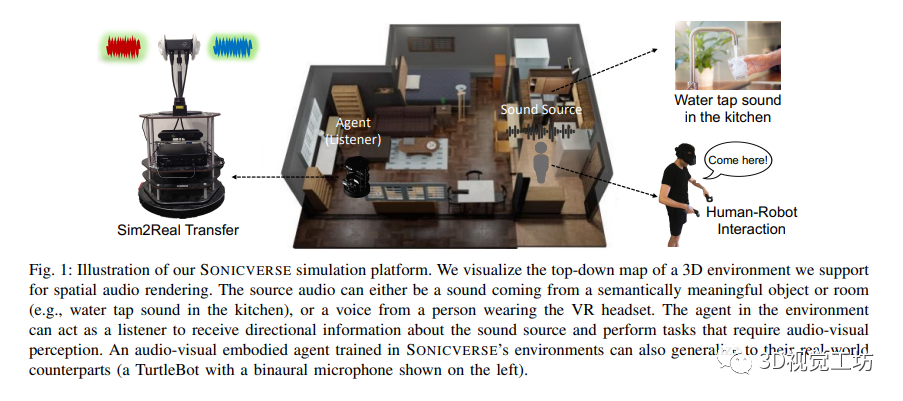
本文介绍了SONICVERSE,这是一个多感官模拟平台,用于训练既能看又能听的家用代理人。该平台在实时的3D环境中实现了逼真的连续音频渲染,并通过新的音频-视觉虚拟现实界面实现与代理人的交互。此外,针对语义音频-视觉导航任务,作者提出了一种新的多任务学习模型,并展示了SONICVERSE通过模拟到真实环境的迁移所达到的真实感。
1 前言
本文介绍了SONICVERSE,一个新的具备多感官功能的模拟平台,用于训练音频-视觉具身代理。该平台实现了实时的3D环境中连续音频渲染,通过使用完整的场景几何和材料属性达到了高保真度的空间音频渲染。同时,还引入了一个多任务学习框架,用于语义音频-视觉导航和占据地图预测,取得了最先进的结果。此外,本文还首次展示了在模拟中训练的音频-视觉导航代理可以成功部署到现实环境中。
作者的贡献有三个方面。
介绍了SONICVERSE,这是一个新的多感官模拟平台,实时模拟了3D环境中的连续音频渲染,为许多需要音频-视觉感知的具身化人工智能和人机交互任务提供了一个新的测试平台。
介绍了一个多任务学习框架,用于语义音频-视觉导航和占据地图预测,取得了最先进的结果。
首次展示了在模拟中训练的音频-视觉导航代理可以成功部署到现实环境中。
2 相关工作
本文介绍了具身AI模拟器和视听学习的相关研究。作者提出了SONICVERSE模拟器,它能够提供连续的3D空间音频渲染,并结合完整的场景几何和表面材料特性实现高度逼真性。作者的工作填补了现有视觉导航研究中缺乏音频的重要空白,并提供了一个新的测试平台来支持需要音视知觉的具身AI任务。通过音视导航任务的案例研究,作者展示了我们模拟器的有用性和逼真性。此外,作者的工作还提供了一个新的视觉和听觉学习的框架,可以应用于各种具身AI任务,包括音视导航、平面图重建、探索驱动好奇心等。
3 SONICVERSE模拟平台
本节介绍了SONICVERSE模拟平台,它是一个具备音视感知功能的具身AI模拟平台。该平台构建在iGibson 2.0之上,并使用开源的Resonance Audio SDK实现对音频的模拟。平台提供了音频模拟、3D环境和其他关键功能,为研究者开展音视知觉方面的具身AI研究提供了强大的工具和环境。
3.1. 声学模拟
声学模拟中的主要组成部分包括直接声音、动态遮挡、早期反射和晚期混响以及头部相关传递函数(HRTFs)。直接声音表示从源头到听者的未受环境阻碍或反射影响的声音,并随着距离的增加而衰减。动态遮挡通过遮挡节点衰减源头到听者的声音,并模拟现实世界的遮挡效果。早期反射和晚期混响是通过预模拟混响烘焙过程计算得到的,早期反射还考虑了听者与探测器位置的关系,并使用箱形近似房间的方法呈现。头部相关传递函数(HRTFs)用于模拟人类通过感知声音的时间和级别差异来定位声源。整个声学模拟过程可以实现逼真的空间音频渲染和实时性能。
3.2. 三维环境
SONICVERSE支持Matterport3D和iGibson两个3D场景数据集,其中Matterport3D包含85个大型的现实世界室内环境场景,而iGibson包含15个具有家具和可动物体的现实世界家庭场景。对于Matterport3D场景,作者使用整个场景进行混响烘焙,并通过将语义网格类别映射到Resonance Audio的材料类型来确定房间表面的声学特性。对于iGibson场景,由于物体可移动,作者只使用场景的静态骨架进行混响烘焙,并对墙壁、天花板、窗户和地板进行相应的映射。
3.3. 主要特点
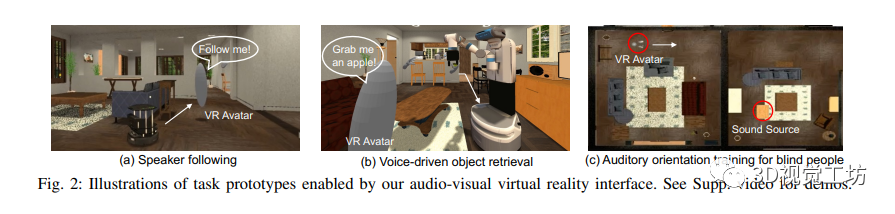
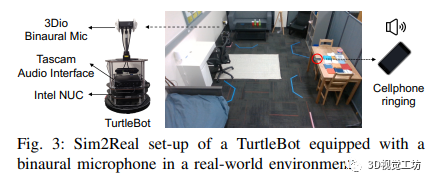
SONICVERSE是一个具备音频-视觉虚拟现实界面和Sim2Real转换能力的模拟器。其音频-视觉虚拟现实界面基于iGibson 2.0和OpenVR,能够将戴着VR头显的人作为音频-视觉化身,并实现人与代理之间的音频-视觉交互任务。具体的任务原型包括说话人跟随、语音驱动的物体检索和盲人听觉定位训练。同时,SONICVERSE使用TurtleBot作为具体化代理,通过3Dio FS双耳麦克风和Tascam音频接口实现音频模拟,并借助Asus XTION PRO RGBD相机和Intel NUC进行视频捕获和处理。相比于SoundSpaces和ThreeDWorld,SONICVERSE的模拟器通过将声音附加到场景中的动态物体实现音频和视觉模拟的整合,并支持动态遮挡和连续空间的音频渲染。此外,SONICVERSE利用完整的场景几何和自动映射的材质进行混音烘焙,实现了更高的逼真度。虽然与ThreeDWorld不同,SONICVERSE不直接模拟物体碰撞声音,但支持将现有的多感官物体资源与预计算的音频模拟相结合使用。通过上述优势和功能,SONICVERSE为音频-视觉模拟和实际环境的转换提供了有效的解决方案。
4 在SonicVerse中训练音视化具象导航智能体
SonicVerse支持许多需要音视感知的具象人工智能任务。作者以具有挑战性的语义音视导航任务作为案例研究,以展示作者模拟器的实用性。这是音频目标导航的更具挑战性的版本,其中智能体必须定位一个持续发出声音的来源。在语义音视导航中,物体会发出与其现实世界对应物相符的声音(例如,门会发出咯吱的声音),而这些声音只会持续很短的一段时间。因此,智能体必须能够在声音停止发出后更好地定位声源,可能通过利用已学习的关于哪些物体可以发出某些声音的知识。
任务定义:在这个任务中,智能体需要通过听到物体发出的声音,在一个未知且未映射的环境中导航到一个特定的有语义意义的物体。声音可以是非周期性的、不连续的,并且长度各异。为了到达目标物体,智能体必须推理出声音物体的语义类别以及音频感知中的双耳空间线索。作者在实验中使用一台TurtleBot作为智能体。使用的15个有语义意义的声音,包括水槽、靠垫、电视、淋浴等声音。每个声音都与特定的目标类别进行一对一映射。为了被认为是成功,智能体需要在声音停止后仍能定位到目标位置,并导航到发出声音的特定目标物体,而不是类别内的其他物体。
行动和观测空间:与任务的现有规范相反,该规范使用固定步长的离散平移和旋转,作者使用连续动作空间来表示机器人轮轴速度。这使得任务设定更加现实和具有挑战性,并且更适用于真实世界的机器人环境。智能体的观测包括RGB图像、深度图、两只耳朵接收到的双声道音频谱图、碰撞传感器输入以及与起始位置相关的当前姿态。
回合规范与成功准则:每个回合由以下内容定义:场景、智能体的起始位置和方向、目标类别、类别内的一个目标物体以及离目标物体位置一米范围内的八个位置,这些位置被视为定义物体边界的附近位置。当智能体到达这九个终止位置之一时,被认为满足成功准则:八个靠近目标物体的位置和原始目标物体位置。达到终点的距离容差为0.36m,这是真实TurtleBot的宽度。
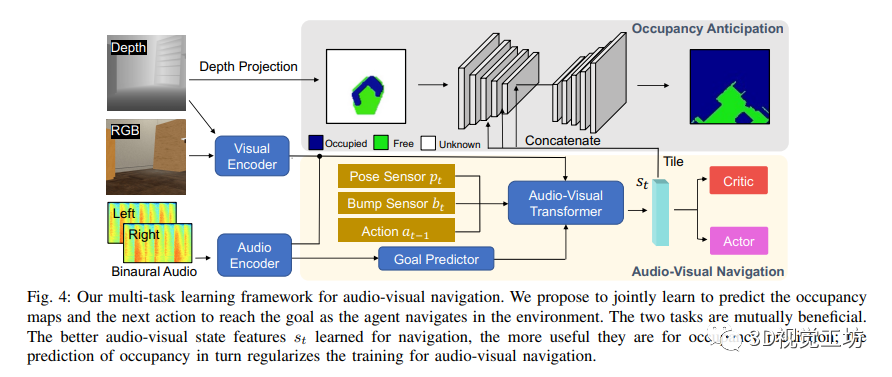
音视导航模型:作者提出了一个多任务学习框架,同时学习语义音视导航和占据地图预测。在每个时间步t,智能体接收到中心视野的视觉观测,包括RGB图像和深度图,以及代表智能体左右耳朵的双声道音频,表示为双声道音频谱图。作者分别从视觉编码器和音频编码器中提取视觉和音频特征。
对于语义音视导航,作者采用了来自SAVi的基本架构,该架构改编自场景记忆变换网络。它主要由两个组件组成:1) Goal Predictor,它以音频特征和智能体当前姿态作为输入,预测一个包含有关声源位置和声音物体的对象类别信息的目标描述符;2) Audio-Visual Transformer,它使用一个记忆模块对智能体的观测进行编码,并使用自注意机制来推理到目前为止看到的3D环境。变换器的解码器使用目标预测器的输出和内存中编码的观测,预测状态特征,然后将其馈送给一个用于预测下一步动作的actor-critic网络。使用中的分布式分散的邻近策略优化两阶段训练范式。
对于占据地图预测,作者将其规定为逐像素分类任务。将自中心自我位置图p ∈ V ×V表示为垂直俯视的地图,该地图由相机前方V×V个单元格的局部区域组成,该区域表示一个5m × 5m的区域。每个单元格中的值表示该单元格被占用的概率。通过使用对应室内环境的3D网格获得地面实际局部占用。使用U-Net进行占据地图预测。编码器的输入是从深度投影中获得的局部占用地图,通过在深度和相机内参的点云上设置高度阈值来获得。然后,复制和平铺状态特征向量以匹配特征图的空间维度,并在后3层编码器的通道维度上进行连接。解码器然后将融合的特征图作为输入,并通过一系列上卷积层输出预测的局部占用地图,包括可见和不可见的单元格。作者使用二元交叉熵损失训练占据预测网络。
作者的占据地图预测模块与机器人技术和具体视觉导航中建立世界的连续表示的前期方法相似。然而,作者联合学习占据预测和音视导航,有新的见解表明准确预测占据地图有助于学习更好的音视特征,从而有助于导航。
5 实验
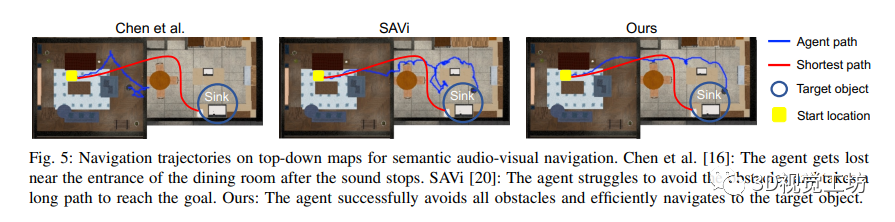
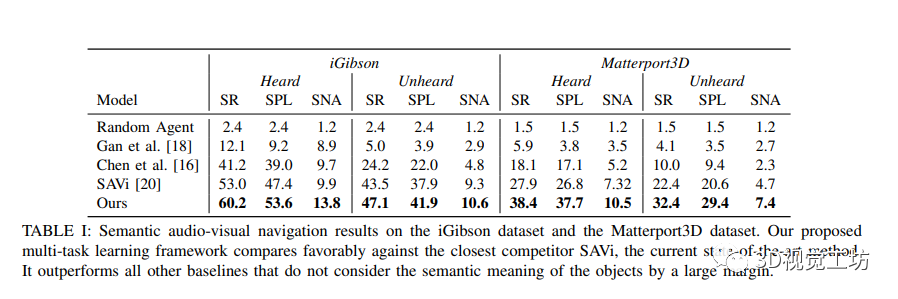
该研究展示了在音频视觉导航领域的实验结果,并将在SONICVERSE模拟器中训练的代理转移到真实世界中。通过与多个基准方法进行比较,作者证明了他们的模型在语义音频视觉导航中的出色性能。作者还使用不同的评估指标对模型进行了评估,并比较了不同数据集上的性能。结果显示,作者的多任务学习框架在所有指标上均优于现有的方法。此外,通过在俯视地图上显示导航轨迹,并与基准方法进行对比,作者进一步证明了他们的模型在感知障碍物和声音、并高效导航到目标物体方面的能力。同时,该研究还展示了他们的模拟器的逼真性,通过将在模拟中训练的导航代理成功转移到真实世界环境中。三个关键步骤(记录机器人噪音、随机变化源声音的增益、校准深度相机)被证明可以减少虚实差距,从而实现成功的策略转移。总体而言,该研究为音频视觉导航领域的研究提供了有价值的见解,并提供了促进虚实转换的有效方法。
5 总结
本研究介绍了SONICVERSE,一个用于训练同时能够看和听的家居智能体的多感官仿真平台。该平台能够实时渲染3D环境中的连续音频,并支持虚拟现实中的音频流传输,为需要音频视觉感知的体验式人工智能任务提供了新的测试平台。在音频视觉导航任务上,研究者提出了一种新的语义音频视觉导航模型,其性能优于以前的方法。此外,他们还成功地将在模拟中训练的智能体应用到真实世界环境中。研究者对SONICVERSE带来的体验式多感官学习研究表示期待。
-
数字孪生智能体平台:可视化、仿真与自主协同的演进逻辑2026-06-02 53
-
正式上线:MotoSim智能电机仿真平台2025-07-03 1983
-
仿真平台Device Studio应用实例2023-07-23 1910
-
多尺度材料设计与仿真平台Device Studio介绍2023-06-12 4948
-
自动驾驶仿真平台概述2023-06-02 698
-
Adams—系统级多体动力学仿真平台2022-05-13 1871
-
什么是全数字仿真平台2021-12-17 1442
-
基于STM32-XPC仿真平台的构架 精选资料推荐2021-08-18 1817
-
Xilinx:如何使用Zynq仿真平台2019-01-03 5904
-
电磁环境仿真平台VREM EmXpert介绍2017-06-14 5137
-
智能车仿真平台2017-01-05 5657
-
Veloce Apps硬件仿真平台2016-04-15 3526
-
ADS无线协同仿真平台2011-10-11 1501
-
三维虚拟仿真平台,三维虚拟仿真平台是什么意思2010-04-10 6896
全部0条评论

快来发表一下你的评论吧 !
