

机器人主流抓取估计方法盘点
机器人
描述
据抓取的表示,应用场合等可以将机器人抓取分为2D平面抓取和6-DoF空间抓取,各自又包含很多方法,下面一一介绍。
1、2D 平面抓取:
适合工业抓取,场景是机械臂竖直向下,从单个角度去抓,抓取通常由平面内的抓取四边形,以及平面内的旋转角度表示(Oriented 2D rectangle):
根据使用的数据RGB/Depth不同,又可以分为以下三类:基于RGB,基于RGB+Depth,和基于Depth。
1.1 基于RGB的抓取估计
数据集包括:Cornell数据集(http://pr.cs.cornell.edu/grasping/rect_data/data.php)和Jacquard数据集https://jacquard.liris.cnrs.fr/,为 人工构建;
基于以上的数据集,出现了很多方法,代表作是2014-Deep Learing for Detecting Robotic Grasps,2014-Real-Time Grasp Detection Using Convolutional Neural Networks,2018-Real-world Multi-object, Multi-grasp Detection等,首先生成大量抓取框候选,再进一步优化得到最终抓取;
亚马逊论文2015-Supersizing Self-supervision: Learning to Grasp from 50K Tries and 700 Robot Hours使用机器自动采集训练集,训练了一个平面抓取估计算法,其数据集如下:

1.2基于RGB+Depth的抓取估计
这类方法本质上与与RGB方法一致,只是多了Depth通道的信息,代表方法有2017-Robotic Grasp Detection using Deep Convolutional Neural Networks等。
1.3 基于Depth的抓取估计
代表性方法是2017-Dex-Nex 2.0 Deep Learning to Plan Robust Grasps with Synthetic Point Clouds and Analytic Grasp Metrics,https://berkeleyautomation.github.io/dex-net/,该方法自己构建基于深度图的抓取质量数据集,训练得到抓取质量评估网络。在线使用时,采集当前视角下的深度图,分割目标物体对应的深度图,在深度图上生成上百个候选抓取位置,得到上百个抓取位置下的深度图,每一个都得到一个抓取质量,选择质量最高的进行抓取。其数据集和算法流程如下图所示。
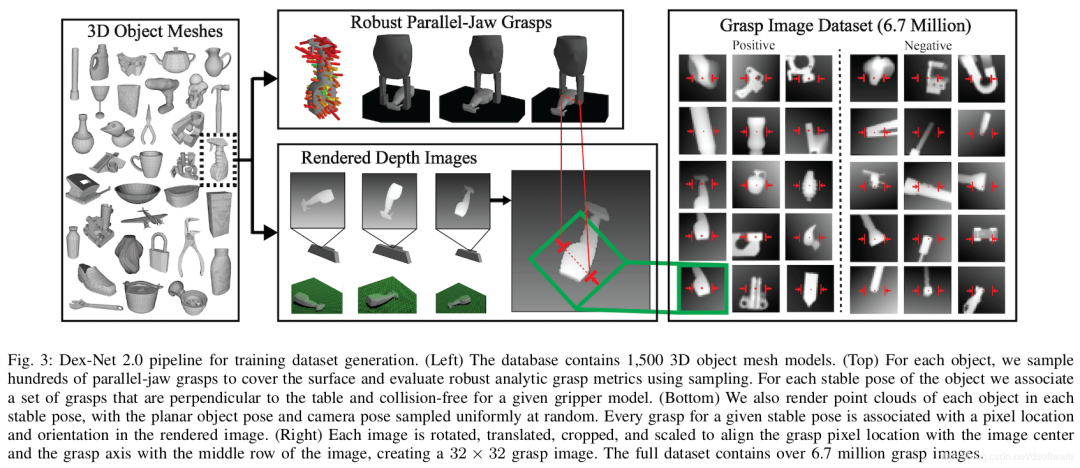
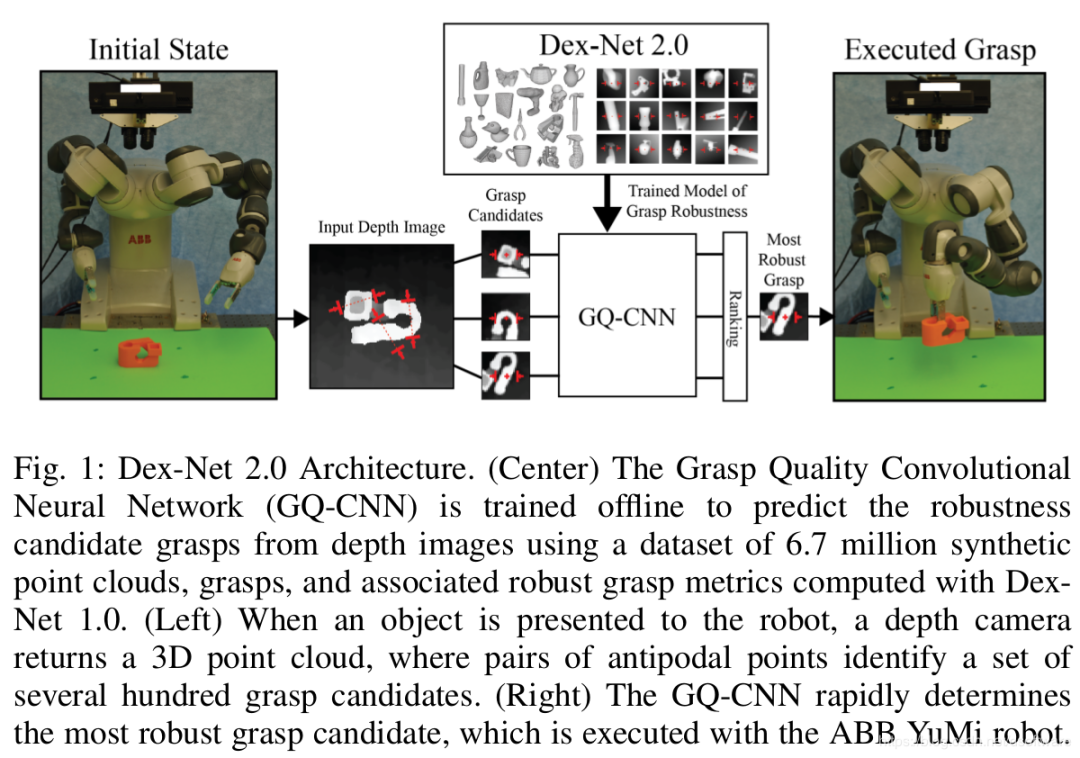
1.4 总结
这类方法适合固定场合下,从单个角度进行抓取。训练数据生成时,每个物体在平面内的放置情况是有概率分布的;而如果扩展到任意视角下,很多视角下的数据在训练集中不存在;任意角度下,网络本身也不一定能够学习到适合抓取的位置。因此,该类方法不适合从任意角度进行抓取。
2、6DoF空间抓取:
平面抓取首先于只能从单个角度去抓,如果想更加灵活,需要获取6DoF的抓取姿态,如下图。
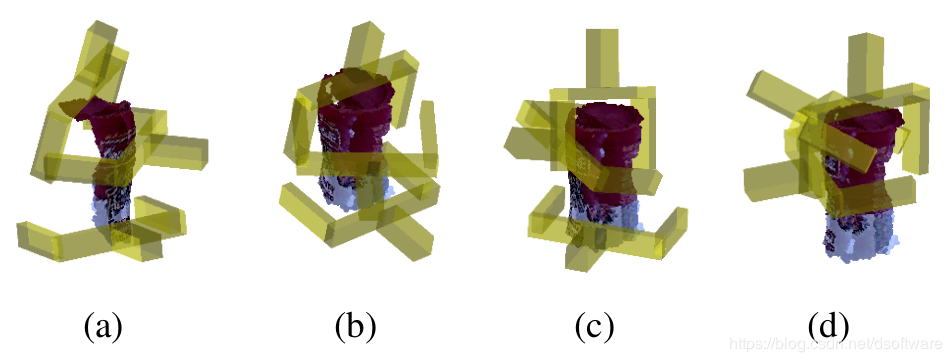
2.1 代表性方法
近年来的代表性方法包括2017-Grasp Pose Detection in Point Clouds,2018-PointNetGPD:Detecting Grasp Configurations from Point Sets,2019-6-Dof GraspNet:Variational Grasp Generation for Object Manipulation等,都包含两大模块:候选抓取位置的筛选,以及抓取质量的评估。这类方法思路与Dex-Net2.0相同,但是作用在3D空间。
2017-GPD使用传统方法进行候选抓取位置的筛选,需要满足抓取器不与物体碰撞,且抓取器内部至少存在一个点;之后基于三个角度下Depth图像基于CNN网络等进行抓取质量估计,如下图所示。
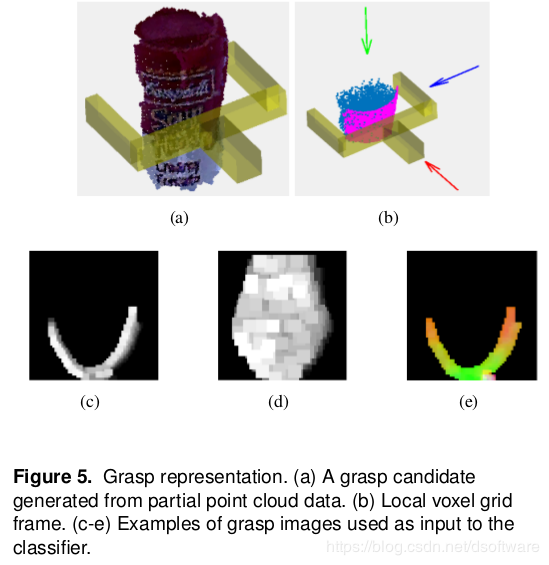
2018-PointNetGPD (Hamberger University, Jianwei Zhang)也使用传统方法筛选候选抓取位置,之后不使用深度图评估抓取质量,而是使用抓取器内部的点云,使用3D神经网络PointNet进行抓取质量估计,如下图所示。

2019-6-Dof GraspNet (Nvidia),对两大模块进行了改进,首先使用大规模虚拟数据进行候选抓取位置的Encoder,这样给定单视角下的点云,能够Decoder出少量质量很高的候选抓取位置;其次,不同于PointNetGPD只对抓取器内部的点云进行抓取质量评估,其对抓取器连同单视角点云,一起使用PointNet++网络评估抓取质量;最后还对最终抓取位置进行了优化。其框架如下图。
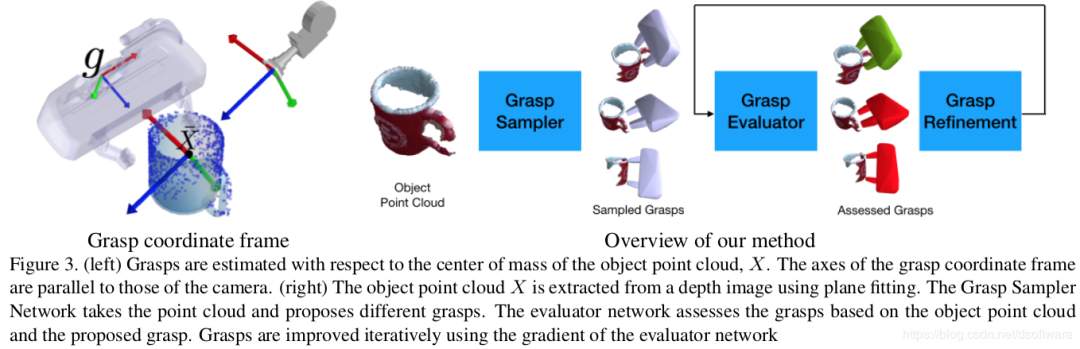
2.2 总结
进行空间6-Dof抓取,需要进行实例分割,确保点云准确,噪声少,否则影响效果;训练可在虚拟环境中进行,只要虚拟环境中的3D模型精确,则不使用domain adaption也能在真实环境下得到很好的结果。
该类方法适合任意角度的抓取,然而该类方法的弊端是,尽管使用了Encoder和Decoder的方式生成候选抓取位置,但是单个角度下获得的数据毕竟有限,而如果能够对物体进行补全,则使用传统方法生成候选抓取位置也能够得到很好的结果。这类方法在下一章介绍。
3、形状补全:
3.1代表方法
这类方法也有很多的尝试,代表方法主要有:2017-Shape Completion Enabled Robotic Grasping,2019-Multi-Modal Geometric Learning for Grasping and Manipulation,2019-Data-Efficient Learning for Sim-to-Real Robotic Grasping using Deep Point Cloud Prediction Networks,2019-kPAM-SC: Generalizable Manipulation Planning using KeyPoint Affordance and Shape Completion等。
2017-Shape Completion Enabled Robotic Grasping是代表性方法,使用3D CNN进行shape completion,其框图如下。
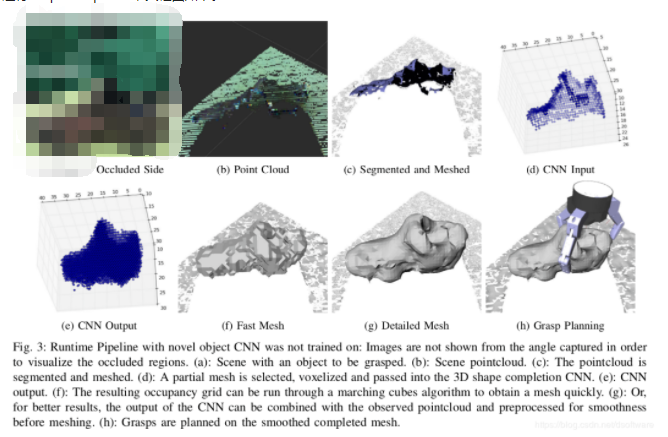
2019-Multi-Modal Geometric Learning for Grasping and Manipulation, (Peter Allen, Columbia University),根据触觉得到对侧的点信息,辅助进行修补。

2019-Data-Efficient Learning for Sim-to-Real Robotic Grasping using Deep Point Cloud Prediction Networks(Google Brain and X)使用RGB+Depth作为输入的网络结构,进行形状补全;Video demos can be accessed via https://sites.google.com/site/shapeawaresimtoreal/
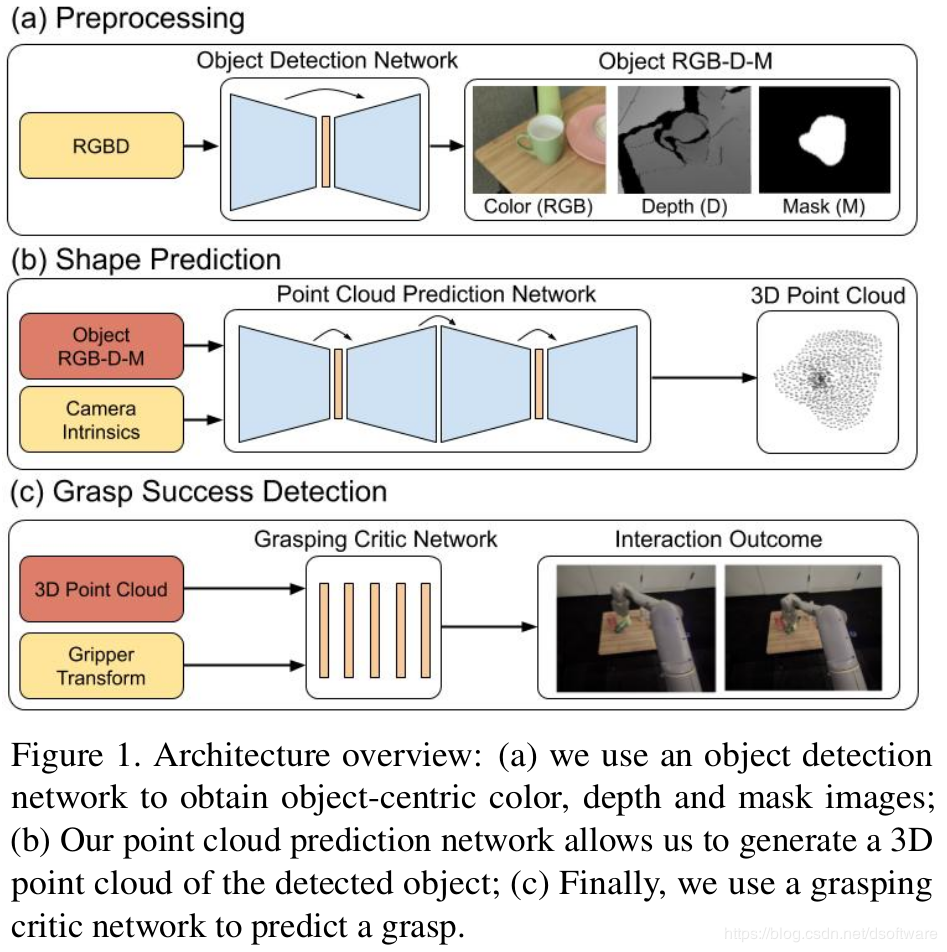
2019-kPAM-SC: Generalizable Manipulation Planning using KeyPoint Affordance and Shape Completion (MIT) 使用关键点以及同一类型的3D模型辅助进行形状补全,Video demos can be accessed via https://sites.google.com/view/generalizable-manipulation/

3.2 总结
这类方法能够对一类相似的形状得到不错的修补结果,无法做到任意通用;但如果能够对一类物体进行了较好的修补,则进行候选抓取位置估计,以及抓取质量评价都可以使用传统方法。
4、人形抓手
以上方法针对的都是平行两指抓取器,而当前绝大多数方法,都没有考虑人形抓手,因为其自由度太高了。做不到任意抓取以及通用,然而针对少量物体,或者一类物体,可以得到较好的结果。
4.1代表方法
2019-Generating Grasp Poses for a High-DOF Gripper Using Neural Networks(Xu Kai, NUDT and University of Maryland at College Park):
针对25DoF的手形抓取器,依赖完整物体体素模型,训练集使用GraspIt!生成,如下图,之后使用神经网络训练模型得到抓取姿态,其框架如下图。
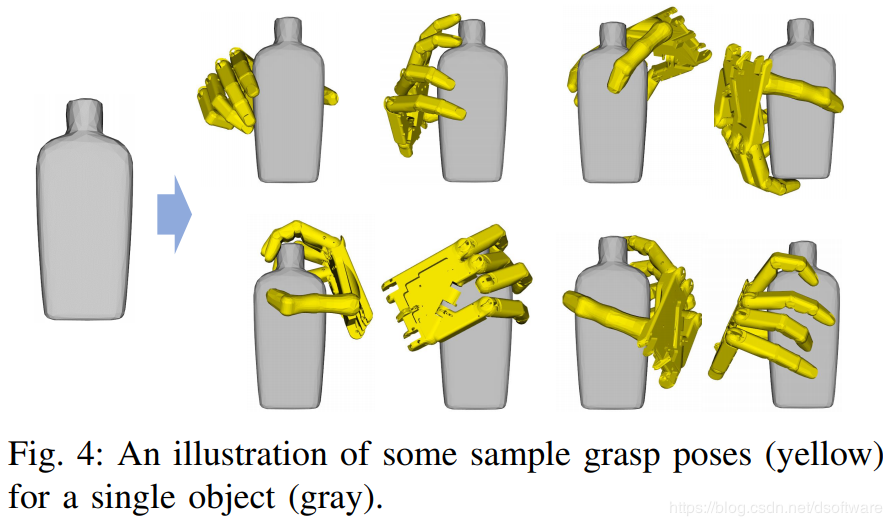
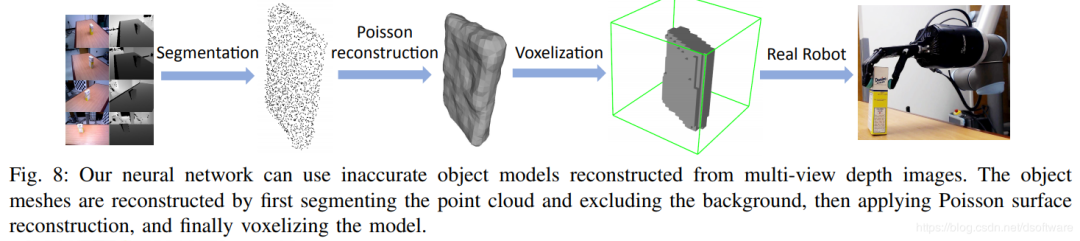
4.2 总结
使用人形抓手进行通用抓取太难了,现阶段实现不了。可以针对特定一类物体,实现类内的通用抓取。
编辑:黄飞
-
机器人主控核心板米尔RK3576 + ROS2,NPU加速实现目标跟随与机械臂抓取2026-04-10 303
-
复合机器人抓取精度的影响因素及提升策略2025-04-12 1386
-
基于视觉的机器人抓取系统设计2023-08-19 3299
-
人形机器人或将成为未来机器人主流2023-07-08 1859
-
浅谈机器人视觉抓取的目的2023-03-30 1213
-
基于视觉的机器人抓取系统2022-05-07 3928
-
乌贼的机器人和鱿鱼机器人主要区别在哪?2020-10-11 3214
-
dfrobot蓝牙四驱机器人主控器Arduino 兼容简介2020-01-03 2357
-
【MYD-CZU3EG开发板试用申请】基于机器视觉的工业机器人抓取工作站2019-09-18 2114
-
软体机器人学习问题探讨2019-08-12 4764
-
机器人主流的导航方法有哪些?2019-08-05 11908
-
澳洲科学家研发出一种新方法 解决机器人抓取难题2019-01-30 1176
-
RM机器人主控系统程序下载2018-04-18 983
-
机器人抓取技术原理分析2017-09-20 2224
全部0条评论

快来发表一下你的评论吧 !
