

Python中的默认编码
描述
####1. Python源代码文件的执行过程
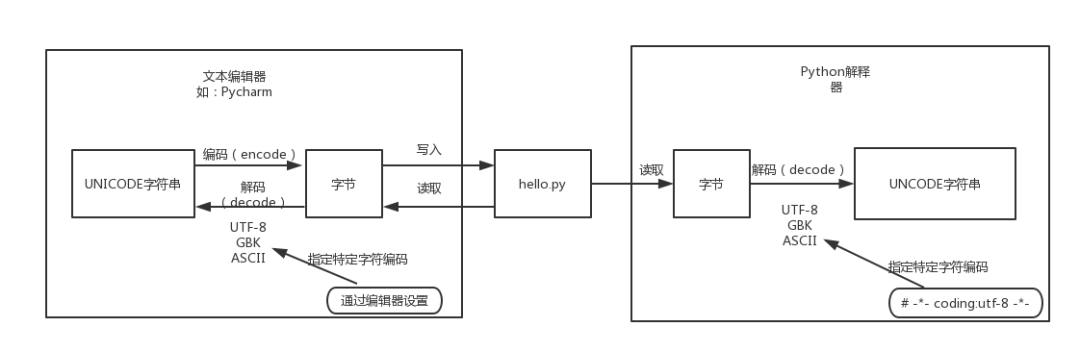
我们都知道,磁盘上的文件都是以二进制格式存放的,其中文本文件都是以某种特定编码的字节形式存放的。对于程序源代码文件的字符编码是由编辑器指定的,比如我们使用Pycharm来编写Python程序时会指定工程编码和文件编码为UTF-8,那么Python代码被保存到磁盘时就会被转换为UTF-8编码对应的字节(encode过程)后写入磁盘。当执行Python代码文件中的代码时,Python解释器在读取Python代码文件中的字节串之后,需要将其转换为UNICODE字符串(decode过程)之后才执行后续操作。
上面已经解释过,这个转换过程(decode,解码)需要我们指定文件中保存的字节使用的字符编码是什么,才能知道这些字节在UNICODE这张万国码和统一码中找到其对应的代码点是什么。这里指定字符编码的方式大家都很熟悉,如下所示:
# -*- coding:utf-8 -*-
2. 默认编码
那么,如果我们没有在代码文件开始的部分指定字符编码,Python解释器就会使用哪种字符编码把从代码文件中读取到的字节转换为UNICODE代码点呢?就像我们配置某些软件时,有很多默认选项一样,需要在Python解释器内部设置默认的字符编码来解决这个问题,这就是文章开头所说的“默认编码”。因此大家所说的Python中文字符问题就可以总结为一句话: 当无法通过默认的字符编码对字节进行转换时,就会出现解码错误(UnicodeEncodeError) 。
Python2和Python3的解释器使用的默认编码是不一样的,我们可以通过sys.getdefaultencoding()来获取默认编码:
> > > # Python2
> > > import sys
> > > sys.getdefaultencoding()
'ascii'
> > > # Python3
> > > import sys
> > > sys.getdefaultencoding()
'utf-8'
因此,对于Python2来讲,Python解释器在读取到中文字符的字节码尝试解码操作时,会先查看当前代码文件头部是否有指明当前代码文件中保存的字节码对应的字符编码是什么。如果没有指定则使用默认字符编码"ASCII"进行解码导致解码失败,导致如下错误:
SyntaxError: Non-ASCII character '\\xc4' in file xxx.py on line 11, but no encoding declared; see http://python.org/dev/peps/pep-0263/ for details
对于Python3来讲,执行过程是一样的,只是Python3的解释器以"UTF-8"作为默认编码,但是这并不表示可以完全兼容中文问题。比如我们在Windows上进行开发时,Python工程及代码文件都使用的是默认的GBK编码,也就是说Python代码文件是被转换成GBK格式的字节码保存到磁盘中的。Python3的解释器执行该代码文件时,试图用UTF-8进行解码操作时,同样会解码失败,导致如下错误:
SyntaxError: Non-UTF-8 code starting with '\\xc4' in file xxx.py on line 11, but no encoding declared; see http://python.org/dev/peps/pep-0263/ for details
3. 最佳实践
- 创建一个工程之后先确认该工程的字符编码是否已经设置为UTF-8
- 为了兼容Python2和Python3,在代码头部声明字符编码:
-*- coding:utf-8 -*-
-
查看python安装路径的方法2023-11-29 14366
-
python中如何保存文件2023-11-24 2498
-
mysql数据库默认字符编码是什么2023-11-16 2612
-
Python编码与解码2023-07-05 1851
-
如何在Ubuntu中安装IDLE Python IDE2023-04-10 1652
-
Python中最基本的10个内容2020-12-11 3470
-
Python 函数默认返回None的原因2020-08-21 3441
-
科普:Python函数默认返回 None 的原因2020-08-17 3101
-
Python的编码规范是怎么样的2020-08-12 668
-
python默认的解释器并不支持tab补全2019-07-11 1078
-
从RHEL 8 Beta开始不再默认系统Python版本2018-12-30 2647
-
从5个方面来解析计算机中的字符编码概念2018-01-16 8878
-
Python中文乱码怎么处理?python中文乱码解决办法2017-12-27 4370
全部0条评论

快来发表一下你的评论吧 !
