

Python字符编码转换
描述
UNICODE字符串可以与任意字符编码的字节进行相互转换,如图:
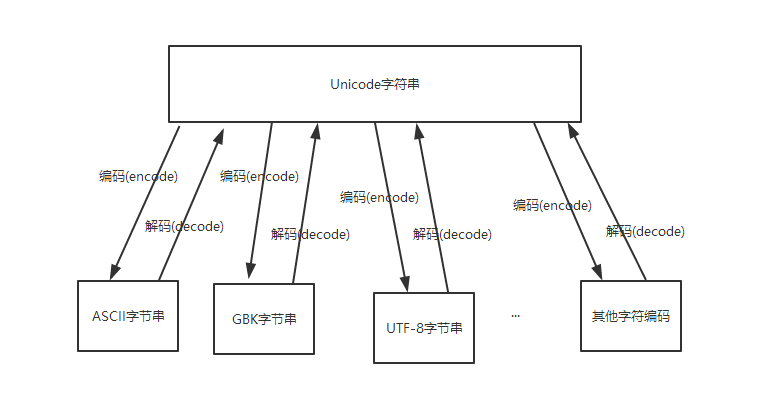
那么大家很容易想到一个问题,就是不同的字符编码的字节可以通过Unicode相互转换吗?答案是肯定的。
Python2中的字符串进行字符编码转换过程是:
字节串-->decode('原来的字符编码')-->Unicode字符串-->encode('新的字符编码')-->字节串
#!/usr/bin/env python
# -*- coding:utf-8 -*-
utf_8_a = '我爱中国'
gbk_a = utf_8_a.decode('utf-8').encode('gbk')
print(gbk_a.decode('gbk'))
输出结果:
我爱中国
Python3中定义的字符串默认就是unicode,因此不需要先解码,可以直接编码成新的字符编码:
字符串-->encode('新的字符编码')-->字节串
#!/usr/bin/env python
# -*- coding:utf-8 -*-
utf_8_a = '我爱中国'
gbk_a = utf_8_a.encode('gbk')
print(gbk_a.decode('gbk'))
输出结果:
我爱中国
最后需要说明的是,Unicode不是有道词典,也不是google翻译器,它并不能把一个中文翻译成一个英文。正确的字符编码的转换过程只是把同一个字符的字节表现形式改变了,而字符本身的符号是不应该发生变化的,因此并不是所有的字符编码之间的转换都是有意义的。怎么理解这句话呢?比如GBK编码的“中国”转成UTF-8字符编码后,仅仅是由4个字节变成了6个字节来表示,但其字符表现形式还应该是“中国”,而不应该变成“你好”或者“China”。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
如何解决Python爬虫中文乱码问题?Python爬虫中文乱码的解决方法2024-01-12 3963
-
mysql数据库默认字符编码是什么2023-11-16 2598
-
Python字符与字节2023-07-05 1836
-
python字符串有哪些特定方法2023-02-23 1993
-
C++字符编码转换的基本方法2022-09-20 2592
-
2.2 python字符串类型2022-02-17 2894
-
Python字符数统计函数程序2021-05-25 787
-
C++中字符编码的转换2020-10-15 2950
-
Python字符的实例详细说明2020-10-14 1745
-
Python转义字符使用总结资料免费下载2019-01-17 1096
-
从5个方面来解析计算机中的字符编码概念2018-01-16 8866
-
字符集与字符集编码详解2017-09-12 793
全部0条评论

快来发表一下你的评论吧 !
