

联合学习在传统机器学习方法中的应用
电子说
描述
在大数据和分布式计算时代,传统的机器学习方法面临着一个重大挑战:当数据分散在多个设备或竖井中时,如何协同训练模型。这就是联合学习发挥作用的地方,它提供了一个很有前途的解决方案,将模型训练与直接访问原始训练数据脱钩。
联合学习最初旨在实现去中心化数据上的协作深度学习,其关键优势之一是其通信效率。这种相同的范式可以应用于传统的 ML 方法,如线性回归、 SVM 、 k-means 聚类,以及基于树的方法,如随机森林和 boosting 。
开发传统 ML 方法的联合学习变体需要在几个层面上进行仔细考虑:
算法级别:您必须回答关键问题,例如客户端应该与服务器共享哪些信息,服务器应该如何聚合收集的信息,以及客户端应该如何处理从服务器接收的全局聚合模型更新。
实施级别:探索可用的 API 并利用它们来创建与算法公式一致的联邦管道是至关重要的。
值得注意的是联邦的和分布式的与深度学习相比,传统方法的机器学习可能不那么独特。对于某些算法和实现,这些术语可以是等效的。
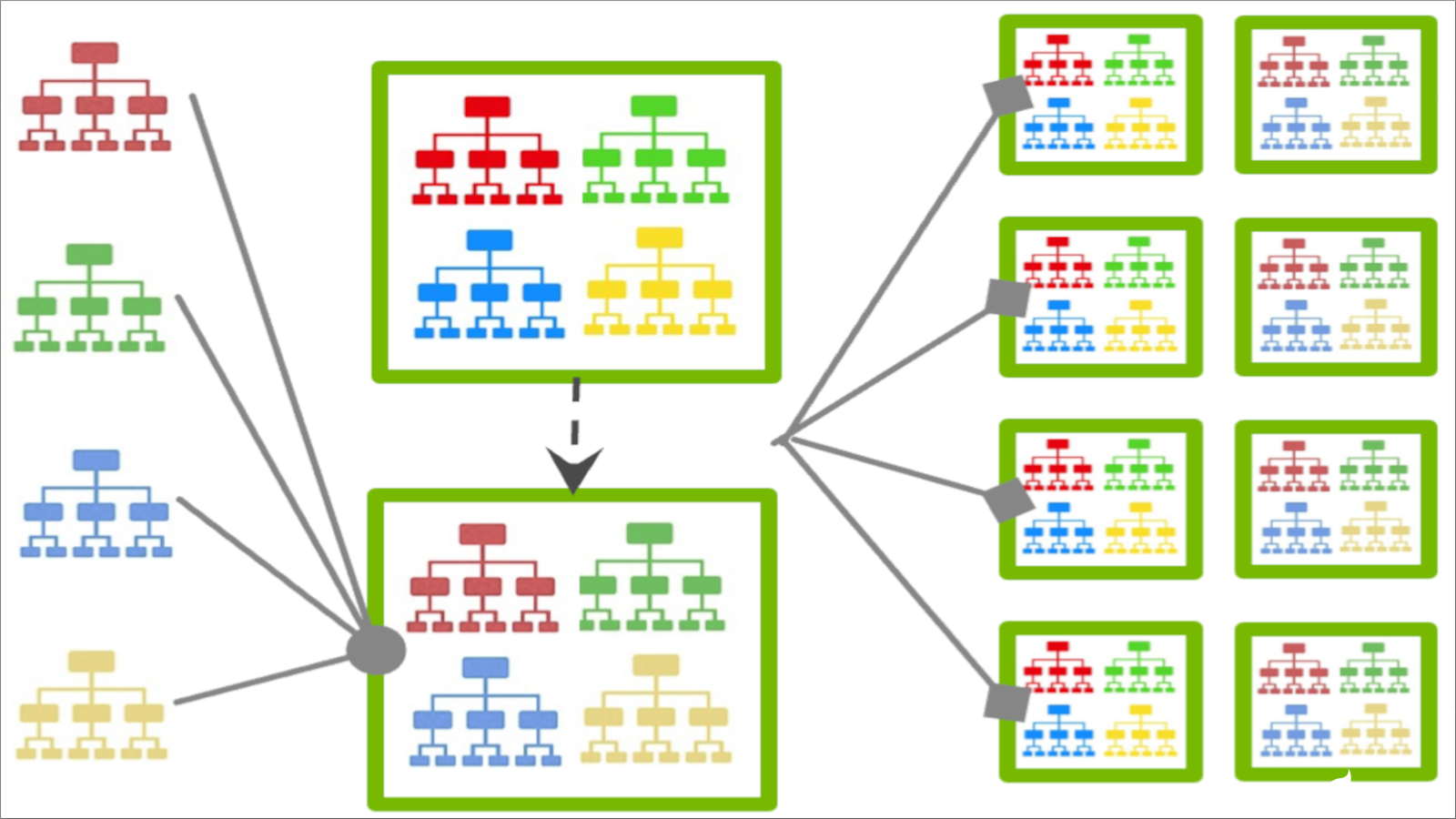
图 1 。对基于联邦树的 XGBoost
在图 1 中,每个客户端构建一个唯一的增强树,该树由服务器聚合为树的集合,然后重新分发给客户端进行进一步的训练。
要开始使用显示此方法的特定示例,请考虑K-Means聚类示例。在这里,我们采用了Mini-Batch K-Means聚类中定义的方案,并将每一轮联合学习公式化如下:
本地培训:从全局中心开始,每个客户端都用自己的数据训练一个本地的 MiniBatchKMeans 模型。
全局聚合:服务器收集集群中心,统计来自所有客户端的信息,通过将每个客户端的结果视为小批量来聚合这些信息,并更新全局中心和每个中心的计数。
对于中心初始化,在第一轮中,每个客户端使用 k-means ++方法生成其初始中心。然后,服务器收集所有初始中心,并执行一轮 k 均值以生成初始全局中心。
从制定到实施
将联邦范式应用于传统的机器学习方法虽然说起来容易,但做起来却很困难。NVIDIA 新发布的白皮书 《联合传统机器学习算法》 提供了许多详细的示例,以展示如何制定和实现这些算法。
我们展示了如何使用流行的库,如scikit-learn和XGBoost,将联邦线性模型、k-means聚类、非线性SVM、随机森林和XGBoost应用于协作学习。
总之,联合机器学习为在去中心化数据上协同训练模型提供了一种令人信服的方法。虽然通信成本可能不再是传统机器学习算法的主要约束,但要充分利用联合学习的好处,仍然需要仔细制定和实施。
-
【卡酷机器人】——基础学习方法2015-01-09 8953
-
模拟电子电路的学习方法2009-08-07 1191
-
ZigBee 简介和学习方法2016-04-15 731
-
深度解析机器学习三类学习方法2018-05-07 15258
-
如何学好机器学习?机器学习的学习方法4个关键点整理概述2018-09-24 7154
-
机器学习入门宝典《统计学习方法》的介绍2018-11-25 5739
-
面向人工智能的机器学习方法体系总结2018-12-17 4351
-
区块链数据集有怎样的机器学习方法2019-11-26 1373
-
机器学习方法迁移学习的发展和研究资料说明2020-07-17 1288
-
深度讨论集成学习方法,解决AI实践难题2020-08-16 1294
-
运用多种机器学习方法比较短文本分类处理过程与结果差别2020-11-02 6475
-
水声被动定位中的机器学习方法研究进展综述2021-12-24 1214
-
基于图嵌入的兵棋联合作战态势实体知识表示学习方法2022-01-11 1466
-
深度学习中的无监督学习方法综述2024-07-09 3265
-
传统机器学习方法和应用指导2024-12-30 2539
全部0条评论

快来发表一下你的评论吧 !
