

利用深度学习模型最大限度地提高外显子组测序分析的准确性
电子说
描述
人类外显子组是理解和治疗遗传疾病的关键。尽管外显子组只占人类基因组的 1% 多一点,但它也包含大约85% 的已知变异具有显着的疾病相关突变。这就是为什么涉及这些区域的提取和测序的全外显子组测序在临床研究和实践中很受欢迎,其中优化准确性、运行时间和成本很重要。
这篇文章展示了 NVIDIA Parabricks,一套用于高通量数据的加速基因组分析应用程序可以用于外显子组分析。 NVIDIA Parabricks 显著降低了运行时间和分析成本,同时最大限度地提高了变体调用的准确性。整个外显子组测序数据分析可以在 range of GPUs可在本地和每个主要的云提供商中使用。
利用深度学习模型最大限度地提高外显子组测序分析的准确性
UK Biobank,是世界上最全面的公开可用生物医学数据资源,为 47 万名参与者提供外显子组数据,所有参与者都按 Regeneron Genetics Center (RGC)这些数据可通过英国生物银行研究分析门户网站提供给世界各地的研究人员,该门户网站通过DNAnexus。
人类基因组包含超过 180000 个蛋白质编码区或外显子,它们共同组成一个外显子组。每个外显子组包含大约 3000 万个核苷酸。因此,变异呼叫在大规模人群研究中至关重要,在这些研究中,即使是低的假阳性和阴性率也会产生相当大的影响。要了解更多信息,请参阅Sequencing Your Genome: What Does It Mean?
出于这个原因, RGC 使用谷歌 DeepVariant 的定制训练版本分析了英国生物库外显子,这是一种高精度的变体分类深度学习方法。该方法通过 NVIDIA Parabricks 进行了加速和部署,提供了与 CPU 代码相同的准确结果,具有更快的运行时间和更低的 RGC 每个外显子组成本。
根据 RGC 基因组信息学和数据工程执行主任 Will Salerno 的说法,“使用 Parabricks 进行优化的关键组成部分之一不仅是使其更快、更便宜,而且还可以获得完全相同的变体。这种再现性对我们来说至关重要,这是透明的。我们不想要秘密酱汁,我们想要对每个人都有效的特殊酱汁,就像对我们一样。”。我们所做的每一件事,都希望我们的任何合作伙伴都能从这些方法中受益。”
基因组学研究人员可以使用各种各样的变体调用工具,从统计技术(例如贝叶斯或高斯混合模型)到将外显子组变体分类为信号或噪声的深度学习方法(卷积或递归神经网络)
尽管统计技术可以提供一种更具普遍性的方法,但如果原始数据可用于将深度学习算法训练到给定的数据类型,这些模型可能会非常准确。一个例子是同一生物体/基因组的瓶中基因组细胞系,在同一实验室用相同的技术和实验室方案进行测序
因此,深度学习变体调用主导了最近提交的precisionFDA Truth Challenge, 68% 的提交是基于深度学习的。 DeepVariant 本身赢得了多个类别
DeepVariant 使用卷积神经网络在下一代测序( NGS )读取或累积窗口中识别变体,并包括所有测序平台的模型,不仅包括 Illumina 数据,还包括 PacBio 数据、 Oxford Nanopore 数据,以及新兴测序平台、全基因组样本、外显子组样本等
NVIDIA Parabricks 提供 GPU-accelerated DeepVariant,以及其他几种变体调用工具。它通过 TensorRT 还包括多个此类模型的优化版本。
请参阅下面的 NVIDIA Parabricks DeepVariant 命令示例,如NVIDIA Parabricks documentation。所有 NVIDIA Parabricks 工具都是插入式替换命令,使相同的分析能够在 GPU 上轻松运行。
# This command assumes all the inputs are in and all the outputs go to .
$ docker run --rm --gpus all --volume :/workdir --volume :/outputdir
-w /workdir
nvcr.io/nvidia/clara/clara-parabricks:4.0.0-1
pbrun deepvariant
--ref /workdir/${REFERENCE_FILE}
--in-bam /workdir/${INPUT_BAM}
--out-variants /outputdir/${OUTPUT_VCF}
使用在适当数据上训练的非常适合的模型可以对变体调用的后续准确性产生重大影响。例如,与全基因组测序( WGS )数据相比,使用在全外显子组测序( WES )数据上训练的 DeepVariant 模型的变体调用外显子数据产生了 519 个更多的真阳性调用, 42 个更少的假阳性调用, 519 个更少的伪阴性调用
这意味着单核苷酸多态性( SNPs )的 F1 得分增加了 1% ,而 indel 的 F1 得分则增加了近 2% 。用 NVIDIA Parabricks 对瓶内基因组地面实况数据运行的结果如表 1 所示。
| HG003-WES-100x | 类 | 总位置 | 真阳性 | 漏报 | 假阳性 | 回忆起 | 精确 | F1 得分 |
| WES 模 | 茚 | 1051 | 1020 | 31 | 9 | 0 . 97050 | 0 . 99143 | 0 . 98086 |
| WES 模 | SNP | 25279 | 24976 | 303 | 46 | 0 . 98801 | 0 . 99816 | 0 . 99306 |
| WGS 模 | 茚 | 1051 | 1006 | 45 | 31 | 0 . 95718 | 0 . 97070 | 0 . 96389 |
| WGS 模 | SNP | 25279 | 24471 | 808 | 66 | 0 . 96804 | 0 . 99731 | 0 . 98246 |
表 1 。 DeepVariant 全外显子组模型显示,与标准全基因组模型相比,准确性显著提高
能够将 DeepVariant 切换到更合适的模型,甚至根据特定的实验室协议微调模型(就像 Regeneron 为英国生物银行所做的那样),这是基于深度学习的变体调用的一个强大功能
一个新的 DeepVariant retraining tool现已在 NVIDIA Parabricks v4 . 1 中提供,使用户可以在 NVIDIA GPU 上快速轻松地完成此操作。您可以训练模型来识别由于不同版本的测序仪、湿实验室试剂盒、试剂等而在数据中产生的任何非随机伪影。
性价比高的以提高的速度进行分析,得到同等的结果
与小面板分析相比,外显子组数据的计算分析是时间和成本的逐步增加。对于临床外显子组测序分析,加速分析在大规模交付结果方面很重要。
Agilent Alissa Reporter software例如,通过在云中自动缩放,利用 NVIDIA GPU 和 NVIDIA Parabricks 提供外显子组分析。这意味着安捷伦可以以更低的成本和更快的运行时间为数千个样本向客户提供基因组数据的临床见解
安捷伦报告称,他们的基础 GATK 工作流程以前需要 5 个小时,成本高达 10 美元,现在已经减少到 9 分钟(运行时间减少 96% ),每个样本只需几美元。
Alissa Reporter 的产品负责人 Joachim De Schrijver 说:“我们从样本中获得的信息越多越好。”。“对整个外显子组而不是小的基因组进行测序可以很好地实现这一点,但每个样本的 FASTQ 文件范围从 5 到 10 GB 不等,这可能意味着需要数小时的计算才能提取有意义的影响生命的结果。”
“安捷伦 Alissa Reporter 利用 GPU 和 Parabricks 来解决这一问题,并在几分钟内处理数据。此外,这降低了云计算基础设施的成本,使我们能够提供极具竞争力的定价,”他补充道。
除了加速 DeepVariant , NVIDIA Parabricks 还加速了变体呼叫者的 GATK 最佳实践版本,包括单倍型呼叫者(用于种系)和 Mutect2 (用于体细胞)。在 NVIDIA Parabricks 中,这两种方法产生的结果与开源版本相当( SNPs 和 Indels 分别为 0 . 999 F1 ),但速度更快,成本更低。
在一个外显子组上运行 NVIDIA Parabricks 种系管道( BWA-MEM 、排序、标记重复项、 BQSR 和 HaplotypeCaller 或 DeepVariant )可以将运行时间从 3 小时以上(在标准 CPU 实例上使用开源等效程序)减少到 DeepVariation 的 11 分钟(快 17 倍)和 HaploypeCaller 的 6 . 5 分钟(快 33 倍)NVIDIA T4GPU 。
这个加速因子转化为每个外显子组节省了可观的成本,因为实例运行的时间更短。如图 2 所示,在 8 个 NVIDIA T4 GPU 上使用 DeepVariant 运行 NVIDIA Parabricks 种系管道,每个样本的成本从 4 . 76 美元降低到 1 . 44 美元(便宜 70% ),使用 HaplotypeCaller 从 5 . 52 美元降低到 42 美分(便宜 92% )。
对于更复杂的管道,这些运行时可以堆叠,使测序的分析步骤成为一个非常大的瓶颈。例如,在癌症研究中,外显子组是一种常见的测序方法,肿瘤和正常组织都经常测序,覆盖范围更广,这些肿瘤 – 正常对的标准外显子管道在 CPU 实例上运行可能需要 14 个小时。如图 3 所示,仅在两台 NVIDIA T4 GPU 上即可将时间缩短至 1 . 5 小时。
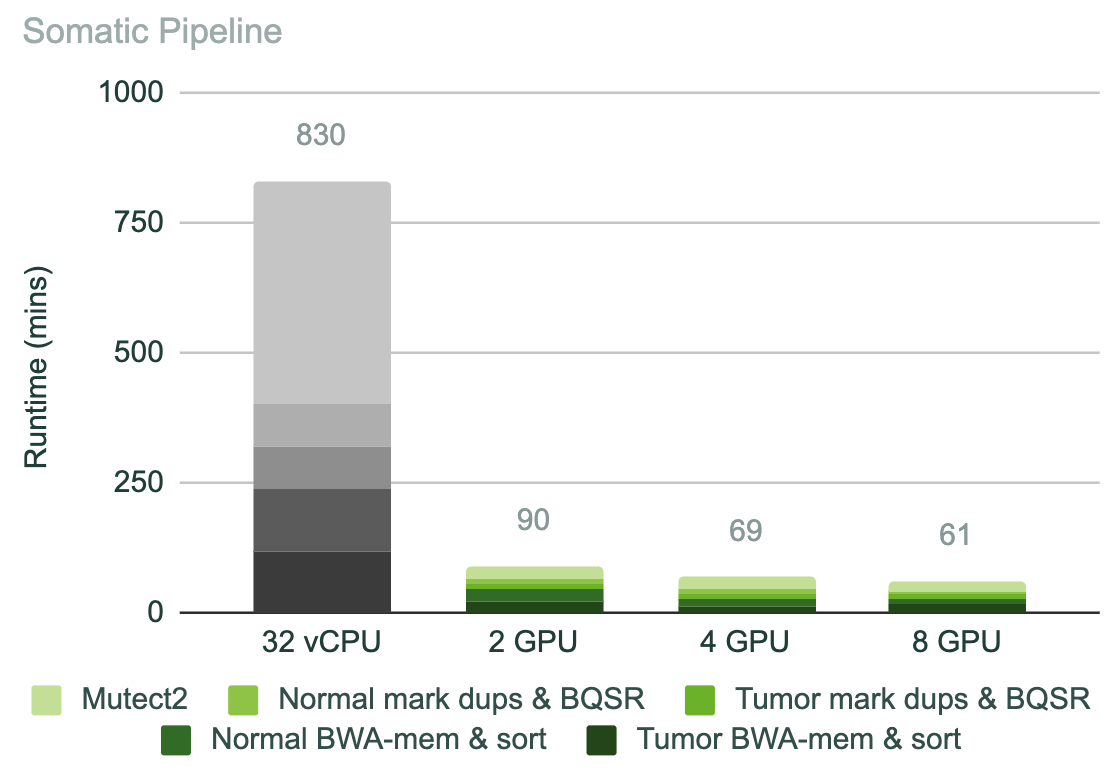 图 3 。体细胞管道的运行时间(以分钟为单位),包括肿瘤文件的对齐、正常文件的对齐,肿瘤文件的处理,正常文件的处理以及用 mutect2 调用变体(分别显示为深色到浅色)。在与图 2 相同的情况下,使用 SEQC-2 172x 深度肿瘤外显子组和 178x 正常外显子。
图 3 。体细胞管道的运行时间(以分钟为单位),包括肿瘤文件的对齐、正常文件的对齐,肿瘤文件的处理,正常文件的处理以及用 mutect2 调用变体(分别显示为深色到浅色)。在与图 2 相同的情况下,使用 SEQC-2 172x 深度肿瘤外显子组和 178x 正常外显子。
-
如何提高工程预算的准确性2016-07-25 2829
-
如何最大限度提高Σ-Δ ADC驱动器的性能2021-01-06 1438
-
全基因组数据CNV分析简介 精选资料分享2021-07-29 1160
-
简单的校准电路最大限度地提高了锂离子电池管理系统中的准确度2009-12-20 681
-
如何提高投标报价编制的准确性2010-01-08 852
-
深圳华大基因研发出猴外显子测序及分析平台2011-11-27 892
-
利用NVIDIA模型分析仪最大限度地提高深度学习的推理性能2020-10-21 1433
-
如何将机器学习模型的准确性从80%提高到90%以上2020-12-10 1814
-
DN471 - 简单的校准电路最大限度地提高了锂离子电池管理系统中的准确度2021-03-19 887
-
应用深度学习分析提高基因组分析的准确性2021-05-14 3029
-
蓄能电池管理系统中最大限度提高电池监测精度和数据完整性2021-05-18 768
-
切换以最大限度地利用SAN2023-09-01 558
-
最大限度提高∑-∆ ADC驱动器的性能2023-11-22 589
-
最大限度地提高MSP430™ FRAM的写入速度2024-10-18 494
-
如何提升ASR模型的准确性2024-11-18 3800
全部0条评论

快来发表一下你的评论吧 !
