

用于图像分类和物体检测的深度学习
电子说
描述
这个Dataiku platform日常人工智能简化了深度学习。用例影响深远,从图像分类到对象检测和自然语言处理( NLP )。 Dataiku 可帮助您对代码和代码环境进行标记、模型培训、可解释性、模型部署以及集中管理。
本文深入探讨了用于图像分类和对象检测的高级 Dataiku 和 NVIDIA 集成。它还涵盖了实时推理的深度学习模型部署以及如何使用开源RAPIDS和 cuML 库,用于客户支持 Tweet 主题建模用例。 NVIDIA 提供硬件 (NVIDIA A10 Tensor Core GPUs,在这种情况下)和各种 OSS(CUDA,RAPIDS) 完成工作
请注意,本文中的所有 NVIDIA AI 软件都可以通过NVIDIA AI Enterprise,一个用于生产人工智能的安全端到端软件套件,由 NVIDIA 提供企业支持
用于图像分类和物体检测的深度学习
本节介绍使用 Dataiku 和 NVIDIA GPU 训练和评估用于图像分类或对象检测的深度学习模型的步骤
无代码方法
从 Dataiku 11.3 开始,您可以使用可视化的无代码工具来实现图像分类或对象检测工作流程的核心领域。您可以使用本地 web 应用程序标记图像、绘制边界框和查看/管理注释。图像标记是训练性能模型的关键:→ 很好的模型。
使用 Dataiku 的图像标记工具,您可以将所有猫标记为“猫”,或者更精细地标记,以适应独特的外表或个性特征
Dataiku 使您能够训练图像分类和对象检测模型,特别是使用迁移学习来微调基于自定义图像/标签/边界框的预训练模型。数据增强重新着色、旋转和裁剪训练图像是增加训练集大小并将模型暴露在各种情况下的常用方法。
EfficientNet (图像分类)和 Faster R-CNN (对象检测)神经网络可以在模型再训练用户界面中与预先训练的权重一起使用,开箱即用。
在将模型训练为自定义图像标签和边界框之后,可以使用叠加的热图模型焦点来解释模型的预测。
一旦您对模型的性能感到满意,就将经过训练的模型作为容器化推理服务部署到 Kubernetes 集群中。这是由 Dataiku API Deployer 工具管理的。
计算发生在哪里?
Dataiku 可以将深度学习模型训练、解释和推理背后的所有计算推送给 NVIDIA PyTorch (图 4 )。您甚至可以通过 GPU 利用多个 GPU 进行分布式培训DistributedDataParallel模块和 TensorFlowMirroredStrategy.
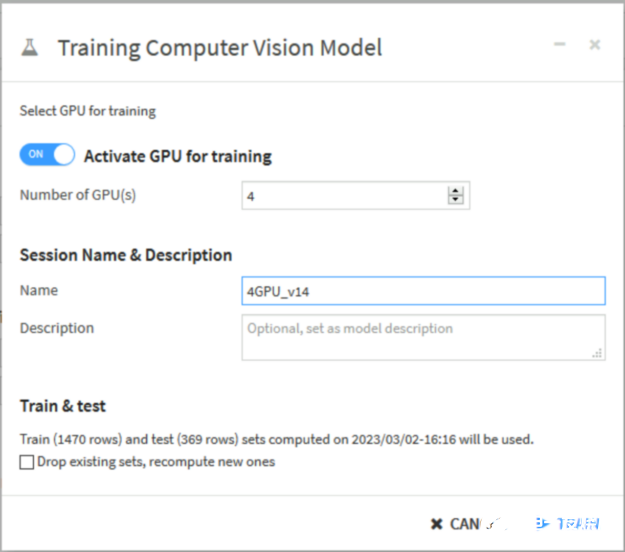 图 4 。使用 Dataiku 接口激活 NVIDIA GPU 进行深度学习模型训练
图 4 。使用 Dataiku 接口激活 NVIDIA GPU 进行深度学习模型训练
通过Dataiku Elastic AI集成。首先,将您的 Dataiku 实例连接到具有 NVIDIA GPU 资源(通过 EKS 、 GKE 、 AKS 、 OpenShift 管理)的 Kubernetes 集群。然后 Dataiku 将创建 Docker 镜像并在后台部署容器
深度学习训练和推理作业可以在 Kubernetes 集群上运行,也可以在任意 Python 代码或 Apache Spark 作业上运行。
对模型训练脚本进行编码
如果你想在 Python 中自定义你自己的深度学习模型,可以尝试在 MLflow 实验跟踪器中封装一个 train 函数。图 6 显示了一个基于 Python 的流程。请参阅中的机器学习教程Dataiku Developer Guide例如。这种方法提供了自定义代码的完全灵活性,以及一些开箱即用的实验跟踪、模型分析可视化,以及 Dataiku 中经过可视化训练的模型的点击式模型部署
自定义 Python 深度学习模型可以通过容器化执行来利用 NVIDIA GPU ,就像 Dataiku 中经过视觉训练的深度学习模型一样(图 7 )。
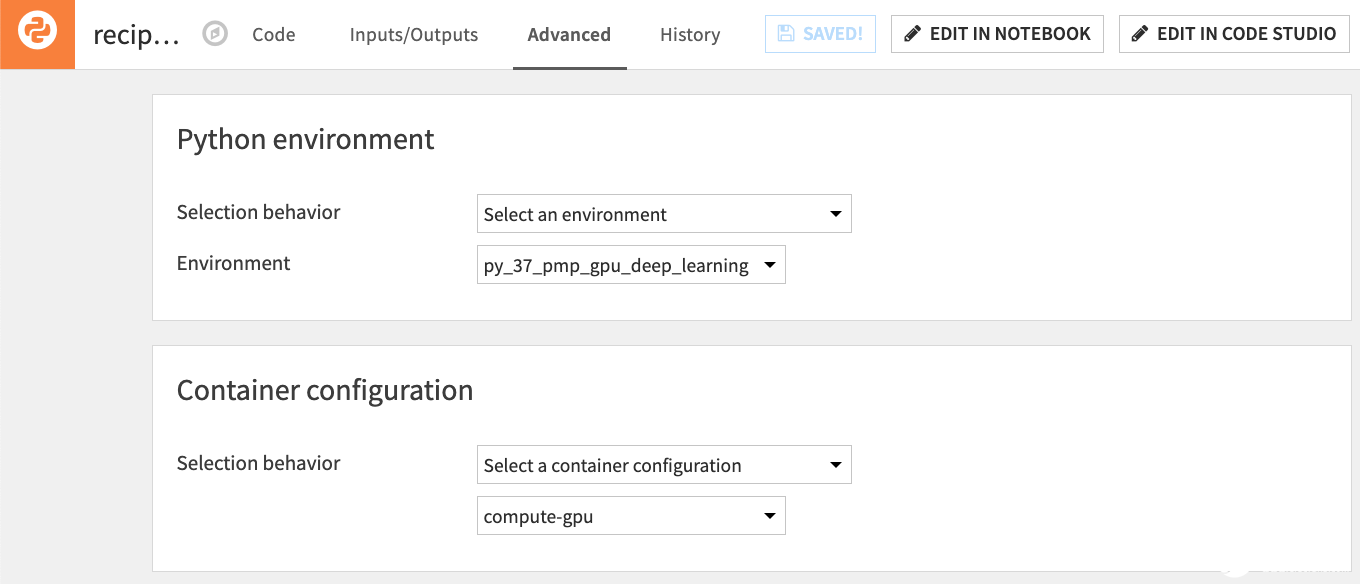 图 7 。 Dataiku 中的任何 Python 工作负载都可以推送到具有 NVIDIA GPU 资源的 Kubernetes 集群
图 7 。 Dataiku 中的任何 Python 工作负载都可以推送到具有 NVIDIA GPU 资源的 Kubernetes 集群
用于实时推理的模型部署
一旦模型经过训练,就到了部署它进行实时推理的时候了。如果您使用 Dataiku 的视觉图像分类、对象检测或带有 MLflow 的自定义编码模型,然后作为 Dataiku 模型导入,只需单击几下即可在经过训练的模型上创建容器化推理 API 服务。
首先,将 Dataiku API Deployer 工具连接到 Kubernetes 集群,以托管这些推理 API 服务,同样在集群节点中提供 NVIDIA GPU 。然后在负载均衡器后面部署容器化服务的 1-N 个副本。从这里开始,边缘设备可以向 API 服务发送请求,并接收来自模型的预测。图 8 显示了整个体系结构。
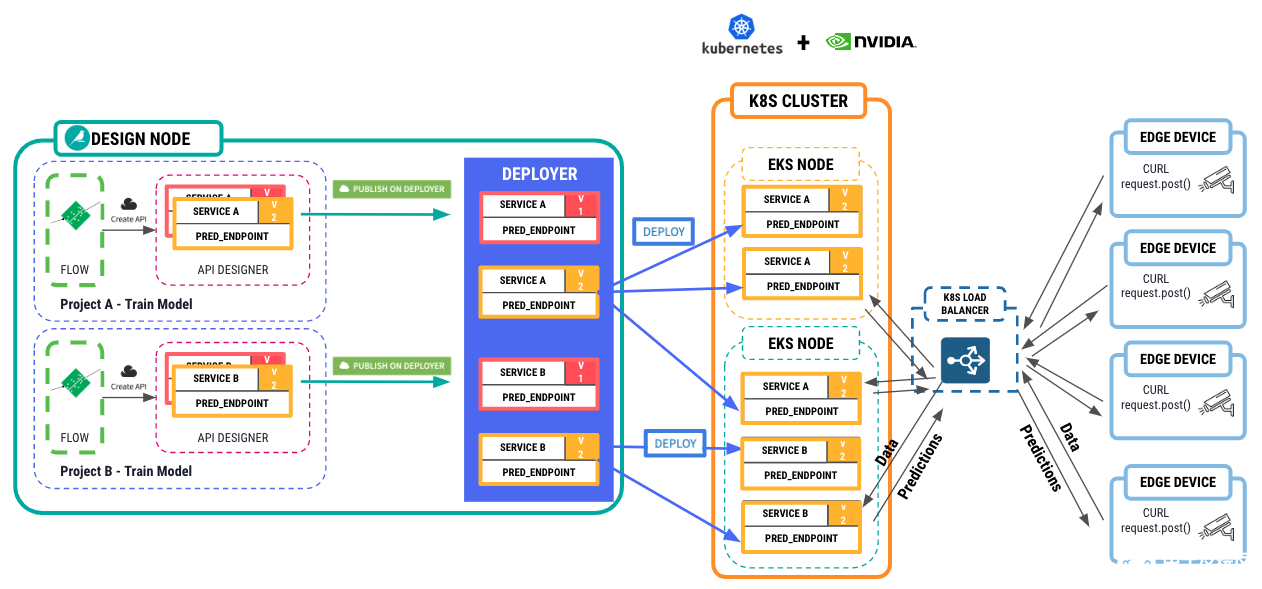 create API service in the API Designer > push the API service to the Deployer > push the API Service to a K8S cluster with NVIDIA GPU resources. From there, edge devices can submit requests to the API service with data, images, and receive predictions back.” width=”1262″ height=”589″> 图 8 。从在 Dataiku 中训练的模型到托管在具有 NVIDIA GPU 的 Kubernetes 集群上的 API 服务的工作流,用于推理
create API service in the API Designer > push the API service to the Deployer > push the API Service to a K8S cluster with NVIDIA GPU resources. From there, edge devices can submit requests to the API service with data, images, and receive predictions back.” width=”1262″ height=”589″> 图 8 。从在 Dataiku 中训练的模型到托管在具有 NVIDIA GPU 的 Kubernetes 集群上的 API 服务的工作流,用于推理
教程:在 Dataiku 中使用带有 RAPIDS 的 BERT 模型加速主题建模
为了更深入地了解,本节将介绍如何在 Dataiku 中设置 Python 环境,以便将 BERTopic 与 RAPIDS 中的 GPU 加速 cuML 库一起使用。它还强调了使用 cuML 获得的性能增益
此示例使用Kaggle Customer Support on Twitter dataset以及主题建模的关键客户投诉主题。
步骤 1 。准备数据集
首先,通过删除标点符号、停止词和词尾词来规范推文文本。还要将数据集过滤为客户在推特上用英语发布的投诉。所有这些都可以使用 Dataiku 可视化配方来完成。
使用拆分配方从初始用户推文中过滤公司的回复。接下来,使用 Dataiku 的Text Preparation plugin检测用户推文中语言分布的配方。
使用过滤配方过滤掉所有非英语和空白的推文。一定要使用文本准备方法来过滤停止词、标点符号、 URL 、表情符号等。将文本转换为小写。
最后,使用分割配方来分割用于训练和测试的数据(简单的 80% / 20% 随机分割)。
步骤 2 。使用 BERTopic 和 RAPIDS 库设置 Python 环境
运行 Python 进程需要一个具有 NVIDIA GPU 的弹性计算环境BERTopic package(及其所需的包装),以及 RAPIDS 容器图像。此示例使用 Amazon EKS 集群(实例类型: g4dnNVIDIA A10 Tensor Core GPUs) ,RAPIDS Release Stable 22.12和 BERTopic ( 0.12.0 )。
首先,在 Dataiku 中启动一个 EKS 集群。设置集群后,您可以在“管理”下的“集群”选项卡中检查其状态和配置。
BER 主题
使用 Dataiku 的托管虚拟代码环境,使用 BERTopic 及其所需的包创建 Dataiku 代码环境。
RAPIDS
使用 Docker Hub 中的 RAPIDS 映像构建一个容器环境。在 Dataiku 中,为您的代码环境使用 Dataiku 基本映像,或者从 DockerHub 或NGC。然后,将您的 Dataiku 代码环境附加到它。请注意, NVIDIA 已经在 PyPi 上发布了 RAPIDS ,所以您现在可以只使用默认的 Dataiku 基本映像。
步骤 3 。使用默认 UMAP 运行 BERTopic
接下来,使用 BERTopic 从 Twitter 投诉中找出前五个话题。要在 GPU 上加速 UMAP 进程,请使用 cuML UMAP 。默认 UMAP 如下所示:
# -------------------------------------------------------------------------------- NOTEBOOK-CELL: CODE
# -*- coding: utf-8 -*-
import dataiku
import pandas as pd, numpy as np
from dataiku import pandasutils as pdu
from bertopic import BERTopic
# -------------------------------------------------------------------------------- NOTEBOOK-CELL: CODE
# Read the train dataset in the dataframe and the variable sample_size which defines the number of records to be used
sample_size = dataiku.get_custom_variables()["sample_size"]
train_data = dataiku.Dataset("train_cleaned")
train_data_df = train_data.get_dataframe(sampling='head',limit=sample_size)
# -------------------------------------------------------------------------------- NOTEBOOK-CELL: CODE
# Create Bertopic object and run fit transform
topic_model = BERTopic(calculate_probabilities=True,nr_topics=4)
topics, probs = topic_model.fit_transform(train_data_df["Review Description_cleaned"])
all_topics_rapids_df = topic_model.get_topic_info()
# -------------------------------------------------------------------------------- NOTEBOOK-CELL: CODE
#Write the List of Topics output as a DSS Dataset
Topic_Model_df = all_topics_rapids_df
Topic_Model_w_Rapids = dataiku.Dataset("Topic_Model")
Topic_Model_w_Rapids.write_with_schema(Topic_Model_df)
RAPIDS cuML UMAP:
# -*- coding: utf-8 -*-
import dataiku
import pandas as pd, numpy as np
from dataiku import pandasutils as pdu
from bertopic import BERTopic
from cuml.manifold import UMAP
from cuml.cluster.hdbscan.prediction import approximate_predict
# -------------------------------------------------------------------------------- NOTEBOOK-CELL: CODE
# Read the train dataset in the dataframe and the variable sample_size which defines the number of records to be used
sample_size = dataiku.get_custom_variables()["sample_size"]
train_data = dataiku.Dataset("train_cleaned")
train_data_df = train_data.get_dataframe(sampling='head',limit=sample_size)
# -------------------------------------------------------------------------------- NOTEBOOK-CELL: CODE
# Create a cuML UMAP Obejct and pass it in the Bertopic object and run fit transform
umap_model = UMAP(n_components=5, n_neighbors=15, min_dist=0.0)
cu_topic_model = BERTopic(calculate_probabilities=True,umap_model=umap_model,nr_topics=4)
cu_topics, cu_probs = cu_topic_model.fit_transform(train_data_df["Review Description_cleaned"])
all_topics_rapids_df = cu_topic_model.get_topic_info()
# -------------------------------------------------------------------------------- NOTEBOOK-CELL: CODE
# Write the List of Topics output as a DSS Dataset
Topic_Model_w_Rapids_df = all_topics_rapids_df
Topic_Model_w_Rapids = dataiku.Dataset("Topic_Model_w_Rapids")
Topic_Model_w_Rapids.write_with_schema(Topic_Model_w_Rapids_df)
UMAP 对整个计算时间有很大贡献。在带有 cuML RAPIDS 的 NVIDIA GPU 上运行 UMAP 可实现 4 倍的性能提升。可以通过在 GPU 上运行更多的算法来实现额外的改进,例如使用 cuML HDBSCAN 。
| 不带 RAPIDS 的主题建模过程 | 运行时 |
| 不带 RAPIDS | 12 分 21 秒 |
| 带 RAPIDS | 2 分 59 秒 |
表 1 。使用 RAPIDS AI 进行配置可实现 4 倍的性能提升
步骤 4 。投诉聚类仪表板
最后,您可以在 Dataiku 中的输出数据集(带有干净的 Tweet 文本和主题)上构建各种看起来很酷的图表,并将其推送到仪表板上进行执行团队审查(图 13 )。
图 13 。 Dataiku 仪表板在一个中心位置显示各种指标
把它们放在一起
如果您希望将深度学习用于图像分类、对象检测或 NLP 用例, Dataiku 可以帮助您标记、模型训练、可解释性、模型部署以及集中管理代码和代码环境。与最新的 NVIDIA 数据科学库和计算硬件的紧密集成构成了一个完整的堆栈。
-
华为云ModelArts入门开发(完成物体分类、物体检测)2023-07-10 3413
-
深度学习DeepLearning实战2021-01-09 19161
-
深度强化学习实战2021-01-10 2970
-
基于深度学习和3D图像处理的精密加工件外观缺陷检测系统2022-03-08 28334
-
设计一个红外物体检测设备2022-06-27 965
-
讨论纹理分析在图像分类中的重要性及其在深度学习中使用纹理分析2022-10-26 2973
-
基于运动估计的运动物体检测技术研究2009-12-14 762
-
图像分类的方法之深度学习与传统机器学习2017-09-28 1852
-
深度学习在计算机视觉上的四大应用2020-08-24 6157
-
传统检测、深度神经网络框架、检测技术的物体检测算法全概述2020-10-22 3899
-
深度学习中图像分割的方法和应用2020-11-27 4636
-
详解深度学习之图像分割2021-01-06 4648
-
基于PyTorch的深度学习入门教程之PyTorch的安装和配置2021-02-16 3510
-
浅析FPGA的图像采集和快速移动物体检测2021-05-12 4091
-
分享使用图像分割来做缺陷检测的一个例子2021-05-29 3511
全部0条评论

快来发表一下你的评论吧 !
