

使用 RAPIDS RAFT 进行机器学习和数据分析的可重用计算模式
电子说
描述
在许多数据分析和机器学习算法中,计算瓶颈往往来自控制端到端性能的一小部分步骤。这些步骤的可重用解决方案通常需要低级别的基元,这些基元非常简单且耗时。
NVIDIA 制造 RAPIDS RAFT 是为了解决这些瓶颈,并在为多维数据构建算法时最大限度地重用,例如机器学习和数据分析中经常遇到的问题。
RAPIDS 是 GPU 上的一套用于数据科学和机器学习的加速库:
pandas 类数据结构的 cuDF
cuGraph 用于图形数据
cuML 用于机器学习
高度优化的 RAFT 计算模式构成了一个丰富的模块化嵌入式加速器目录,为您提供了强大的元素来组成新的算法或加速现有的库。
这仅仅是一个开始:随着新 GPU 架构的发布, RAFT 组件将继续优化,确保您始终从硬件中获得最佳性能。
RAFT 使您能够花时间设计和开发应用程序,而不必担心您是否能充分利用 GPU 硬件。
在这篇文章中,我讨论了 RAFT 在开发人员工具箱中的位置,使用它的环境,更重要的是,在需要时使用 RAFT 的权力。
消除常见瓶颈
NVIDIA 构建 RAFT ,为开发者提供基本元素作为构建块。
最近的邻居就是一个很好的例子。它很常见,很有用,而且计算量很大。邻域方法涵盖了 machine learning 的大部分算法,如聚类和降维。支持线性代数、稀疏矩阵运算、采样、优化和统计矩等应用数学的核心工具。
事实上, RAFT 构成了 RAPIDS cuML 中几乎所有的算法,包括但不限于流行的 HDBSCAN 、 TSNE 、 UMAP 以及所有其他用于聚类和可视化的算法。
| Category | Examples |
| Data Formats | Sparse and dense, conversions, data generation |
| Dense Operations | Linear algebra, matrix and vector operations, slicing, norms, factorization, least squares, svd, and eigenvalue problems |
| Sparse Operations | Linear algebra, eigenvalue problems, slicing, symmetrization, components, and labeling |
| Spatial | Pairwise distances, nearest neighbors, neighborhood graph construction |
| Basic Clustering | Spectral clustering, hierarchical clustering, k-means |
| Solvers | Combinatorial optimization, iterative solvers |
| Statistics | Sampling, moments and summary statistics, metrics |
| Tools and Utilities | Common utilities for developing CUDA applications, multi-node multi-gpu infrastructure |
表 1 。 RAFT 包含几个不同类别的构建块,包括数据格式、稀疏和密集运算、最近邻等空间运算、基本聚类、迭代求解器和统计。
如果你想在绝对最快的作品基础上创作新作品,那么你现在只会受到创造力的限制。除了所有的基本方法外,向量搜索领域的最佳方法是在搜索大型语言模型( LLM )和推荐系统方面取得令人兴奋的进展。
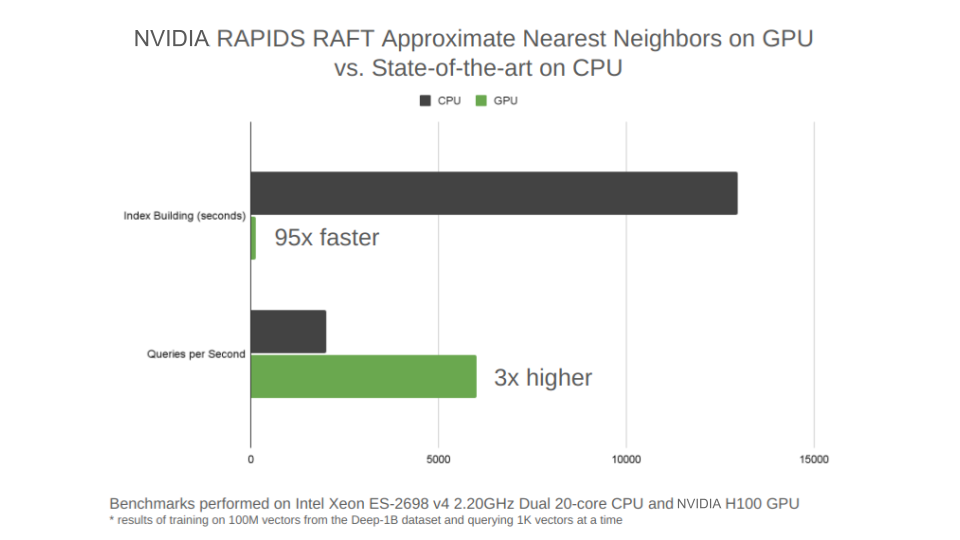 图 1 。 NVIDIA H100 GPU 上的新 RAFT IVF-PQ 算法与 CPU 上的 HNSW 算法的比较
图 1 。 NVIDIA H100 GPU 上的新 RAFT IVF-PQ 算法与 CPU 上的 HNSW 算法的比较
图 1 重点介绍了一种新的 RAFT 最先进的近似最近邻算法,它是一类被称为 inverted file indexes ( IVF )的算法中 product quantization ( PQ )的变体。 IVF 将训练数据划分为一组集群,并将查询减少到仅最近集群的子集。这是 PQ 算法的 IVF 版本,称为 IVF-PQ 。
RAFT IVF-PQ 实现已针对生产向量相似性搜索系统所需的小批量查询进行了调整。这类针对小批量调整的算法中目前最先进的技术被称为分层可导航小世界图( HNSW )算法。它尤其以在 CPU 上速度快而闻名。新的 RAFT IVF-PQ 算法的训练速度比 HNSW 快 95 倍,在执行小批量查询时快 3 倍。
打造始终如一的体验
RAFT 在其核心是一个只有头部的 C ++模板库,它需要一组最小的依赖项。它主要依赖于 CUDA 工具包附带的库。这使您能够灵活地根据需要专门化所需数据类型的模板(图 2 )。
 图 2:RAFT 技术堆栈
图 2:RAFT 技术堆栈
图 2 显示了堆栈从一个仅包含头的模板库开始。在纯头库的基础上构建了一个共享库,其中包含预编译的模板专用化和主机可访问的运行时 API 。 PyLibRAFT 为 Python 用户提供了强大的 RAFT 构建块。
一个可选的共享库可以通过预编译常见类型的模板专用化来减少编译时间。共享库中还提供了一个运行时 API ,可以链接到您的构建中。它使 RAFT API 能够以类似于从 C 源文件调用 cuBLAS 、 cuSOLVER 和 cuSPARSE API 的方式从常规 C ++源文件调用。
直接使用共享库中的运行时 API 的是一个名为pylibraft的 Python API ,它包含 C ++ API 的轻量级包装器。
管理设备资源
RAFT 使用raft::resources对象来管理不同的资源,如 CUDA 流、流池和各种 CUDA 库的句柄,如 cuBLAS 和 cuSOLVER 。raft::device_resources实例是配置和管理 GPU 特定资源以调用 RAFT API 的最简单方法。
#include raft::device_resources resource_handle;
下面是 Python 中的相同示例:
from pylibraft.common.handle import DeviceResources resource_handle = DeviceResources()
使用 CUDA 构建复杂的端到端算法传统上需要低水平的专业知识和关于每个 GPU 体系结构的能力的高级知识,以持续保持硬件繁忙。
像 Cub 、 Thrust 和 CUTLASS 这样的库使编写 CUDA 应用程序变得更加容易。它们将较低级别的 API 抽象为较高级别的原语,这些原语可用于开发各种算法。
RAFT 提供了一个类似的抽象层,但它特别关注 ML 和数据分析的稍微高级的原语。如果你已经熟悉深度神经网络的嵌入式加速器 CUDA 库 cuDNN ,你可以说 RAFT 与 RAPIDS cuML 等库的关系与 cuDNN 与 TensorFlow 等库相似。
处理多维数据
虽然开始出现与 GPU 交互的标准,但 RAFT C ++ API 基于 C ++ 23 STL 标准中的 mdspan (多维非拥有视图)。
mdspan是一种非所有权视图结构,具有高度的表达能力、灵活性和自文档化。它有一个灵活的 API 来表示多维数据,在精神上类似于 NumPy 的ndarray,但在 C ++中。mdspan提供了干净和一致的 API 体验,因为它包裹了任何现有的指针,无论是在主(主机)内存还是设备内存中。
#include #include std::vector my_floats(10); … populate vector … auto my_mdspan = raft::make_host_vector(my_floats.data(), 10);
下面是 Python 中的相同示例:
#include float *my_floats; … allocate and populate device memory … auto my_mdspan = raft::make_device_vector(my_floats, 10);
为了简化具有多维表示的内存分配,mdarray标准提供了一个 RAII 兼容的内存,与 RAFT 也采用的mdspan相对应。通过使用mdarray 来分配和包含内存,可以使示例变得更容易。
#include #include raft::device_resources handle; int n_rows = 10; int n_cols = 10; auto scalar = raft::make_device_scalar(handle, 1.0); auto vector = raft::make_device_vector(handle, n_cols); auto matrix = raft::make_device_matrix(handle, n_rows, n_cols);
下面是 Python 中的相同示例:
#include int n_rows = 10; int n_cols = 10; auto scalar = raft::make_host_scalar(1.0); auto vector = raft::make_host_vector(n_cols); auto matrix = raft::make_host_matrix(n_rows, n_cols);
在mdarray实例中分配并包含内存后,创建mdspan 视图以使用.view方法调用 RAFT API 。
// Scalar mdspan on device auto scalar_view = scalar.view(); // Vector mdspan on device auto vector_view = vector.view(); // Matrix mdspan on device auto matrix_view = matrix.view();
使用 C ++和 Python API
例如,使用新的 RAFT 近似最近邻 API 在 C ++和 Python 中构建和查询索引。以下代码示例使用 RAFT IVF-PQ 算法构建索引。
#include raft::device_resources handle; raft::neighbors::ivf_pq::index_params idx_params; auto index = raft::neighbors::ivf_pq::build(handle, idx_params, dataset);
您可以使用以下代码示例来查询新建的索引。
#include
raft::neighbors::ivf_pq::search_params search_params;
uint32_t n_query_rows = 1000;
uint32_t k = 5;
…
auto out_inds = raft::make_device_matrix(handle, n_query_rows, k);
auto out_dists = raft::make_device_matrix(handle, n_query_rows, k);
raft::neighbors::ivf_pq::search(handle, search_params, index, queries,
out_inds.view(), out_dists.view());
下面是 Python 中相同的索引构建示例:
import cupy as cp
from pylibraft.neighbors import ivf_pq
n_samples = 50000
n_query_rows = 1000
index_params = ivf_pq.IndexParams(
n_lists=1024,
metric="sqeuclidean",
pq_dim=10)
index = ivf_pq.build(index_params, dataset)
下面是 Python 中相同的索引搜索示例:
search_params = ivf_pq.SearchParams(n_probes=20)
k = 10
…
distances, neighbors = ivf_pq.search(ivf_pq.SearchParams(), index,
queries, k)
PyLibRAFT 可以与任何支持 __cuda_array_interface__ ( CAI )的库进行互操作,如 PyTorch 、 CuPy 和 Numba 。默认情况下, PyLibRAFT 函数可以接受任何符合 CAI 的数组,即使在需要时也可以将输出写入到位。您可以通过配置执行输出转换的函数,将此行为自定义到您选择的库中,以实现更无缝的集成。
以下代码示例将 PyLibRAFT 配置为返回 CuPy ndarray或 PyTorch tensors。
import pylibraft.config
pylibraft.config.set_output_as("cupy") # All compute APIs will return cupy arrays
pylibraft.config.set_output_as("torch") # All compute APIs will return torch tensors
您也可以配置自定义功能。例如,以下代码示例将 PyLibRAFT 函数的所有输出转换为主(主机)存储器中的 NumPy 数组。
pylibraft.config.set_output_as(lambda device_ndarray: return device_ndarray.copy_to_host())
获取 RAFT
以下步骤提供了有关安装 RAFT 的不同方式的信息。 Conda 和 PIP 是最简单的路线,尤其是在与 PyLibRAFT 交互时。由于 RAFT 是一个核心的 C ++库,我们还简要展示了它可以多么容易地集成到 Cmake 中。
康达牌手表
对于 C ++和 Python 使用,安装 RAFT 的一种简单方法是使用 conda 。将 C ++标头安装到您的 conda 环境中。
conda install -c rapidsai -c conda-forge -c nvidia libraft-headers
将预编译的二进制文件也安装到您的环境中。
conda install -c rapidsai -c conda-forge -c nvidia libraft-distance libraft-nn
当然, Python 库也有 conda 版本:
conda install -c rapidsai -c conda-forge -c nvidia pylibraft
皮普
RAPIDS 还提供了 pip 包,可以在纯 Python 环境中轻松安装。
pip install pylibraft-cu11 --extra-index-url=https://pypi.ngc.nvidia.com pip install raft-dask-cu11 --extra-index-url=https://pypi.ngc.nvidia.com
C 制造商
RAFT 也可以使用 CMake Package Manager ( CPM )和 rapids-cmake 轻松集成到您的 cmake 项目中,它们还可以下载所需版本并配置raft::raft cmake 目标。
如果 RAFT 已经安装,例如之前的 conda 命令,请使用 cmake 的find_package使raft::raft目标可用于您的项目。
find_package(raft)
raft::raft目标携带了许多主要 RAFT 功能所需的基本依赖项集,如 RAPIDS 内存管理器( RMM )和 CUDA 工具包库。但是,如果您使用来自以下任何命名空间的 API ,则可能需要额外的依赖项:
raft::distance
raft::neighbors
raft::comms
RAFT 使用可选的 cmake 组件,这使得新的 cmakes 目标能够将这些依赖关系传递到您的项目中。
find_package(raft COMPONENTS distance distributed)
此 cmake 功能可启用目标 raft :: distance 和 raft :: distributed ,此外还有 raft :: raft 。将它们添加到必要的构建目标中,以便传递包含路径和依赖关系的链接库信息。例如,可以为距离组件链接 CUTRASS ,或者为分布式组件链接 NVIDIA Collective Communications Library ( NCCL )和 Unififed Communications X ( UCX )。
主要收获
RAFT 是一个用于机器学习和数据分析的高度可重用计算模式库。集中化重要计算使您能够在进行优化时自动获得性能改进的好处,例如在发布新的 GPU 体系结构和功能时。
RAFT 还包含高度可重复使用的基础设施,用于构建具有干净灵活接口的生产质量加速库,遵循 C ++ STL 等重要标准,以保证使用寿命。
RAFT 通过覆盖从 C ++到 Python 的整个堆栈来简化集成,进一步实现了与其他流行的 GPU 加速库的互操作性,如 PyTorch 、 CuPy 和 Numba ,以及 RAPIDS 生态系统中的库。
-
网络爬虫,Python和数据分析2024-07-13 663
-
数据分析除了spss还有什么2024-07-05 2045
-
机器学习在数据分析中的应用2024-07-02 2390
-
机器学习与数据挖掘的区别 机器学习与数据挖掘的关系2023-08-17 3311
-
使用 RAPIDS 进行更快的单细胞分析2023-07-05 1670
-
电商数据分析攻略,让你轻松搞定数据分析!2023-06-27 4252
-
使用Azure和机器学习进行传感器数据分析2023-06-16 777
-
成为Python数据分析师,需要掌握哪些技能2021-06-23 6984
-
内部和外部扫描:机器学习,大数据分析与AI2020-05-31 2803
-
大数据分析与机器学习有什么区别2020-03-28 5878
-
基于人工智能克服数据分析限制2019-07-29 2811
-
推荐几本机器学习和深度学习必读书籍+机器学习实战视频PPT+大数据分析书籍2019-07-22 2531
-
大数据和数据分析区别2018-12-19 17541
-
怎么有效学习Python数据分析?2018-06-28 3008
全部0条评论

快来发表一下你的评论吧 !
