

NVIDIA Parabricks v4.1的功能
电子说
描述
NVIDIA Parabricks 是一套加速的基因组分析应用程序,它在加速测序比对和提高深度学习变体调用的准确性方面比以往任何时候都更进一步。该版本包括 PacBio 长读数据的新工作流程,包括加速的 Minimap2 工具和谷歌的 DeepVariant ,用于对 PacBio 数据进行完整的 GPU 端到端分析。
NVIDIA Parabricks 可以免费使用,并提供付费企业支持选项。它包含各种优化的、基于人工智能的行业标准基因组工具,比基于 CPU 的工具提供高达 80 倍的加速,并将计算成本降低高达 50% 。与 CPU 上的约 24 小时相比,现在只需 16 分钟即可分析 30 倍的全基因组,相当于每年在一台服务器上分析多达 30000 个全基因组。
快速查看 Parabricks v4.1 的功能
一种新的 DeepVariant 重新训练工具,使任何人都能为自己的数据重新训练或微调 DeepVariation ,从而实现更准确的变体调用(现已在 NGC 上提供)。
PacBio 的端到端( FastQ 到 VCF )加速工作流,将在 GitHub 、 Terra.Bio 和其他云平台上的 Parabricks 工作流中提供。
新的加速 Minimap2 工具,用于调整 PacBio 的长读数。
用于 PacBio 数据的新加速 DeepVariant 变体调用程序,在 DGX 站[4xA100 GPU s]上运行 30 倍全基因组,运行时间为 8 分钟。
与 v4.0 中的 21 分钟和仅在 CPU – 上的约 24 小时相比, DGX A100 GPU [8xA100 GPU s]在 16 分钟内进一步加速了 30 倍全基因组的短读种系管道。
与新的 NVIDIA H100 GPU 兼容,其中包括强大的 DPX 指令,用于增强动态编程算法,如 Smith Waterman ,用于局部序列比对。
注册以获得 Parabricks 4.1 release 的通知,或尝试 prerelease DeepVariant re-training tool 。
支持长读分析
长读测序,即对明显较长的 DNA 片段进行测序的能力,与传统的短读测序相比具有多种固有优势。最重要的是,这些读数更容易被组装到完整的基因组中。
较低水平的模糊性和比对误差使长读测序更好地用于基因组中更具挑战性的部分(例如,高度重复的区域)或组装基因组 de novo (没有提供参考文献)。
这为测序界带来了许多改进,包括对结构变异(大插入、缺失、反转、重复等)有了更多的了解。结构变异可能导致疾病,如卢·格里格病( ALS )、帕金森病和心脏病。
它还最终使科学界能够端到端地完全完成人类参考基因组,即 2022 年发布的端粒到端粒( T2T )基因组。
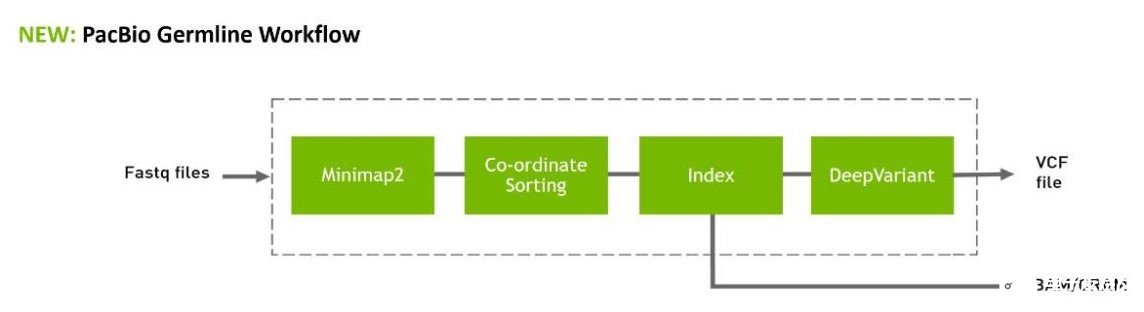 图 2:Parabricks 4.1 中提供了长阅读工具和工作流程,并为 PacBio 提供了新的 Minimap2 和 FastQ 到 VCF
图 2:Parabricks 4.1 中提供了长阅读工具和工作流程,并为 PacBio 提供了新的 Minimap2 和 FastQ 到 VCF
PacBio 是长阅读测序领域的杰出领导者。他们的技术产生长达 25 千碱基的读取(相比之下,每次读取的短读取测序< 300 碱基)。他们还通过基于循环一致性测序的 HiFi 读取技术和基于 transformer 的深度学习模型 DeepConsensus 的分析,突破了测序准确性的界限。
PacBio 的 Revio 长读测序系统采用 NVIDIA GPU ,每年可将这种方法扩展到 1300 个人类全基因组。
除此之外, NVIDIA Parabricks 4.1软件可用于 GPU -与Minimap2的加速对齐,以及与DeepVariant的PacBio模型的变体调用,为PacBio数据提供完整的端到端工作流程。
DeepVariant 使用 Parabricks 重新训练
DeepVariant 是一个基于 CNN 的准确变体调用程序,用于短读和长读数据的种系工作流,作为 NVIDIA Parabricks 的一部分,在 GPU 上加速。 Parabricks 4.1 包括一个框架,用于重新训练和微调基础 CNN 模型,为分析工作流程带来更准确的变体调用。
具体来说,这具有能够将模型微调到单个数据集并识别后续数据中产生的任何非随机伪影的优点。这已经成功地应用于测序仪级别,例如 Ultima 、 Singular 和 PacBio 都生产了自己的特定模型,并根据其独特的误差分布进行了训练。
它也已应用于项目级别,例如 Regeneron Genetic Center’s exome sequencing as part of the UKBioBank project 。不同的实验室通常使用不同版本的测序仪、湿实验室试剂盒和试剂,并且通常有不同的实验室流程。所有这些差异都可能在它们的样本中引入微妙而独特的人工制品。
通过使用 DeepVariant 基础模型作为一个温暖的开端,通过对少数瓶中基因组细胞系进行测序以进行训练、测试和验证,实施实验室特定的微调可以是一个相对简单的过程。
在 Regeneron 的情况下,使用单个 V100 GPU 训练 12 小时,仅在一个样本( HG001 )上训练就足以看到模型收敛, 20% 的数据保留用于测试,第二个样本( HG002 )用于验证。这使得相对少量的数据在准确性上有了令人印象深刻的提高,例如将 INDEL 的孟德尔误差率从 0.075 降低到 0.056 。
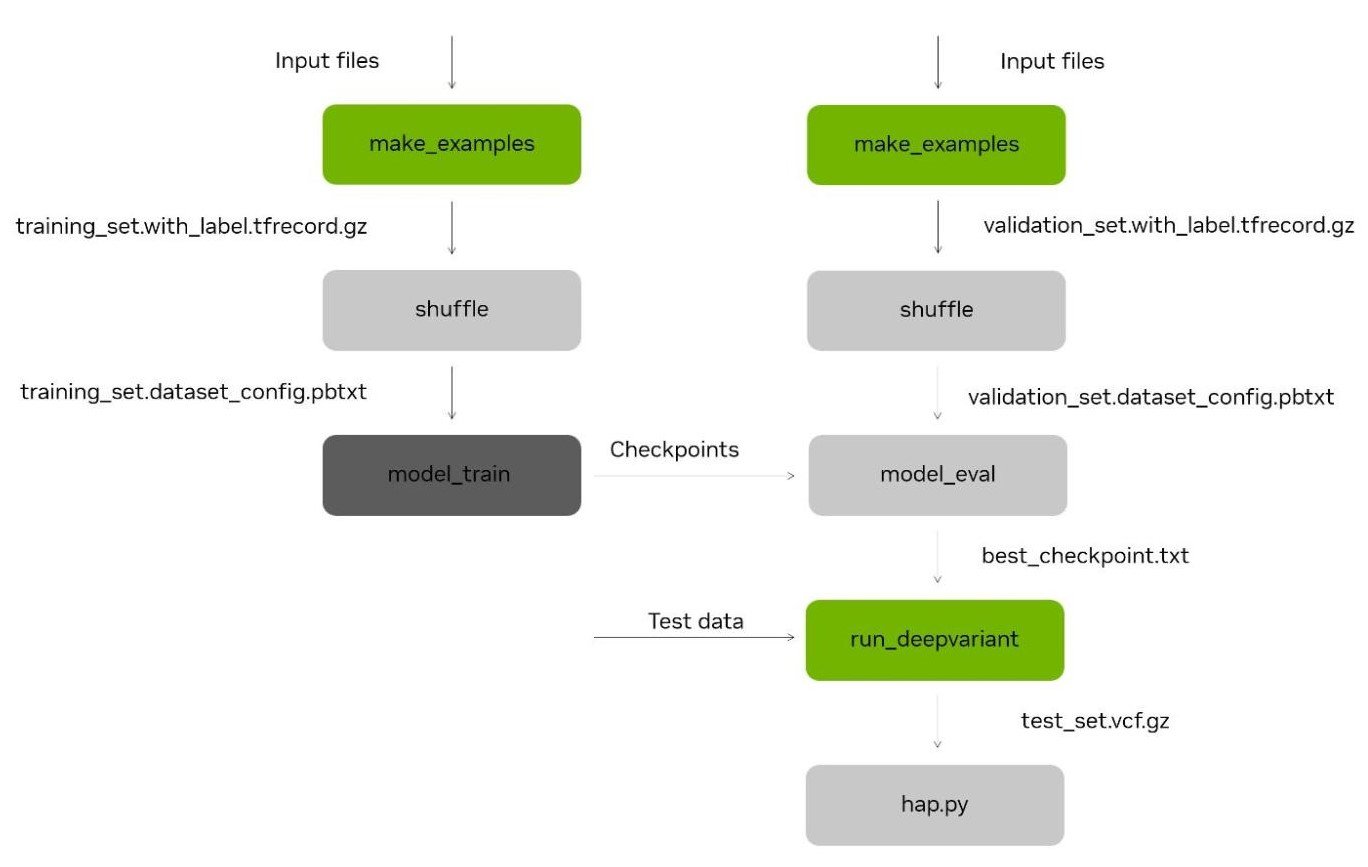 图 4 。 DeepVariant 重新训练框架流程图,包括使用 hap.py 进行准确性测试
图 4 。 DeepVariant 重新训练框架流程图,包括使用 hap.py 进行准确性测试
-
NVIDIA Parabricks v4.3.1版本的新功能2024-09-10 1702
-
请问ESP-IDF v4.1怎么生成静态库和调用静态库?2024-06-24 648
-
DMA/Bridge Subsystem for PCI Express v4.1指南2023-09-14 1711
-
有人有ESP-WROVER-KIT V4.1的BOM吗?求分享2023-04-12 650
-
SSC 通信板 V4.1 数据表2023-03-15 491
-
关于Wi-Fi CERTIFIED EasyMesh测试计划v4.1版本2022-06-24 4268
-
NetAssist网络调试助手V4.1应用程序免费下载2020-03-16 1437
-
电机控制工作台4.1如何通过ST MC Workbench v4.1计算系数2018-10-10 2780
-
uniflash V4.1 无法为CC3220SF下载代码2018-05-14 4236
-
中学电路虚拟实验室 V4.1下载2018-02-26 802
-
《Camera_for_RockChipSDK参考说明_v4.1》下载2017-09-19 2675
-
RVDS v4.1 官方开发工具2014-10-15 4895
-
dy3208电子钟_v4.12013-04-12 2185
-
Altera发布无线基站和远程射频前端设计CPRI v4.12009-08-11 763
全部0条评论

快来发表一下你的评论吧 !
