

AI大模型的的三个发展阶段
人工智能
描述
AI大模型是“大数据+大算力+强算法”结合的产物,凝聚了大数据内在精华的“隐式知识库”。包含了“预训练”和“大模型”两层含义,即模型在大规模数据集上完成了预训练后无需微调,或仅需要少量数据的微调,就能直接支撑各类应用。
AI大模型成为人工智能迈向通用智能的里程碑技术。AI大模型的落地应用使得AI的三要素由“数据、算法、算力”演变为“场景、产品、算力”。基于数据的互联网时代和基于算力的云计算时代之后,我们将进入基于大模型的AI时代。
AI大模型的发展历程
► 从参数规模上看,AI大模型先后经历了预训练模型、大规模预训练模型、超大规模预训练模型三个阶段,每年参数规模至少提升10倍,参数量实现了从亿级到百万亿级的突破。目前千亿级参数规模的大模型成为主流。
►从技术架构上看, Transformer架构是当前大模型领域主流的算法架构基础,由此形成了GPT和BERT两条主要的技术路线,其中BERT最有名的落地项目是谷歌的AlphaGo。在GPT3.0发布后,GPT逐渐成为大模型的主流路线。综合来看,当前几乎所有参数规模超过千亿的大型语言模型都采取GPT模式,如百度文心一言,阿里发布的通义千问等。
► 从模态支持上看,AI大模型可分为自然语言处理大模型,CV大模型、科学计算大模型等。AI大模型支持的模态更加多样,从支持文本、图片、图像、语音单一模态下的单一任务,逐渐发展为支持多种模态下的多种任务。
►从应用领域上看,大模型可分为通用大模型和行业大模型两种。通用大模型是具有强大泛化能力,可在不进行微调或少量微调的情况下完成多场景任务,相当于AI完成了“通识教育”,ChatGPT、华为的盘古都是通用大模型。行业大模型则是利用行业知识对大模型进行微调,让AI完成“专业教育”,以满足在能源、金融、制造、传媒等不同领域的需求,如金融领域的BloombergGPT、航天-百度文心等。
当前,AI大模型的发展正从以不同模态数据为基础过渡到与知识、可解释性、学习理论等方面相结合,呈现出全面发力、多点开花的新格局。
AI大模型发展阶段
AI大模型发展历经三个阶段,分别是萌芽期、沉淀期和爆发期。
►萌芽期(1950-2005):以CNN为代表的传统神经网络模型阶段。1956年,从计算机专家约翰·麦卡锡提出“人工智能”概念开始,AI发展由最开始基于小规模专家知识逐步发展为基于机器学习。1980年,卷积神经网络的雏形CNN诞生。1998年,现代卷积神经网络的基本结构LeNet-5诞生,机器学习方法由早期基于浅层机器学习的模型,变为了基于深度学习的模型,为自然语言生成、计算机视觉等领域的深入研究奠定了基础,对后续深度学习框架的迭代及大模型发展具有开创性的意义。
►沉淀期(2006-2019):以Transformer为代表的全新神经网络模型阶段。2013年,自然语言处理模型 Word2Vec诞生,首次提出将单词转换为向量的“词向量模型”,以便计算机更好地理解和处理文本数据。2014年,被誉为21世纪最强大算法模型之一的GAN(对抗式生成网络)诞生,标志着深度学习进入了生成模型研究的新阶段。2017年,Google颠覆性地提出了基于自注意力机制的神经网络结构——Transformer架构,奠定了大模型预训练算法架构的基础。2018年,OpenAI和Google分别发布了GPT-1与BERT大模型,意味着预训练大模型成为自然语言处理领域的主流。在探索期,以Transformer为代表的全新神经网络架构,奠定了大模型的算法架构基础,使大模型技术的性能得到了显著提升。
►爆发期(2020-至今):以GPT为代表的预训练大模型阶段。
2020年,OpenAI公司推出了GPT-3,模型参数规模达到了1750亿,成为当时最大的语言模型,并且在零样本学习任务上实现了巨大性能提升。随后,更多策略如基于人类反馈的强化学习(RHLF)、代码预训练、指令微调等开始出现, 被用于进一步提高推理能力和任务泛化。2022年11月,搭载了GPT3.5的ChatGPT横空出世,凭借逼真的自然语言交互与多场景内容生成能力,迅速引爆互联网。2023年3月,最新发布的超大规模多模态预训练大模型——GPT-4,具备了多模态理解与多类型内容生成能力。在迅猛发展期,大数据、大算力和大算法完美结合,大幅提升了大模型的预训练和生成能力以及多模态多场景应用能力。如ChatGPT的巨大成功,就是在微软Azure强大的算力以及wiki等海量数据支持下,在Transformer架构基础上,坚持GPT模型及人类反馈的强化学习(RLHF)进行精调的策略下取得的。
国内外企业发展概况
目前,在大模型领域,国内外巨头的竞争已经白热化。OpenAI已成为引领大模型发展的标杆企业。继多模态大模型GPT-4发布后,预计今年四季度OpenAI将发布更为高级的ChatGPT-5版本。微软借助对OpenAI的投资与合作,将旗下Office办公产品全线整合,已在3月下旬推出Copilot Office。5月24日,微软宣布Win11接入GPT-4。
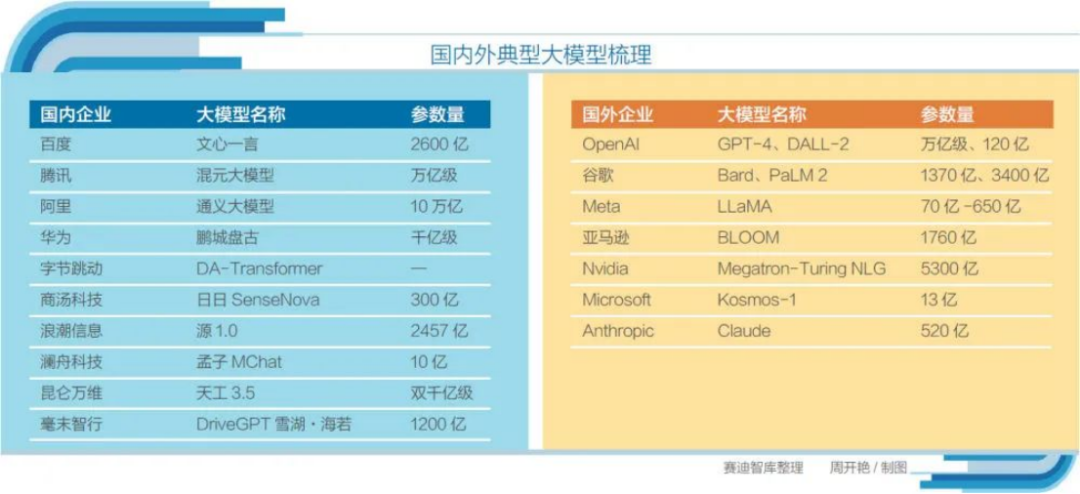
图片来源:赛迪智库
5月10日,微软的直接竞争对手谷歌推出新一代大模型PaLM 2,已有超过25个AI产品和功能全线接入PaLM 2,包括原有对话机器人Bard,AI+办公助手Duet AI、AI+搜索引擎等,Meta则发布大模型LLaMA,加入竞赛。亚马逊与人工智能初创公司Hugging Face合作开发ChatGPT竞品——BLOOM。
国内,产投研各方均已加快布局步伐。一是国内科技龙头企业密集发布自研大模型。百度发布大模型文心一言,阿里发布首个超大规模语言模型通义千问,腾讯混元AI大模型团队推出了万亿级别中文NLP预训练模型HunYuan-NLP-1T。华为发布的鹏城盘古大模型是业界首个千亿级生成和理解中文NLP大模型。
二是投创界积极入局大模型竞赛。美团联合创始人王慧文自带5000万美元入局AI大模型,搜狗前CEO王小川与搜狗前COO茹丽云共同创立百川智能,澜舟科技发布其语言生成模型——孟子MChat可控大模型,西湖心辰也推出了心辰Chat大模型。
三是高校与科研院所积极布局大模型。复旦大学推出国内首个类ChatGPT大模型MOSS,清华大学知识工程实验室与其技术成果转化公司智谱AI发布ChatGLM,中科院自动化所推出多模态大模型紫东太初,IDEA 研究院 CCNL推出开源通用大模型“姜子牙”。
目前大模型面临四个挑战
第一,评估验证:当前针对大模型的评估数据集往往是更像“玩具”的学术数据集,但是这些学术数据集无法完全反应现实世界中形形色色的问题与挑战,因此亟需实际的数据集在多样化、复杂的现实问题上对模型进行评估,确保模型可以应对现实世界的挑战;
第二,伦理道德:模型应该与人类的价值观相符,确保模型行为符合预期,作为一个高级的复杂系统,如果不认真处理这种道德问题,有可能会为人类酝酿一场灾难;
第三,安全隐患:需要更多的做好模型的可解释性、监督管理工作,安全问题应该是模型开发的重要组成部分,而非锦上添花可有可无的装饰;
第四,发展趋势:模型的性能还会随着模型规模的增加而增长吗?这个问题估计 OpenAI 也难以回答,我们针对大模型的神奇现象的了解仍然十分有限,针对大模型原理性的见解仍然十分珍贵。
编辑:黄飞
-
因特网发展的三个阶段2017-08-09 9586
-
未来全球LED智能路灯市场会进入快速发展阶段2020-10-23 1293
-
区块链架构发展的三个阶段2018-11-02 18252
-
视频监控公安行业应用的发展可以分为以下三个阶段2019-02-12 2660
-
第三代半导体原料三个发展阶段的现状与应用分析2019-11-05 6997
-
区块链的技术本质及其三个发展阶段2019-12-24 10299
-
宁夏将分三个阶段全面促进5G网络的建设发展2020-01-16 1258
-
EDA的三个发展阶段2020-05-14 8924
-
数字化医院发展的三个阶段分析2020-08-31 3469
-
蔡坚:封装技术正在经历系统级封装与三维集成的发展阶段2021-01-10 3547
-
元宇宙的发展阶段是怎么样的2021-11-03 4279
-
对智能制造三个发展阶段的认识2022-11-23 4998
-
AI大模型对数据存储技术的发展趋势2023-10-23 2493
-
算力网络发展的三个阶段分别是2023-12-19 2248
-
未来工业AI发展的三个必然阶段2025-10-27 832
全部0条评论

快来发表一下你的评论吧 !
