

图文结合带你搞懂GreatSQL体系架构
描述
很多小伙伴使用了GreatSQL,但是对GreatSQL的底层原理还不是很了解,今天就带大家一起揭开GreatSQL体系架构的神秘面纱!
首先来回顾一张经典的体系架构图:
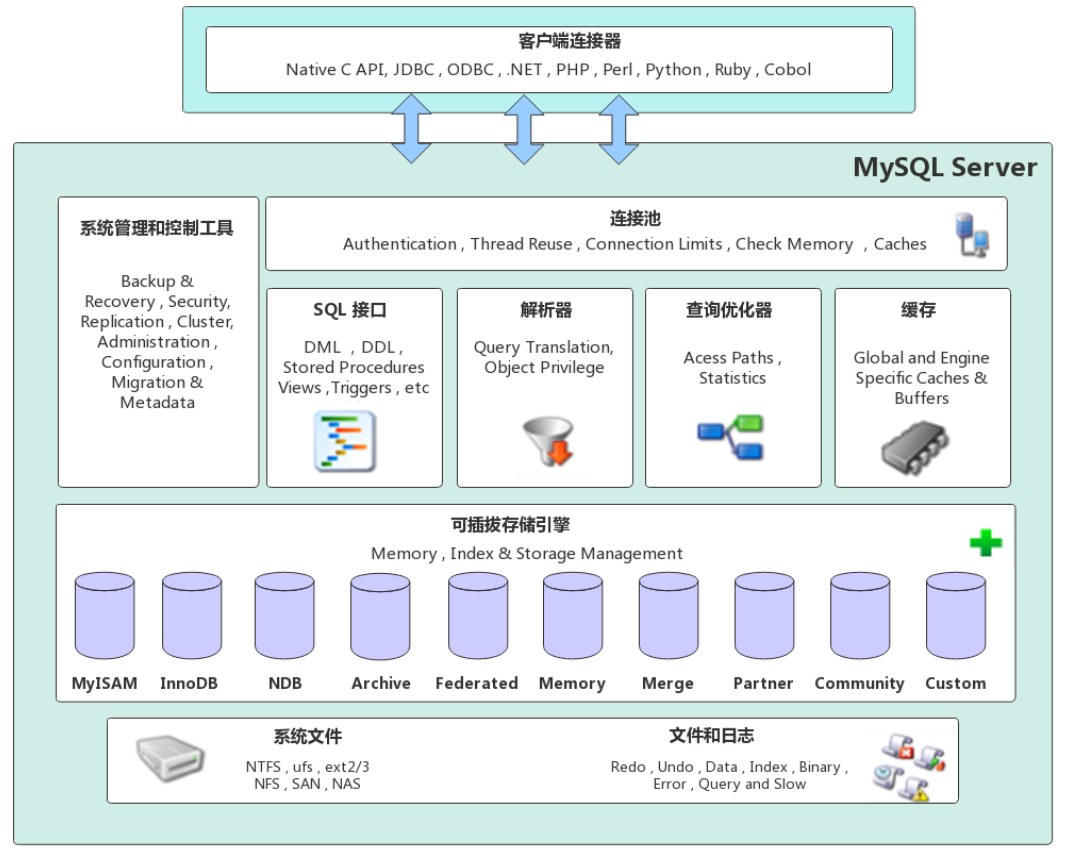
图1_GreatSQL5.7 版本体系架构图
由此可以发现,GreatSQL5.7 由以下几部分组成
- 连接池组件
- 系统管理和控制工具
- SQL接口组件
- 查询解析器
- 查询优化器
- 缓存组件
- 可插拔存储引擎
- 系统和日志文件
GreatSQL数据库区别于其他数据库的一个特点就是其可插拔的表存储引擎,特别需要注意的是,存储引擎是基于表的,而不是数据库。
然而,经典同时也意味着这幅图已经相当陈旧了。在GreatSQL8.0 及更高版本中,查询缓存这一功能已经被移除。
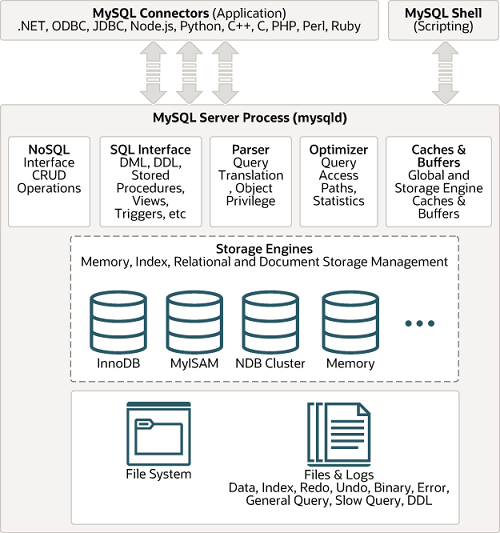
图2_GreatSQL8.0 版本体系架构图
总体来说,GreatSQL8.0 可以分为连接层、服务层、存储引擎层。
一、连接层(Client Connectors)
连接层又名为客户端连接器(Client Connectors)作用是提供与GreatSQL服务器建立的支持。
客户端通过TCP/IP协议与GreatSQL服务器建立连接,每个连接对应一个线程。连接管理还包括了连接池技术,以复用已经建立好的连接,减少重复建立连接的开销。
而且几乎支持所有主流的服务端编程技术,主要完成一些类似于连接处理、授权认证、及相关的安全方案。
会对从 TCP 传输过来的账号密码做身份认证、权限获取
-
用户名或密码不对,会收到
Access denied for user错误,客户端程序结束执行
例如:
$ mysql -uroot -p
ERROR 1045 (28000): Access denied for user 'root'@'localhost' (using password: NO)
- 用户名密码认证通过,会从权限表查出账号拥有的权限与连接关联,之后的权限判断逻辑,都将依赖于此时读到的权限
二、服务层(GreatSQL Server)
服务层是GreatSQL Server的核心,主要包含连接器、分析器、优化器、执行器等,涵盖 GreatSQL 的大多数核心服务功能,以及所有的内置函数(如日期、时间、数学和加密函数等),所有跨存储引擎的功能都在这一层实现,比如存储过程、触发器、视图等。
Ⅰ.SQL Interface: SQL接口
接收用户的SQL命令,并且返回用户需要查询的结果。比如SELECT … FROM就是调用SQL Interface,GreatSQL支持DML、DDL、存储过程、视图、触发器、自定义函数等多种SQL语言接口
同时还支持NoSQL,NoSQL泛指非关系型数据库和数据存储。随着互联网平台的规模飞速发展,传统的关系型数据库已经越来越不能满足需求。从5.6版本开始,GreatSQL就开始支持简单的NoSQL存储功能。GreatSQL8.0 版本对这一功能做了优化,以更灵活的方式实现NoSQL功能,不再依赖模式(schema)。
Ⅱ.Parser: 解析器
在解析器中对 SQL 语句进行语法分析、语义分析。将 SQL 语句分解成数据结构,并将这个结构传递到后续步骤,以后 SQL 语句的传递和处理就是基于这个结构的,并且判断你输入的这个 SQL 语句是否满足 GreatSQL 语法。
Ⅲ.Optimizer: 查询优化器
在开始执行之前,还要先经过优化器的处理。
SQL语句在语法解析之后、查询之前会使用查询优化器确定 SQL 语句的执行路径,生成一个执行计划,可以使用EXPLAIN命令查看执行计划。
这个执行计划表明应该使用哪些索引进行查询(全表检索还是使用索引检索),表之间的连接顺序如何,最后会按照执行计划中的步骤调用存储引擎提供的方法来真正的执行查询,并将查询结果返回给用户。
例如下面的 JOIN 语句:
SELECT * FROM tb1 JOIN tb2 USING(ID) WHERE tb1.a=1 and tb2.a=2;
那就有两种方法可以选择:
-
第一种,
先取表 tb1里 a=1 的记录的ID值,再根据 ID 关联表 tb2 ,然后再判断 tb2 里面 a 的值是否等于 2 -
第二种,
先取表 tb2里面的 a=2 记录的 ID 值,在根据 ID 值关联 tb1 ,再判断 tb1 里面 a 的值是否等于 10
执行的结果肯定是一致的,但是效率就大不相同了,所以我们要选择用小的数据集去驱动大的数据集,也就是小表驱动大表。
Ⅳ.Caches & Buffers:查询缓存组件
GreatSQL 内部维持着一些 Cache 和 Buffer,比如 Query Cache 用来缓存一条 SELECT 语句的执行结果,如果能够在其中找到对应的查询结果,那么就不必再进行查询解析、优化和执行的整个过程了,直接将结果反馈给客户端。
但是在 GreatSQL 8.0 版本及以上中删除了查询缓存功能,因为查询缓存必须要两条SQL语句完全一模一样,否则是不能触发查询缓存,非常的鸡肋~
三、引擎层(Storage Engines)
Ⅰ.存储引擎层
真正的负责了 GreatSQL 中数据的存储和提取,对物理服务器级别维护的底层数据执行操作,服务器通过API与存储引擎进行通信。
存储引擎的优势在于,各式各样的存储引擎都具备独特的特性,从而能够针对特定的应用需求建立不同存储引擎表。
GreatSQL 支持的存储引擎如下:
greatsql> SHOW ENGINES;
+--------------------+---------+----------------------------------------------------------------------------+--------------+------+------------+
| Engine 引擎名称 | Support 支持情况 | Comment 引擎的说明 | Transactions 事务支持 | XA 分布式事务支持 | Savepoints 保存点 |
+--------------------+---------+----------------------------------------------------------------------------+--------------+------+------------+
| FEDERATED | NO | Federated MySQL storage engine | NULL | NULL | NULL |
| PERFORMANCE_SCHEMA | YES | Performance Schema | NO | NO | NO |
| InnoDB | DEFAULT | Percona-XtraDB, Supports transactions, row-level locking, and foreign keys | YES | YES | YES |
| MEMORY | YES | Hash based, stored in memory, useful for temporary tables | NO | NO | NO |
| MyISAM | YES | MyISAM storage engine | NO | NO | NO |
| MRG_MYISAM | YES | Collection of identical MyISAM tables | NO | NO | NO |
| BLACKHOLE | YES | /dev/null storage engine (anything you write to it disappears) | NO | NO | NO |
| CSV | YES | CSV storage engine | NO | NO | NO |
| ARCHIVE | YES | Archive storage engine | NO | NO | NO |
+--------------------+---------+----------------------------------------------------------------------------+--------------+------+------------+
9 rows in set (0.00 sec)
得益于 GreatSQL 数据库的开源特性,用户得以依据存储引擎接口自行编写个性化的存储引擎。当对某一种存储引擎的性能或功能存有疑虑时,可通过优化代码实现所需特性,这正展示了开源所赋予我们的便捷与力量。
Ⅱ.存储层
所有的数据,数据库、表的定义,表的每一行的内容,索引,都是存在 文件系统上,以文件的方式存在的,并完成与存储引擎的交互。当然有些存储引擎比如InnoDB,也支持不使用文件系统直接管理裸设备,但现代文件系统的实现使得这样做没有必要了。在文件系统之下,可以使用本地磁盘,可以使用DAS、NAS、SAN等各种存储系统。
总结
所以可以把 GreatSQL 的架构图简化如下:
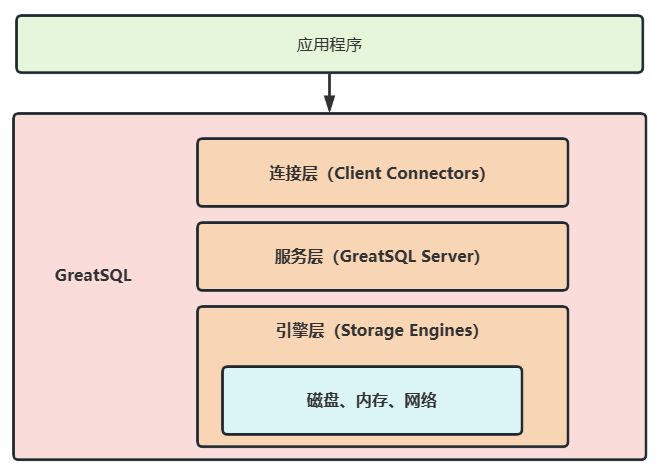
要把架构图牢牢记住,对于以后深入理解 GreatSQL 数据库会有极大帮助!
-
GreatSQL面向金融级应用的数据库2022-06-17 550
-
向量中断能嵌套吗?请结合ARM体系进行阐述2012-05-08 3577
-
如何对ARM+DSP体系架构进行调试?2021-04-28 1883
-
嵌入式Linux系统体系架构2021-11-05 1070
-
谈谈嵌入式处理器的体系架构2021-12-15 1906
-
ARM的体系架构基本概念2022-01-25 1442
-
同济大学嵌入式体系架构2010-02-09 551
-
YDT 1654-2007 IPTV承载网络体系架构2010-07-30 878
-
自制功放机详细教程 简单图文轻松过程2018-01-19 118460
-
Altera开发中RF体系架构解析2018-06-13 5132
-
复杂装备的PHM数据体系架构设计方案2021-06-25 1003
-
88页PPT带你搞懂集成电路封装(附下载)2021-11-18 1819
-
技术干货 | 654页PPT带你搞懂模拟电子(附下载)2022-01-07 1749
-
【硬核科普】3分钟带你搞懂PCB压合工艺2022-08-12 2403
-
一文带你彻底搞懂K8s网络2026-02-06 960
全部0条评论

快来发表一下你的评论吧 !
