

简单盘点一下影响PCIe链路性能的因素
接口/总线/驱动
描述
在PCIe链路中,数据的传输性能一般不会超过链路的最大带宽,通过将PCIe设备的硬件、固件优化极致,可以使性能发挥尽可能接近链路极限,但即便如此,编码层面的开销、链路层和物理层开销,以及一些参数设定,仍然会对PCIe链路的实际性能带来影响。
本文将对这些影响PCIe链路性能的因素做一个简单盘点,看看它们是如何影响PCIe实际性能发挥的。
数据编码
近年来,PCIe技术迎来了快速发展,从1.0到5.0,每一次技术迭代都带来了数据传输速率的翻倍提升,为NVMe SSD等PCIe设备实现性能的快速增长打下基础。细心的朋友肯定发现了,PCIe从1.0的2.5GT/s一路发展到5.0的32GT/s,它们并没有严格遵循等比关系,这里引出影响PCIe实际传输效率的第一个因素——数据编码。
在信号高速传输中,连续的多个0或多个1会导致信号失真和时钟恢复困难等问题。为避免此现象发生,PCIe 1.0和2.0使用了8b/10b编码机制,通过将8bit数据转换为10bit数据进行传输,使得信号中的0和1数量尽可能相等,并避免连续的多个0或多个1出现。如下图所示,数据 000 0000经8b/10b编码后,输出 100111 0100 或 011000 1011。
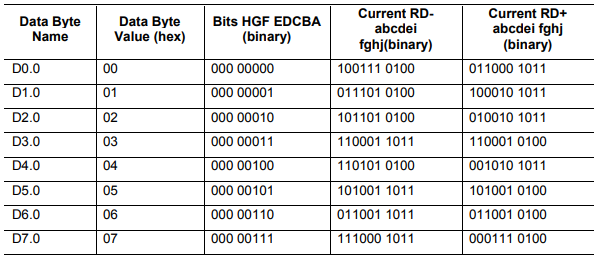
部分8b/10b Data Symbol Codes(引自PCIe 1.0 Spec) 8b/10b编码极大优化了PCIe链路的信号质量,但由此也带来了20%的编码开销,这也是PCIe 1.0、PCIe 2.0的数据传输速率明为2.5GT/s、5GT/s,实为2GT/s、4GT/s的原因。
PCIe 3.0、PCIe 4.0和PCIe 5.0使用更加先进的128b/130b编码以及新的扰码方式,以达到直流均衡的效果。同时,由于有效数据载荷占到数据流的98.5%,可以在大幅提高数据传输速率的同时,使得数据编码/扰码带来的损耗可以忽略不计;PCIe 6.0则改用PAM4调制,在不改变时钟频率的前提下实现传输带宽翻倍(即1次信号可以表述2bit数据),同时1b/1b的编码方式对传输效率无影响。 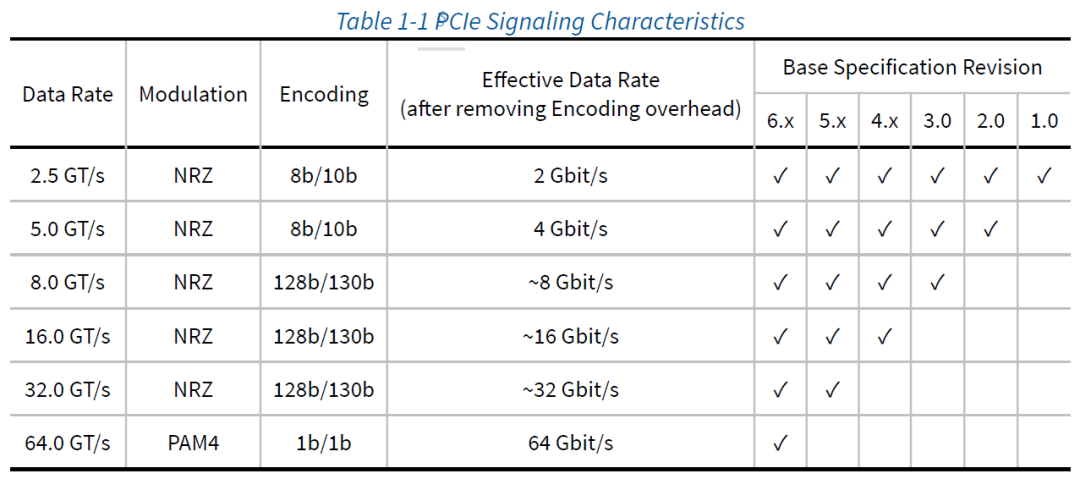
不同PCIe速率对应的数据编码与数据传输速率(引自PCIe 6.0 Spec)
链路层和物理层
在PCIe链路中,Host与PCIe设备(如NVMe SSD)之间的数据交换以TLP(Transaction Layer Packet)数据包的形式,由发送端事务层到接收端事务层进行传输。TLP由Header、Payload、ECRC组成,其中,Header为必需项,包含了该TLP的起始标识符、事务类型、请求方ID、需要发送的目标地址等重要信息,大小为12或16字节;Payload为可选项,是TLP中承载的有效数据,最大4096字节,如果该TLP并不需要传输数据,则Payload为0;ECRC也是可选项,大小为4字节,是对Header、Payload的校验,防止TLP本身出错。

TLP数据包构成 TLP在发送过程中,会经过“加头加尾”的过程——数据链路层添加Sequence Number与LCRC信息,防止数据丢包并避免链路层的错误产生;随后经过物理层,会添加开始与结束信息(结束信息自PCIe 3.0开始不再适用)。TLP在接收过程中,则会经过“掐头去尾”的过程——依照物理层、数据链路层、事务层的顺序,对TLP层层剥茧,识别和校验。毫无疑问,Header、ECRC、Sequence、LCRC、开始信息都会占用额外的数据带宽。
MPS
Payload是TLP中承载的最终有效用户数据,最大长度4096字节。MPS(Maximum Payload Size)是对PCIe链路中最大Payload字节数的设定,根据PCIe Spec规定,分为128B、256B、512B、1024B、2048B、4096B六种,MPS越大,TLP中可以承载的有效数据占比就越高。
但是,MPS并非越大越好。较大的MPS会导致每个数据包的大小增加,进而增加传输负载,使得延迟增加,错误率上升,甚至降低系统性能。常见MPS一般集中在128B、256B、512B三种。在PCIe链路初始化过程中,会根据RC、PCIe Switch、Endpoint的MPS支持情况,按照木桶效应将MPS设定为相同的值。以下图为例,Endpoint 3支持的MPS为128 Bytes,则该PCIe链路只能以最高128 Bytes MPS运行。 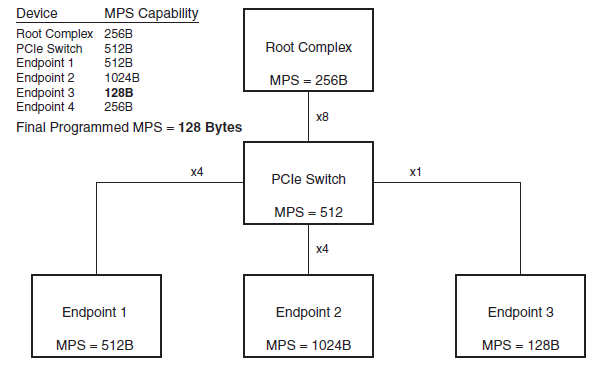
PCIe链路MPS设定示意(引自Xilinx)
MRRS
在PCIe链路中,为平衡带宽分配,防止某个读请求过大导致独占PCIe带宽,PCIe Spec还规定了名为MRRS(Maximum Read Request Size)的最大读请求设定,并同样分为128B、256B、512B、1024B、2048B、4096B六种。读请求并不包含Payload。在Endpoint向Host请求较多数据时(如,将大量数据写入NVMe SSD),过低的MRRS设定会导致读TLP过多,并带来大量的ACK/NAK DLLP额外开销。
MPS、MRRS都是影响PCIe传输效率的重要参数,但二者并没有绝对相关性。通常,MRRS会等于或大于MPS,以带来更高的效率。如,MPS设定为128B,MRRS设定为512B,当发起512B数据读请求时,数据将分为4个TLP被传输。
以上是影响PCIe链路传输效率的几个重要因素,它们客观存在且不可避免。作为技术实力领先的NVMe SSD产品和解决方案供应商,我们要做的,是不管产品处在何种PCIe接口速率下,亦或何种不同的硬件搭配、参数设置,都尽可能发挥出产品应有的性能,为企业业务的稳定开展带来支撑。
审核编辑:刘清
-
调试PCIE链路动态均衡介绍2024-12-05 3525
-
盘点一下CST电磁仿真软件的求解器2023-11-20 9113
-
[PCIe] [电源管理] 面向硬件的ASPM链路状态和L1子状态2022-01-06 2069
-
PCIe设备的低功耗状态要求2022-01-03 3454
-
PCIe设备的低功耗状态2021-12-28 1450
-
PCIe 3.0/4.0的链路均衡的工作原理2020-11-25 5084
-
AC701能否通过Artix 7的PCIe链路与PC通信?2019-09-10 2606
-
盘点一下哪些手机支持5G网络呢2019-08-22 18246
-
时钟抖动对高速链路性能的影响2018-09-19 2451
-
PCIe总线中的链路初始化与训练2018-06-05 11921
-
全链路压测一招搞定,阿里云性能测试铂金版发布2018-01-30 2432
-
WLAN时变信道下链路性能改进2011-02-23 867
全部0条评论

快来发表一下你的评论吧 !
