

谷歌新作SPAE:GPT等大语言模型可以通过上下文学习解决视觉任务
描述
LLM 的能力还可以发挥到机器学习的更多子领域。
当前,大型语言模型(LLM)已经掀起自然语言处理(NLP)领域的变革浪潮。我们看到 LLM 具备强大的涌现能力,在复杂的语言理解任务、生成任务乃至推理任务上都表现优异。这启发人们进一步探索 LLM 在机器学习另一子领域 —— 计算机视觉(CV)方面的潜力。 LLM 的一项卓越才能是它们具备上下文学习的能力。上下文学习不会更新 LLM 的任何参数,却在各种 NLP 任务中却展现出了令人惊艳的成果。那么,GPT 能否通过上下文学习解决视觉任务呢? 最近,来自谷歌和卡内基梅隆大学(CMU)的研究者联合发表的一篇论文表明:只要我们能够将图像(或其他非语言模态)转化为 LLM 能够理解的语言,这似乎是可行的。

SPAE: Semantic Pyramid AutoEncoder for Multimodal Generation with Frozen LLMs 代码:https://github.com/google-research/magvit/ 论文地址:https://arxiv.org/abs/2306.17842 这篇论文揭示了 PaLM 或 GPT 在通过上下文学习解决视觉任务方面的能力,并提出了新方法 SPAE(Semantic Pyramid AutoEncoder)。这种新方法使得 LLM 能够执行图像生成任务,而无需进行任何参数更新。这也是使用上下文学习使得 LLM 生成图像内容的首个成功方法。 我们先来看一下通过上下文学习,LLM 在生成图像内容方面的实验效果。 例如,在给定上下文中,通过提供 50 张手写图像,论文要求 PaLM 2 回答需要生成数字图像作为输出的复杂查询:
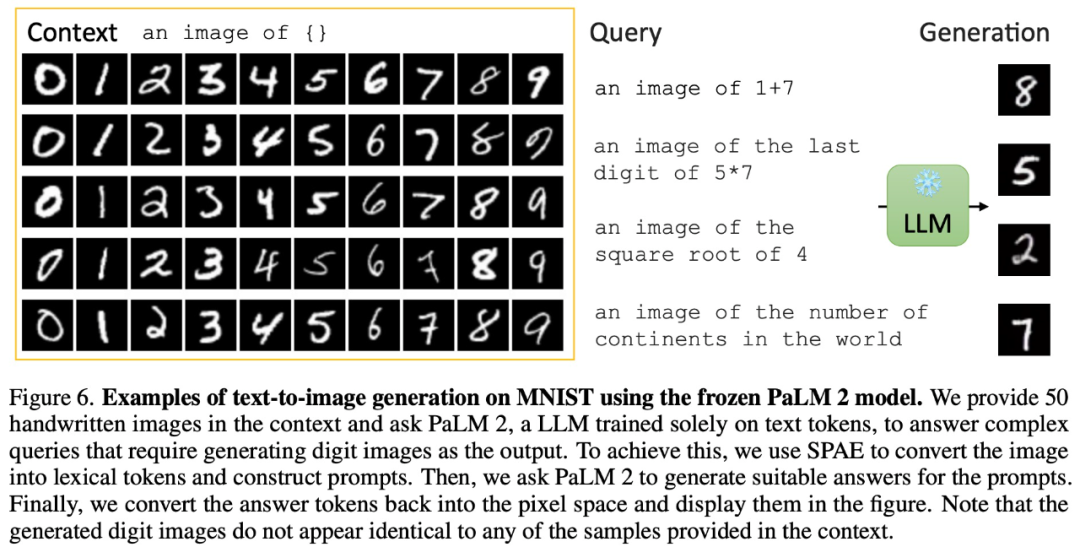
还能在有图像上下文输入的情况下生成逼真的现实图像:

除了生成图像,通过上下文学习,PaLM 2 还能进行图像描述:

还有与图像相关问题的视觉问答:

甚至可以去噪生成视频:

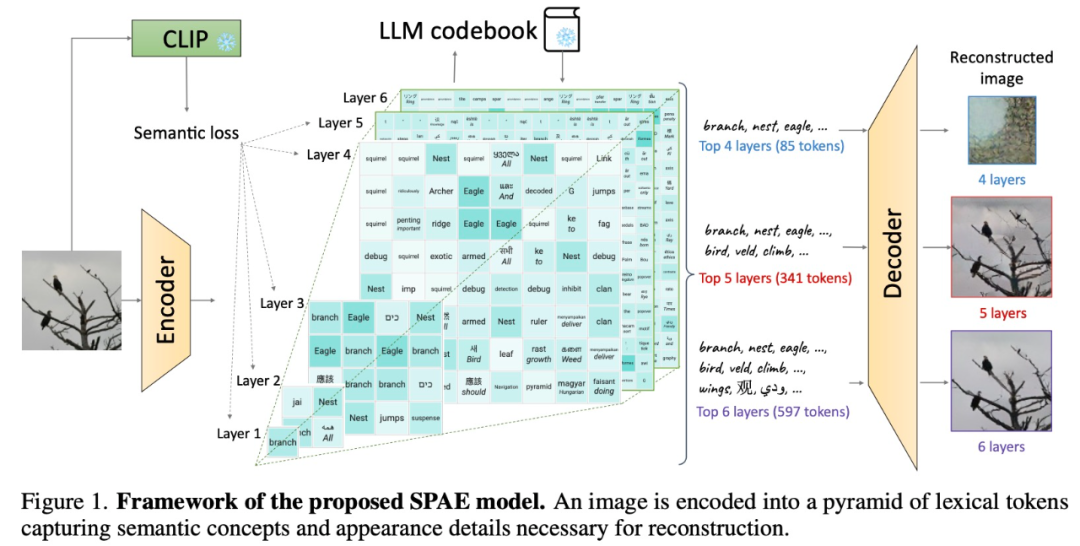
方法概述 实际上,将图像转化为 LLM 能够理解的语言,是在视觉 Transformer(ViT)论文中就已经研究过的问题。在 Google 和 CMU 的这篇论文中,他们将其提升到了一个新的层次 —— 使用实际的单词来表示图像。 这种方法就像建造一个充满文字的塔楼,捕捉图像的语义和细节。这种充满文字的表示方法让图像描述可以轻松生成,并让 LLM 可以回答与图像相关的问题,甚至可以重构图像像素。
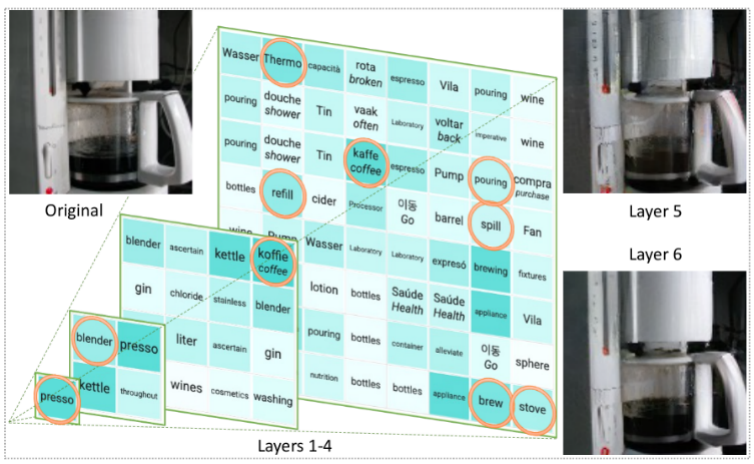
具体来说,该研究提出使用经过训练的编码器和 CLIP 模型将图像转换为一个 token 空间;然后利用 LLM 生成合适的词法 token;最后使用训练有素的解码器将这些 token 转换回像素空间。这个巧妙的过程将图像转换为 LLM 可以理解的语言,使我们能够利用 LLM 在视觉任务中的生成能力。
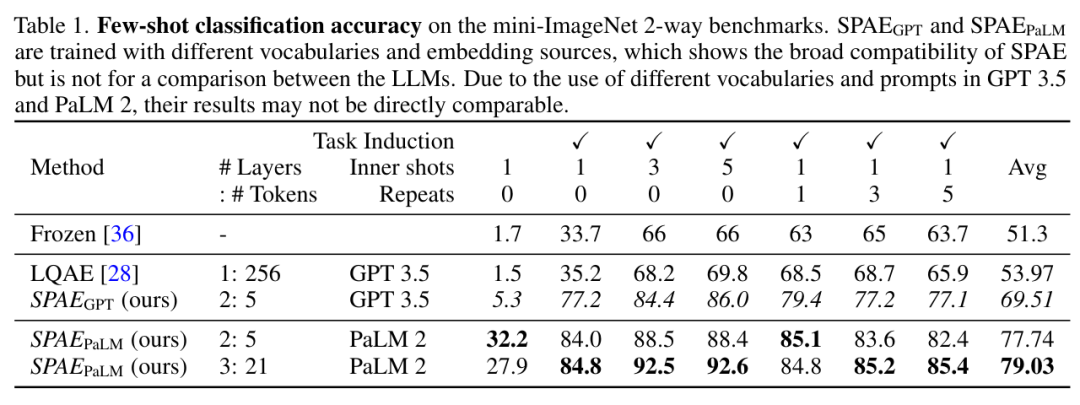
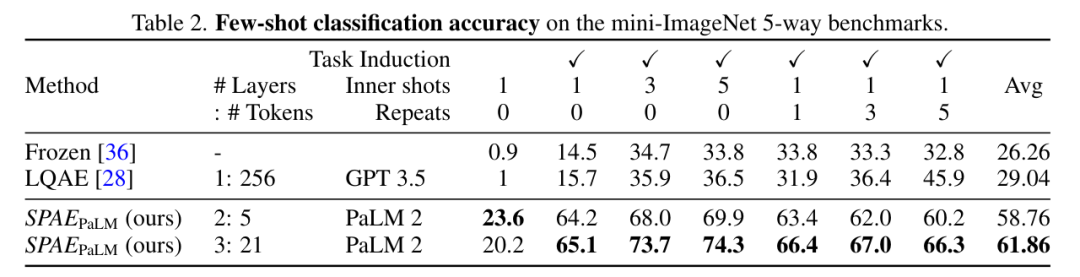
实验及结果 该研究将 SPAE 与 SOTA 方法 Frozen 和 LQAE 进行了实验比较,结果如下表 1 所示。SPAEGPT 在所有任务上性能均优于 LQAE,且仅使用 2% 的 token。
总的来说,在 mini-ImageNet 基准上的测试表明,SPAE 方法相比之前的 SOTA 方法提升了 25% 的性能。
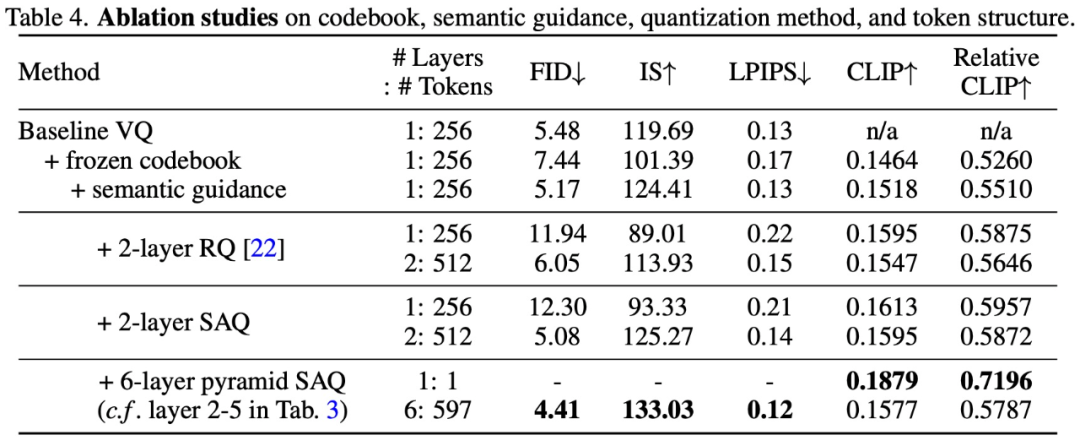
为了验证 SPAE 设计方法的有效性,该研究进行了消融实验,实验结果如下表 4 和图 10 所示:

-
为什么transformer性能这么好?Transformer的上下文学习能力是哪来的?2023-09-25 2511
-
【大语言模型:原理与工程实践】揭开大语言模型的面纱2024-05-04 886
-
【大语言模型:原理与工程实践】大语言模型的基础技术2024-05-05 1384
-
《具身智能机器人系统》第7-9章阅读心得之具身智能机器人与大模型2024-12-24 2455
-
关于进程上下文、中断上下文及原子上下文的一些概念理解2018-09-06 3899
-
进程上下文与中断上下文的理解2018-12-11 3432
-
进程上下文/中断上下文及原子上下文的概念2021-01-13 1127
-
中断中的上下文切换详解2023-03-23 1525
-
终端业务上下文的定义方法及业务模型2010-03-06 649
-
基于上下文相似度的分解推荐算法2017-11-27 983
-
Web服务的上下文的访问控制策略模型2018-01-05 963
-
我们能否扩展现有的预训练 LLM 的上下文窗口2023-06-30 1628
-
首篇!Point-In-Context:探索用于3D点云理解的上下文学习2023-07-13 2011
-
更强更通用:智源「悟道3.0」Emu多模态大模型开源,在多模态序列中「补全一切」2023-07-16 1673
-
大语言模型如何处理上下文窗口中的输入2025-12-03 906
全部0条评论

快来发表一下你的评论吧 !
