

Redis的LRU与LFU算法实现
描述
一、前言
Redis是一款基于内存的高性能NoSQL数据库,数据都缓存在内存里, 这使得Redis可以每秒轻松地处理数万的读写请求。
相对于磁盘的容量,内存的空间一般都是有限的,为了避免Redis耗尽宿主机的内存空间,Redis内部实现了一套复杂的缓存淘汰策略来管控内存使用量。
Redis 4.0版本开始就提供了8种内存淘汰策略,其中4种都是基于LRU或LFU算法实现的,本文就这两种算法的Redis实现进行了详细的介绍,并阐述其优劣特性。
二、Redis的LRU实现
在介绍Redis LRU算法实现之前,我们先简单介绍一下原生的LRU算法。
2.1 LRU算法原理
LRU(The Least Recently Used)是最经典的一款缓存淘汰算法,其原理是 :如果一个数据在最近一段时间没有被访问到,那么在将来它被访问的可能性也很低,当数据所占据的空间达到一定阈值时,这个最少被访问的数据将被淘汰掉。
如今,LRU算法广泛应用在诸多系统内,例如Linux内核页表交换,MySQL Buffer Pool缓存页替换,以及Redis数据淘汰策略。
以下是一个LRU算法示意图:
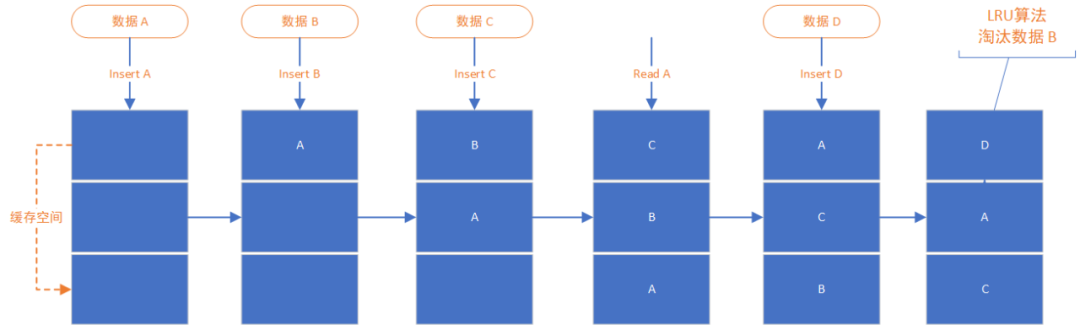
向一个缓存空间依次插入三个数据A/B/C,填满了缓存空间;
读取数据A一次,按照访问时间排序,数据A被移动到缓存头部;
插入数据D的时候,由于缓存空间已满,触发了LRU的淘汰策略,数据B被移出,缓存空间只保留了D/A/C。
一般而言,LRU算法的数据结构不会如示意图那样,仅使用简单的队列或链表去缓存数据,而是会采用Hash表 + 双向链表的结构,利用Hash表确保数据查找的时间复杂度是O(1),双向链表又可以使数据插入/删除等操作也是O(1)。
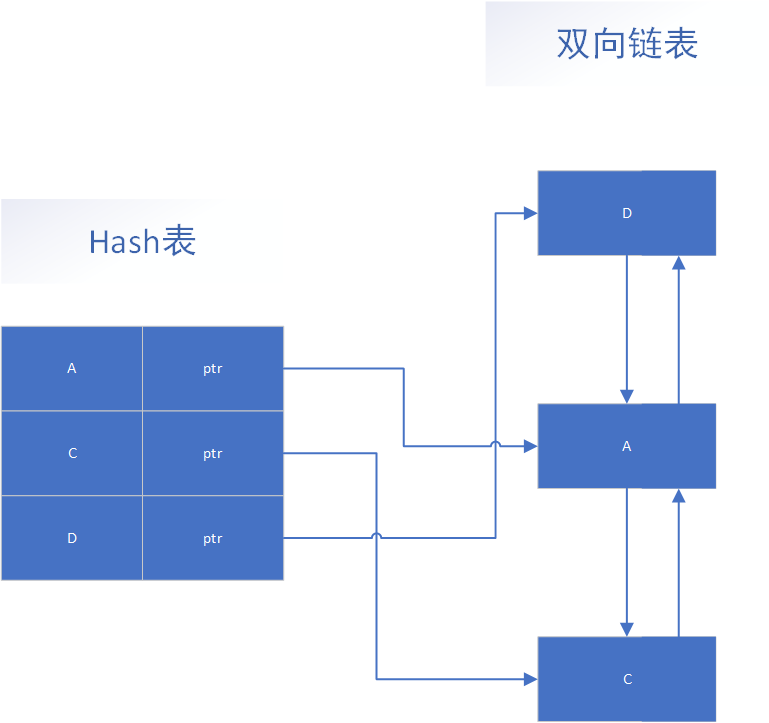
如果你很熟悉Redis的数据类型,你会发现这个LRU的数据结构与ZSET类型OBJ_ENCODING
_SKIPLIST编码结构相似,只是LRU数据排序方式更简单一些。
2.2 Redis LRU算法实现
按照官方文档的介绍,Redis所实现的是一种近似的LRU算法,每次随机选取一批数据进行LRU淘汰,而不是针对所有的数据,通过牺牲部分准确率来提高LRU算法的执行效率。
Redis内部只使用Hash表缓存了数据,并没有创建一个专门针对LRU算法的双向链表,之所以这样处理也是因为以下几个原因:
筛选规则,Redis是随机抽取一批数据去按照淘汰策略排序,不再需要对所有数据排序;
性能问题,每次数据访问都可能涉及数据移位,性能会有少许损失;
内存问题,Redis对内存的使用一向很“抠门”,数据结构都很精简,尽量不使用复杂的数据结构管理数据;
策略配置,如果线上Redis实例动态修改淘汰策略会触发全部数据的结构性改变,这个Redis系统无法承受的。
redisObject是Redis核心的底层数据结构,成员变量lru字段用于记录了此key最近一次被访问的LRU时钟(server.lruclock),每次Key被访问或修改都会引起lru字段的更新。
#define LRU_BITS 24
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
int refcount;
void *ptr;
} robj;
默认的LRU时钟单位是秒,可以修改LRU_CLOCK_RESOLUTION宏来改变单位,LRU时钟更新的频率也和server.hz参数有关。
unsigned int LRU_CLOCK(void) {
unsigned int lruclock;
if (1000/server.hz <= LRU_CLOCK_RESOLUTION) {
atomicGet(server.lruclock,lruclock);
} else {
lruclock = getLRUClock();
}
return lruclock;
}
由于lru字段仅占用了24bit的空间,按秒为单位也只能存储194天,所以可能会出现一个意想不到的结果,即间隔194天访问Key后标记的时间戳一样,Redis LRU淘汰策略局部失效。
2.3 LRU算法缺陷
LRU算法仅关注数据的访问时间或访问顺序,忽略了访问次数的价值,在淘汰数据过程中可能会淘汰掉热点数据。
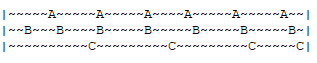
如上图所示,时间轴自左向右,数据A/B/C在同一段时间内被分别访问的数次。数据C是最近一次访问的数据,按照LRU算法排列数据的热度是C>B>A,而数据的真实热度是B>A>C。
这个是LRU算法的原理性问题,自然也会在Redis 近似LRU算法中呈现,为了解决这个问题衍生出来LFU算法。
三、Redis的LFU实现
3.1 LFU算法原理
LFU(Least frequently used)即最不频繁访问,其原理是:如果一个数据在近期被高频率地访问,那么在将来它被再访问的概率也会很高,而访问频率较低的数据将来很大概率不会再使用。
很多人看到上面的描述,会认为LFU算法主要是比较数据的访问次数,毕竟访问次数多了自然访问频率就高啊。实际上,访问频率不能等同于访问次数,抛开访问时间谈访问次数就是在“耍流氓”。
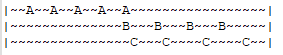
在这段时间片内数据A被访问了5次,数据B与C各被访问了4次,如果按照访问次数判断数据热度值,必然是A>B=C;如果考虑到时效性,距离当前时间越近的访问越有价值,那么数据热度值就应该是C>B>A。因此,LFU算法一般都会有一个时间衰减函数参与热度值的计算,兼顾了访问时间的影响。
LFU算法实现的数据结构与LRU一样,也采用Hash表 + 双向链表的结构,数据在双向链表内按照热度值排序。如果某个数据被访问,更新热度值之重新插入到链表合适的位置,这个比LRU算法处理的流程复杂一些。
3.2 Redis LFU算法实现
Redis 4.0版本开始增加了LFU缓存淘汰策略,也采用数据随机筛选规则,然后依据数据的热度值排序,淘汰掉热度值较低的数据。
3.2.1 LFU算法代码实现
LFU算法的实现没有使用额外的数据结构,复用了redisObject数据结构的lru字段,把这24bit空间拆分成两部分去使用。
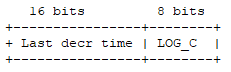
由于记录时间戳在空间被压缩到16bit,所以LFU改成以分钟为单位,大概45.5天会出现数值折返,比LRU时钟周期还短。
低位的8bit用来记录热度值(counter),8bit空间最大值为255,无法记录数据在访问总次数。
LFU热度值(counter)的算法实现:
#define LFU_INIT_VAL 5
/* Logarithmically increment a counter. The greater is the current counter value
* the less likely is that it gets really implemented. Saturate it at 255. */
uint8_t LFULogIncr(uint8_t counter) {
if (counter == 255) return 255;
double r = (double)rand()/RAND_MAX;
double baseval = counter - LFU_INIT_VAL;
if (baseval < 0) baseval = 0;
double p = 1.0/(baseval*server.lfu_log_factor+1);
if (r < p) counter++;
return counter;
}
counter 小于或等于 LFU_INIT_VAL 时候,数据一旦被访问命中, counter接近100%概率递增1;
counter 大于 LFU_INIT_VAL 时候,需要先计算两者差值,然后作为分母的一部分参与递增概率的计算;
随着counter 数值的增大,递增的概率逐步衰减,可能数次的访问都不能使其数值加1;
当counter 数值达到255,就不再进行数值递增的计算过程。
LFU counter的计算也并非“一尘不变”,为了适配各种业务数据的特性,Redis在LFU算法实现过程中引入了两个可调参数:

热度值counter的时间衰减函数:
unsigned long LFUDecrAndReturn(robj *o) {
unsigned long ldt = o->lru >> 8;
unsigned long counter = o->lru & 255;
unsigned long num_periods = server.lfu_decay_time ? LFUTimeElapsed(ldt) / server.lfu_decay_time : 0;
if (num_periods)
counter = (num_periods > counter) ? 0 : counter - num_periods;
return counter;
}
阅读完以上的内容,是否感觉似曾相似?实际上LFU counter计算过程就是对访问次数进行了数值归一化,将数据访问次数映射成热度值(counter),数值的范围也从[0,+∞)映射到另一个维度的[0,255]。
3.3.2 LFU Counter分析
仅从代码层面分析研究Redis LFU算法实现会比较抽象且枯燥,无法直观的呈现counter递增概率的算法效果,以及counter数值与访问次数的关系。
在lfu_log_factor为默认值10的场景下,利用Python实现Redis LFU算法流程,绘制出LFU counter递增概率曲线图:
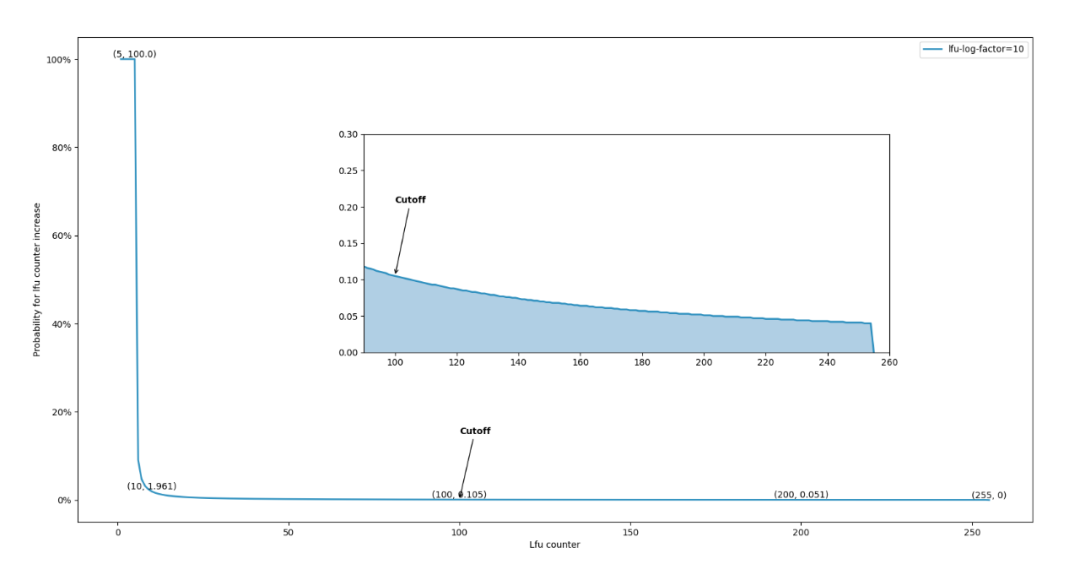
可以清晰的观察到,当LFU counter数值超过LFU_INIT_VAL之后,曲线出现了垂直下降,递增概率陡降到0.2%左右,随后在底部形成一个较为缓慢的衰减曲线,直至counter数值达到255则递增概率归于0,贴合3.3.1章节分析的理论。
保持Redis系统配置默认值的情况下,对同一个数据持续的访问,并采集此数据的LFU counter数值,绘制出LFU counter数值曲线图:
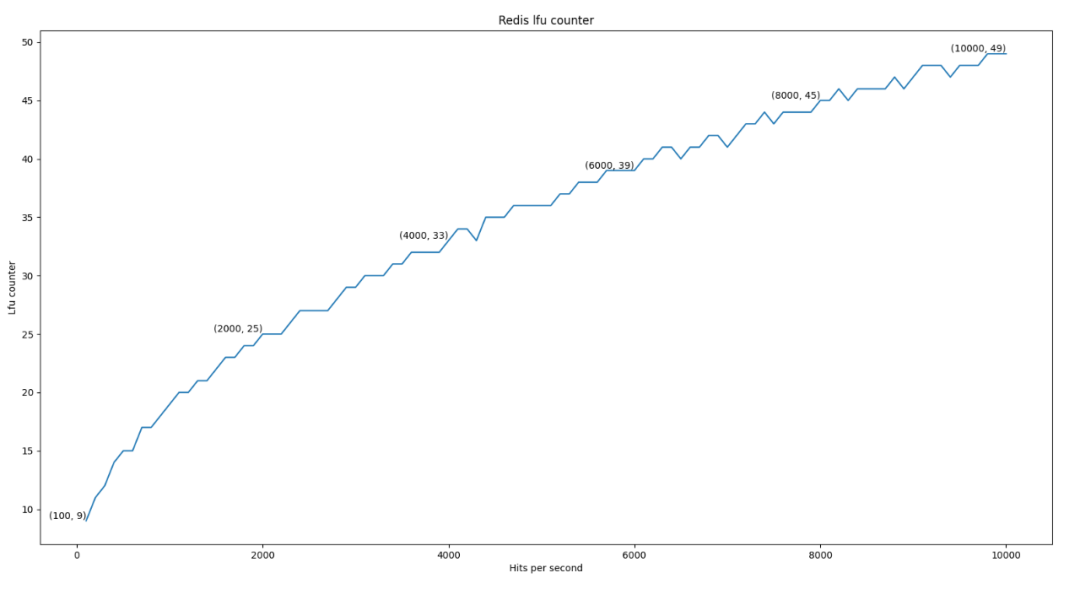
随着访问次数的不断增加,LFU counter数值曲线呈现出爬坡式的递增,形态趋近于根号曲线,由此推测出以下观点:
在访问次数相同的情况下,counter数值不是固定的,大概率在一个范围内波动;
在同一个时间段内,数据之间访问次数相差上千次,才可以通过counter数值区分出哪些数据更热,而“温”数据之间可能很难区分热度。
四、总结
通过对Redis LRU与LFU算法实现的介绍,我们可以大体了解两种算法策略的优缺点,在Redis运维过程中,可以依据业务数据的特性去选择相应的算法。
如果业务数据的访问较为均匀,OPS或CPU利用率一般不会出现周期性的陡升或陡降,数据没有体现出相对的“冷热”特性,即建议采用LRU算法,可以满足一般的运维需求。
相反,业务具备很强时效性,在活动推广或大促期间,业务某些数据会突然成为热点数据,监控上呈现出OPS或CPU利用率的大幅波动,为了能抓取热点数据便于后期的分析或优化,建议一定要配置成LFU算法。
在Used_memory接近Maxmemory的情况下,Redis一直都采用随机的方式筛选数据,且筛选的个数极其有限,所以,LFU算法无法展现出较大的优势,也可能会淘汰掉比较热的数据。
审核编辑:刘清
-
关于LRU(Least Recently Used)的逻辑实现2024-11-12 1982
-
Redis的LRU实现和应用2023-12-15 1596
-
redis的lru原理2023-12-05 1424
-
redis集群中的hash一致性算法的理解2023-12-04 1630
-
Redis工具集的实现和使用2023-12-03 2112
-
LRU缓存模块最佳实践2023-09-30 1986
-
设计并实现一个满足LRU约束的数据结构2023-06-07 1739
-
Redis实现限流的三种方式分享2023-02-22 2049
-
一文读懂缓存淘汰算法:LFU 算法2020-08-25 10820
-
Redis Cluster的基本原理及实现细节2017-09-28 1042
-
基于BWDSP指令Cache的PLRU替换算法研究2013-09-25 1062
全部0条评论

快来发表一下你的评论吧 !
