

摄像头深度检测主要技术方法
光电显示
描述
摄像头测距
深度检测主要技术方法:
1.双目匹配(双RGB摄像头+可选的照明系统)
三角测量原理即目标点在左右两幅视图中成像的横坐标之间存在的差异(视差Disparity),与目标点到成像平面的距离成反比例的关系:Z = ft/d;得到深度信息。
双目匹配采用三角测量原理完全基于图像处理技术,通过寻找两个图像中的相同的特征点得到匹配点,从而得到深度值。
双目测距中光源是环境光或者白光这种没有经过编码的光源,图像识别完全取决于被拍摄的物体本身的特征点,因此匹配一直是双目的一个难点。
匹配的精度和正确性很难保证,因此出现了结构光技术来解决匹配问题。
技术点:立体匹配算法,一般步骤:匹配代价计算,匹配代价叠加,视差获取,视差细化(亚像素级)
优点:给定的工作条件下,较好效果,硬件简单。
缺点:双目使用的是物体本身的特征点,对表面颜色和纹理特征不明显的物体失效。
因为结构光光源带有很多特征点或者编码,因此提供了很多的匹配角点或者直接的码字,可以很方便的进行特征点的匹配。
换句话说,不需要使用被摄物体本身的特征点,因此能提供很好的匹配结果。
2.一般结构光(一个RGB摄像头+结构光投射器(红外)+结构光深度感应器(CMOS))
结构光测距的不同点在于对投射光源进行了编码或者说特征化。这样拍摄的是被编码的光源投影到物体上被物体表面的深度调制过的图像。
结构光基本原理:
通过投影一个预先设计好的图案作为参考图像(编码光源),将结构光投射至物体表面,再使用摄像机接收该物体表面反射的结构光图案,这样,同样获得了两幅图像,
一幅是预先设计的参考图像,另外一幅是相机获取的物体表面反射的结构光图案,由于接收图案必会因物体的立体型状而发生变形,故可以通过该图案在摄像机上的位置和形变程度来计算物体表面的空间信息。普通的结构光方法仍然是部分采用了三角测距原理的深度计算。
同样是进行图像匹配,这种方法比双目匹配好的地方在于,参考图像不是获取的,而是经过专门设计的图案,因此特征点是已知的,而且更容易从测试图像中提取。
结构光采用三角视差测距,基线(光源与镜头光心的距离)越长精度越高。
技术点:提供什么样的辅助信息来帮助快速而精确的对应点匹配是结构光编码方法的衡量标准。
优点:成熟,经验证,可量产
缺点:有限的供应商,技术和供应链门槛,阳光干扰敏感,多设备之间存在严重干扰
3.Light coding(激光散斑光源)
与结构光不同,Light coding的光源为“激光散斑”,是激光照射到粗糙物体或穿透毛玻璃后随机形成的衍射斑点。这些散斑具有高度的随机性,而且会随着距离的不同而变换图案。也就是说空间中任意两处的散斑图案都是不同的。
只要在空间中打上这样的光,整个空间都被做了标记,把一个物体放进这个空间,只要看看物体上面的散斑图案,就可以知道这个物体在什么位置了。当然在这之前要把整个空间的散斑图案都记录下来,所以要先做一次光源标定。primesense公司的三维测量使用的就是激光散斑技术。primesense将该技术称为光源标定技术。光源标定技术在整个空间中每隔一段距离选取一个参考平面,把参考平面上的散斑图案保存下来。
Light coding不是通过空间几何关系求解的,它的测量精度只和标定时取得参考面的密度有关,参考面越密测量越精确。不用为了提高精度而将基线拉宽。
缺点:激光器发出的编码光斑容易被太阳光淹没掉
4. 单目相机测距
三角测距法
还记得文章开头的那个小孔相机模型吗?
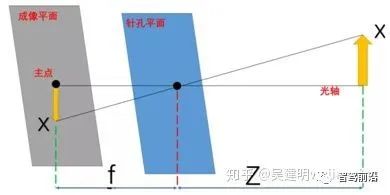
三角测距法就是基于这个理想的,简单的模型,进行的,在知道物体大小,透镜焦距F,并测出图像中的物体长度后,就可以基于下面公式进行计算长度Z了。

像素块测距法
这个方法是玩openmv时知道的,openmv封装的单目测距算法,就是将目标对象先在固定的距离(10cm)拍一张照片,测出照片中该物体的像素面积。得到一个比例系数K,然后将物体挪到任意位置,就可以根据像素面积估算距离了。 不过这两种方法肯定鲁棒性都不咋样。
5. 相机标定
在上文,相机内参加上相机外参一共有至少8个参数,而我们要想消除相机的畸变,就要靠相机标定来求解这8个未知参数。
说完相机模型,又要说一下相机标定了,相机标定是为了求解上面这8个参数的,那求解出这8个参数可以干什么呢?可以进行软件消除畸变,也就是在得知上面8个参数后,利用上面罗列的数学计算式,将每个偏移的像素点归位。
标定需要用到一个叫标定板的东西,有很多种类,但常用的大概就是棋盘图了,棋盘要求精度需要很高,格子是正方形,买一张标定板很贵的,在csdn上下棋盘图也要画好多c币,所以大家可以用word画一张,很简单的,只要做一个5列7行的表格,拉大到全页,再设置每个格子的宽高来将它设为正方形再涂色就可以了。这张图里有符号,但打印出来就没有了,建议大家自己画一张就OK了。

编辑:黄飞
-
基于FPGA的摄像头心率检测装置设计2024-07-01 984
-
摄像头的主要结构和组件2009-04-14 6553
-
LabVIEW获取网络摄像头方法2013-04-14 154293
-
最新摄像头技术给车辆以强大的视觉功能2017-04-12 7310
-
摄像头如何使用?2020-11-06 4338
-
回收手机摄像头 收购手机摄像头2021-07-05 3066
-
专业回收手机摄像头 收购手机摄像头价格高2021-10-16 1648
-
摄像头镀膜的主要作用是什么?2021-11-02 8177
-
数字摄像头介绍2022-11-08 1136
-
飞思卡尔摄像头的赛道参数检测方法2011-07-06 743
-
摄像头如何进行气密性防水检测2021-04-07 2059
-
车载摄像头防水检测重要吗?-海瑞思2023-05-15 1840
-
车载摄像头防水检测的作用2023-07-21 2544
-
技术前沿:摄像头模组2023-09-12 10069
-
多光谱火焰检测摄像头2024-12-11 1486
全部0条评论

快来发表一下你的评论吧 !
