

LinkedIn图数据库 LIquid:为9.3亿会员提供实时数据访问
电子说
描述
最近,LinkedIn 分享了其图数据库 LIquid 是如何自动索引和实时访问会员、学校、技能、公司、职位、工作、事件等之间的关系数据的。这个知识图谱被称为 LinkedIn 的“Economic Graph”,有 2700 亿条边,并且还在不断增长,目前每秒处理 200 万次查询。
LinkedIn 将其“你可能认识的人(People You May Know,PYMK)”推荐系统从传统的 GAIA 系统迁移到了 LIquid。这一变化显著改善了每秒查询数(QPS)、延迟和 CPU 利用率。QPS 从 120 增加到 18000,延迟从超过 15 秒下降到平均 50 毫秒以下,CPU 利用率下降了 3 倍以上。LIquid 还引入了新的数据库索引技术,支持实时数据查询,实现了即时推荐。
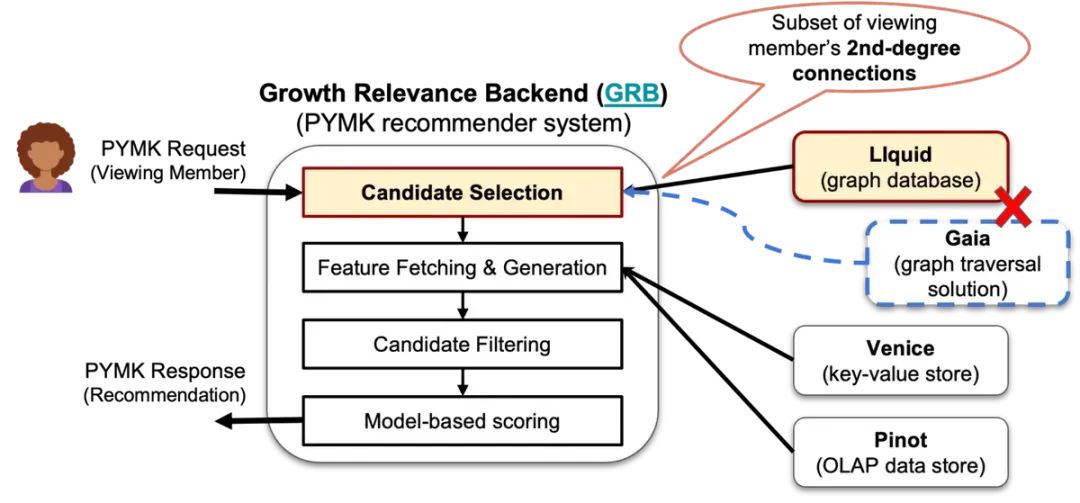
图片来源:https://engineering.linkedin.com/blog/2023/how-liquid-connects-everything-so-our-members-can-do-anything
上图是系统的架构图,使用了 LIquid,可以以较小的延迟和可接受的硬件成本来执行图查询。通过 LIquid 对 Economic Graph 的查询生成数百个候选对象,并应用第二个排名函数。这个排名函数使用 Venice 的机器学习功能和 Apache Pinot 的分析见解来评分并选择最佳候选对象。过滤步骤为呈现和最终评分准备好了这个排名列表。
LIquid 的设计使其能够伸缩到当前十倍的规模,可以支持 LinkedIn 9.3 亿多会员的有机增长和新的语义领域。它提供 99.99% 的可用性,并可以自动根据图的大小和活动量的增加进行自动伸缩。
图数据库使用基于 Datalog 的可组合声明式查询语言,帮助开发人员高效地访问和使用数据。可组合语言能够让开发人员在现有的特性(叫作模块)上进行构建,声明式语言能够让开发人员专注于表达他们想要开发的东西,而 LIquid 自动化了高效的访问过程。开发人员因此可以快速变更数据集,大大减少了调整和更新数据库所需的时间。
LinkedIn 工程总监 Bogdan Artintescu 描述了 LIquid 的发展路线图:
要让会员能够做更多的事情,我们需要在回答会员的问题方面提供更加完善的能力。我们可以沿着两个方向做出改进。首先,复杂的查询和添加到 Economic Graph 的数据源的多样性将会驱动新特性的开发和呈现。其次,丰富数据将提高推理能力。这可以通过创建派生数据(通过确定性算法或概率机器学习方法)或通过知识图谱(KG)模式中更丰富的语义改进推理来实现。我们计划专注于高性能图形计算和分析,并建立一个 KG 生态系统,让我们的开发人员能够进一步增强会员体验。
LIquid 的成功激励了 LinkedIn 的其他团队和微软的姐妹团队将它作为图数据索引。
-
工业大数据中的实时数据库与时序数据库是什么2019-11-09 9070
-
紫金桥实时数据库在石化领域的应用2017-10-13 977
-
Ebase实时数据库手册2013-09-17 2199
-
基于RTX的实时数据库系统关键技术研究2013-05-06 1024
-
异步增量的实时数据库历史数据分析处理系统2013-01-31 986
-
基于实时数据库的数据压缩算法2011-05-26 806
-
控制软件系统实时数据库的设计2011-05-14 785
-
实时数据库在石化行业的典型应用2010-10-07 404
-
基于面向对象的过程实时数据库引擎设计2009-12-25 608
-
组态软件实时数据库研究2009-09-14 737
-
基于Linux的嵌入式实时数据库的设计2009-08-22 512
-
基于PHD实时数据库的电气监控系统2009-08-07 1098
-
先进控制软件系统实时数据库的设计2009-07-07 493
-
DCS组态软件实时数据库系统的设计2009-03-14 973
全部0条评论

快来发表一下你的评论吧 !
