

AMD Versal系列FPGA NoC介绍及实战
可编程逻辑
描述
一、NoC前世今生
NoC是相对于SoC的新一代片上互连技术,从计算机发展的历史可以看到NoC 必将是SoC 之后的下一代主流技术,SoC 通常指在单一芯片上实现的数字计算机系统,总线结构是该系统的主要特征,由于其可以提供高性能的互连而被广泛运用。然而随着半导体工艺技术的持续发展,出现了一些与总线相关的问题:总线地址空间有限,由于使用单一时钟整个芯片均同步的限制。一个典型的SoC系统主要包含以下结构:
A. 至少一个微控制器(MCU)或微处理器(MPU)或数字信号处理器(DSP),但是也可以有多个处理器内核;
B. 存储器可以是RAM、ROM、EEPROM和闪存中的一种或多种;
C. 用于提供时间脉冲信号的振荡器和锁相环电路;
D. 由计数器和计时器、电源电路组成的外设;
E. 不同标准的连线接口,如USB、火线、以太网、通用异步收发和序列周边接口等;
F. 用于在数字信号和模拟信号之间转换的ADC/DAC;
G. 电压调理电路及稳压器;
目前的SOC架构各个组件之间的通讯还是以AMBA总线为主,AMBA包含AHB/ASB/APB/AXI这四种主要的总线协议,而这些协议无一例外的都是基于中断和仲裁机制的。然而,随着商业应用开始不断追求指令运行并存性和预测性,芯片中集成的核数目将不断增多,基于总线架构的SoC将逐渐难以满足不断增长的计算需求。其主要表现为:
A. 可扩展性差:SoC系统设计是从系统需求分析开始,确定硬件系统中的模块。为了使系统能够正确工作,SoC中各物理模块在芯片上的位置是相对固定的;一旦在物理设计完毕后,要进行修改,实际上就有可能是一次重新设计的过程;另一方面,基于总线架构的SoC,由于总线架构固有的仲裁通信机制,即同一时刻只能有一对处理器核心进行通信,限制了可以在其上扩展的处理器核心的数量;
B. 平均通信效率低:SoC中采用基于独占机制的总线架构,其各个功能模块只有在获得总线控制权后才能和系统中其他模块进行通信;从整体来看,一个模块取得总线仲裁权进行通信时,系统中的其他模块必须等待,直到总线空闲;
C. 单一时钟同步问题:总线结构要求全局同步,然而随着工艺特征尺寸越来越小,工作频率迅速上升,达到10GHz以后,连线延时造成的影响将严重到无法设计全局时钟树的程度,而且由于时钟网络庞大,其功耗将占据芯片总功耗的大部分; 二、AMD Versal器件NoC介绍
AMD Versal系列器件上的NoC网络主要架构如下图所示:
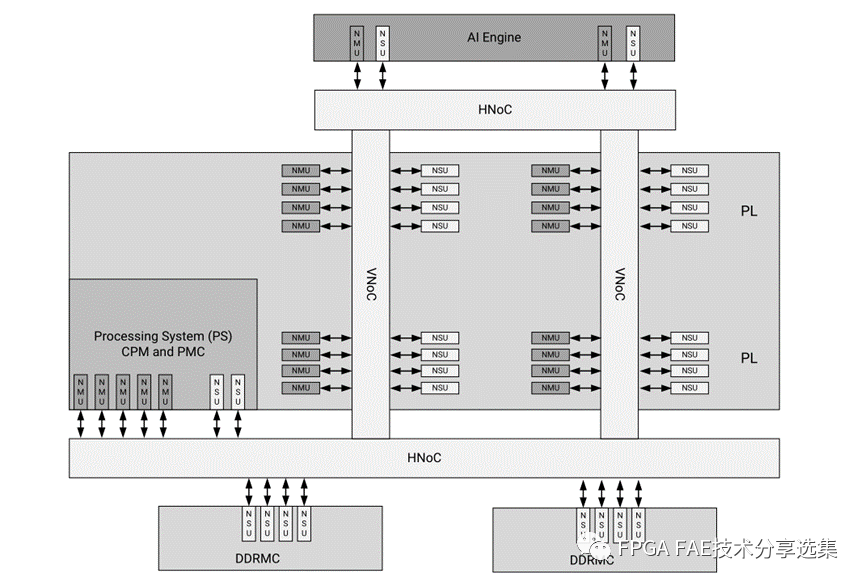
AMD Versal可编程芯片网络(NoC)是使用的互连网络,用于在可编程逻辑(PL)、处理系统(PS)中的IP端点之间共享数据。这种设备范围的基础设施是高速、集成化并带有专用开关的数据路径。可以对NoC进行逻辑配置以表示复杂的拓扑,使用一系列水平和垂直路径以及一组可定制的体系结构。
NoC是为可扩展性而设计的。它是由一系列相互连接的水平(HNoC)和垂直(VNoC)路径,由一组可定制的硬件实现支持。可以以不同方式配置的组件,以满足设计时间,速度和逻辑利用需求。HNoC和VNoC是连接集成块的专用高带宽路径,在处理器系统和可编程逻辑(PL)之间不需要消耗大量可编程逻辑的数量。
NoC支持端到端服务质量(QoS),以有效地管理事务和平衡每个流量流的竞争延迟和带宽需求。NoC组件包括NoC主单元(NMU)、NoC从单元(NSU)和NoC包交换机(NPS)和NoC模间桥(NIDB)。NMU为交通入口点,而NSU是交通出口点。所有ip都有一定数量的主连接和从连接。NIDB将两个超级逻辑区域(slr)连接在一起,提供芯片之间的高带宽。NPS是横条交换机,用于完全形成网络。
AMD Versal系列器件的NoC支持如下特性:
A. PL对PL通信;
B. PL到CIPS的通信;
C. CIPS到PL通信;
D. CIPS到DDR内存通信;
E. CIPS到AI引擎的通信;
F. 高带宽数据传输;
G. 支持标准的AXI4接口到NoC,支持AXI4-Lite需要软桥;
H. 支持时钟域交叉;
I. 内部寄存器编程互连编程NoC寄存器;
J. 多种路由选择:基于物理地址;根据目的接口设置;虚拟地址支持;
K. 通过强化SSIT桥接实现芯片间连接;
L. 在SSIT配置中,从源芯片PMC传输比特流到目标芯片PMC;
M. 可编程路由表的负载平衡和死锁避免;
N. 调试和性能分析功能;
O. 端到端数据保护的可靠性,可用性,可服务性(RAS);
P. 在整个NoC中有效地支持虚拟通道和服务质量(QoS),管理事务并平衡每个事务的竞争延迟和带宽需求;
Q. NoC连接硬件(或接入点)使用主从,内存映射配置。NoC上最基本的连接由一个主连接组成到使用单个分组交换机的单个从机。使用这种方法,主机获得AXI信息并将其打包,以便通过分组交换机在NoC上传输到从机的slave将数据包分解为传递给连接后的AXI信息。为了实现这一点,一个NoC接入点管理所有的时钟域交叉、交换和AXI和NoC端之间的数据缓冲,反之亦然;
R. 支持内存映射事务的纠错码(ECC),不支持流;
NoC功能模块如下:
A. NoC Master Unit (NMU):用于连接主控节点和NoC;
B. NoC Slave Unit (NSU):用于连接从设备到NoC;
C. NoC分组交换机(NPS):用于沿NoC和执行传输和分组交换设置和使用虚拟通道NMU和NSU组件通过标准从可编程逻辑端访问;
NoC的AXI4使用以下基本的AXI特性:
A. 支持AXI4和AXI4- stream;
B. 可配置AXI接口宽度:32、64、128、256或512位接口;
C. 64位寻址;
D. AXI排他访问的处理;
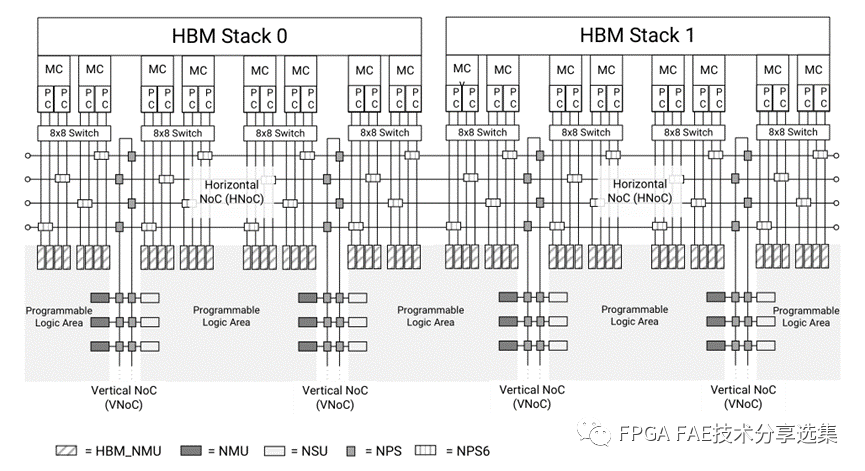
在AMD Versal系列器件中将NoC整合到了专用的硬化DDR/HBM控制器中,可以更为方便的对存储器数据流进行分配。其中HBM NoC结构可以参见下图:
三、AMD Versal NoC IP功能介绍
AMD Versal NoC IP主要包括AXI/DDR Memory Controller/HBM Memory Controller/AXI Stream几种基础模式,可以根据速率/带宽的需求进行自由组合和选择。本文主要基于AXI接口的NoC IP进行简要介绍,基本界面如下图所示:
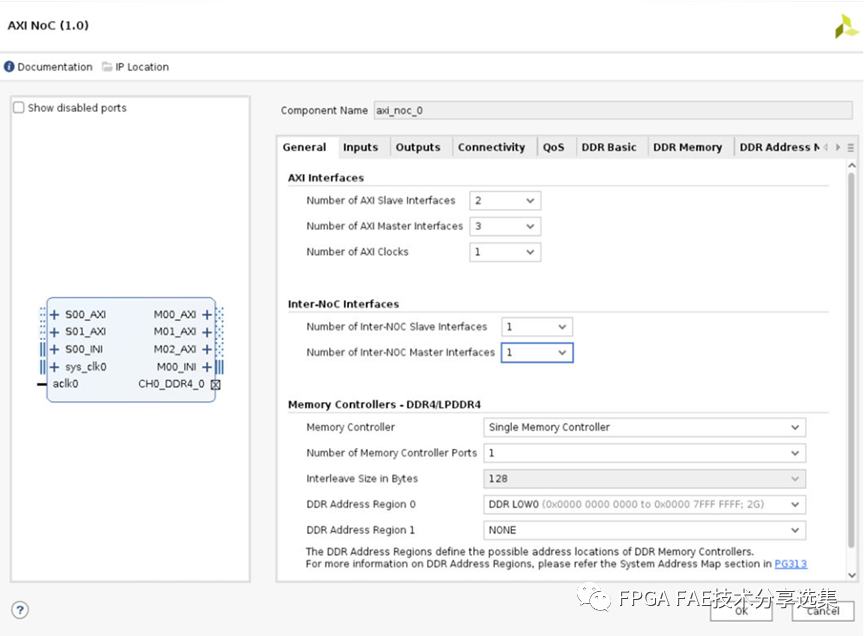
对界面上几个主要选项做如下说明:
AXI接口:
A. AXI Slave接口数量:NMU (NoCingress)接口的数; B. AXI Master Interface数量:NSU (NoC出口)端口数量; C. AXI时钟的数量:这是将被跨使用的独立AXI时钟的数量,NMU和NSU端口的集合,基于接口输入相关时钟的工具将推断每个接口的时钟关联;
Inter-NoC接口:
A. Inter-NoC SlaveInterface的数量:表示Inter-NoC Interface ingress (INI)的数量;
B. Inter-NoC MasterInterface数量:Inter-NoC Interface出接口数量(INI)端口;
内存控制器-DDR4/LPDDR4:
A. 内存控制器数量:已连接的集成内存控制器数量这个axi_noc实例,必须为0、1、2或4,2或4表示内存控制器交错;
B. Memory ControllerPorts数量:内存控制器中可连接的MC端口数量连接选项卡,必须是0-4,这对应于已启用的NSU连接数;
C.交错大小:当内存控制器交错时,设置每个字节的数量交错,必须是{128,256,512,1024,2048,4096}中的一个;
D. DDR地址区域0/1:将DDRMC地址与统一的系统地址进行映射通用设备的地图,有关更多信息,请参阅系统地址映射;
对于input和output页面的功能主要是配置NoC的互联信息,整体界面如下图所示:
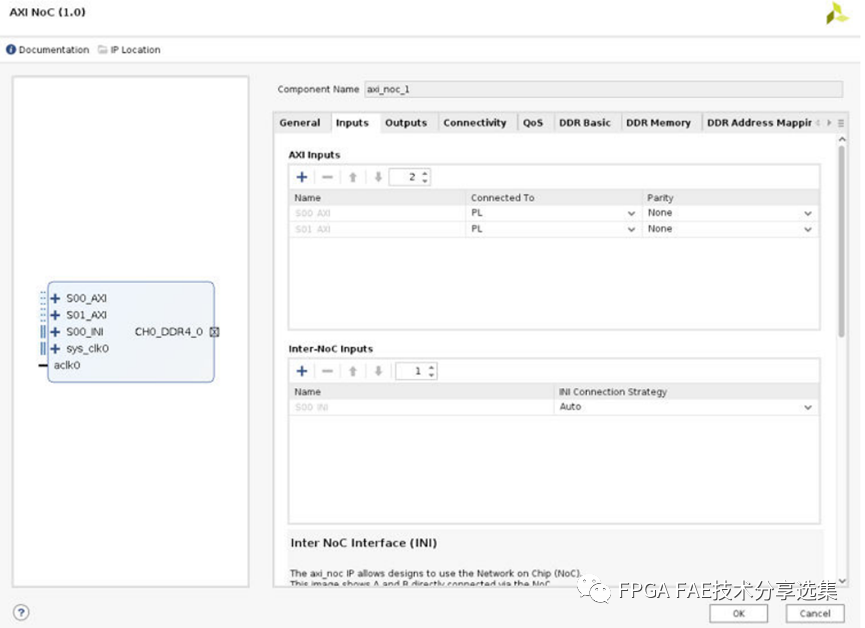
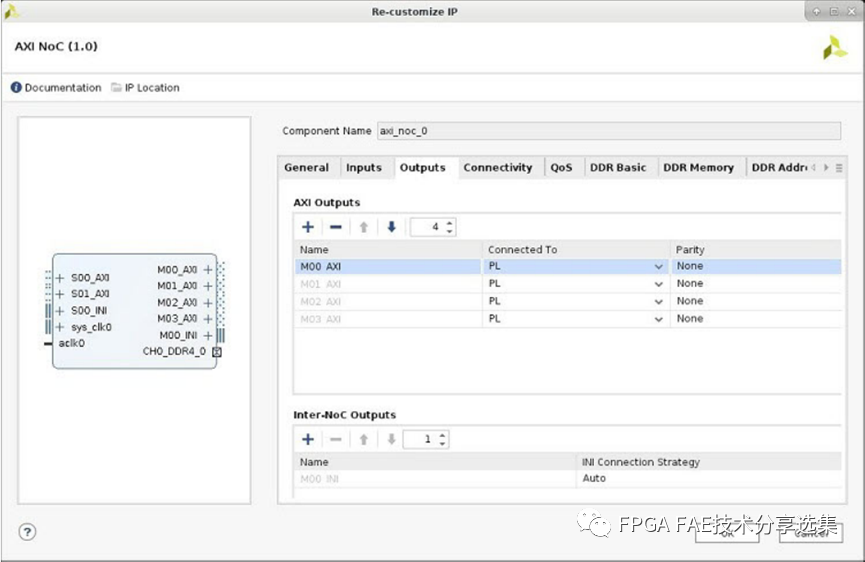
A. AXI输入:设置该实例的AXI输入的数量,并配置每个输入的配置选项有如下连接对象:
• AIE:来自AI引擎阵列;
• PS非相干:来自PS的非相干接口之一;
• PS PMC:来自PS的平台管理控制器;
• PS LPD:来自低功耗域;
• PL:来自可编程逻辑结构;
• PS Cache Coherent:从PS的一个Cache Coherent接口;
• PS PCIe:从PS的PCIe接口;
B. 奇偶校验:启用从AXI主机到NMU的连接的奇偶校验,可用的奇偶校验选项有:
• None:不校验;
• 地址:AXI地址奇偶校验启用;
• 数据:AXI数据奇偶校验启用;
• 地址和数据:启用了AXI地址和数据检查;
奇偶校验位的对应关系如下表所示:
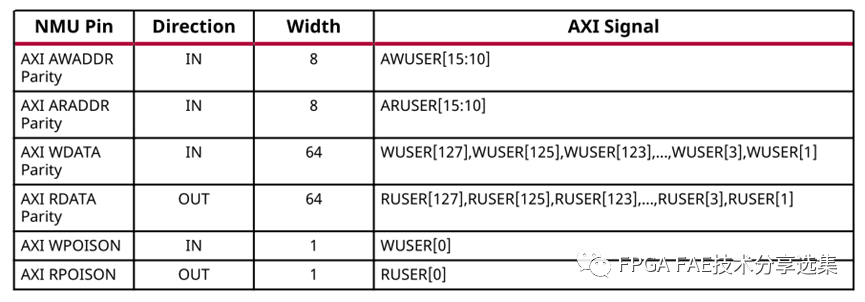
注意:奇偶校验只对连接到PL的输入有效,从PS或AI引擎不支持奇偶校验。
C. Inter-NoC输入:使用Inter-NoC接口指定来自其他axi_noc实例的输入(INI);
您可以选择设置INI连接策略如下:
• 自动:IP集成商决定正确的策略。这是默认设置;
• 单驱动:只有一个驱动,可能有多个负载;
• 单负载:有一个负载和可能的多个驱动程序;
D. AXI输出:设置该实例的AXI输出数量并配置每个输出,配置选项有:
• 连接对象;
• PL:到可编程逻辑结构;
• AIE:连接到AI引擎阵列;
• PS Cache CoherentVirtual:到PS的一个Cache Coherent接口,路由到此NSU端主机使用固定目的地地址路由所有从NMU到NSU的事务,此设置适用于使用功能在SMMU-400和/或CCI-500;
• PS Cache CoherentPhysical:到PS的Cache Coherent接口之一,All PL路由到该NSU端口的主机使用地址解码寻址来路由事务,此设置适用于以PS中的端点从机为目标的端点主机并不适用于使用CCI-500中的特性的端点主机;
• PS Non-CoherentVirtual:指向PS上的一个非相干接口路由到此NSU端口的主机使用固定目的地地址路由所有从NMU到NSU的事务;
• PS Non-CoherentPhysical:到PS的一个非相干接口路由到该NSU端口的主机使用地址解码寻址来路由事务,此设置适用于以PS中的端点从服务器为目标的端点主服务器;
• PS PCIe:连接到PS的PCIe接口;
• PS PMC:到PS的平台管理控制器;
• 奇偶校验:启用从NSU到AXI slave的连接的奇偶校验使用奇偶校验,奇偶校验选项与输入选项卡中描述的选项相同;
奇偶校验位的映射说明如下表所示:
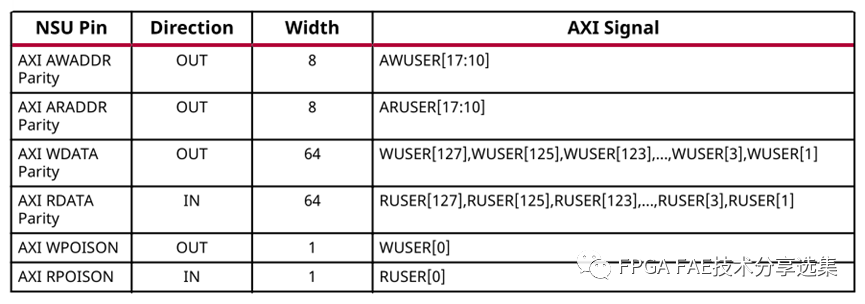
注意:奇偶校验只对连接到PL的输出有效,对于PS或AI引擎无效;
E. Inter-NoC输出:使用Inter-NoC接口指定输出到其他axi_noc实例(INI);
您可以选择设置INI连接策略如下:
• 自动:允许IP集成商确定正确的策略;
• 单驱动(NMU):负载(NSU/MC)拥有PR路径并具有QoS;
• 单负载(NSU/MC):NMU (Driver)拥有PR路径和QoS;
对于Connectivity页面来说主要是用于配置AXI接口的Slave和Master的连接关系,就不再详述了,页面布局如下图所示:
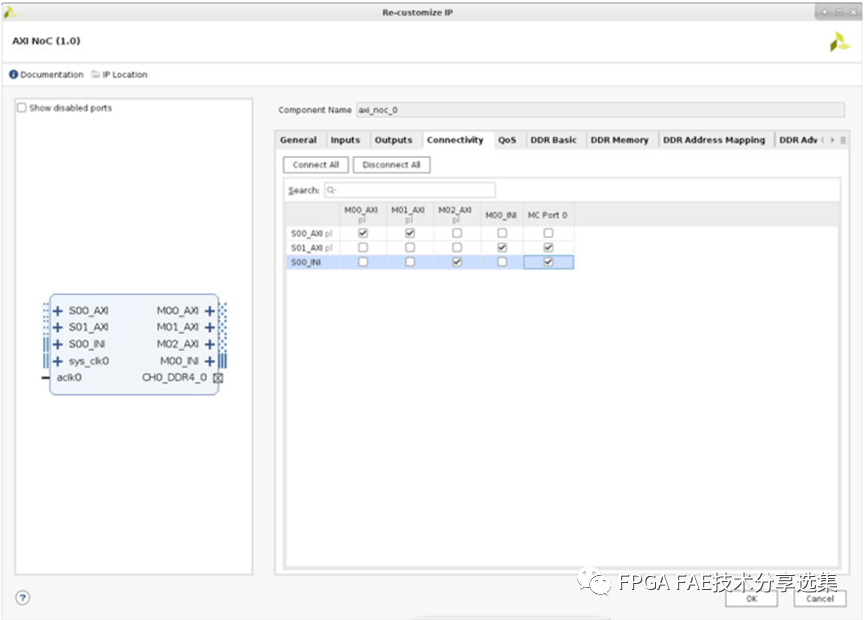
对于QoS页面来说主要是配置NoC的QoS特性,分为基础QOS和高级QOS配置两种,整体界面如下图所示:
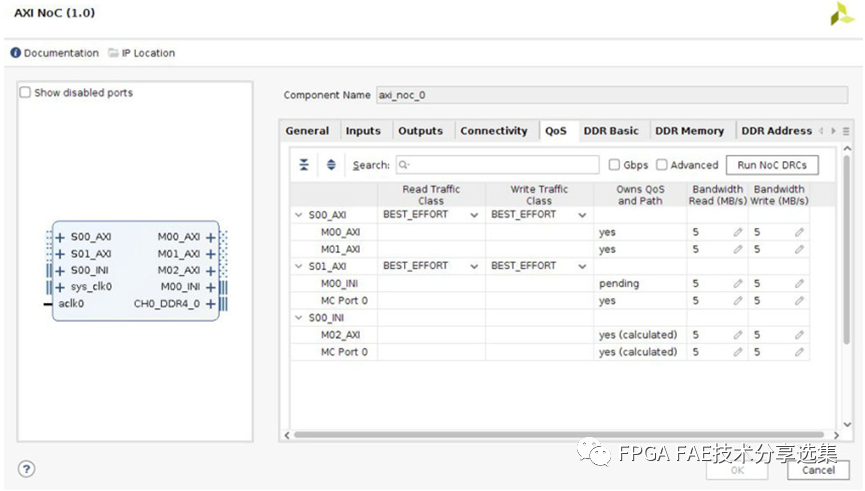
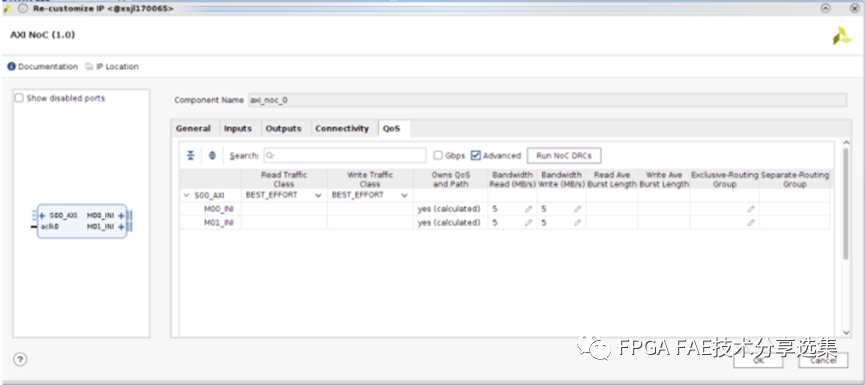
A. QoS选项卡的第一列显示了定义的连接的树形结构连接选项卡;每个树的顶部(左对齐的端口名称)是NoC入口端口;每个入口端口下面显示的是相关行对于每个连接的出口端口。
B. 第二列定义读流量的分类: 取值为LOW_LATENCY和BEST_EFFORT(默认),流量类适用于所有连接源自给定的入口端口;
C. 第三列定义写流量类别,取值包括ISOCHRONOUS和BEST_EFFORT,写流量不支持LOW_LATENCY,写流量类适用于从给定入口端口发起的所有连接;
D. 第四列表示该NoC实例是否拥有给定路径的QoS设置:NoC路径可以使用INI遍历多个NoC实例,QoS设置取自拥有QoS和路径的NoC实例,当NoC实例不拥有QoS时,QoS将被忽略的路径,所有权正处于从NMU或strategy=Driver者到NSU, MC,或strategy=Load,如果值为“pending”,则表示在此期间将计算所有权验证,或单击上面的Run NoC drc按钮,对于值“error”,请验证或单击单击上面的Run NoC drc按钮,在Tcl控制台和消息窗口中查看错误详细信息;
E. 第五列为读带宽,单位为MB/s,允许取值范围为0 (不接受读流量)到NoC物理通道的最大数据带宽;
F. 第六列为写带宽,单位为MB/s,允许的值范围从0(不接受写流量)到NoC物理通道的最大数据带宽;
拥有QoS和路径:
NoC路径可以使用INI遍历多个NoC实例,QoS设置取自拥有QoS和Path的NoC实例,当NoC不拥有QoS时,将忽略QoS路径;所有权处于从NMU或strategy=Driver程序到NSU, MC或的过渡阶段strategy=Load,值“pending”意味着所有权将在验证期间计算,或者通过单击运行上面的NoC DRCs按钮,若值为“error”,请验证或单击“Run NoC drc”按钮在Tcl控制台和消息窗口中查看错误详细信息。
注意:如果“拥有QoS”和“路径”为“否”,则所有设置BW和流量分类将被忽略。
运行NoC drc:
在整个设计中运行NoC drc,错误会在Tcl控制台和消息窗口中列出,通过计算所有权来更新'Owns QoS'列中的'pending'条目设计,NoC路径可以使用INI遍历多个NoC实例,采取QoS设置从拥有QoS和Path的NoC实例获取,当NoC没有忽略QoS时,QoS将被忽略拥有这条路径;所有权正处于从NMU或strategy=Driver者到NSU, MC,或strategy=Load。
对于Address Remap页面来说主要是配置输入输出的地址映射关系,有一些地址规则会详细说明,Address Remap页面如下图所示:
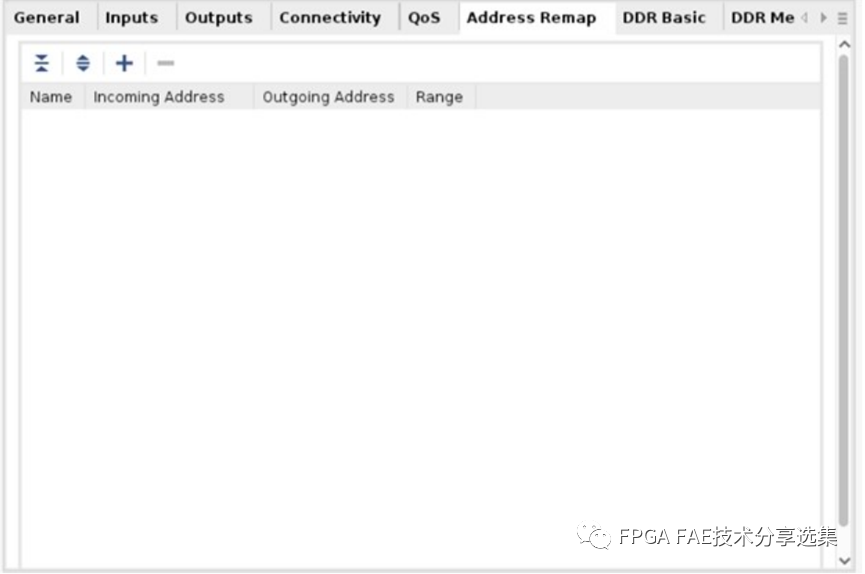
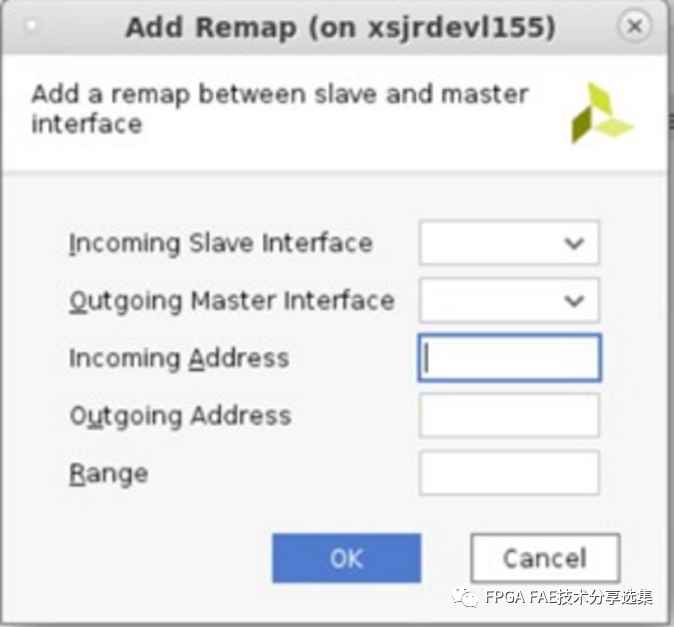
A. IncomingSlave Interface:从下拉菜单中选择从端口(NMU)存在需要重新映射的传入地址;
B. 出主接口:从下拉菜单中选择主接口(NSU)输出重新映射的地址;
C. 入站地址:从站发送的起始地址,需要重新映射;
D. 发送地址:发送地址为映射后的地址,这是第一个地址在重新映射开始的地方;
E. 范围:要访问的地址空间的总范围;
F. 重新映射规则:
• 范围必须最小为64K,必须为2的整数次方;
• 范围内的入地址位必须为零:incoming_address& (range-1) == 0;
• 示例:对于由主控机寻址的32位4G范围;
• 输出地址范围内的位必须为零:output_address& (range-1) == 0;
四、DDR4/LPDDR4 NoC IP实战
在 Versal新一代ACAP器件上,除了延续之前Ultrascale/Ultrascale+系列器件上已有的DDR4IP之外,还配置了最新的DDR4/LPDDR4 硬核控制器(NoC IP)。它的性能更高,并且不额外占用其他的可编程逻辑资源(PL),使用它的时候,在硬件设计方面和设计流程上,和之前的软核控制器(DDR4 IP)也有着很大的不同。今天我们来介绍一下I/O planning方面的设计考虑和实现流程。
我们首先要新建一个工程并添加CISP IP core,这样我们才能顺利的开始block design的设计工作。
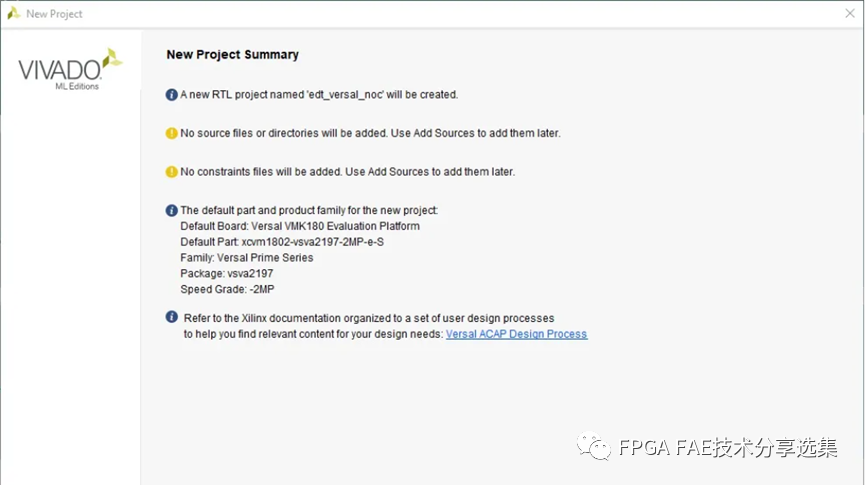
新建如图基于VMK180的vivado工程'edt_versal_noc':
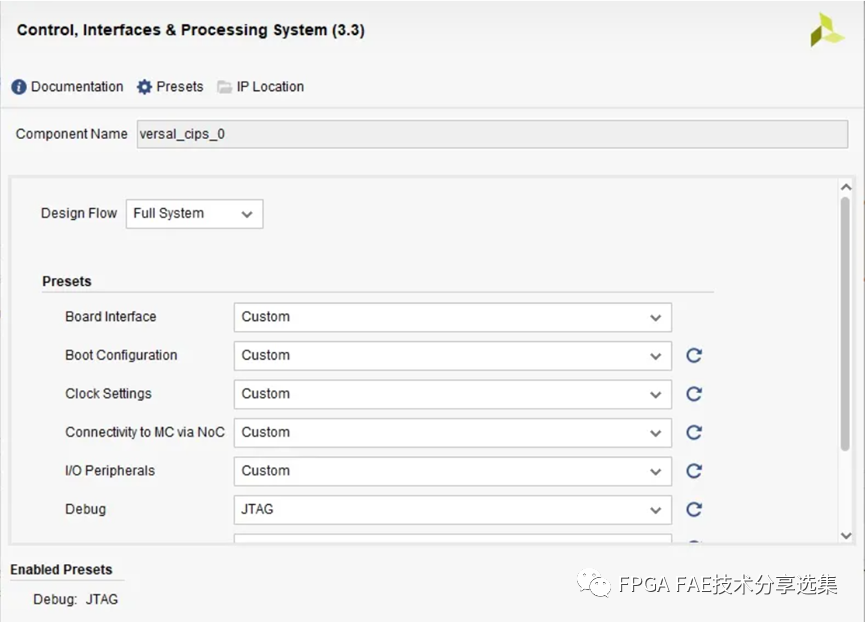
新建一个BlockDesign,这里我们添加CISP ip core (系统默认为versal_cips_0),并且run design automation让vivado对ip核做自动初始化。这里我们使用CISP IP的默认配置,不进行更改。
自动化后双击versal_cips_0框图,进入Re-customize IP向导,将Board Interface设置成Custom, 如图所示:
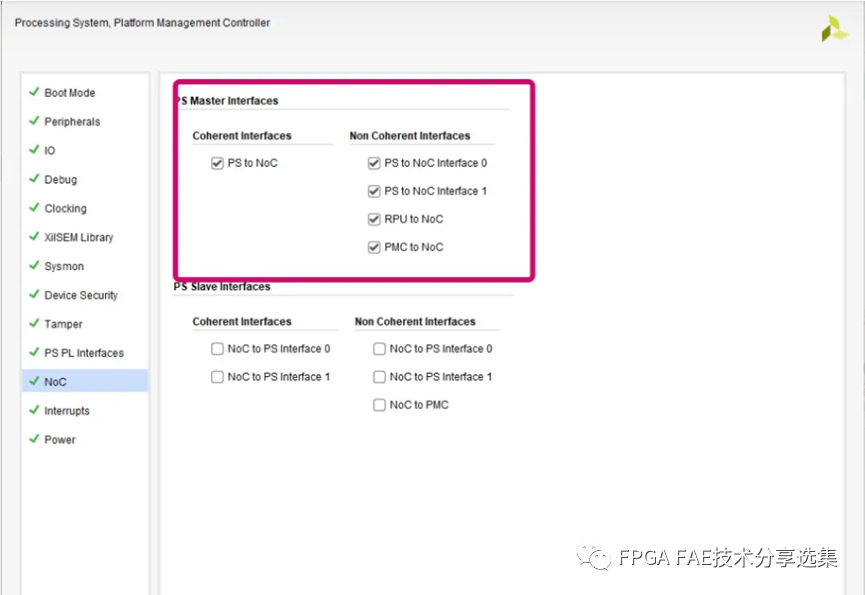
双击CIPS打开配置向导找到PS PMC配置NoC页, 启动PS Master Interfaces如图所示:
最后点击Finish更新CIPS的配置。
接着添加另外一个IP核 AXI NoC,RunBlock Automation, 配置如下:
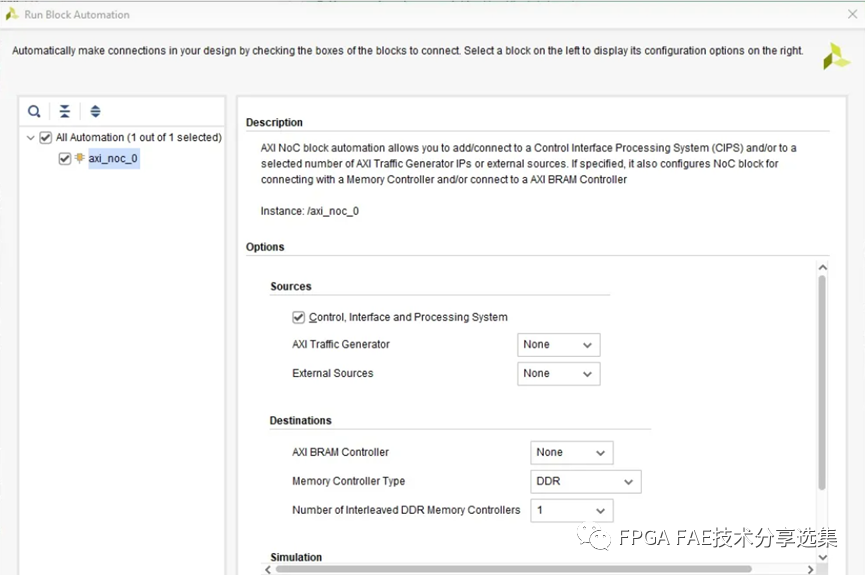
在block design中添加NoC IP。
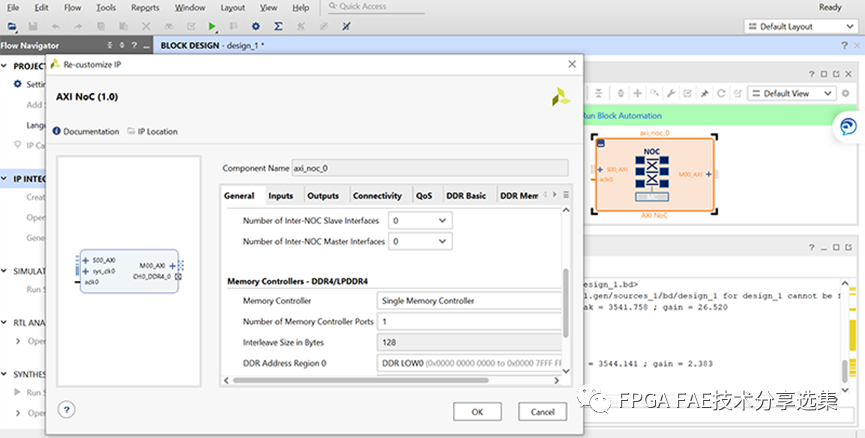
在IP wizard中,根据memory 容量,位宽,带宽等要求完成相关配置。
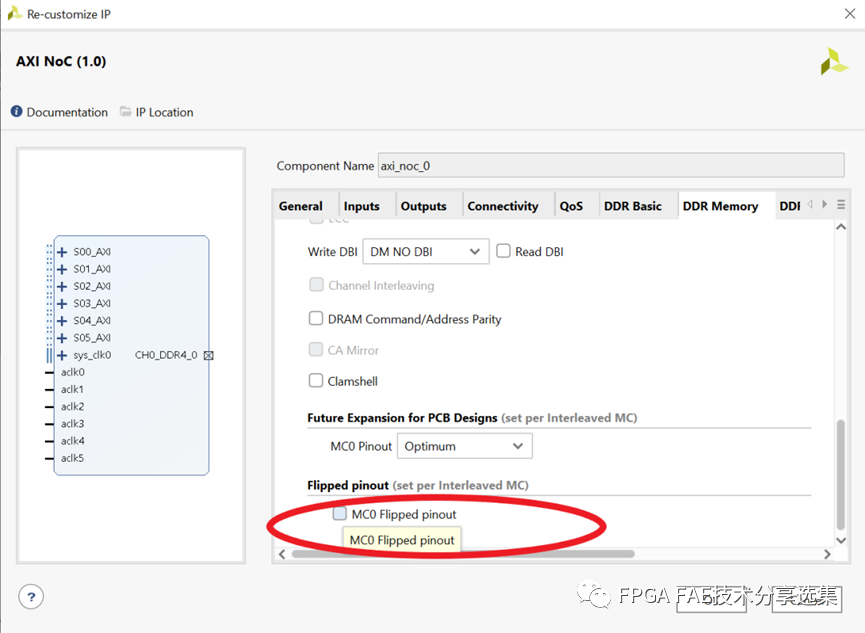
总体上来讲,DDR4/LPDDR4的管脚有2种分配模式—Flipped和Non-flipped,模式的选择可以通过使能或者关闭NoC IP中 “Flipped pinout”的选项来实现。
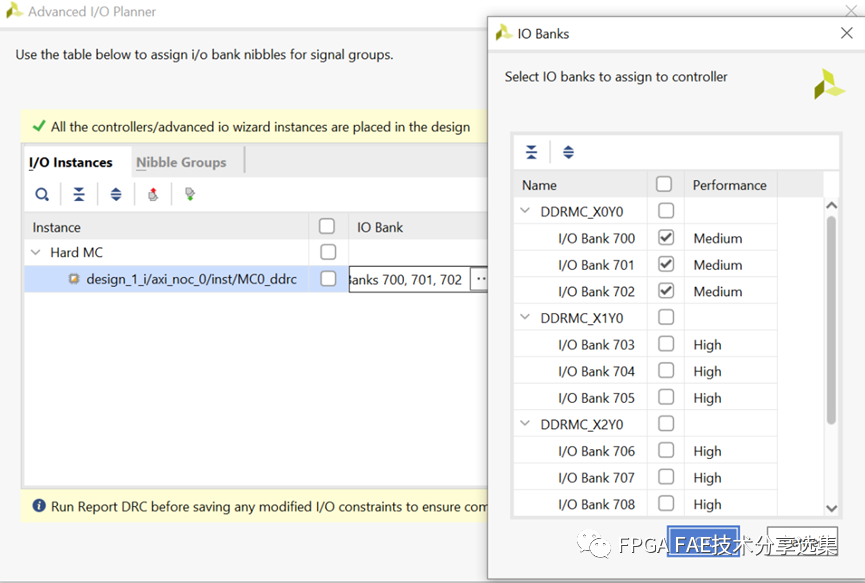
Versal器件上每个NoC IP对应3个IO bank的管脚,它们都位于同一个triplet之中。一个NoC IP对应的所有DDR4/LPDDR4接口管脚都必须放置在这3个IO bank之中。在对block design进行综合之后,打开synthesized design,在I/O ports窗口中点击 “Open advanced I/O planner” ,按照bank或者nibble为单位指定所有管脚的位置。
在此之后,地址、控制和时钟管脚的位置就被固定了下来。数据管脚在Byte以内和Byte之间可以进行微调,这样一个NoC的block design实例工程就搭建完成了。
审核编辑:刘清
-
AMD 7nm Versal系列器件NoC的使用及注意事项2025-09-19 3312
-
使用Aurora 6466b协议实现AMD UltraScale+ FPGA与AMD Versal自适应SoC的对接2026-01-13 4145
-
AMD Versal系列CIPS IP核建立示例工程2023-12-05 1860
-
AMD Versal AI Edge自适应计算加速平台之Versal介绍(2)2024-03-06 3134
-
【ALINX 技术分享】AMD Versal AI Edge 自适应计算加速平台之 Versal 介绍(2)2024-03-07 3131
-
AMD Versal AI Edge自适应计算加速平台之PL通过NoC读写DDR4实验(4)2024-03-22 15257
-
Versal系列芯片三个产品的基础知识2021-02-11 4783
-
在Versal中通过NoC从PS-APU对AXI BRAM执行基本读写操作2022-11-09 1402
-
AMD Versal系列FPGA NoC介绍及实战2023-07-13 2627
-
AMD率先推出符合DisplayPort™ 2.1 8K视频标准的FPGA和自适应SoC2024-01-24 1575
-
ALINX VERSAL SOM产品介绍2024-08-05 2069
-
AMD推出第二代Versal Premium系列2024-11-13 1980
-
AMD Versal自适应SoC器件Advanced Flow概览(下)2025-01-23 1989
-
AMD第二代Versal AI Edge和Versal Prime系列加速量产 为嵌入式系统实现单芯片智能2025-06-11 2248
-
AMD Versal Gen 2开发实战进阶工坊系列活动即将举办2026-04-15 574
全部0条评论

快来发表一下你的评论吧 !
