

Linux系统性能分析之Perf命令
嵌入式技术
描述
安装
在开发板上使用apt安装perf命令:
apt install -y perf
或者进入kernel内核源码目录tools/perf,交叉编译执行make,然后拷贝到开发板中运行。
认识Perf
perf可以用来统计一个程序运行期间花了多少时间、上下文切换次数、cache命中率等一些性能相关的事件,通过perf可以分析一个程序的性能瓶颈,从而对程序做出优化。
perf性能事件的关系图如下:
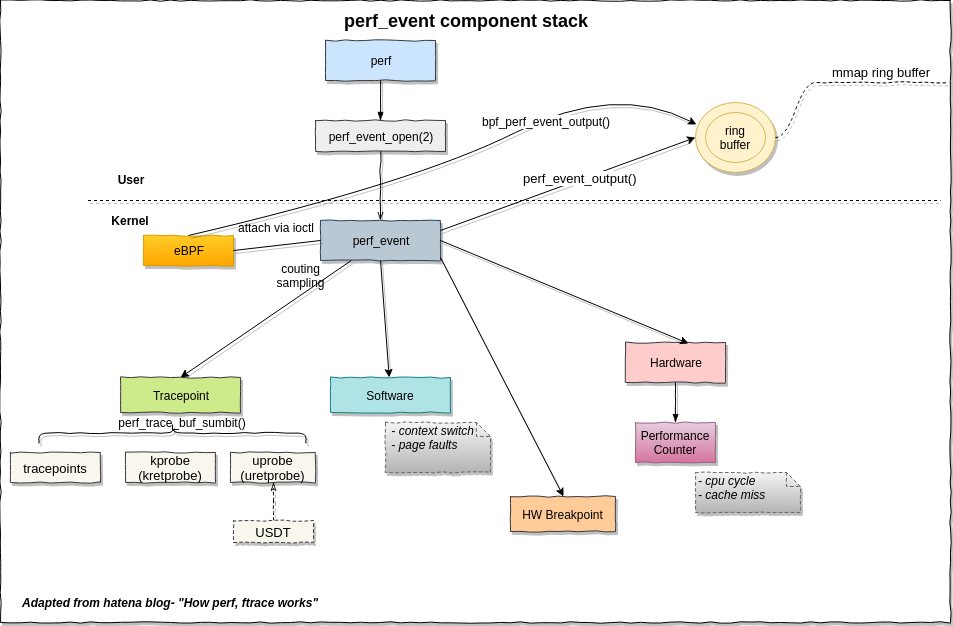
执行命令:
perf list
可以看到如下显示:
branch-instructions OR branches [Hardware event]
branch-misses [Hardware event]
cache-misses [Hardware event]
... ...
context-switches OR cs [Software event]
page-faults OR faults [Software event]
... ...
L1-dcache-load-misses [Hardware cache event]
L1-dcache-loads [Hardware cache event]
... ...
block:block_bio_backmerge [Tracepoint event]
clk:clk_enable [Tracepoint event]
dma_fence:dma_fence_destroy [Tracepoint event]
... ...
其中
hardware event是硬件相关的性能事件software event是软件相关的性能事件hardware cache event是cache相关的性能事件tracepoint event是内核设置的相关的性能事件
perf的性能事件主要可以分为以上四类,但是像hardware event这类事件依赖于硬件的实现,如果硬件不支持也无法统计。部分的其它事件在使用的过程也会遇到不支持的情况。
另外执行perf list命令并不会把所有的事件都列举出来,perf list只会显示支持的事件,如果不支持就看不到了。
Perf功能概览
perf的功能可以分为基础子命令和功能型子命令两大类。
基础子命令是最常用的命令,是必须要学会的。
基础子命令如下 :

功能型子命令如下 :

更多的命令详细参考perf -h说明。
Perf基础子命令
perf list
perf list可以列举支持哪些事件:

perf stat
perf stat可以采样perf list所列举的事件,使用帮助如下:
perf stat -h
-a, --all-cpus system-wide collection from all CPUs
-A, --no-aggr disable CPU count aggregation
-B, --big-num print large numbers with thousands' separators
-C, --cpu < cpu > list of cpus to monitor in system-wide
-D, --delay < n > ms to wait before starting measurement after program start (-1: start with events disabled)
-d, --detailed detailed run - start a lot of events
-e, --event < event > event selector. use 'perf list' to list available events
-G, --cgroup < name > monitor event in cgroup name only
-g, --group put the counters into a counter group
... ...
perf stat可以通过-e指定某个事件,例如统计ls命令的cpu-clock事件:

对于tracepoint event事件,其本身就分为很多种类型,例如:block:block_bio_backmerge,就表示block这个类型的block_bio_backmerge这个采样点。
tracepoint event支持采样类型和采样点非常多,有clk,mmc,sched等类型,而其中每个采样类型又分为更多的采样点,因此, 可以通过perf list后面跟上采样类型的名字 ,来查看某个特性类型的采样点。

可以看到,一个sched类型,对应很多采样点。
对应着sched:sched_switch这个采样点。通过perf stat子命令可以得到观测结果:

可以看到,执行ls,cpu运行了29次sched_switch,也就是对应的__schedule函数。
其实tracepoint event最强大的地方在于时间的统计 ,内核中每个采样点都代表了一些重要的时刻,比如,进程切换了,调度器把进程放入runqueue,或者开始真正的进程运行,都会加上一个tracepoint,来记录时间,从而为分析和调试提供支持。
perf record & perf report
perf stat子命令展示的是 即时的数据 ,若想要获取更多信息,则需要用perf record子命令将信息组成一个perf.data文件,并利用perf report将其解析并展示出来。
因此perf record和perf report命令通常是一起使用的。
同样的,perf record和perf report子命令也具有相当多的参数。
perf report -h
-b, --branch-stack use branch records for per branch histogram filling
-c, --comms < comm[,comm...] >
only consider symbols in these comms
-C, --cpu < cpu > list of cpus to profile
... ...
例如对context-switches事件采样:
perf record -e context-switches -a sleep 1

然后执行perf report显示更多的详细信息:

可以看到,perf report子命令不光展示了cpu执行sleep 1时发生的上下文切换次数,还展示了这切换都分布在哪些进程中。
perf script
perf script主要被用来生成perf.unfold文件,被交给一个名叫FlameGraph( 火焰图 )的工具,这个工具会解析perf.unfold数据,然后将其转换成易于人类阅读和分析的图形。
火焰图
wget "https://github.com/brendangregg/FlameGraph/archive/master.zip"
unzip master.zip
如果希望了解CPU在一段时间内的都运行了哪些函数以及各函数都消耗了多少时间,就可以使用On CPU火焰图,这种火焰图基于cpu-cycles事件进行采样,然后通过svg图片格式展现出来
dd if=/dev/zero of=/tmp/testfile bs=4K count=102400 &
perf record -e cpu-cycles -a -g sleep 1
perf script > perf.unfold
cd FlameGraph-master
./stackcollapse-perf.pl < ../perf.unfold | ./flamegraph.pl > ../perf.svg
首先在后台启动一个dd命令,让它持续运行一段时间,然后开启perf record,记录一秒钟内cpu都运行了多少个cpu-cycles,也就是时间(同时使能-g,就会一并记录运行的函数以及调用关系),再利用perf script命令将perf.data转成perf.unfold,最后利用FlameGraph工具将其转换成一个perf.svg,这是一个图形文件,用浏览器打开后会得到这样一幅图:

此图记录着函数调用关系及其cpu-cycles(时间)占比,就像一缕缕升起的火苗,所以被称之为火焰图。
火焰图还可以通过鼠标点击放大,观察其细节,如下:

Perf功能型子命令
列举2个perf功能型子命令实例top和bench,更多的参考-h列举的说明。
perf top
perf top子命令动态地显示各种采样事件,例如:
perf top -e sched:sched_wakeup

perf bench
perf bench子命令是perf内部集成的一个benchmark测试程序,可以看一下perf bench支持哪些benchmark:

可见,benchmark有sched,mem,futex等几大类
perf bench mem

而mem里又包含了2个测试点
perf bench mem memcpy

perf bench mem memset

总结
perf是用于性能分析的一个工具,功能强大,用法也非常多。但是要真正用明白,懂得分析,需要长时间的学习和沉淀。
例如必须得知道cycles、instructions、分支预测等这些是什么意思,每个性能事件的统计值高低所带来的影响分别是什么,如何增加/降低某个性能事件的统计值等等,只有在具备这些理论基础的情况下,去分析perf的统计值才比较有意义。
-
Linux系统性能优化技巧2025-08-27 1133
-
Linux系统性能调优方案2025-08-06 1052
-
Linux perf 简要介绍2023-11-09 1835
-
如何使用perf性能分析工具2023-11-08 2935
-
Linux perf性能、实际应用与案例2023-07-03 1404
-
一文看懂Linux性能分析之perf原理2022-11-14 2563
-
perf 在内核中的实现原理2022-10-17 3667
-
一文详解Linux的perf_event2022-10-11 2682
-
全志Tina中使用perf分析CPU使用率2022-05-20 6107
-
赛昉科技发布Perf性能分析工具2022-04-24 2983
-
Linux kernel系统性能优化工具Perf介绍2022-04-15 4877
-
你知道perf学习-linux自带性能分析工具怎么用?2019-05-16 3249
-
Linux服务器性能测试及分析命令大全2017-09-05 1075
全部0条评论

快来发表一下你的评论吧 !
