

英特尔推出AI加速器性价比产品Gaudi2
描述
日前,英特尔面向中国市场发布了HabanaGaudi2深度学习加速卡器。
新的Gaudi2直接给到了24个Tensor处理核心(TPC),是上代产品的三倍;而在对大模型应用至关重要的显存方面,Gaudi2也大方的配置了96GBHBM2e,显存带宽直接达到了2.4TB/s。而在连接方式上,Gaudi2则采用了OCPOAM接口形式,可扩展出21个100G以太网连接,并支持RoCE(RDMAover Converged Ethernet)v2。同时,Gaudi2还集成了多媒体处理器引擎和48MB片上SRAM作为高速缓存。
在系统层面,英特尔则提供能够同时安装8块Gaudi2的夹层基板,同样遵循OCP标准,可扩展出24个100GRoCE网络接口。
性能更好的新选择
Gaudi2搭载的96GBHBM显存的确令人眼前一亮,但真正能够影响用户购买行为的仍旧似乎加速卡本身的计算性能。
在HuggingFace工程师RégisPierrard去年底进行的Gaudi2测试中,Gaudi2不仅在与前代产品的对比中表现出了近乎线性的性能提升,更大幅超越了对标的A100加速卡。
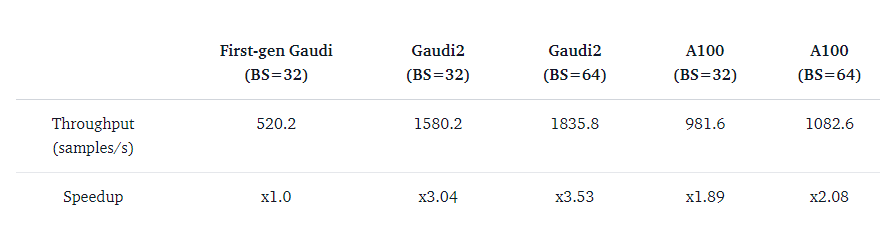
BERT预训练,8卡
Gaudi2使用bf16/fp32混合精度,A100使用fp16精度

StableDiffusion测试,单卡
从RégisPierrard使用IntelDeveloper Cloud进行的两轮测试中我们不难发现,无论是在BERT这样的大模型应用中,还是在StableDiffusion这样的“传统”AIGC应用中,Gaudi2的性能表现均相当亮眼;相对于前代产品展现出了至少3倍的性能优势(Gaudi2的TPC数量是前代的3倍),且比对标的A100产品更具性能优势。
在两项测试中,Gaudi2均使用了英特尔推出的 SynapseAI1.10套件和OptimumHabana1.6;其中前者是面向Gaudi系列加速卡的SDK开发套件,能够对TensorFlow和Pytorch等流行框架提供支持,而后者则是专门面向Transformers和Diffusers优化的运行库。
同时,在发布会的现场演示环节,英特尔工作人员展示了StableDiffusion应用中1至64张卡的计算性能,并实现了99%的近线性性能扩展。换而言之,在更大规模的业务部署当中,Gaudi2也能通过集群横向扩展获得更加线性的性能增长。
目前,Gaudi系列AI加速器已经在AWS的EC2DL1主机中进行了实际的商业部署。AWS表示,相对于传统GPU,Gaudi能够在深度学习应用中带来40%的性价比提升。
在走量的市场做走心的产品
诚然,Gaudi2的竞品并非性能无两的H100,更无法对即将面市的H100NVL构成性能威胁。但对于更加“走量”的A100而言,Gaudi2所展现出的性价比则对大多数用户而言更有价值。
近两年,“从中端入局”似乎已经成为英特尔的惯用手段,消费级的Arc770显卡和如今的Gaudi2均如此。
走量的中端市场对英特尔有足够的吸引力,也更容易帮助英特尔用一两款产品就建立口碑、站稳脚跟;同时,能在中端市场为用户提供先进技术和优势性价比也证明英特尔对目标用户足够走心,愿意把真正的实惠带给最广阔的用户市场。
在走量的市场做走心的产品,这样的英特尔令人喜闻乐见。
为Ai加速器市场打开一扇窗
近两年,以AIGC为代表的AI应用快速崛起,吸引了科技圈和投资界的广泛关注,其中的语言类大模型更有望大幅降低企业在营销、客服和售后方面的成本,实现生产效率的大幅提升。
在科技企业争相进行大模型“军备竞赛”的背后,GPU的需求也水涨船高。在GPU市场格局高度固化的当下,这一现象很容易带来终端市场的价格起伏,导致GPU价格畸高,进而推高企业投身AI业务的成本并导致基础架构被绑定。
而英特尔Gaudi2加速卡的出现则意味着企业有了全新选择。一方面,Gaudi2在绝对性能、显存容量、集群性能等方面都比对标产品有优势,能够承接现有的市场需求;另一方面,伴随oneAPI等算力调用工具的不断成熟和完善,用户也能在开发和应用层面实现基础架构的透明化,更轻松的调用多元算力,继而获得算力和基础架构层面的灵活性。
作为AI加速器市场的“追赶者”,Gaudi2证明英特尔能够为用户提供有竞争力的先进产品。当然,这还仅是在“独立AI加速器”这一条赛道中。
在更广阔的数据中心赛道中,英特尔还有并行的DataCenter Max和DataCenterFlex两条产品线,以及更加独立的FPGA赛道。此外,英特尔也在积极推动AI能力与传统CPU的结合。从最初的AVX-512指令集和DLBoost到如今AMX-512指令集,英特尔正在为用户构建一条“用CPU灵活处理AI推理业务”的全新路径。
很显然,在英特尔的眼中,用户在未来应该针对不同场景和不同业务负载来规划不同的基础架构,用不同算力来满足业务需求。而伴随oneAPI的逐步成熟,底层算力的区别将被抹除,模型训练和多端部署不再需要特别调优就能实现无缝迁移和高效调优。
在产品层面,英特尔最新推出的Gaudi2对用户而言有足够的吸引力;在战略层面,Gaud2则是英特尔站稳独立AI加速器市场并构筑多元算力体系的重要一步。而在AI研究快速推进,技术落地如火如荼的当下,Gaudi2的出现无疑为用户带来了全新选择;而奋力前行的英特尔更有望为市场带来AI与算力需求之间的全新平衡。
-
英特尔Gaudi 2E AI加速器为DeepSeek-V3.1提供加速支持2025-08-26 3533
-
英特尔Gaudi 2D AI加速器助力DeepSeek Janus Pro模型性能提升2025-02-10 1158
-
DeepSeek发布Janus Pro模型,英特尔Gaudi 2D AI加速器优化支持2025-02-08 1235
-
英特尔发布Gaudi3 AI加速器,押注低成本优势挑战市场2024-09-26 2134
-
英特尔Gaudi 3系列AI加速器明年上市2023-12-15 1472
-
有消息透露称,英特尔Gaudi 2处理器订单增多,Gaudi 3预计明年上市2023-09-20 1743
-
Gaudi2架构和软件的全面解释2023-08-04 705
-
gpt-4怎么用 英特尔Gaudi2加速卡GPT-4详细参数2023-07-21 1301
-
大模型算力新选择——宝德AI服务器采用8颗英特尔Gaudi®2加速器2023-07-19 1465
-
英特尔面向中国市场发布Gaudi2处理器,加速大模型训练和推理2023-07-17 3083
-
英特尔全新Gaudi2处理器面世中国市场,加速大规模深度学习训练与推理2023-07-14 2178
-
为深度学习而生,英特尔全新Gaudi2处理器正式登陆中国2023-07-13 1445
-
第四代英特尔至强可扩展处理器和Habana Gaudi2在深度学习训练中展现领先的AI性能2022-12-01 1011
-
亚马逊弹性计算云(EC2)实例将采用英特尔旗下Habana Labs的Gaudi加速器2020-12-03 2951
全部0条评论

快来发表一下你的评论吧 !
