

CVPR 2023 | 完全无监督的视频物体分割 RCF
描述

TLDR:视频分割一直是重标注的一个 task,这篇 CVPR 2023 文章研究了完全不需要标注的视频物体分割。仅使用 ResNet,RCF模型在 DAVIS16/STv2/FBMS59 上提升了 7/9/5%。文章里还提出了不需要标注的调参方法。代码已公开可用。
 论文标题: Bootstrapping Objectness from Videos by Relaxed Common Fate and Visual Grouping
论文标题: Bootstrapping Objectness from Videos by Relaxed Common Fate and Visual Grouping
论文链接:
https://arxiv.org/abs/2304.08025
作者机构:
UC Berkeley, MSRA, UMich
分割效果视频:
https://people.eecs.berkeley.edu/~longlian/RCF_video.html
项目主页:
https://rcf-video.github.io/
代码链接:
https://github.com/TonyLianLong/RCF-UnsupVideoSeg

视频物体分割真的可以不需要人类监督吗?
视频分割一直是重标注的一个 task,可是要标出每一帧上的物体是非常耗时费力的。然而人类可以轻松地分割移动的物体,而不需要知道它们是什么类别。为什么呢?
Gestalt 定律尝试解释人类是怎么分割一个场景的,其中有一条定律叫做 Common Fate,即移动速度相同的物体属于同一类别。比如一个箱子从左边被拖到右边,箱子上的点是均匀运动的,人就会把这个部分给分割出来理解。然而人并不需要理解这是个箱子来做这个事情,而且就算是婴儿之前没有见过箱子也能知道这是一个物体。

运用Common Fate来分割视频
这个定律启发了基于运动的无监督分割。然而,Common Fate 并不是物体性质的可靠指标:关节可动(articulated)/可变形物体(deformable objects)的一些 part 可能不以相同速度移动,而物体的阴影/反射(shadows/reflections)始终随物体移动,但并非其组成部分。
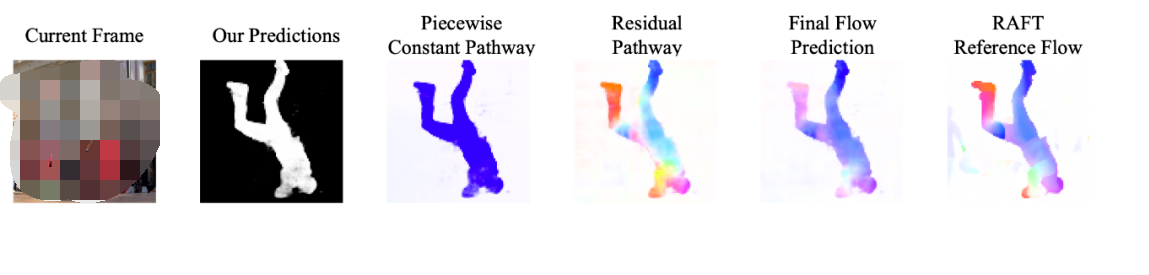
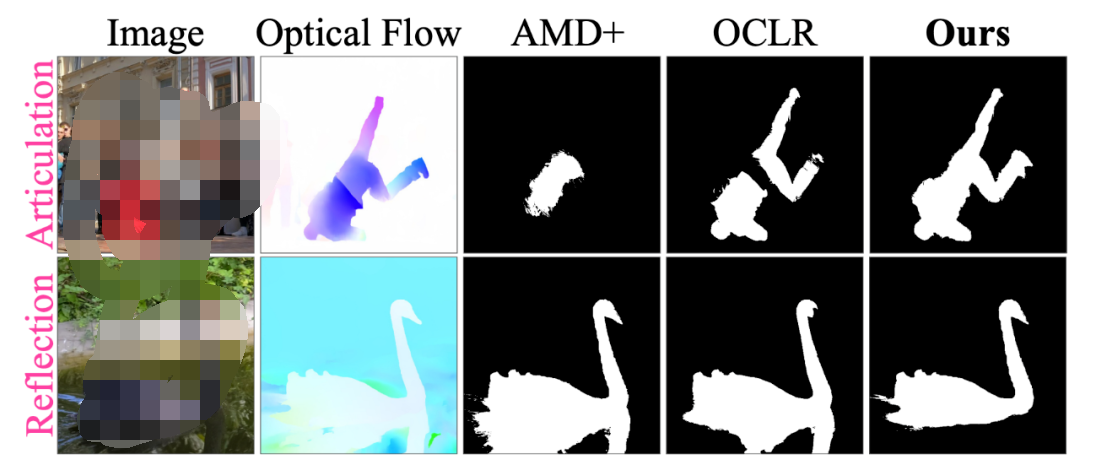
举个例子,下面这个人的腿和身子的运动是不同的(Optical Flow 可视化出来颜色不同)。这很常见,毕竟人有关节嘛(articulated),要是这个处理不了的话,很多视频都不能分割了。然而很多 baseline 是处理不了这点的(例如 AMD+ 和 OCLR),他们把人分割成了几个部分。

还有就是影子和反射,比如上面这只天鹅,它的倒影跟它的运动是一致的(Optical Flow 可视化颜色一样),所以之前的方法认为天鹅跟倒影是一个物体。很多视频里是有这类现象的(毕竟大太阳下物体都有个影子嘛),如果这个处理不了的话,很多视频也不能分割了。

那怎么解决?放松。Relax.
长话短说,那我们的方法是怎么解决这个问题的呢?无监督学习的一个特性是利用神经网络自己内部的泛化和拟合能力进行学习。既然 Common Fate 有自己的问题,那么我们没有必要强制神经网络去拟合 Common Fate。于是我们提出了 Relaxed Common Fate,通过一个比较弱的学习方式让神经网络真正学到物体的特性而不是 noise。
具体来说,我们的方法认为物体运动由两部分组成:物体总体的 piecewise-constant motion (也就是 Common Fate)和物体内部的 segment motion。比如你看下图这个舞者,他全身的运动就可以被理解成 piecewise-constant motion 来建模,手部腿部这些运动就可以作为 residual motion 进行拟合,最后合并成一个完整的 flow,跟 RAFT 生成的 flow 进行比较来算 loss。我们用的 RAFT 是用合成数据(FlyingChairs 和 FlyingThings)进行训练的,不需要人工标注。

Relaxed Common Fate
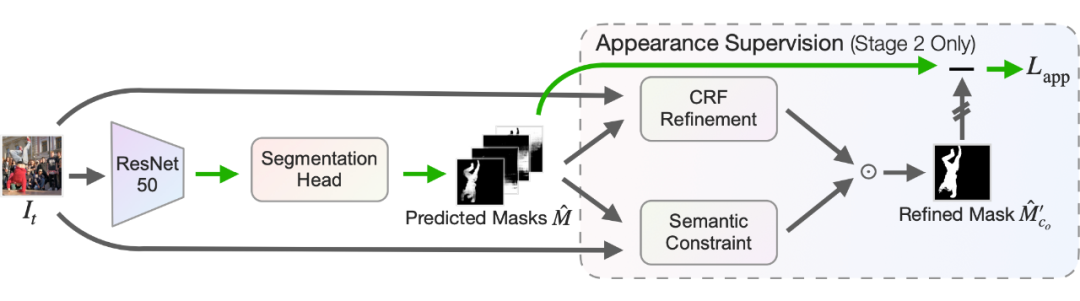
首先我们使用一个 backbone 来进行特征提取,然后通过一个简单的 full-convolutional network 获得 Predicted Masks (下图里的下半部分),和一般的分割框架是一样的,也可以切换成别的框架。 那我们怎么优化这些 Masks 呢?我们先提取、合并两帧的特征,放入一个 residual flow prediction head 来获得 Residual Flow (下图里的上半部分)。 然后我们对 RAFT 获得的 Flow 用 Predicted Masks 进行 Guided Pooling,获得一个 piecewise-constant flow,再加上预测的 residual flow,就是我们的 flow prediction 了。最后把 flow prediction 和 RAFT 获得的 Flow 的差算一个 L1 norm Loss 进行优化,以此来学习 segmentation。 在测试的时候,只有 Predicted Masks 是有用的,其他部分是不用的。
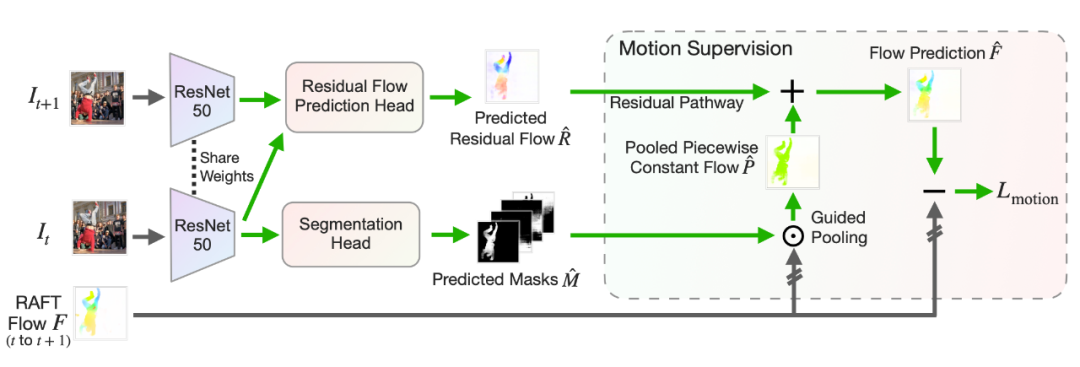
这里的 Residual Flow 会尽量初始化得小一些,来鼓励先学 piecewise-constant 的部分(有点类似 ControlNet),再慢慢学习 residual 部分。

引入Appearance信息来帮助无监督视频分割
光是 Relaxed Common Fate 就能在 DAVIS 上相对 baseline 提 5%了,但这还不够。前面说 Relaxed Common Fate 的只用了 motion 而没有使用 appearance 信息。
让我们再次回到上面这个例子。这个舞者的手和身子是一个颜色,然而 AMD+ 直接把舞者的手忽略了。下面这只天鹅和倒影明明在 appearance 上差别这么大,却在 motion 上没什么差别。如果整合 appearance 和 motion,是不是能提升分割质量呢?
因此我们引入了 Appearance 来进行进一步的监督。在学习完 motion 信息之后,我们直接把取得的 Mask 进行两步优化:一个是 low-level 的 CRF refinement,强调颜色等细节一致的地方应该属于同一个 mask(或背景),一个是 semantic constraint,强调 Unsupervised Feature 一直的地方应该属于同一个 mask。
把优化完的 mask 再和原 mask 进行比较,计算 L2 Loss,再更新神经网络。这样训练的模型的无监督分割能力可以进一步提升。具体细节欢迎阅读原文。

无监督调参
很多无监督方法都需要使用有标注的数据集来调参,而我们的方法提出可以利用前面说的 motion 和 appearance 的一致性来进行调参。简单地说,motion 学习出的 mask 在 appearance 上不一致代表这个参数可能不是最优的。具体方法是在 Unsupervised Feature 上计算 Normalized Cuts (但是不用算出最优值),Normalized Cuts 越小越代表分割效果好。原文里面对此有详细描述。

方法效果
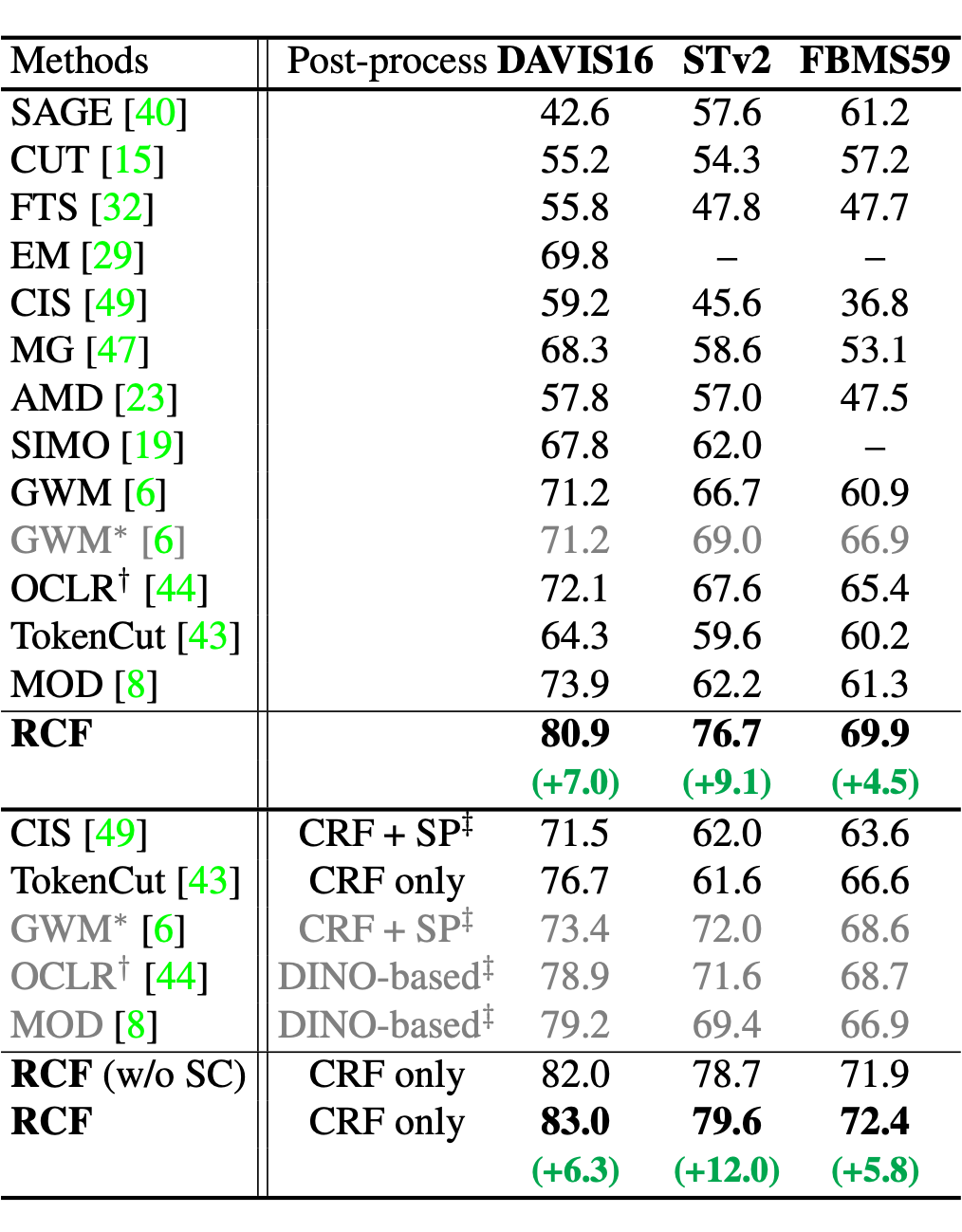
无论是否有 Post-processing,我们的方法在三个视频分割数据集上都有很大提升,在 STv2 上更是提升了 12%。
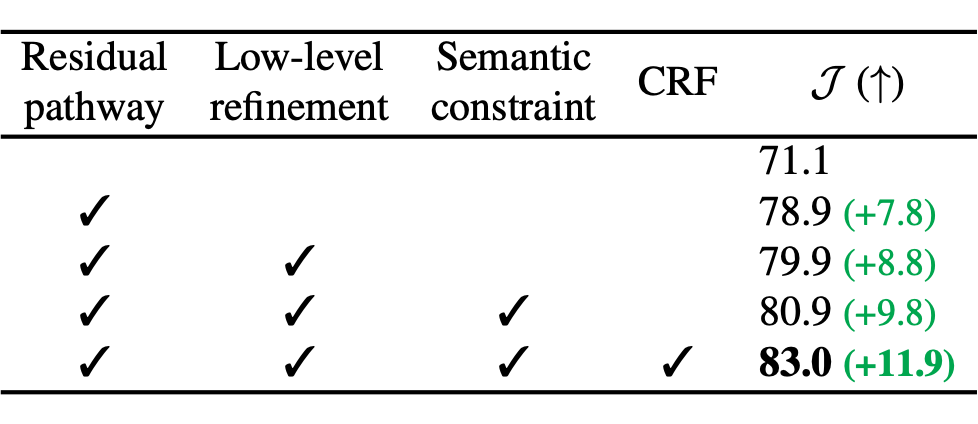
Ablation 可以看出 Residual pathway (Relaxed Common Fate)的贡献是最大的,其他部分总计贡献了 11.9% 的增长。
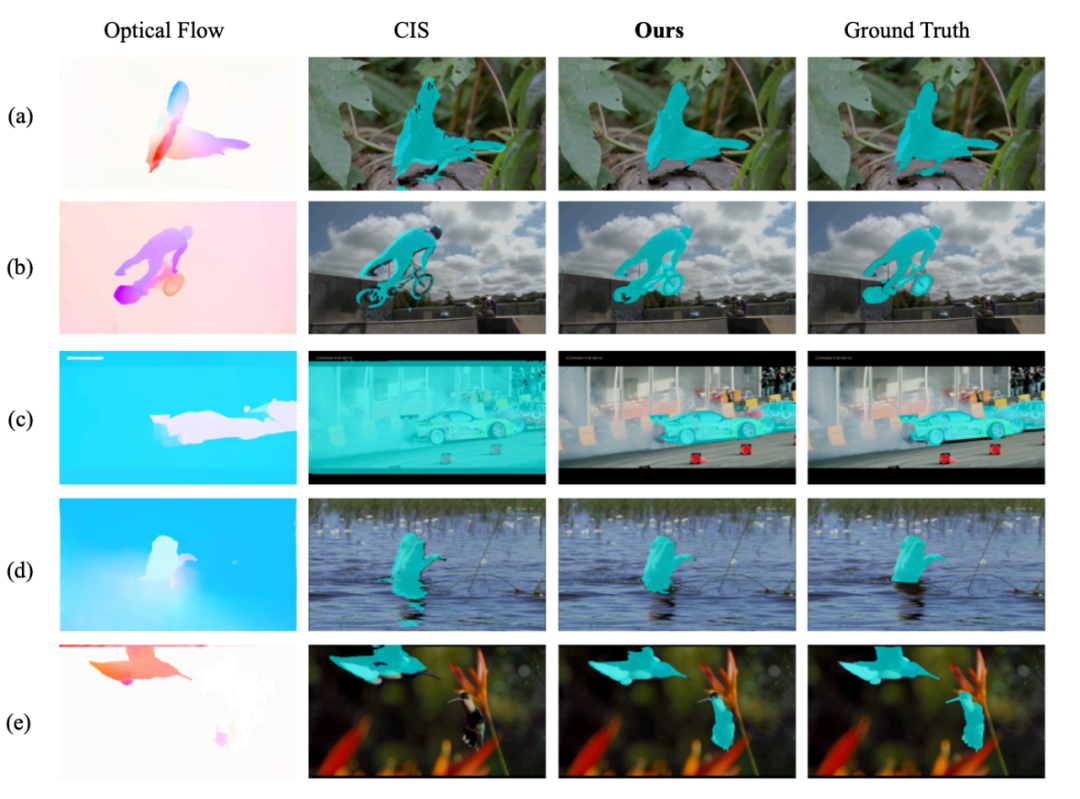
Visualizations




总结
这篇 CVPR 2023 文章研究了完全不需要标注的视频物体分割。通过 Relaxed Common Fate 来利用 motion 信息,再通过改进和利用 appearance 信息来进一步优化,RCF 模型在 DAVIS16/STv2/FBMS59 上提升了 7/9/5%。文章里还提出了不需要标注的调参方法。代码和模型已公开可用。
原文标题:CVPR 2023 | 完全无监督的视频物体分割 RCF
文章出处:【微信公众号:智能感知与物联网技术研究所】欢迎添加关注!文章转载请注明出处。
- 相关推荐
- 热点推荐
- 物联网
-
ESP8685的射频部分完全无法使用了怎么解决?2024-07-01 453
-
2280规格SSD使用附带螺丝完全无法锁住是为什么?2023-09-12 696
-
立体声耳机完全无声的修理2009-09-02 1711
-
半监督的谱聚类图像分割2017-11-13 1073
-
劳斯莱斯计划在2025年前实现完全无人驾驶船队的部署2018-11-26 2498
-
基于无监督空间一致性约束的心脏MRI分割2021-06-27 990
-
快速HAC聚类算法的改进及应用于无监督语音分割2021-07-26 1100
-
用于弱监督大规模点云语义分割的混合对比正则化框架2022-09-05 2410
-
一个全新的无监督不需要明确物体种类的实例分割算法2022-10-11 3781
-
首个无监督3D点云物体实例分割算法2022-11-09 3717
-
英伟达新方法入选CVPR 2023:对未知物体的6D姿态追踪和三维重建2023-04-10 1569
-
SAM-PT:点几下鼠标,视频目标就分割出来了!2023-07-10 1692
-
TLDR: 视频分割一直是重标注的一个task,这篇CVPR 2023文章研究了完全不需要标注的视频物体分割。2023-07-12 1387
-
CVPR 2023 中的领域适应:用于切片方向连续的无监督跨模态医学图像分割2023-08-17 3368
-
复旦开源LVOS:面向真实场景的长时视频目标分割数据集2023-09-04 2258
全部0条评论

快来发表一下你的评论吧 !
