

基于扩散模型的图像生成过程
描述
近年来,扩散模型在文本到图像生成方面取得了巨大的成功,实现了更高图像生成质量,提高了推理性能,也可以激发扩展创作灵感。
不过仅凭文本来控制图像的生成往往得不到想要的结果,比如具体的人物姿势、面部表情等很难用文本指定。
最近,谷歌发布了MediaPipe Diffusion插件,可以在移动设备上运行「可控文本到图像生成」的低成本解决方案,支持现有的预训练扩散模型及其低秩自适应(LoRA)变体
背景知识
基于扩散模型的图像生成过程可以认为是一个迭代去噪过程。
从噪声图像开始,在每个步骤中,扩散模型会逐渐对图像进行降噪以生成符合目标概念的图像,将文本提示作为条件可以大大提升图像生成的效果。
对于文本到图像生成,文本嵌入通过交叉注意层连接到图像生成模型上,不过仍然有部分信息难以通过文本提示来描述,比如物体的位置和姿态等。
为了解决这个问题,研究人员提出引入额外的模型添加到扩散模型中,在条件图像中注入控制信息。
常用的控制文生图方法包括:
1. 即插即用(Plug-and-Play)用到去噪扩散隐式模型(DDIM)inversion方法,从输入图像开始反转生成过程来导出初始噪声输入,然后采用扩散模型(Stable Diffusion1.5的情况下需要8.6亿参数)对来自输入图像的条件进行编码。
即插即用从复制的扩散中提取具有自注意力的空间特征,并将其注入到文本转图像的扩散过程中。
2. ControlNet会创建扩散模型编码器的一个可训练副本,通过零初始化参数后的卷积层连接,将传递到解码器层的条件信息进行编码。
3. T2I Adapter是一个较小的网络(7700万参数),在可控生成中可以实现类似的效果,只需要将条件图像作为输入,其输出在所有扩散迭代中共享。
不过T2I适配器模型并不是为便携式移动设备设计的。
MediaPipe Diffusion插件
为了使条件生成更高效、可定制且可扩展,研究人员将MediaPipe扩散插件设计为一个单独的网络:
1. 可插入(Plugable):可以很容易地与预训练基础模型进行连接;
2. 从零开始训练(Trained from scratch):不使用来自基础模型的预训练权重;
3. 可移植性(Portable):可以在移动设备上运行基础模型,并且推理成本相比原模型来说可以忽略不计。

即插即用、ControlNet、T2I适配器和MediaPipe扩散插件的对比,*具体数字会根据选用模型不同而发生变化
简单来说,MediaPipe扩散插件就是一个用于文本到图像生成的,可在便携式设备上运行的模型,从条件图像中提取多尺度特征,并添加到相应层次扩散模型的编码器中;当连接到文生图扩散模型时,插件模型可以向图像生成提供额外的条件信号。
插件网络是一个轻量级的模型,只有600万参数,使用MobileNetv2中的深度卷积和反向瓶颈(inverted bottleneck)在移动设备上实现快速推理。
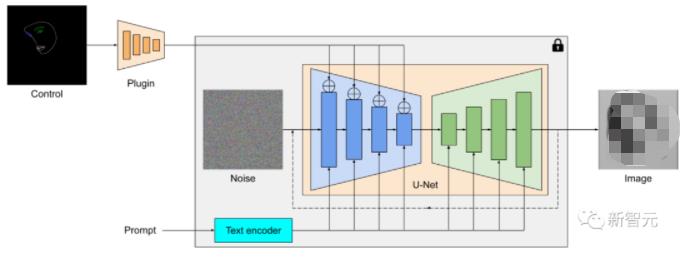
MediaPipe扩散模型插件是一个单独的网络,输出可以插入到预训练的文本到图像生成模型中,提取的特征应用于扩散模型的相关下采样层(蓝色)。
与ControlNet不同,研究人员在所有扩散迭代中注入相同的控制功能,所以对于图像生成过程只需要运行一次插件,节省了计算量。
下面的例子中可以看到,控制效果在每个扩散步骤都是有效的,即使在前期迭代步中也能够控制生成过程;更多的迭代次数可以改善图像与文本提示的对齐,并生成更多的细节。
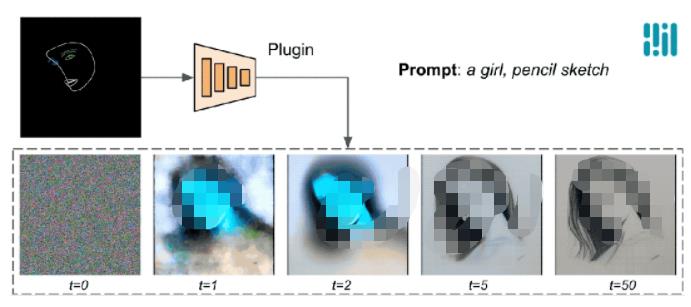
使用MediaPipe扩散插件进行生成过程的演示
示例
在这项工作中,研究人员开发了基于扩散的文本到图像生成模型与MediaPipe face landmark,MediaPipe holistic landmark,深度图和Canny边缘的插件。
对于每个任务,从超大规模的图像-文本数据集中选择约10万张图像,并使用相应的MediaPipe解决方案计算控制信号,使用PaLI优化后的描述来对插件进行训练。
Face Landmark
MediaPipe Face Landmarker任务计算人脸的478个landmark(具有注意力)。
研究人员使用MediaPipe中的drawing utils来渲染人脸,包括脸部轮廓、嘴巴、眼睛、眉毛和虹膜,并使用不同的颜色进行表示。
下面这个例子展现了通过调节面网格和提示随机生成的样本;作为对比,ControlNet和Plugin都可以在给定条件下控制文本到图像的生成。
用于文本到图像生成的Face-landmark插件,与ControlNet进行比较。
Holistic Landmark
MediaPipe Holistic Landmark任务包括身体姿势、手和面部网格的landmark,可以通过调节整体特征来生成各种风格化的图像。

用于文本到图像生成的Holistic landmark插件。
深度
深度插件的文本到图像生成。
Canny Edge
用于生成文本到图像的Canny-edge插件。
评估
研究人员对face landmark插件进行定量评估以证明该模型的性能,评估数据集包含5000张人类图像,使用的评估指标包括Fréchet起始距离(FID)和CLIP分数。
基础模型使用预训练的文本到图像扩散模型Stable Diffusion v1.5
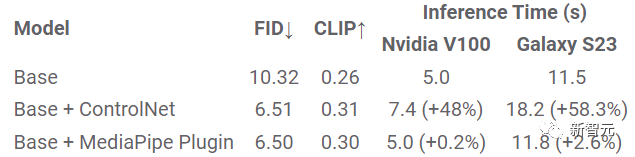
FID、CLIP和推理时间的定量比较
从实验结果中的FID和CLIP分数来看,ControlNet和MediaPipe扩散插件生成的样本质量比基础模型好得多。
与ControlNet不同,插件模型只需要为每个生成的图像运行一次,不需要在每个去噪步中都运行,所以推理时间只增加了2.6%
研究人员在服务器机器(使用Nvidia V100 GPU)和移动端设备(Galaxy S23)上测量了三种模型的性能:在服务器上,使用50个扩散步骤运行所有三个模型;在移动端上,使用MediaPipe图像生成应用程序运行20个扩散步骤。
与ControlNet相比,MediaPipe插件在保持样本质量的同时,在推理效率方面表现出明显的优势。
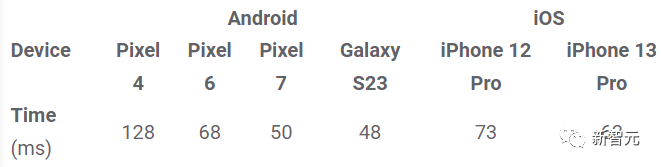
插件在不同移动的设备上的推理时间(ms)
总结
在这项工作中,研究人员提出了MediaPipe,一个可在移动端使用的、有条件的文本到图像生成插件,将从条件图像中提取的特征注入扩散模型,从而控制图像的生成过程。
便携式插件可以连接到在服务器或设备上运行的预训练的扩散模型,通过在设备上完全运行文本到图像生成和插件,可以更灵活地应用生成式AI
责任编辑:彭菁
-
如何在PyTorch中使用扩散模型生成图像2023-11-22 1405
-
基于图像局部结构的扩散平滑2009-04-23 912
-
基于生成器的图像分类对抗样本生成模型2021-04-07 1381
-
基于像素级生成对抗网络的图像彩色化模型2021-06-27 920
-
扩散模型在视频领域表现如何?2022-04-13 2715
-
如何改进和加速扩散模型采样的方法22022-05-07 4562
-
新晋图像生成王者扩散模型2022-06-06 2170
-
扩散模型和其在文本生成图像任务上的应用2022-08-03 4046
-
蒸馏无分类器指导扩散模型的方法2022-10-13 2321
-
基于文本到图像模型的可控文本到视频生成2023-06-14 2158
-
如何加速生成2 PyTorch扩散模型2023-09-04 2237
-
DDFM:首个使用扩散模型进行多模态图像融合的方法2023-09-19 8046
-
基于DiAD扩散模型的多类异常检测工作2024-01-08 3276
-
KOALA人工智能图像生成模型问世2024-03-05 1700
-
借助谷歌Gemini和Imagen模型生成高质量图像2025-01-03 1828
全部0条评论

快来发表一下你的评论吧 !
