

从Kafka中学习高性能系统如何设计
描述
1 前言
相信各位小伙伴之前或多或少接触过消息队列,比较知名的包含 Rocket MQ 和 Kafka,在京东内部使用的是自研的消息中间件 JMQ,从 JMQ2 升级到 JMQ4 的也是带来了性能上的明显提升,并且 JMQ4 的底层也是参考 Kafka 去做的设计。在这里我会给大家展示 Kafka 它的高性能是如何设计的,大家也可以学习相关方法论将其利用在实际项目中,也许下一个顶级项目就在各位的代码中产生了。
2 如何理解高性能设计
2.1 高性能设计的” 秘籍”
先抛开 kafka,咱们先来谈论一下高性能设计的本质,在这里借用一下网上的一张总结高性能的思维导图: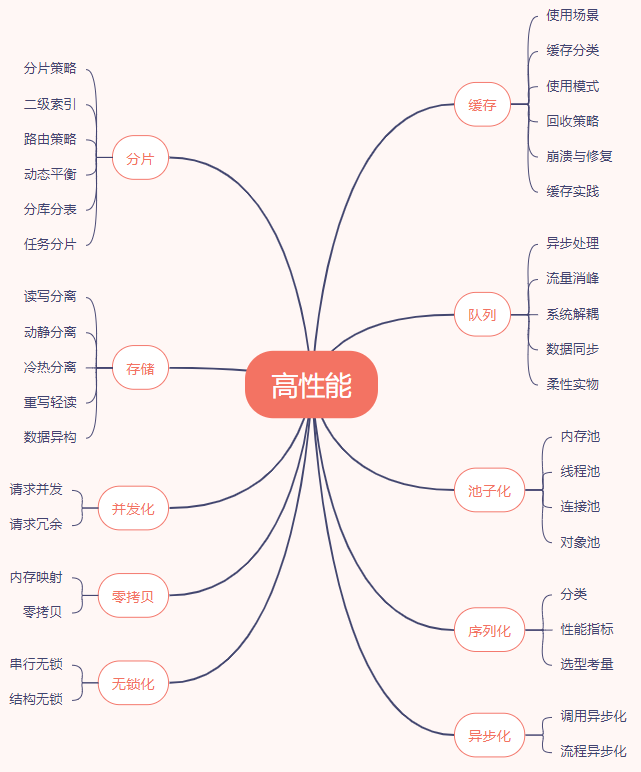
从中可以看到,高性能设计的手段还是非常多,从” 微观设计” 上的无锁化、序列化,到” 宏观设计” 上的缓存、存储等,可以说是五花八门,令人眼花缭乱。但是在我看来本质就两点:计算和 IO。下面将从这两点来浅析一下我认为的高性能的” 道”。
2.2 高性能设计的” 道法”
2.2.1 计算上的” 道”
计算上的优化手段无外乎两种方式:1. 减少计算量 2. 加快单位时间的计算量
减少计算量:比如用索引来取代全局扫描、用同步代替异步、通过限流来减少请求处理量、采用更高效的数据结构和算法等。(举例:mysql 的 BTree,redis 的跳表等)
加快单位时间的计算量:可以利用 CPU 多核的特性,比如用多线程代替单线程、用集群代替单机等。(举例:多线程编程、分治计算等)
2.2.2 IO 上的” 道”
IO 上的优化手段也可以从两个方面来体现:1. 减少 IO 次数或者 IO 数据量 2. 加快 IO 速度
减少 IO 次数或者 IO 数据量:比如借助系统缓存或者外部缓存、通过零拷贝技术减少 IO 复制次数、批量读写、数据压缩等。
加快 IO 速度:比如用磁盘顺序写代替随机写、用 NIO 代替 BIO、用性能更好的 SSD 代替机械硬盘等。
3 kafka 高性能设计
理解了高性能设计的手段和本质之后,我们再来看看 kafka 里面使用到的性能优化方法。各类消息中间件的本质都是一个生产者 - 消费者模型,生产者发送消息给服务端进行暂存,消费者从服务端获取消息进行消费。也就是说 kafka 分为三个部分:生产者 - 服务端 - 消费者,我们可以按照这三个来分别归纳一下其关于性能优化的手段,这些手段也会涵盖在我们之前梳理的脑图里面。
3.1 生产者的高性能设计
3.1.1 批量发送消息
之前在上面说过,高性能的” 道” 在于计算和 IO 上,咱们先来看看在 IO 上 kafka 是如何做设计的。 IO 上的优化
kafka 是一个消息中间件,数据的载体就是消息,如何将消息高效的进行传递和持久化是 kafka 高性能设计的一个重点。基于此分析 kafka 肯定是 IO 密集型应用,producer 需要通过网络 IO 将消息传递给 broker,broker 需要通过磁盘 IO 将消息持久化,consumer 需要通过网络 IO 将消息从 broker 上拉取消费。
网络 IO 上的优化:producer->broker 发送消息不是一条一条发送的,kafka 模式会有个消息发送延迟机制,会将一批消息进行聚合,一口气打包发送给 broker,这样就成功减少了 IO 的次数。除了传输消息本身以外,还要传输非常多的网络协议本身的一些内容(称为 Overhead),所以将多条消息合并到一起传输,可有效减少网络传输的 Overhead,进而提高了传输效率。
磁盘 IO 上的优化:大家知道磁盘和内存的存储速度是不同的,在磁盘上操作的速度是远低于内存,但是在成本上内存是高于磁盘。kafka 是面向大数据量的消息中间件,也就是说需要将大批量的数据持久化,这些数据放在内存上也是不现实。那 kafka 是怎么在磁盘 IO 上进行优化的呢?在这里我先直接给出方法,具体细节在后文中解释(它是借助于一种磁盘顺序写的机制来提升写入速度)。
3.1.2 负载均衡
1.kafka 负载均衡设计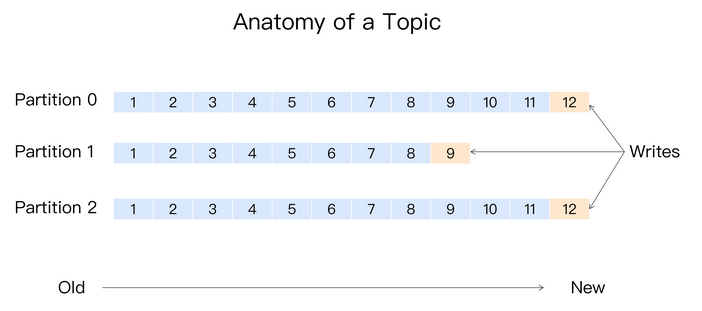
Kafka 有主题(Topic)概念,他是承载真实数据的逻辑容器,主题之下还分为若干个分区,Kafka 消息组织方式实际上是三级结构:主题 - 分区 - 消息。主题下的每条消息只会在某一个分区中,而不会在多个分区中被保存多份。
Kafka 这样设计,使用分区的作用就是提供负载均衡的能力,对数据进行分区的主要目的就是为了实现系统的高伸缩性(Scalability)。
不同的分区能够放在不同的节点的机器上,而数据的读写操作也都是针对分区这个粒度进行的,每个节点的机器都能独立地执行各自分区读写请求。我们还可以通过增加节点来提升整体系统的吞吐量。Kafka 的分区设计,还可以实现业务级别的消息顺序的问题。
2. 具体分区策略
所谓的分区策略是指决定生产者将消息发送到那个分区的算法。Kafka 提供了默认的分区策略是轮询,同时 kafka 也支持用户自己制定。
轮询策略:也称为 Round-robin 策略,即顺序分配。轮询的优点是有着优秀的负载均衡的表现。
随机策略:虽然也是追求负载均衡,但总体表现差于轮询。
消息键划分策略:还要一种是为每条消息配置一个 key,按消息的 key 来存。Kafka 允许为每条消息指定一个 key。一旦指定了 key ,那么会对 key 进行 hash 计算,将相同的 key 存入相同的分区中,而且每个分区下的消息都是有序的。key 的作用很大,可以是一个有着明确业务含义的字符串,也可以是用来表征消息的元数据。
其他的分区策略:基于地理位置的分区。可以从所有分区中找出那些 Leader 副本在某个地理位置所有分区,然后随机挑选一个进行消息发送。
3.1.3 异步发送
1. 线程模型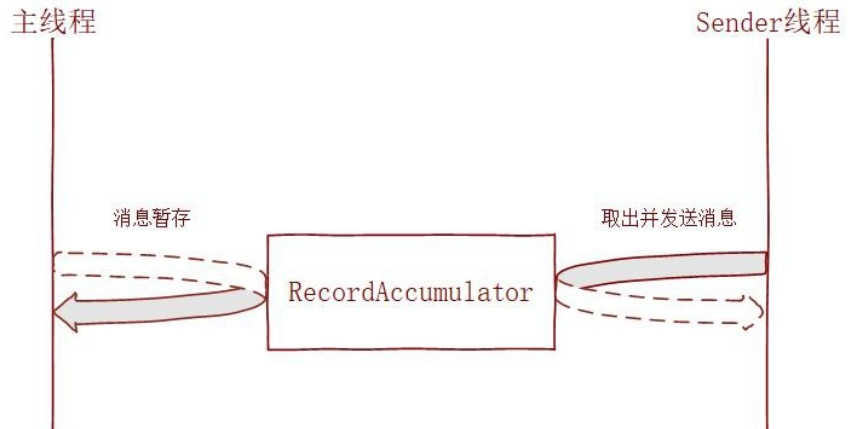
之前已经说了 kafka 是选择批量发送消息来提升整体的 IO 性能,具体流程是 kafka 生产者使用批处理试图在内存中积累数据,主线程将多条消息通过一个 ProduceRequest 请求批量发送出去,发送的消息暂存在一个队列 (RecordAccumulator) 中,再由 sender 线程去获取一批数据或者不超过某个延迟时间内的数据发送给 broker 进行持久化。
优点:
可以提升 kafka 整体的吞吐量,减少网络 IO 的次数;
提高数据压缩效率 (一般压缩算法都是数据量越大越能接近预期的压缩效果);
缺点:
数据发送有一定延迟,但是这个延迟可以由业务因素来自行设置。
3.1.4 高效序列化
1. 序列化的优势
Kafka 消息中的 Key 和 Value,都支持自定义类型,只需要提供相应的序列化和反序列化器即可。因此,用户可以根据实际情况选用快速且紧凑的序列化方式(比如 ProtoBuf、Avro)来减少实际的网络传输量以及磁盘存储量,进一步提高吞吐量。
2. 内置的序列化器
org.apache.kafka.common.serialization.StringSerializer;
org.apache.kafka.common.serialization.LongSerializer;
org.apache.kafka.common.serialization.IntegerSerializer;
org.apache.kafka.common.serialization.ShortSerializer;
org.apache.kafka.common.serialization.FloatSerializer;
org.apache.kafka.common.serialization.DoubleSerializer;
org.apache.kafka.common.serialization.BytesSerializer;
org.apache.kafka.common.serialization.ByteBufferSerializer;
org.apache.kafka.common.serialization.ByteArraySerializer;
3.1.5 消息压缩
1. 压缩的目的
压缩秉承了用时间换空间的经典 trade-off 思想,即用 CPU 的时间去换取磁盘空间或网络 I/O 传输量,Kafka 的压缩算法也是出于这种目的。并且通常是:数据量越大,压缩效果才会越好。
因为有了批量发送这个前期,从而使得 Kafka 的消息压缩机制能真正发挥出它的威力(压缩的本质取决于多消息的重复性)。对比压缩单条消息,同时对多条消息进行压缩,能大幅减少数据量,从而更大程度提高网络传输率。 2. 压缩的
方法
想了解 kafka 消息压缩的设计,就需要先了解 kafka 消息的格式:
Kafka 的消息层次分为:消息集合(message set)和消息(message);一个消息集合中包含若干条日志项(record item),而日志项才是真正封装消息的地方。
Kafka 底层的消息日志由一系列消息集合 - 日志项组成。Kafka 通常不会直接操作具体的一条条消息,他总是在消息集合这个层面上进行写入操作。
每条消息都含有自己的元数据信息,kafka 会将一批消息相同的元数据信息给提升到外层的消息集合里面,然后再对整个消息集合来进行压缩。批量消息在持久化到 Broker 中的磁盘时,仍然保持的是压缩状态,最终是在 Consumer 端做了解压缩操作。
压缩算法效率对比
Kafka 共支持四种主要的压缩类型:Gzip、Snappy、Lz4 和 Zstd,具体效率对比如下: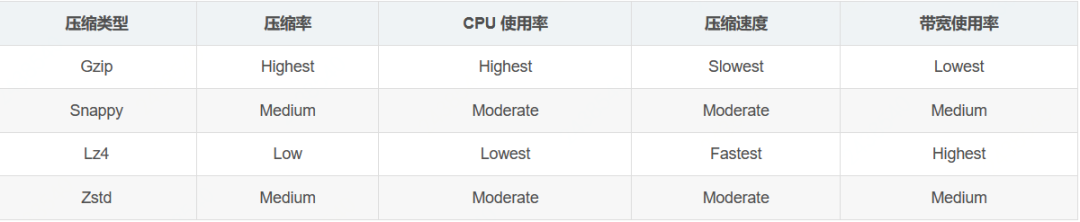
3.2 服务端的高性能设计
3.2.1 Reactor 网络通信模型
kafka 相比其他消息中间件最出彩的地方在于他的高吞吐量,那么对于服务端来说每秒的请求压力将会巨大,需要有一个优秀的网络通信机制来处理海量的请求。如果 IO 有所研究的同学,应该清楚:Reactor 模式正是采用了很经典的 IO 多路复用技术,它可以复用一个线程去处理大量的 Socket 连接,从而保证高性能。Netty 和 Redis 为什么能做到十万甚至百万并发?它们其实都采用了 Reactor 网络通信模型。
1.kafka 网络通信层架构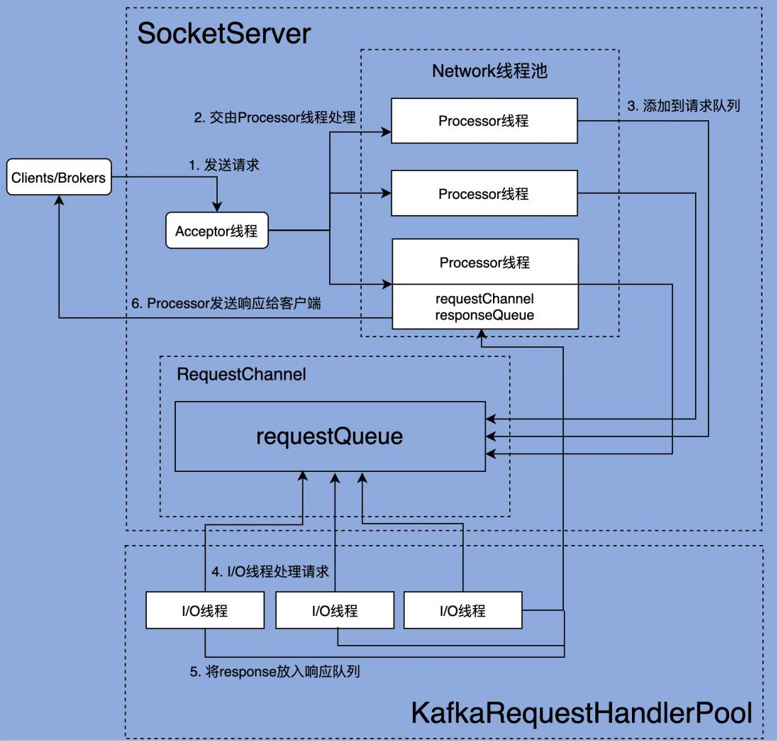
从图中可以看出,SocketServer 和 KafkaRequestHandlerPool 是其中最重要的两个组件:
SocketServer:主要实现了 Reactor 模式,用于处理外部多个 Clients(这里的 Clients 指的是广义的 Clients,可能包含 Producer、Consumer 或其他 Broker)的并发请求,并负责将处理结果封装进 Response 中,返还给 Clients
KafkaRequestHandlerPool:Reactor 模式中的 Worker 线程池,里面定义了多个工作线程,用于处理实际的 I/O 请求逻辑。
2. 请求流程
Clients 或其他 Broker 通过 Selector 机制发起创建连接请求。(NIO 的机制,使用 epoll)
Processor 线程接收请求,并将其转换成可处理的 Request 对象。
Processor 线程将 Request 对象放入共享的 RequestChannel 的 Request 队列。
KafkaRequestHandler 线程从 Request 队列中取出待处理请求,并进行处理。
KafkaRequestHandler 线程将 Response 放回到对应 Processor 线程的 Response 队列。
Processor 线程发送 Response 给 Request 发送方。
3.2.2 Kafka 的底层日志结构
基本结构的展示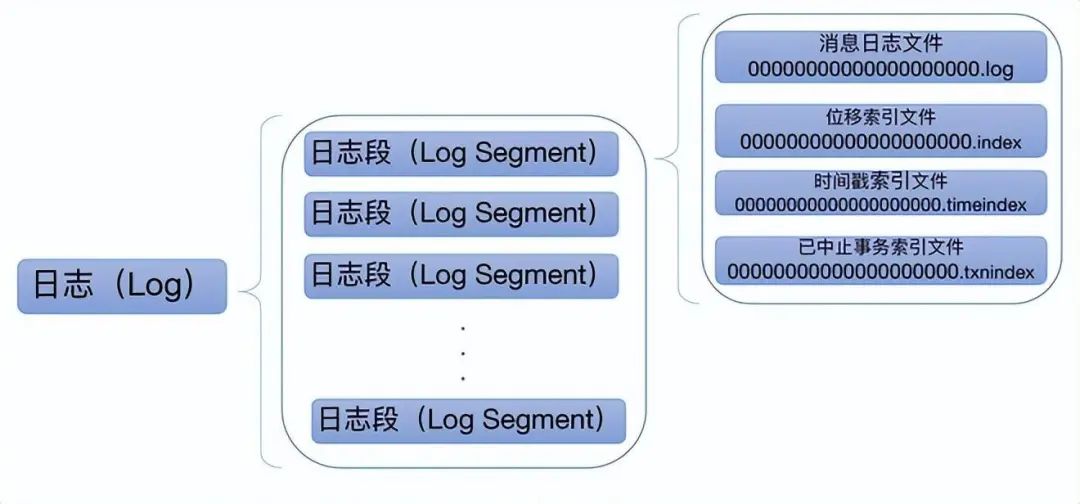
Kafka 是一个 Pub-Sub 的消息系统,无论是发布还是订阅,都须指定 Topic。Topic 只是一个逻辑的概念。每个 Topic 都包含一个或多个 Partition,不同 Partition 可位于不同节点。同时 Partition 在物理上对应一个本地文件夹 (也就是个日志对象 Log),每个 Partition 包含一个或多个 Segment,每个 Segment 包含一个数据文件和多个与之对应的索引文件。在逻辑上,可以把一个 Partition 当作一个非常长的数组,可通过这个 “数组” 的索引(offset)去访问其数据。 2.Partition 的并行处理能力
一方面,topic 是由多个 partion 组成,Producer 发送消息到 topic 是有个负载均衡机制,基本上会将消息平均分配到每个 partion 里面,同时 consumer 里面会有个 consumer group 的概念,也就是说它会以组为单位来消费一个 topic 内的消息,一个 consumer group 内包含多个 consumer,每个 consumer 消费 topic 内不同的 partion,这样通过多 partion 提高了消息的接收和处理能力
另一方面,由于不同 Partition 可位于不同机器,因此可以充分利用集群优势,实现机器间的并行处理。并且 Partition 在物理上对应一个文件夹,即使多个 Partition 位于同一个节点,也可通过配置让同一节点上的不同 Partition 置于不同的 disk drive 上,从而实现磁盘间的并行处理,充分发挥多磁盘的优势。
3. 过期消息的清除
Kafka 的整个设计中,Partition 相当于一个非常长的数组,而 Broker 接收到的所有消息顺序写入这个大数组中。同时 Consumer 通过 Offset 顺序消费这些数据,并且不删除已经消费的数据,从而避免了随机写磁盘的过程。
由于磁盘有限,不可能保存所有数据,实际上作为消息系统 Kafka 也没必要保存所有数据,需要删除旧的数据。而这个删除过程,并非通过使用 “读 - 写” 模式去修改文件,而是将 Partition 分为多个 Segment,每个 Segment 对应一个物理文件,通过删除整个文件的方式去删除 Partition 内的数据。这种方式清除旧数据的方式,也避免了对文件的随机写操作。
3.2.3 朴实高效的索引
1. 稀疏索引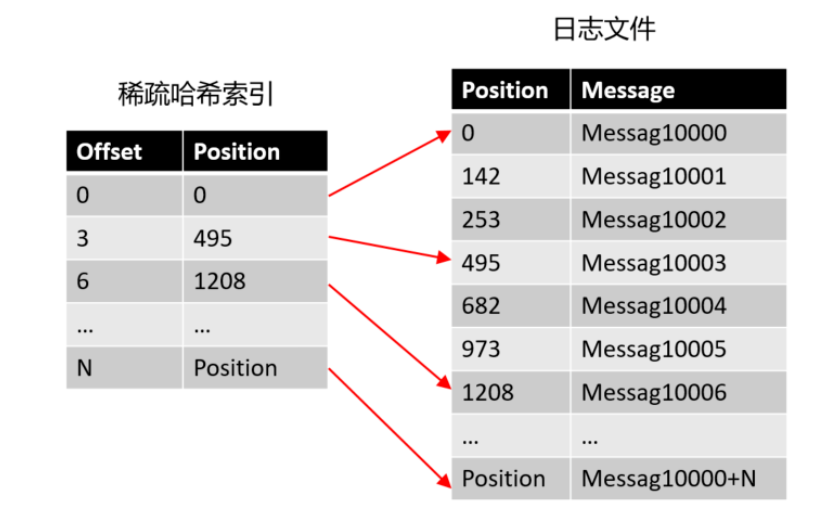
可以从上面看到,一个 segment 包含一个.log 后缀的文件和多个 index 后缀的文件。那么这些文件具体作用是干啥的呢?并且这些文件除了后缀不同文件名都是相同,为什么这么设计?
.log 文件:具体存储消息的日志文件
.index 文件:位移索引文件,可根据消息的位移值快速地从查询到消息的物理文件位置
.timeindex 文件:时间戳索引文件,可根据时间戳查找到对应的位移信息
.txnindex 文件:已中止事物索引文件
除了.log 是实际存储消息的文件以外,其他的几个文件都是索引文件。索引本身设计的原来是一种空间换时间的概念,在这里 kafka 是为了加速查询所使用。kafka 索引不会为每一条消息建立索引关系,这个也很好理解,毕竟对一条消息建立索引的成本还是比较大的,所以它是一种稀疏索引的概念,就好比我们常见的跳表,都是一种稀疏索引。
kafka 日志的文件名一般都是该 segment 写入的第一条消息的起始位移值 baseOffset,比如 000000000123.log,这里面的 123 就是 baseOffset,具体索引文件里面纪录的数据是相对于起始位移的相对位移值 relativeOffset,baseOffset 与 relativeOffse 的加和即为实际消息的索引值。假设一个索引文件为:00000000000000000100.index,那么起始位移值即 100,当存储位移为 150 的消息索引时,在索引文件中的相对位移则为 150 - 100 = 50,这么做的好处是使用 4 字节保存位移即可,可以节省非常多的磁盘空间。(ps:kafka 真的是极致的压缩了数据存储的空间)
2. 优化的二分查找算法
kafka 没有使用我们熟知的跳表或者 B+Tree 结构来设计索引,而是使用了一种更为简单且高效的查找算法:二分查找。但是相对于传统的二分查找,kafka 将其进行了部分优化,个人觉得设计的非常巧妙,在这里我会进行详述。
在这之前,我先补充一下 kafka 索引文件的构成:每个索引文件包含若干条索引项。不同索引文件的索引项的大小不同,比如 offsetIndex 索引项大小是 8B,timeIndex 索引项的大小是 12B。
这里以 offsetIndex 为例子来详述 kafka 的二分查找算法:
1)普通二分查找
offsetIndex 每个索引项大小是 8B,但操作系统访问内存时的最小单元是页,一般是 4KB,即 4096B,会包含了 512 个索引项。而找出在索引中的指定偏移量,对于操作系统访问内存时则变成了找出指定偏移量所在的页。假设索引的大小有 13 个页,如下图所示:
由于 Kafka 读取消息,一般都是读取最新的偏移量,所以要查询的页就集中在尾部,即第 12 号页上。根据二分查找,将依次访问 6、9、11、12 号页。
当随着 Kafka 接收消息的增加,索引文件也会增加至第 13 号页,这时根据二分查找,将依次访问 7、10、12、13 号页。
可以看出访问的页和上一次的页完全不同。之前在只有 12 号页的时候,Kafak 读取索引时会频繁访问 6、9、11、12 号页,而由于 Kafka 使用了mmap来提高速度,即读写操作都将通过操作系统的 page cache,所以 6、9、11、12 号页会被缓存到 page cache 中,避免磁盘加载。但是当增至 13 号页时,则需要访问 7、10、12、13 号页,而由于 7、10 号页长时间没有被访问(现代操作系统都是使用 LRU 或其变体来管理 page cache),很可能已经不在 page cache 中了,那么就会造成缺页中断(线程被阻塞等待从磁盘加载没有被缓存到 page cache 的数据)。在 Kafka 的官方测试中,这种情况会造成几毫秒至 1 秒的延迟。 2)kafka 优化的二分查找
Kafka 对二分查找进行了改进。既然一般读取数据集中在索引的尾部。那么将索引中最后的 8192B(8KB)划分为 “热区”(刚好缓存两页数据),其余部分划分为 “冷区”,分别进行二分查找。这样做的好处是,在频繁查询尾部的情况下,尾部的页基本都能在 page cahce 中,从而避免缺页中断。
下面我们还是用之前的例子来看下。由于每个页最多包含 512 个索引项,而最后的 1024 个索引项所在页会被认为是热区。那么当 12 号页未满时,则 10、11、12 会被判定是热区;而当 12 号页刚好满了的时候,则 11、12 被判定为热区;当增至 13 号页且未满时,11、12、13 被判定为热区。假设我们读取的是最新的消息,则在热区中进行二分查找的情况如下: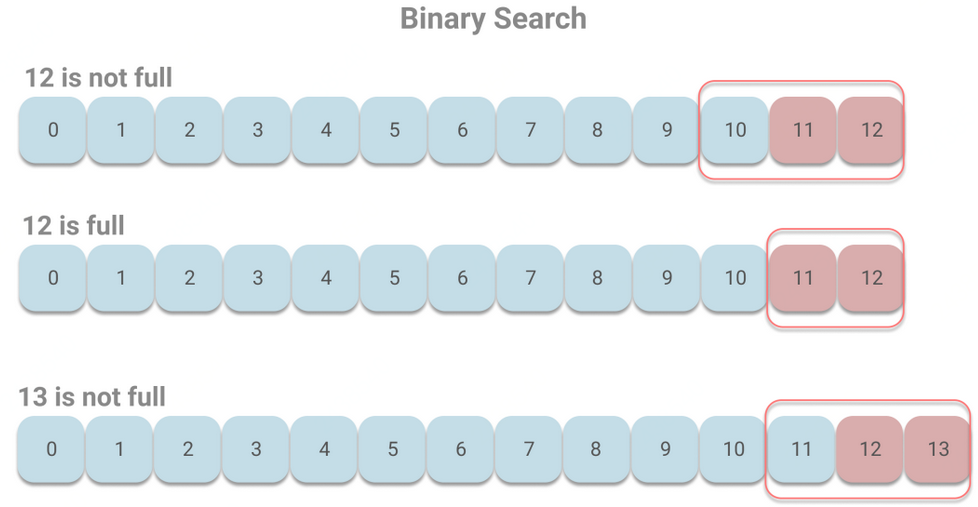
当 12 号页未满时,依次访问 11、12 号页,当 12 号页满时,访问页的情况相同。当 13 号页出现的时候,依次访问 12、13 号页,不会出现访问长时间未访问的页,则能有效避免缺页中断。
3.mmap 的使用
利用稀疏索引,已经基本解决了高效查询的问题,但是这个过程中仍然有进一步的优化空间,那便是通过 mmap(memory mapped files) 读写上面提到的稀疏索引文件,进一步提高查询消息的速度。
究竟如何理解 mmap?前面提到,常规的文件操作为了提高读写性能,使用了 Page Cache 机制,但是由于页缓存处在内核空间中,不能被用户进程直接寻址,所以读文件时还需要通过系统调用,将页缓存中的数据再次拷贝到用户空间中。
1)常规文件读写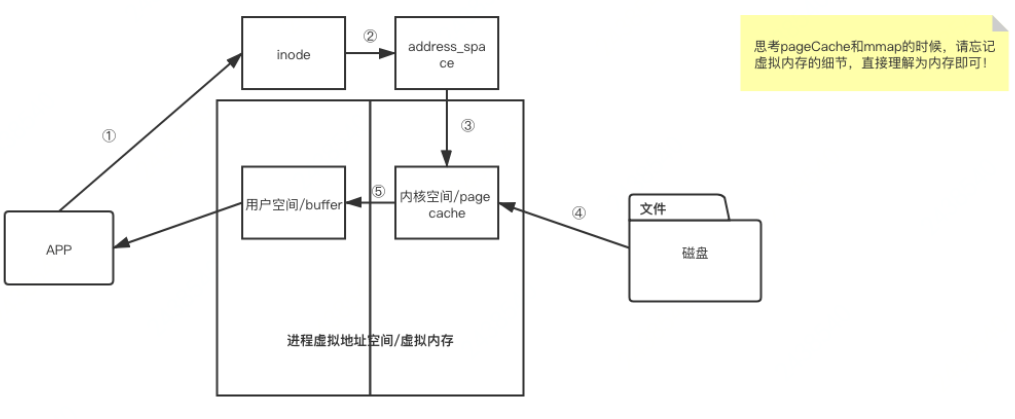
app 拿着 inode 查找读取文件
address_space 中存储了 inode 和该文件对应页面缓存的映射关系
页面缓存缺失,引发缺页异常
通过 inode 找到磁盘地址,将文件信息读取并填充到页面缓存
页面缓存处于内核态,无法直接被 app 读取到,因此要先拷贝到用户空间缓冲区,此处发生内核态和用户态的切换
tips:这一过程实际上发生了四次数据拷贝。首先通过系统调用将文件数据读入到内核态 Buffer(DMA 拷贝),然后应用程序将内存态 Buffer 数据读入到用户态 Buffer(CPU 拷贝),接着用户程序通过 Socket 发送数据时将用户态 Buffer 数据拷贝到内核态 Buffer(CPU 拷贝),最后通过 DMA 拷贝将数据拷贝到 NIC Buffer。同时,还伴随着四次上下文切换。
2)mmap 读写模式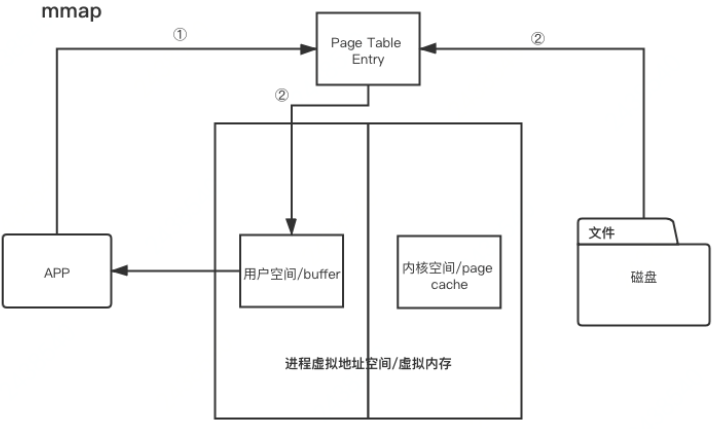
调用内核函数 mmap (),在页表 (类比虚拟内存 PTE) 中建立了文件地址和虚拟地址空间中用户空间的映射关系
读操作引发缺页异常,通过 inode 找到磁盘地址,将文件内容拷贝到用户空间,此处不涉及内核态和用户态的切换
tips:采用 mmap 后,它将磁盘文件与进程虚拟地址做了映射,并不会招致系统调用,以及额外的内存 copy 开销,从而提高了文件读取效率。具体到 Kafka 的源码层面,就是基于 JDK nio 包下的 MappedByteBuffer 的 map 函数,将磁盘文件映射到内存中。只有索引文件的读写才用到了 mmap。
3.2.4 消息存储 - 磁盘顺序写
对于我们常用的机械硬盘,其读取数据分 3 步:
寻道;
寻找扇区;
读取数据;
前两个,即寻找数据位置的过程为机械运动。我们常说硬盘比内存慢,主要原因是这两个过程在拖后腿。不过,硬盘比内存慢是绝对的吗?其实不然,如果我们能通过顺序读写减少寻找数据位置时读写磁头的移动距离,硬盘的速度还是相当可观的。一般来讲,IO 速度层面,内存顺序 IO > 磁盘顺序 IO > 内存随机 IO > 磁盘随机 IO。这里用一张网上的图来对比一下相关 IO 性能:
Kafka 在顺序 IO 上的设计分两方面看:
LogSegment 创建时,一口气申请 LogSegment 最大 size 的磁盘空间,这样一个文件内部尽可能分布在一个连续的磁盘空间内;
.log 文件也好,.index 和.timeindex 也罢,在设计上都是只追加写入,不做更新操作,这样避免了随机 IO 的场景;
3.2.5 Page Cache 的使用
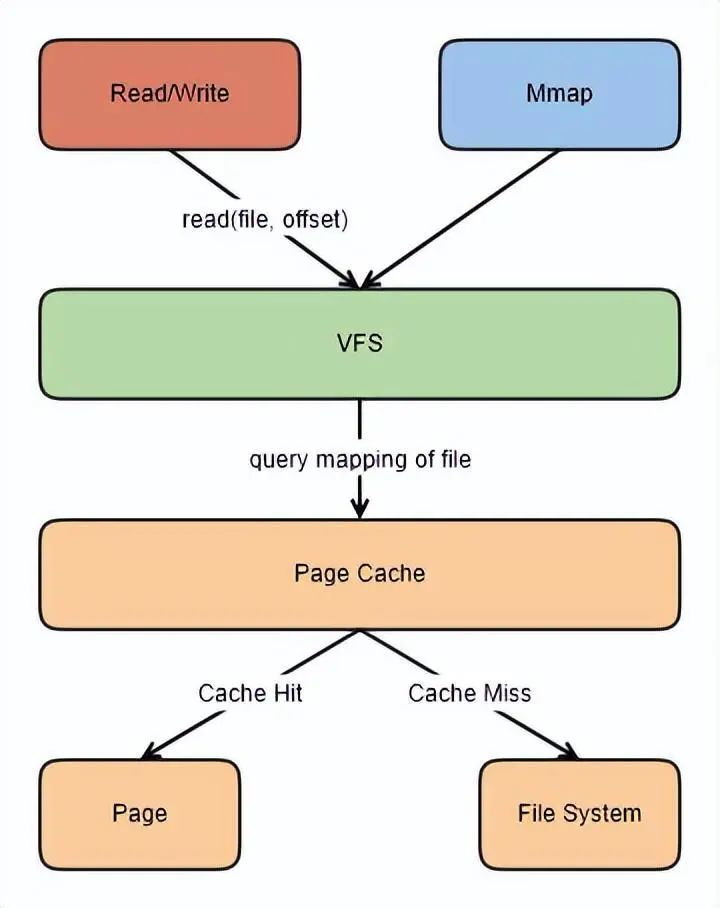
为了优化读写性能,Kafka 利用了操作系统本身的 Page Cache,就是利用操作系统自身的内存而不是 JVM 空间内存。这样做的好处有:
避免 Object 消耗:如果是使用 Java 堆,Java 对象的内存消耗比较大,通常是所存储数据的两倍甚至更多。
避免 GC 问题:随着 JVM 中数据不断增多,垃圾回收将会变得复杂与缓慢,使用系统缓存就不会存在 GC 问题
相比于使用 JVM 或 in-memory cache 等数据结构,利用操作系统的 Page Cache 更加简单可靠。
首先,操作系统层面的缓存利用率会更高,因为存储的都是紧凑的字节结构而不是独立的对象。
其次,操作系统本身也对于 Page Cache 做了大量优化,提供了 write-behind、read-ahead 以及 flush 等多种机制。
再者,即使服务进程重启,JVM 内的 Cache 会失效,Page Cache 依然可用,避免了 in-process cache 重建缓存的过程。
通过操作系统的 Page Cache,Kafka 的读写操作基本上是基于内存的,读写速度得到了极大的提升。
3.3 消费端的高性能设计
3.3.1 批量消费
生产者是批量发送消息,消息者也是批量拉取消息的,每次拉取一个消息 batch,从而大大减少了网络传输的 overhead。在这里 kafka 是通过 fetch.min.bytes 参数来控制每次拉取的数据大小。默认是 1 字节,表示只要 Kafka Broker 端积攒了 1 字节的数据,就可以返回给 Consumer 端,这实在是太小了。我们还是让 Broker 端一次性多返回点数据吧。
并且,在生产者高性能设计目录里面也说过,生产者其实在 Client 端对批量消息进行了压缩,这批消息持久化到 Broker 时,仍然保持的是压缩状态,最终在 Consumer 端再做解压缩操作。
3.3.2 零拷贝 - 磁盘消息文件的读取
1.zero-copy 定义
零拷贝并不是不需要拷贝,而是减少不必要的拷贝次数。通常是说在 IO 读写过程中。
零拷贝字面上的意思包括两个,“零” 和 “拷贝”:
“拷贝”:就是指数据从一个存储区域转移到另一个存储区域。
“零” :表示次数为 0,它表示拷贝数据的次数为 0。
实际上,零拷贝是有广义和狭义之分,目前我们通常听到的零拷贝,包括上面这个定义减少不必要的拷贝次数都是广义上的零拷贝。其实了解到这点就足够了。
我们知道,减少不必要的拷贝次数,就是为了提高效率。那零拷贝之前,是怎样的呢?
2. 传统 IO 的流程
做服务端开发的小伙伴,文件下载功能应该实现过不少了吧。如果你实现的是一个 web 程序 ,前端请求过来,服务端的任务就是:将服务端主机磁盘中的文件从已连接的 socket 发出去。关键实现代码如下:
while((n = read(diskfd, buf, BUF_SIZE)) > 0) write(sockfd, buf , n); 传统的 IO 流程,包括 read 和 write 的过程。
read:把数据从磁盘读取到内核缓冲区,再拷贝到用户缓冲区
write:先把数据写入到 socket 缓冲区,最后写入网卡设备 流程图如下:
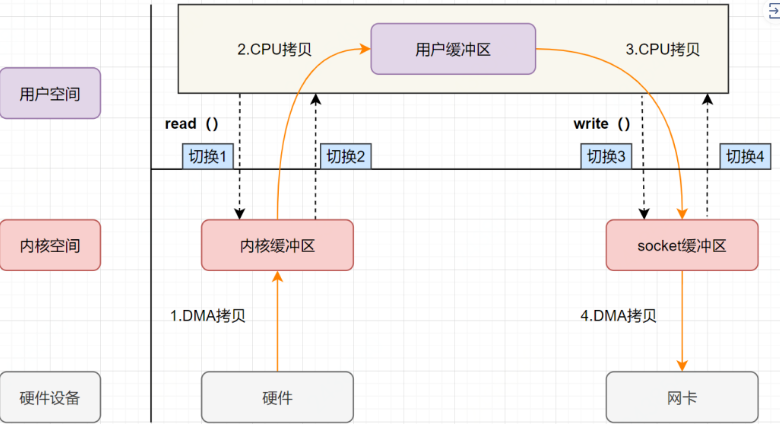
用户应用进程调用 read 函数,向操作系统发起 IO 调用,上下文从用户态转为内核态(切换 1)
DMA 控制器把数据从磁盘中,读取到内核缓冲区。
CPU 把内核缓冲区数据,拷贝到用户应用缓冲区,上下文从内核态转为用户态(切换 2) ,read 函数返回
用户应用进程通过 write 函数,发起 IO 调用,上下文从用户态转为内核态(切换 3)
CPU 将用户缓冲区中的数据,拷贝到 socket 缓冲区
DMA 控制器把数据从 socket 缓冲区,拷贝到网卡设备,上下文从内核态切换回用户态(切换 4) ,write 函数返回
从流程图可以看出,传统 IO 的读写流程 ,包括了 4 次上下文切换(4 次用户态和内核态的切换),4 次数据拷贝(两次 CPU 拷贝以及两次的 DMA 拷贝 ),什么是 DMA 拷贝呢?我们一起来回顾下,零拷贝涉及的操作系统知识点。
3. 零拷贝相关知识点
1)内核空间和用户空间
操作系统为每个进程都分配了内存空间,一部分是用户空间,一部分是内核空间。内核空间是操作系统内核访问的区域,是受保护的内存空间,而用户空间是用户应用程序访问的内存区域。以 32 位操作系统为例,它会为每一个进程都分配了 4G (2 的 32 次方) 的内存空间。
内核空间:主要提供进程调度、内存分配、连接硬件资源等功能
用户空间:提供给各个程序进程的空间,它不具有访问内核空间资源的权限,如果应用程序需要使用到内核空间的资源,则需要通过系统调用来完成。进程从用户空间切换到内核空间,完成相关操作后,再从内核空间切换回用户空间。
2)用户态 & 内核态
如果进程运行于内核空间,被称为进程的内核态
如果进程运行于用户空间,被称为进程的用户态。
3)上下文切换 cpu 上下文
CPU 寄存器,是 CPU 内置的容量小、但速度极快的内存。而程序计数器,则是用来存储 CPU 正在执行的指令位置、或者即将执行的下一条指令位置。它们都是 CPU 在运行任何任务前,必须的依赖环境,因此叫做 CPU 上下文。
cpu 上下文切换
它是指,先把前一个任务的 CPU 上下文(也就是 CPU 寄存器和程序计数器)保存起来,然后加载新任务的上下文到这些寄存器和程序计数器,最后再跳转到程序计数器所指的新位置,运行新任务。
一般我们说的上下文切换 ,就是指内核(操作系统的核心)在 CPU 上对进程或者线程进行切换。进程从用户态到内核态的转变,需要通过系统调用 来完成。系统调用的过程,会发生 CPU 上下文的切换 。 4)DMA 技术
DMA,英文全称是 Direct Memory Access ,即直接内存访问。DMA 本质上是一块主板上独立的芯片,允许外设设备和内存存储器之间直接进行 IO 数据传输,其过程不需要 CPU 的参与 。
我们一起来看下 IO 流程,DMA 帮忙做了什么事情。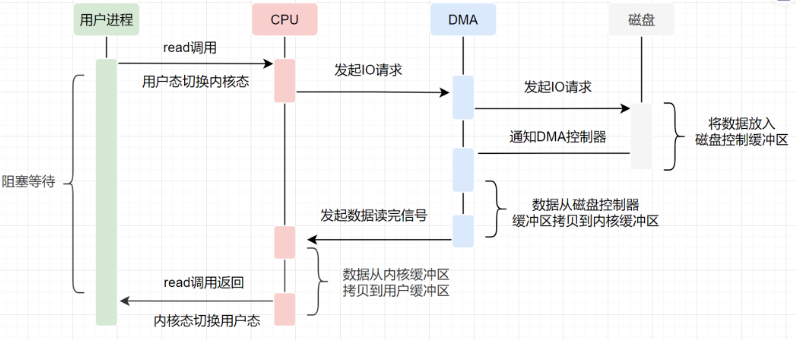
可以发现,DMA 做的事情很清晰啦,它主要就是帮忙 CPU 转发一下 IO 请求,以及拷贝数据 。 之所以需要 DMA,主要就是效率,它帮忙 CPU 做事情,这时候,CPU 就可以闲下来去做别的事情,提高了 CPU 的利用效率。 4.kafka 消费的 zero-copy
1)实现原理
零拷贝并不是没有拷贝数据,而是减少用户态 / 内核态的切换次数以及 CPU 拷贝的次数。零拷贝实现有多种方式,分别是
mmap+write
sendfile
在服务端那里,我们已经知道了 kafka 索引文件使用的 mmap 来进行零拷贝优化的,现在告诉你 kafka 消费者在读取消息的时候使用的是 sendfile 来进行零拷贝优化。
linux 2.4 版本之后,对 sendfile 做了优化升级,引入 SG-DMA 技术,其实就是对 DMA 拷贝加入了 scatter/gather 操作,它可以直接从内核空间缓冲区中将数据读取到网卡。使用这个特点搞零拷贝,即还可以多省去一次 CPU 拷贝 。
sendfile+DMA scatter/gather 实现的零拷贝流程如下: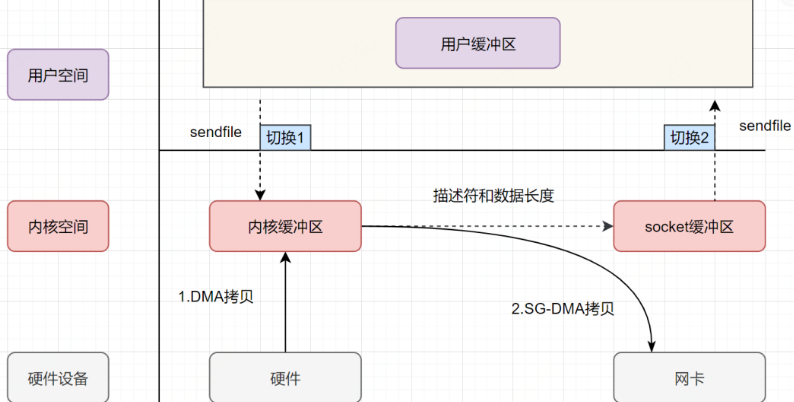
用户进程发起 sendfile 系统调用,上下文(切换 1)从用户态转向内核态。
DMA 控制器,把数据从硬盘中拷贝到内核缓冲区。
CPU 把内核缓冲区中的文件描述符信息 (包括内核缓冲区的内存地址和偏移量)发送到 socket 缓冲区
DMA 控制器根据文件描述符信息,直接把数据从内核缓冲区拷贝到网卡
上下文(切换 2)从内核态切换回用户态 ,sendfile 调用返回。
可以发现,sendfile+DMA scatter/gather 实现的零拷贝,I/O 发生了 2 次用户空间与内核空间的上下文切换,以及 2 次数据拷贝。其中 2 次数据拷贝都是包 DMA 拷贝 。这就是真正的 零拷贝(Zero-copy) 技术,全程都没有通过 CPU 来搬运数据,所有的数据都是通过 DMA 来进行传输的。
2)底层实现 Kafka 数据传输通过 TransportLayer 来完成,其子类 PlaintextTransportLayer 通过 Java NIO 的 FileChannel 的 transferTo 和 transferFrom 方法实现零拷贝。底层就是 sendfile。消费者从 broker 读取数据,就是由此实现。
@Override public long transferFrom(FileChannel fileChannel, long position, long count) throws IOException { return fileChannel.transferTo(position, count, socketChannel); } tips:transferTo 和 transferFrom 并不保证一定能使用零拷贝。实际上是否能使用零拷贝与操作系统相关,如果操作系统提供 sendfile 这样的零拷贝系统调用,则这两个方法会通过这样的系统调用充分利用零拷贝的优势,否则并不能通过这两个方法本身实现零拷贝。
4 总结
文章第一部分为大家讲解了高性能常见的优化手段,从” 秘籍” 和” 道法” 两个方面来诠释高性能设计之路该如何走,并引申出计算和 IO 两个优化方向。 文章第二部分是 kafka 内部高性能的具体设计 —— 分别从生产者、服务端、消费者来进行全方位讲解,包括其设计、使用及相关原理。 希望通过这篇文章,能够使大家不仅学习到相关方法论,也能明白其方法论具体的落地方案,一起学习,一起成长。
审核编辑:刘清
-
基于闪存存储的Apache Kafka性能提升方法2019-07-24 1299
-
从Kafka读取数据操作指南2019-09-16 1327
-
详解Kafka学习2019-10-12 1820
-
基于发布与订阅的消息系统Kafka2020-03-05 1875
-
Kafka基础入门文档2020-03-12 1281
-
Kafka存储数据学习2020-04-03 1104
-
Kafka的四个基础概念学习2020-05-03 3419
-
如何将物联网数据从设备连接到Kafka集群?2020-07-28 1721
-
为什么Kafka会怎么快 Kafka 的应用场景2021-06-04 2937
-
Kafka的概念及Kafka的宕机2021-08-27 3318
-
探究Kafka宕机引发的高可用问题2021-10-20 2306
-
Kafka如何做到那么高的性能2022-09-14 1911
-
Kafka 的简介2023-07-03 1522
-
golang中使用kafka的综合指南2023-11-30 1636
-
Kafka高性能背后的技术原理2024-10-23 1523
全部0条评论

快来发表一下你的评论吧 !
