

视觉Transformer对加速器架构的作用及挑战
人工智能
描述
在快速发展的人工智能世界里,CNN和其相关模型似乎在很久之前就已经把人工智能引擎架构推向了边缘。虽然神经网络算法的性质已经发生了显著的变化,但它们都被认为是在异构平台上有效处理DNN的不同层:NPU用于张量操作,DSP或GPU用于矢量操作,CPU(或集群)管理其余东西。
该架构在视觉处理中工作得很好,其中矢量和标量类操作不会与张量层过多交叉。一个过程从标准化操作(灰度,几何尺寸等)开始,通过向量操作有效地处理。然后是一系列深度层,通过逐层张量操作提取图像特征。最后,使用softmax之类的激活函数对输出进行标准化。算法和异构架构是围绕这种假定的逐层操作设计的,所有的智能部分都在张量引擎中被无缝地处理。
Transformer架构问世
2017年,谷歌研究院/谷歌大脑推出了Transformer架构,以解决自然语言处理(NLP)中的一些问题。CNN及其同类算法通过局部注意力过滤器进行串行处理。一个层中的每个过滤器选择一个局部特征——边缘、纹理或其他信息。叠加滤波器累积自下而上的识别信息,最终识别出全局对象。
在自然语言中,一个句子中一个词的意义并不仅仅由该句子中相邻的词来决定;距离较远的单词可能会对结果产生重要影响。应用多个连续的局部注意力最终可以获得远距离处的信息,但其权重会被削弱。更好的方法是关注全局信息,同时查看句子中的每个单词,距离不作为加权因素,大型语言模型的显著成功证明了这一点。
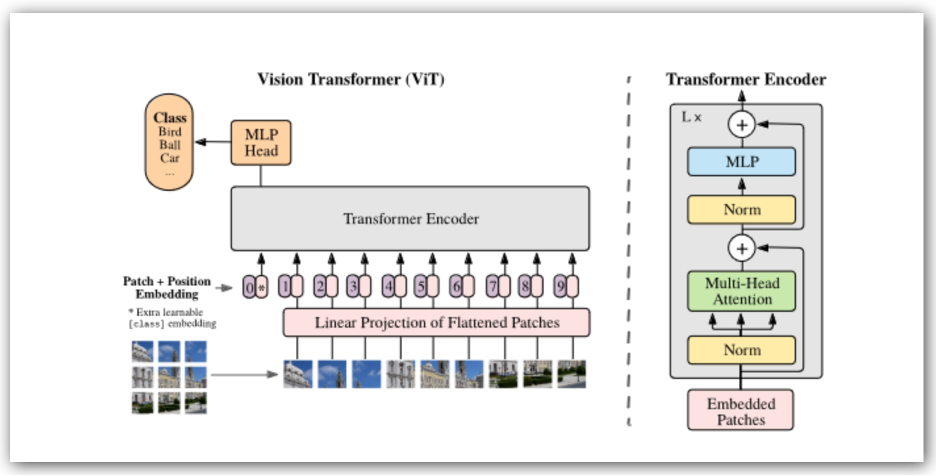
虽然Transformer在GPT和类似应用中最为知名,但它们在视觉Transformer(称为ViT)中也取得了极大进展。图像被分割成小块(比如16×16像素),然后作为字符串通过Transformer进行处理,这样有充分的机会进行并行化。对于每一个序列都是通过一系列连续的张量和向量操作。无论Transformer支持多少个编码器块,都可以重复进行。
与传统神经网络模型的最大区别是,这里的张量和向量操作是交错的。在异构加速器上运行这样的算法是可行的,但在引擎之间频繁的上下文切换可能不是很有效。
优势是什么?
实验结果表明,ViT能够达到与CNN / DNN相当的精度水平,在某些情况下可能具有更好的性能。更有趣的是,Vi可能更倾向于图形中的拓扑信息,而不是自下而上的像素级识别,这可能是它们对图像失真或黑客攻击更强大的原因。此外,ViT还在自监督工作中取得了较好的结果,这可以大大减少训练工作量。
人工智能中的新架构刺激了大量新技术的涌现,这在过去几年的许多ViT论文中就可以看出来。这意味着加速器需要对传统模型和Transformer模型都友好。这对Quadric来说是个好兆头,他们的Chimera通用NPU (GPNPU)处理器被设计成一个单一的处理器解决方案,用于所有AI/ML计算,包括图像预处理、推理等过程,由于所有的计算都在一个具有共享内存层次结构的单一内核中处理,因此不需要在不同类型的ML运算器的计算节点之间进行数据移动。
编辑:黄飞
- 相关推荐
- 热点推荐
- 加速器
- 神经网络
- 人工智能
- 视觉处理
- Transformer
-
基于FPGA的GNN加速器顶层架构2021-08-27 8920
-
#硬声创作季 电子制作:磁性加速器Mr_haohao 2022-10-19
-
从版本控制到全流程支持:揭秘Helix Core如何成为您的创意加速器龙智DevSecOps 2024-11-26
-
关于长整加速器的工作步骤:2018-03-17 3420
-
采用控制律加速器的Piccolo MCU2019-07-26 2574
-
机器学习实战:GNN加速器的FPGA解决方案2020-10-20 1993
-
基于Fast Model的加速器软件开发2022-07-29 3539
-
【书籍评测活动NO.18】 AI加速器架构设计与实现2023-07-28 40690
-
《 AI加速器架构设计与实现》+第2章的阅读概括2023-09-17 4012
-
21489的IIR加速器滤波参数设置如何对应加速器的滤波参数?2023-11-30 19280
-
工具包和Eval板帮助加速加速器应用2017-09-14 1062
-
什么是AI加速器 如何确需要AI加速器2022-02-06 6188
-
Rapanda流加速器-实时流式FPGA加速器解决方案2023-09-13 627
-
粒子加速器的加速原理是啥呢?2023-12-18 5033
-
回旋加速器原理 回旋加速器的影响因素2024-01-30 8851
全部0条评论

快来发表一下你的评论吧 !
