

什么是专用处理器?专用处理器的设计方法和工具介绍
处理器/DSP
描述
什么是专用处理器?
先说一般的处理器概念,wiki定义是“ In computing, a processor is an electronic circuit which performs operations on some external data source, usually memory or some other data stream ”。专用处理器就是针对特定应用或者领域的处理器,类似于是我们经常说的Domain Specific Architecture的概念。
最为通用的处理器当然是CPU(比如intel的桌面CPU,ARM的嵌入式CPU),可以运行任何程序,处理各种数据。但问题是CPU对某些应用效率太低(处理能力不够,无法实时处理,或者是能耗太大)。比如,处理graphic不行,于是出现了GPU;信号处理不行,于是出现了DSP。GPU可以做图像处理,也可以做DNN的training和inference,但是在处理某些DNN应用的时候效率不高,于是有了专用针对这些应用处理器,也就是我最近讨论的AI/ML/DL处理器。所以说,专用处理器也是个相对概念,相对CPU而言,别的类型处理器都可以认为是专用处理器。而我在本文里主要讨论的是相对GPU/DSP而言更为“ 专用 ”的处理器。
专用处理器的覆盖范围也很广,有的能够运行标准的C程序,比如很多ASIP处理器(Application Specific ISA Processor);有的只有很简单的可编程性,比如一些可配置的硬件加速器(Configurable Hardware Accelerators),极端的例子就是“只运行一条fft指令的“FFT硬件加速器。当然具体的硬件设计里可能并没有指令的概念,只有配置的概念。我讨论的重点是至少具有一定可编程能力,可以(并需要)运行程序的专用处理器。
指令集设计
这里先简单说一下指令集的概念。指令集就是一个处理器的硬件可以支持的基本操作(符号化的抽象描述)的集合。(wiki:“ An instruction set, with its instruction set architecture (ISA), is the interface between a computer's software and its hardware, and thereby enables the independent development of these two computing realms; it defines the valid instructions that a machine may execute. ”)。借用Patterson老爷子最近讲演里了一张图,ISA就是传统上软件和硬件的分界线。

通常,处理器的指令集架构(ISA:Instruction Set Architecture)决定了处理器的功能(编程模型)。最著名的x86就是intel CPU的指令集。一个通用处理器,为了适应所有的应用,其指令集必须考虑最大的灵活性。这种灵活性主要表现在指令功能是不是完备和粒度是不是足够细。
举个例子,大家都知道FFT运算是由蝶形运算组成的;而蝶形运算是由复数乘法和加法组成;复数的乘法和加法又是由普通的乘法和加法组成。如果你设计一个可以处理FFT的处理器,可以有几种方法设计指令集。最简单的就是用一个通用指令集,指令集里有最基本的乘法和加法就没问题。FFT的处理分解为这些基本运算,一步一步完成。这样,你的处理器具有最高的灵活性,如果这个处理器不做FFT,还可以做其它的运算。还有一种方法,指令集里只设计一条指令,fft指令,执行这条指令就可以完成所有操作。当然,这样显然没什么灵活性。即使是要做一个“1+1”的操作,你的处理器也干不了。这个例子比较极端,实际设计中一般是折中的处理。但是后者就是我想讨论的专用处理器的一个重要特点,一条指令完成更多的处理。
由于专用处理器这个名称可以用在很多地方,我想再明确一下本文说的专用处理器设计的范围:1. 我们主要讨论IP级的设计,也就是说专用处理器设计最终作为一个SoC(System-on-Chip)芯片中的IP出现。它需要和其它模块合作完成整个芯片要实现的功能(下图为一个简化模型)。2. 我们主要讨论的专用处理器是要运行程序的,有自己的指令集(可能很简单,比如Google第一代TPU,主要指令不超过10条),需要有存储程序的空间和读取指令,执行指令的机制。
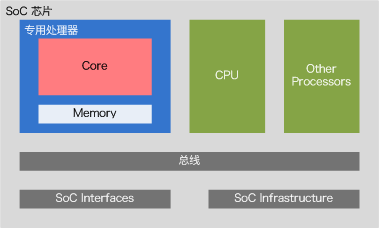
专用处理器虽然强调专用二字,但实际上还是一个处理器。因此,设计一个专用处理器,和设计通用处理器的内容和过程类似。简单来说,这一过程覆盖指令集(ISA),微结构(硬件)和工具链(软件)的设计和实现。下面先讨论一下指令集的问题。
对专用处理器来说,指令集的设计直接反映了对应用需求的理解。比如,第一篇中介绍的例子,如果我们的专用处理器只是为了加速256点的FFT用的,那么指令集里只有FFT指令就够用了。考虑到数据搬移的需求,再加上几条数据搬移的指令,比如读取数据,写回数据。于是可以得到一个有三条指令的指令集(fft,load,store)。这个处理器执行的汇编(Assembly)程序大概就是这样的。

当然,这里做了很多简化,但看起来这个指令集已经可以work了。同时,这也是一个“高效”的设计,没有多余的东西。如果你要循环做8次fft,那么可能需要增加一条loop(循环)指令,要不然你就得把上面的代码copy八次。加了loop指令,汇编代码可能是下面这样。

设计指令集除了确定每条指令的功能和操作数(比如上面的例子里的寄存器的名字,循环次数等等),还有一个重要工作就是设计指令编码。像“load”这样的指令名称只是个抽象的描述,而处理器的硬件看到的实际上是二进制的指令编码。还是上面这个例子,由于我们的指令集有4条指令,则需要2个比特来区分,比如,00:fft;01:load:10;store;11:loop。再具体看load指令,还需要几个bit来说明目标寄存器,假设一共有8个寄存器(R0-R7),区分他们又需要3个bit;另外需要一个bit来说明数据的来源:是一个立即数还是来自内存;如果来源是内存,还需要几个bit表示内存地址,或者指示存放内存地址的寄存器编号,等等。你会发现,可能对于一个load指令,一共需要32个bit的指令编码。上面的汇编程序第三行对应的机器码可能是这样的。
最后,把所有的情况列出来,就形成一个指令和指令编码的列表。这就是一个完整的指令集架构(ISA)了。实际上的ISA当然比这个复杂很多,但不管多复杂,主要也就是这几大类功能:第一是执行运算或处理功能的,比如算数运算;第二类是控制程序流的,比如循环,分支和跳转;第三类实现数据搬移的,比如内存到寄存器,寄存器之间;最后还有一些辅助功能,比如debug,中断,cache之类的指令。这里就不展开讲了,有兴趣的同学可以自己研究一下现在很火的开源指令集RISC-V。个人感觉,仔细看明白一个好的指令集的设计思想,比看教科书收获要多得多。
以上算是指令集的背景知识吧,回到设计专用处理器的问题。当我们有了一个应用需求,怎么来设计和优化一套专用的指令集呢?我想这个问题可能很难有个统一的答案,这里就说说我的个人经验吧。
1. 确定评价标准
我们设计专用处理器都是有明确目的性的,先把目标弄清楚至关重要。评价一般的通用处理器有一些成熟的benchmark。还有一些benchmark更面向专用领域,比如多媒体,DSP,或者针对特殊结构的,比如cache。
那么评价专用处理器的标准是什么呢?很简单,目标应用。 所以,最好在开始设计之前,就把目标应用定量化。如果目标应用已经有程序代码,就可以直接用这些程序代码做benchmark,来评价你的设计。如果还没有完整的应用程序代码,最好也要把关键算法部分写出来。当然,这一条不只是针对指令集,而是针对完整的专用处理器,包括工具链的设计(后续再介绍)。对于专用处理器设计来说,评价标准一般是有限而明确,是正是它能够在一个领域做的比通用处理器效率高的最重要因素。
2. 选择一个参考指令集作为基础
从零开始做专用处理器相当于“重新发明轮子”,存在很大的风险。那么我们能否把问题变成“优化轮子设计”呢(是不是看起来要简单了很多)?在多数情况下都是可以,而且有效的。对于大部分应用来说,其合理的指令集都需要一些基本的指令,比如基本的算术指令和跳转控制指令等,这一部分完全可以参考已有的设计。这样可以大大降低设计的风险。
比如,我们现在有一个应用,在通用处理以外需要大量的FFT操作。一种方法是自己设计一套指令集,即包括通用指令,又包括特殊指令,比如专门的蝶形运算(butterfly)操作。另一种方法是参考一个成熟的指令集,在它的基础上做优化工作,增加butterfly指令,并减少一些不常用的指令。相比第一种方法,这样显然风险要小的多。还有一个好处,我们 可以重用参考处理器的工具链 ,或者只要少量改动,进一步降低的工作量。
结合第1点,一般我们可以先把目标应用的程序在参考的处理器上跑一下,做一些评估,找到瓶颈。针对瓶颈问题设计或改进指令集,以及后面要介绍的微结构和工具链。这也说明在开始的时候就有一个明确的评价标准的好处。
3. 充分利用工具
实际上,不管是指令集还是微结构,设计和优化过程就是一个在优化目标指导下的设计空间探索问题。如果你足够厉害,你当然可以采用“pencil & paper”的方法。但对于我们大部分设计者来说,人肉探索这个设计空间几乎是不可能的。能不能充分利用工具帮忙,往往决定我们是不是能够尽快得出一个比较好的设计。在第2点里,我们先把应用在一个现有的处理器上跑一下,然后根据profiling结果做优化设计,实际就是借助工具帮助我们分析问题。
如果你有足够的资金,还可以借助一些商用的工具。比如,有的DSP IP支持一些扩展和定制的功能和工具,你可以在一个基础设计上针对你的应用设计你自己的专用处理器;还有专门设计ASIP(专用指令处理器)的工具,你甚至可以用一些高层次的语言来描述处理器,工具自动生成工具链和硬件设计(RTL代码),并且评估设计的好坏,帮忙进行优化。当然,这些IP或者工具一般价格昂贵,也有一定的技术门槛。以后有机会在详细介绍吧。
微结构
下面我们来看看上述指令集的硬件实现,微结构(microarchitecture)。wiki对微结构的定义如下:
“In electronics engineering and computer engineering, microarchitecture, also called computer organization and sometimes abbreviated as µarch or uarch, is the way a given instruction set architecture (ISA) is implemented in a particular processor. A given ISA may be implemented with different microarchitectures; implementations may vary due to different goals of a given design or due to shifts in technology.”
如果说指令集是一个处理器的功能规范,那么微结构可以认为是实现ISA的硬件架构。对于不同的优化目标,相同的一个ISA可能用不同的微结构来实现。换句话说,微结构是最终实现性能指标要求的途径。当然,一个优秀合理的ISA的在设计的时候肯定也考虑了微结构实现的问题。在我们设计一个专用处理器的时候,ISA和微结构的设计和优化往往是一个交织进行的过程。先设计一个ISA,然后在做微结构实现的过程中再修改ISA也是很常见的。
微结构的设计和优化又是一个巨大的话题,也涉及很多知识。我还是先通过FFT专用处理器的例子来说明一下基本概念。为了实现上一部分设计的ISA,我们可以设计这样一个处理器微结构。

如果读者您一看就明白了这个图的意思,请跳过下面这段简要说明,直接看微结构优化的讨论。
首先,我们要执行的关键指令是fft指令,这里假设fft指令就是做一次蝶形运算(buffterfly)。所以我们要有一个做蝶形运算的硬件单元(图中的4)。而这个功能单元FU(Functional Unit)需要输入和输出数据。数据了来源可能是通用寄存器堆RF(Register File,图中的3),也可能是memory或者流水线寄存器。同样,数据的输出也有很多可能。因此,需要一些MUX来进行选择。简单说,图中的3和4就构成了处理器中的数据通道(datapath),也就是处理数据的通路。另外,为了把数据从数据存储器(data memory)中读进来进行处理(load),或者将处理的结果再写回到存储器,还需要一个“load store单元”(图中的5)。
但是,数据通道要正确运行,需要很多控制信息。比如,在寄存器堆中倒底哪个存放的是输入数据;哪个应该存放运算结果?FU的数据来源倒底来自RF还是memory;结果要写回哪里?等等。而这些信息实际上就包含在程序指令里。我们假想汇编程序,每行指令都包含对datapath的控制信息。因此,在一个处理器里还需要有一条控制通路(control path),根据程序指令实现对datapath的设置和控制。
我们先要把指令从程序存储器(PM:program memory)读进来。这需要一个取指令的功能模块(fetch);取指模块的功能是向PM发出地址,执行“读”操作。这个地址是根据一个特殊的寄存器:程序计数器(PC:program counter)产生的。PC也可以看作是指向程序存储空间的一个指针,它实际控制着程序执行的流程。如果程序按正常顺序执行,则PC = PC + 1。如果需要改变程序流,比如跳转,则需要改变PC的值,指向要跳转的新地址,PC = PC + offset。这样取指模块读出的就是跳转目标位置的指令。
上篇文章已经介绍了,指令经过编码以后形成一个二进制的机器码。取指模块读进来的正是这个机器码。要确定这条指令要执行的具体操作,就需要进行译码(decode)。比如,在咱们的例子中,根据机器码的头两个bit就可以判断倒底是那一条指令。
分辨出具体是什么指令,就可以执行该指令的操作了。通常这个过程称为指令发射(issue)或者执行(execution)。其结果包括,对数据通路的控制,比如“fft”指令;对PC的修改,比如指令“loop”和对访的控制“load和store”指令,等等。
到此为止,我们已经有了一个workable的硬件架构了,在这个硬件上可以运行前面说的汇编程序并且输出结果。但实际上,这是一个“极简”微结构,忽略了很多重要内容。为了后面讨论的方便,下面介绍几个和微结构相关的名词。
指令周期(Instruction cycle):
一条指令一般会经历“取指”,“译码”,“发射/执行”和“写回”这些操作。处理器执行程序的过程就是不断重复这几个操作。
指令流水线(Instruction pipeline):
当一条指令,完成了“取指”操作,开始进行“译码”的时候,取指模块就可以取下一条指令了,这样可以让这些模块不至于闲着没用。wiki对指令流水线的示例如下(IF:取指;ID:指令译码;EX:执行;MEM:访存;WB:写回):

指令并行(Instruction-level parallelism):
同时执行多条指令。比如,一边从memory读数据,一边进行fft处理。我们经常听到的超标量(Superscalar),超长指令字(VLIW),乱序执行( Out-of-order execution)等等技术都是发掘指令级并行的技术。
数据并行(Data parallelism):
同时处理多个数据。我们常听到的向量处理器(vector procesor),张量处理器(Tensor processor)多数都是利用了SIMD(一条指令可以处理多个数据,比如一个向量乘法)技术。
存储层次(memory hierarchy):
处理器相关的存储实际是由多种类型的存储器组成。一般访问速度越快(离datapath的“距离”越近),成本越高;相应的容量也越小。按从快到慢的顺序,包括芯片内的存储器:寄存器(Register),TCM(Tightly Coupled Memory),L1 cache,L2 cache和芯片外的存储器,DDR,硬盘等等。
实际上,对处理器微结构的研究到今天为止已经非常非常成熟,想有很大的创新几乎不太可能了。做一个专用处理器无非是怎么针对应用的特点,利用好这些经验的问题。当然,这也是一种创新。下面谈一些做专用处理器的个人感受吧。
1. 通用处理器的背景知识
既然专用处理器只是一种特殊的处理器,那么处理器的一般性知识还是非常重要的。如果你对处理器设计的常用技术和技巧都非常熟悉,那么你设计专用处理器肯定也是游刃有余。比如指令级并行和数据并行是微结构设计的两个重要方向,你是否能准确的了解每一种并行技术的优势,劣势和代价呢?最好你能够在脑子里就有一个对比的表格,随时可以拿出来和目标应用放在一起做评估。另外,还是要跟踪这个领域的最新进展,也许能给你带来很大的启发。
2. 突破通用处理器的思维
虽然做专用处理器要以处理器的一般知识为基础。但也要敢于做出突破。实际上,我们看到的处理器设计经典知识往往针对通用处理器。毕竟它的应用范围广,讨论的也比较多。而面向某个领域的专用处理器通常都是by design的优化,可能就只有你自己或者很少的人做,讨论的也比较少。这种时候就要相信自己对应用的理解,敢于做出一些“奇怪”的设计。当然,前提是我们有严谨的定量分析做支撑。这一点我会在后续介绍方法学和工具链的文章里进一步说明。
3. 发掘历史的宝藏
从最近两年AI硬件热潮中我们发现,很多在历史上昙花一现的架构重新获得了成功,或者至少获得了新的关注,Google TPU中使用的脉动阵列架构就是最好的例子。在历史上有过体系结构百花齐放的年代,当时很多有趣的设计只是由于生不逢时而被遗忘了。对于专用处理器来说,重点是高效解决特定问题,因此历史上很多当时看起来”非主流“的设计可能反而是最合适的。所以我们不妨经常做做“考古”工作,能发现金矿也说不定。
设计方法和工具
前面我们分别讨论了专用处理器的指令集和微结构的问题。其实,在指令集和微结构方面,专用处理器用的技术基本上都是在通用处理器发展过程中探索过的东西。要说专用处理器设计最为特殊的地方,我个人认为应该是设计方法(方法学)和工具。专用处理器设计成功与否完全由目标应用来检验,而应用的多样性也决定了专用处理器的多样性。这种多样性不仅反映在软硬件设计本身,也反映在设计方法和工具上。

上面这副图展示的domain-specific computing的概念既包括了专用处理器(图中的ASP,Application Specific Processor)设计和也包括了相应的工具开发。下面我们就结合这副图,把DNN作为一个domain,讨论一下专用处理器的设计方法和各种工具。
Domain Modeling
首先是对特定领域(domain,比我们说的目标应用的概念要更广泛一下)进行建模,把需求模型化和量化,作为后续工作的评价标准。建模可能会使用特殊的语言扩展或者数据流图的形式,比如在DNN领域经常使用的Tensorflow就是典型的例子。
Domain Model是后续开发的基础,据此可以得到两个重要的中间描述:一个是用于硬件架构设计的Domain Characteristics;另一个是用于生成C/C++应用代码(当然也可能是其它语言)的Application Model。这里的具体名称并不太重要,重要的是一个domain model需要经过处理,分离出指导硬件设计和生成应用软件代码的两部分信息。
HW Architecture design和Architecture Model
硬件架构设计的主要工作是设计专用的计算引擎(Customized Computing Engine)和互连机制(Customized Interconnection)。比如在CNN加速器中比较常见的由PE(Processing Engine)组成的2D mesh网络,PE就是专用的计算引擎,2D网络就是适应CNN 2D卷积特征的互连机制。
硬件架构设计还要输出一个架构模型。而这个硬件架构模型也是整个设计方法中重要的一环。一方面,这个架构模型可以生成虚拟原型系统(Virtual Prototyping);另一方面,它也是程序代码映射工具(Source-to-source mapper)的输入,而代码映射功能用于将一些特殊的模型转换为C/C++这类传统的编程语言(这类语言有很好的工具进行处理),同时输出Analysis Annotations,用于指导硬件设计和软件工具链的前端设计。
虚拟原型(Virtual Prototyping)
我们通常说的Prototyping一般指基于FPGA或者测试芯片(testchip)系统原型,即用于验证硬件设计,又可以debug固件,操作系统和应用程序。但是开发硬件原型系统本身也是一项费时的工作,并且要等等所有硬件设计完成了才能实现。虚拟原型则是个纯软件的仿真器。最常见的方式是使用SystemC这样语言(抽象层次更高)来对硬件进行建模,而不是直接使用RTL级的硬件模型。建模的抽象层次提高虽然会损失一些细节,但好处是开发便捷(C++编程),仿真速度快。和硬件的原型系统相比,虚拟原型可以在项目开始阶段就开发完成,提供给软件开发人员,而不需要等到硬件准备好。最后,虚拟原型是纯软件仿真,很容易debug,也很容易部署。虚拟原型是个有趣的话题,以后有机会可以专门讲一下。
计算引擎硬件实现
这里把计算引擎分为三种:专用处理器(ASP),硬件加速器(HW Accelerators)和可编程阵列(Programing fabric)。前两种我们都介绍过,第三种的硬件结果类似于FPGA,差别是这里的逻辑电路阵列也是根据应用定制的。实现这三类计算引擎可以靠工程师完成,也可以借助专门的工具,比如,High-level Synthesizer(高层次综合工具,也有叫行为级综合的)可以把C,systemC甚至Matlab代码(当然有一定的约束)自动综合成硬件设计(RTL代码)。也有一些工具可以根据特殊的处理器描述语言,如Synopsys的LISA,NML和RISC-V处理器用的Bluespec等,自动生成RTL代码。
这里插一句,自动生成RTL代码看起来高大上,实际也没那么难。记得10年前在SiliconHive(也是一个做专用处理器和工具的公司,后来被Intel收购了)实习做NoC的时候,RTL代码就是从XML描述里自动生成的。其实就是大家平时形成的好习惯:RTL代码尽量用脚本生成,积累起来也就成了自己的自动化工具。
这之后的工作主要就是将计算引擎和互连机制集成在一起,并且实现硬件的原型系统。互连机制的设计也有很多内容,这里就暂不深入了。
软件开发工具链
图的右半部分就是软件开发的工具链,这个和我们传统上说的工具链基本是类似的,即从C/C++的源代码,经过一系列的工具,生成运行在最终硬件上的机器代码(可以有很多形式)。工具链主要包括,前端(front end)后端(back end)和runtime。这里和通用CPU的工具链的主要差别在于back end和runtime,因为这两部分和硬件架构(指令集和微结构)关系密切。对应专用处理器的硬件,主要体现在customized和adaptive这种特征。不过这里还有一些辅助性的工具,比较典型的比如debuger,就不细说了。
小结一下:
1.专用处理器虽然特殊,但设计方法和工具是有普遍性的,这也是研究方法学的价值所在。2. 设计方法往大说是方法学,但在实际的工程中体现为任务,流程和工具,设计专用处理器的过程也是优化方法学的过程。3. 专用处理器设计面向应用,往往有比较高的Time to Market要求,因此从架构探索到RTL生成到原型验证,都要尽量利用自动化工具提高设计的效率,自己设计小工具并且不断积累是很好的实践;4. 采用专用处理器的系统往往是软硬件紧密协同的系统,设计方法上最重要的理念是软硬件的联合优化:在设计硬件的时候充分利用对应用软件的分析;而在设计软件工具链的时候也要充分结合硬件架构的特点;Architecture Model和Analysis Annotations就是软硬件设计和工具间的桥梁。
“自己动手”设计专用处理器
最后实战一下专用处理器的设计项目吧。我们先从结果说起,也就是这项任务的最终交付物。这里不妨参考ARM处理器核的deliverables。当然,如果只是一个自己用的专用处理器,不一定要有这么完整的交付物。
硬件 :主要是处理器相关的RTL代码,验证环境,EDA工具的脚本,文档等等。
工具软件 :主要包括编译工具(compiler),调试工具(debugger),仿真工具(simulator)和性能分析工具(profiler)。下图是ARM的编译工具的例子,主要包括armclang(C编译器),armasm(汇编器),armlink(链接器)和fromelf(image工具)。

source: arm.com
仿真工具一般至少包括一个指令仿真器 instruction set simulator (ISS)。
模型 :此外,现在一般的处理器IP还会提供一些处理器的模型来支持系统级设计,比如用于前面介绍的虚拟原型的处理器模型(类似于ARM的Fast Model)。专用的处理器模型是虚拟平台的重要组成部分,和总线模型以及其它IP模型一起模拟系统的功能。
看到这一大堆工作,如果你没有胆怯,而是觉得很有意思。那么我也很愿意给你点帮助,看看是不是可以把你的想法变成现实。其实方法也很简单 -- 自己做不了就“找别人帮忙呗”。具体来说,根据你的预算情况,可以分为“ 穷 ”和“ 富 ”两种玩法。
我先说说有钱的玩法吧。其实,不止你一个人想做专用处理器,很多大公司也有这样的需求。所以,就有人为这种需求专门提供了解决方案,比如Synopsys的ASIP-designer工具就是为了满足定制处理器的需求而设计的。ASIP designer支持从零开始设计和实现一个专用处理器。你可以非常自由的设计指令集和微结构,覆盖从Extensible processor,到Application-specific uP/DSP,到Programmable datapath这样一个更大的架构空间,如下图所示。这里也可以看出,这个工具的目标并不是设计通用处理器。

source:synopsys.com
下图是该工具完整的方法学。

source: synopsys.com
它的输入就是两个,算法(C/C++代码)和处理器模型(Processor Model),输出则是一个处理器相关的所有设计和工具链。从输入到输出的过程同样是自动化完成的。当然,这个过程并不像看起来那么简单,处理器建模的门槛不低。而且,工具赋予你的灵活性越高,掌握这种工具的门槛也越高。ASIP designer的处理器建模需要使用一种专门的语言,即nML,对处理器的指令集和架构进行高层次建模;此外还需要很多和编译器相关的设计。所以,即使你能买得起,要玩好这套工具,还得具备两个条件:第一,是你必须熟悉处理器架构和编译方面知识;第二,是要学习这套建模语言和工具。
总的来说,如果你有专用处理器设计的需求,足够的资金和学习的耐心,可以考虑引入这类辅助设计工具。在经历过一定的学习周期后,你不仅可以完成一个设计,还能获得快速、高效设计处理器的能力。
下面再看看“ 穷玩法 ”。如果你没有足够的资金来购买上述工具,或者是你的目标收益还不值得做出这样的投资。这种情况下,我建议你从开源免费的处理器(或者指令集)开始做你自己的专用处理器。其实这也算是废话吧。
假设你想在RSIC-V的基础上做定制处理器吧。RSIC-V是现在一个相对成熟的开源处理器指令集,也有开源的处理器实现和非常活跃的社区。相信大家都听说过,就不科普了。这里得说明一下,我并没有对RISC-V进行过深入的研究和尝试,以下的说法基本上是纸上谈兵,不对的地方请大家批评指正。
首先,你要好好学习一下RISC-V指令集手册中的“Chapter 10 Extending RISC-V”,这里明确介绍了给RISC-V指令集扩展指令的规则。包括标准的扩展和非标准扩展两个方面。
第二,在现有的RISC-V的硬件实现基础上,增加新指令对应的硬件。可能需要增加专用的寄存器,运算单元,pipeline寄存器,控制信号等等。或者,你可以按照新的指令集(假设叫“RISC-V++ ISA”)自己做完整的硬件实现。其实我觉得第二种方法还更靠谱一点。很多时候,修改别人的东西,要比自己做困难的多。
第三,在RISC-V原有的工具链(比如GNU或者LLVM的编译器)基础上做出修改,支持新的指令。相对来说,这项工作是有比较完善的规则的,只要按照编译工具的规则就可以把新增的指令加进去。当然,如果你增加的指令比较特殊,比如是向量操作,那么工具链的设计会困难很多。这种情况下的一个选择是在高级程序语言的编译器中不增加对新指令的支持,这些新的指令以汇编或者intrinsic的方法实现。
最后,这套方法是不是也能支持在前面提到的快速design space exploration呢?基本的思路也是差不多的。你可以先用基本指令集来仿真你的算法;根据profiling的结果(比如性能指标,指令效率,code size等)考虑对指令集进行的修改;然后更新相应的微架构设计,硬件实现和工具链,再编译和测试你的算法,并不断迭代。如果这个过程没有自动化工具的帮忙,可能需要比较长的时间才能完成,特别是需要对功耗面积进行详细优化的情况。
这种方法看起来行的通,不过中间的坑可能非常多,要求你对基础处理器(比如RISC-V)非常熟悉。适合那些已经完整的做过RISC-V实现的玩家尝试。否则,也许有的坑你根本过不去。
设计专用处理器常见的”坑“
做专用处理器是个复杂工程,坑很多,以下仅举几例。
我们并不真的了解目标应用
在我们做一个面向特定应用的专用处理器的时候,也许没有想象中那么了解这个应用。我倾向于用这样问题来判断:“1.你是否已经有了全部目标应用或者算法的软件(程序)?2. 你是否有定量的约束条件?”。如果有,那么你就可以保证对你的设计进行客观和定量的评价(验证)。如果在对设计进行评估的时候,能够覆盖目标应用的软件程序还不到80%,或者具体的约束条件还不明确,那么就有很大风险。一种可能是,你为不确定性做出一些over design;另一种可能是你的优化目标和实际情况并不相符。不管是那一种情况,实际上都没有能够很好的发挥专用处理器的优势。
不知道什么不应该做
如果我们不具备自己做专用处理器的能力,往往觉得它很神秘,会夸大设计的难度和风险。而当我们具备了这种能力,一个可能的倾向是夸大专用处理器的优势,什么地方都想用专用处理器来搞定。实际上,掌握了设计专用处理器的能力,相当于一个团队有了一件强有力的武器。至于是否使用和怎样使用则是一种更强的能力。一个好的SoC架构,往往是各种类型的处理器和硬件加速器配合工作的。能够得到这样的架构,或者是通过了多次迭代和优化,或者是以定量分析和仿真为基础(再次强调这一点)。
忽视工具链的开发
设计一个专用处理器,要经历需求分析,架构设计,硬件实现和工具链开发等多项工作。一个比较常见的问题是忽视工具链的开发。但正如我在对方法和工具的讨论中指出的,工具链(包括处理器开发工具和应用开发工具)对于专用处理器开发和使用是至关重要的。即使你的架构设计和硬件实现做的再好,如果没有一个完善的工具链,这些硬件就没法发挥最大的效能。从另一个角度来说,如果没有好的开发工具,架构设计和硬件实现也很难做好。个人认为,比较好的实践是在项目开始的时候就能够对工具链设计做出规划并配置专职的人员。
-
恩智浦首次推出带有专用神经处理引擎的i.MX应用处理器,支持边缘计算2020-01-08 1801
-
一款高质量多速率语音专用处理器芯片的设计2009-10-06 2777
-
专用处理器,未来电机驱动的主流2015-12-31 5347
-
采用专用处理器实现电机驱动方案2019-07-26 3070
-
DSP处理器与通用处理器的比较2021-09-03 2096
-
专用处理器技术在嵌入式系统中应用间题研究2009-05-09 514
-
多媒体应用处理器的原理和应用2009-12-01 703
-
应用处理器专用电源2008-11-26 603
-
流水线操作,应用处理器,应用处理器的结构和原理是什么?2010-03-26 1457
-
寒武纪科技将发布深度学习专用处理器2017-10-11 1382
-
可编程语音压缩专用处理器设计2018-10-31 685
-
CEVA的智能传感技术适用于边缘AI计算的专用处理器2020-07-23 1272
-
应用处理器芯片行业科普2022-01-25 949
-
阿里云正式发布云数据中心专用处理器CIPU2022-06-13 2386
-
芯易荟发布首款领域专用处理器生成工具FARMStudio2023-04-12 1563
全部0条评论

快来发表一下你的评论吧 !
