

超强Trick,一个比Transformer更强的CNN Backbone
描述
导读继卷积神经网络之后,Transformer又推进了图像识别的发展,成为视觉领域的又一主导。最近有人提出Transformer的这种优越性应归功于Self-Attention的架构本身,本文带着质疑的态度对Transformer进行了仔细研究,提出了3种高效的架构设计,将这些组件结合在一起构建一种纯粹的CNN架构,其鲁棒性甚至比Transformer更优越。

视觉Transformer最近的成功动摇了卷积神经网络(CNNs)在图像识别领域十年来的长期主导地位。具体而言,就out-of-distribution样本的鲁棒性而言,最近的研究发现,无论不同的训练设置如何,Transformer本质上都比神经网络更鲁棒。此外,人们认为Transformer的这种优越性在很大程度上应该归功于它们类似Self-Attention的架构本身。在本文中,作者通过仔细研究Transformer的设计来质疑这种信念。作者的发现导致了3种高效的架构设计,以提高鲁棒性,但足够简单,可以在几行代码中实现,即:将这些组件结合在一起,作者能够构建纯粹的CNN架构,而无需任何像Transformer一样鲁棒甚至比Transformer更鲁棒的类似注意力的操作。作者希望这项工作能够帮助社区更好地理解鲁棒神经架构的设计。代码:https://github.com/UCSC-VLAA/RobustCNN
对输入图像进行拼接
扩大kernel-size
减少激活层和规范化层
1、简介
深度学习在计算机视觉中的成功很大程度上是由卷积神经网络(CNNs)推动的。从AlexNet这一里程碑式的工作开始,CNNs不断地向计算机视觉的前沿迈进。有趣的是,最近出现的视觉Transformer(ViT)挑战了神经网络的领先地位。ViT通过将纯粹的基于Self-Attention的架构应用于图像Patch序列,提供了一个完全不同的路线图。与CNN相比,ViT能够在广泛的视觉基准上获得有竞争力的性能。最近关于out-of-distribution鲁棒性的研究进一步加剧了神经网络和Transformer之间的争论。与两种模型紧密匹配的标准视觉基准不同,Transformer在开箱测试时比神经网络更强大。此外,Bai等人认为,这种强大的out-of-distribution鲁棒性并没有从中提供的高级训练配置中受益,而是与Transformer的类似Self-Attention的架构内在地联系在一起。例如,简单地将纯CNN“升级”为混合架构(即同时具有CNN块和Transformer块)可以有效地提高out-of-distribution鲁棒性。尽管人们普遍认为架构差异是导致Transformer和CNNs之间鲁棒性差距的关键因素,但现有的工作并没有回答Transformer中的哪些架构元素应该归因于这种更强的鲁棒性。最相关的分析都指出,Self-Attention操作是中枢单元的Transformer块对鲁棒性至关重要。尽管如此,给定-
Transformer块本身已经是一个复合设计
-
Transformer还包含许多其他层(例如,Patch嵌入层),鲁棒性和Transformer的架构元素之间的关系仍然令人困惑。
-
首先,将图像拼接成不重叠的Patch可以显著地提高out-of-distribution鲁棒性;更有趣的是,关于Patch大小的选择,作者发现越大越好;
-
其次,尽管应用小卷积核是一种流行的设计方法,但作者观察到,采用更大的卷积核(例如,从3×3到7×7,甚至到11×11)对于确保out-of-distribution样本的模型鲁棒性是必要的;
-
最后,受最近工作的启发,作者注意到减少规范化层和激活函数的数量有利于out-of-distribution鲁棒性;同时,由于使用的规范化层较少,训练速度可能会加快23%。
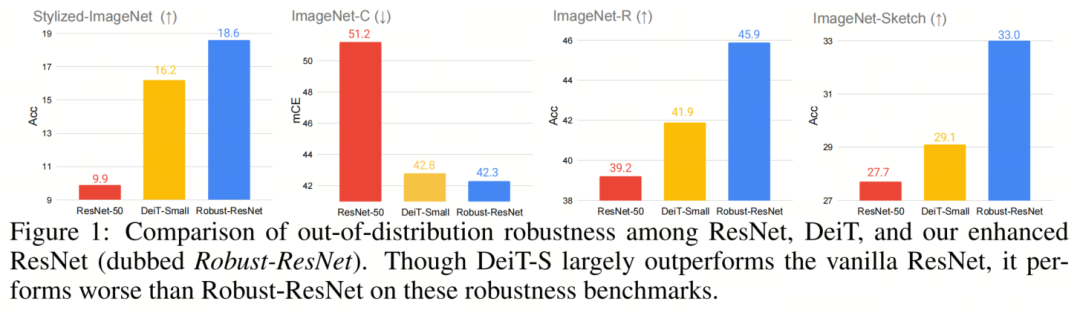 作者的实验验证了所有这3个体系结构元素在一组CNN体系结构上一致有效地提高了out-of-distribution鲁棒性。据报道,最大的改进是将所有这些集成到CNNs的架构设计中,如图1所示,在不应用任何类似Self-Attention的组件的情况下,作者的增强型ResNet(称为Robust-ResNet)能够在Stylized-ImageNet上比类似规模的Transformer DeiT-S高2.4%(16.2%对18.6%),在ImageNet-C上高0.5%(42.8%对42.3%),ImageNet-R上为4.0%(41.9%对45.9%),ImageNet Sketch上为3.9%(29.1%对33.0%)。作者希望这项工作能帮助社区更好地理解设计鲁棒神经架构的基本原理。
作者的实验验证了所有这3个体系结构元素在一组CNN体系结构上一致有效地提高了out-of-distribution鲁棒性。据报道,最大的改进是将所有这些集成到CNNs的架构设计中,如图1所示,在不应用任何类似Self-Attention的组件的情况下,作者的增强型ResNet(称为Robust-ResNet)能够在Stylized-ImageNet上比类似规模的Transformer DeiT-S高2.4%(16.2%对18.6%),在ImageNet-C上高0.5%(42.8%对42.3%),ImageNet-R上为4.0%(41.9%对45.9%),ImageNet Sketch上为3.9%(29.1%对33.0%)。作者希望这项工作能帮助社区更好地理解设计鲁棒神经架构的基本原理。2、SETTINGS
在本文中,使用ResNet和ViT对CNN和Transformer之间的鲁棒性进行了彻底的比较。2.1、CNN Block Instantiations
如图2所示,本文作者考虑4种不同的块实例化。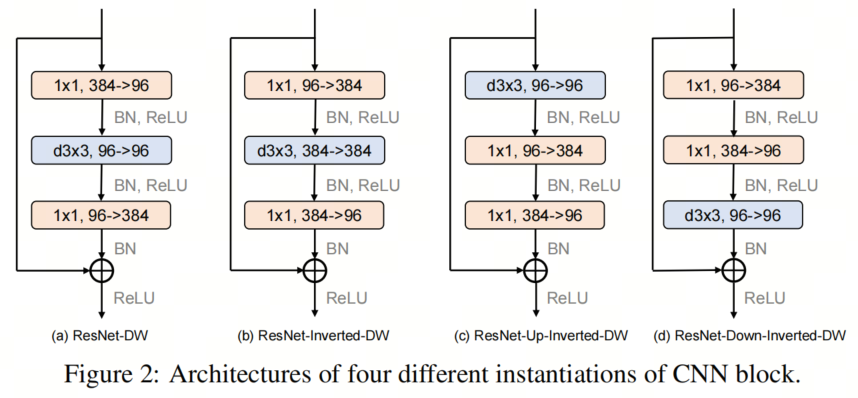
-
第1个Block是Depth-wise ResNet Bottleneck block,其中3×3卷积层被3×3深度卷积层取代;
-
第2个Block是Inverted Depth-wise ResNet Bottleneck block,其中隐藏维度是输入维度的4倍;
-
第3个Block基于第2个Block,深度卷积层在ConvNeXT中的位置向上移动;
-
基于第2个Block,第4 Block向下移动深度卷积层的位置。
2.2、Computational Cost
在这项工作中,作者使用FLOP来测量模型大小。在这里,作者注意到,由于使用了深度卷积,用上述4个实例化块直接替换ResNet Bottleneck 块将显著减少模型的总FLOP。为了减少计算成本损失并提高模型性能,遵循ResNeXT的精神,作者将每个阶段的通道设置从(64,128,256,512)更改为(96,192,384,768)。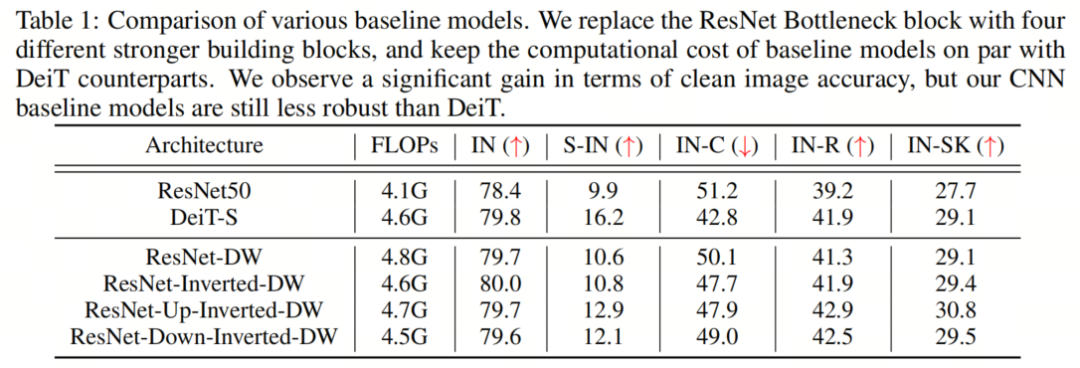 然后,作者在第3阶段调整块数,以保持 Baseline 模型的总FLOP与DeiT-S大致相同。作者的 Baseline模型的最终FLOP如表1所示。除非另有说明,否则本工作中考虑的所有模型都与DEITS具有相似的规模。
然后,作者在第3阶段调整块数,以保持 Baseline 模型的总FLOP与DeiT-S大致相同。作者的 Baseline模型的最终FLOP如表1所示。除非另有说明,否则本工作中考虑的所有模型都与DEITS具有相似的规模。2.3、Robustness Benchmarks
在这项工作中,作者使用以下基准广泛评估了模型在out-of-distribution鲁棒性方面的性能:-
Stylized-ImageNet,它包含具有形状-纹理冲突线索的合成图像;
-
ImageNet-C,具有各种常见的图像损坏;
-
ImageNet-R,它包含具有不同纹理和局部图像统计的ImageNet对象类的自然呈现;
-
ImageNet Sketch,其中包括在线收集的相同ImageNet类的草图图像。
2.4、Training Recipe
神经网络可以通过简单地调整训练配置来实现更好的鲁棒性。因此,在这项工作中,除非另有说明,否则作者将标准的300-epoch DeiT训练配置应用于所有模型,因此模型之间的性能差异只能归因于架构差异。2.5、Baseline Results
为了简单起见,作者使用“IN”、“S-IN”、”INC“、”IN-R“和”IN-SK“作为“ImageNet”、“Styleized ImageNet”,“ImageNet-C”、“ImageNet-R”和“ImageNet Sketch”的缩写。结果如表1所示,DeiT-S表现出比ResNet50更强的鲁棒性泛化。此外,作者注意到,即使配备了更强的深度卷积层,ResNet架构也只能在clean图像上实现相当的精度,同时保持明显不如DeiT架构的鲁棒性。这一发现表明,视觉Transformer令人印象深刻的鲁棒性的关键在于其架构设计。3、COMPONENT DIAGNOSIS
3.1、PATCHIFY STEM
CNN或Transformer通常在网络开始时对输入图像进行下采样,以获得适当的特征图大小。标准的ResNet架构通过使用Stride为2的7×7卷积层,然后使用Stride为2中的3×3最大池化来实现这一点,从而降低了4倍的分辨率。另一方面,ViT采用了一种更积极的下采样策略,将输入图像划分为p×p个不重叠的Patch,并用线性层投影每个Patch。在实践中,这是通过具有 kernel-size p和Stride p的卷积层来实现的,其中p通常设置为16。这里,ViT中的典型ResNet Block或Self-Attention块之前的层被称为Backbone。虽然之前的工作已经研究了神经网络和Transformer中Stem设置的重要性,但没有人从鲁棒性的角度来研究这个模块。为了进一步研究这一点,作者将 Baseline 模型中的ResNet-style stem替换为 ViT-style patchify stem。具体来说,作者使用 kernel-size 为p和Stride为p的卷积层,其中p从4到16不等。作者保持模型的总Stride固定,因此224×224的输入图像将始终在最终全局池化层之前产生7×7的特征图。特别地,原始ResNet在阶段2、3和4中为第1个块设置Stride=2。当使用8×8 patchify Stem时,作者在第2阶段为第1个块设置Stride=1,当使用16×16 patchify stem时,在第2和第3阶段为第1块设置Stride=1。为了确保公平的比较,作者在第3阶段添加了额外的块,以保持与以前类似的FLOP。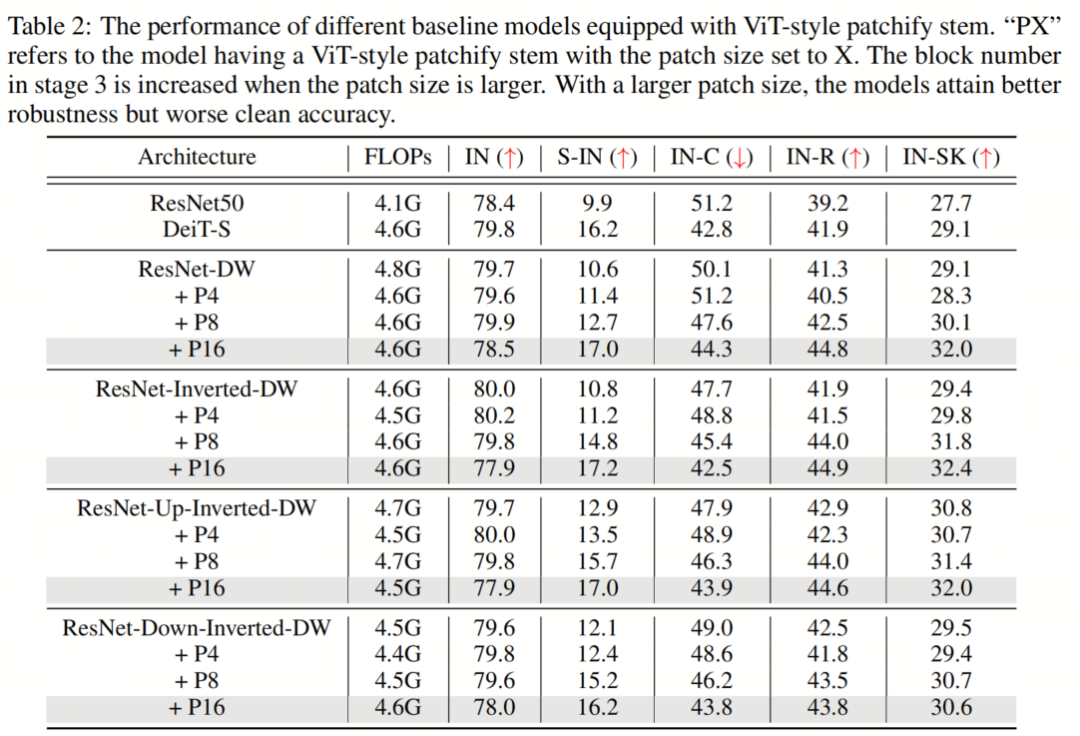 在表2中,作者观察到,增加ViT-style Patch Stem的Patch大小会提高鲁棒性基准的性能,尽管可能会以clean准确性为代价。具体而言,对于所有 Baseline 模型,当Patch大小设置为8时,所有鲁棒性基准的性能至少提高了0.6%。当Patch大小增加到16时,所有鲁棒性基准的性能提高了至少1.2%,其中最显著的改进是Stylized-ImageNet的6.6%。根据这些结果,作者可以得出结论,这种简单的Patch操作在很大程度上有助于ViT的强大鲁棒性,同时,可以在缩小CNNs和Transformers之间的鲁棒性差距方面发挥重要作用。作者还对 Advanced patchify stems进行了实验。令人惊讶的是,虽然这些Stem提高了相应的干净图像的准确性,但作者发现它们对out-of-distribution鲁棒性的贡献很小。这一观察结果表明,clean准确性和out-of-distribution的鲁棒性并不总是表现出正相关性。换言之,增强clean精度的设计可能不一定会带来更好的鲁棒性。强调了探索除了提高clean精度之外还可以提高鲁棒性的方法的重要性。
在表2中,作者观察到,增加ViT-style Patch Stem的Patch大小会提高鲁棒性基准的性能,尽管可能会以clean准确性为代价。具体而言,对于所有 Baseline 模型,当Patch大小设置为8时,所有鲁棒性基准的性能至少提高了0.6%。当Patch大小增加到16时,所有鲁棒性基准的性能提高了至少1.2%,其中最显著的改进是Stylized-ImageNet的6.6%。根据这些结果,作者可以得出结论,这种简单的Patch操作在很大程度上有助于ViT的强大鲁棒性,同时,可以在缩小CNNs和Transformers之间的鲁棒性差距方面发挥重要作用。作者还对 Advanced patchify stems进行了实验。令人惊讶的是,虽然这些Stem提高了相应的干净图像的准确性,但作者发现它们对out-of-distribution鲁棒性的贡献很小。这一观察结果表明,clean准确性和out-of-distribution的鲁棒性并不总是表现出正相关性。换言之,增强clean精度的设计可能不一定会带来更好的鲁棒性。强调了探索除了提高clean精度之外还可以提高鲁棒性的方法的重要性。3.2、LARGE KERNEL SIZE
将Self-Attention运算与经典卷积运算区分开来的一个关键特性是,它能够对整个输入图像或特征图进行运算,从而产生全局感受野。甚至在Vision Transformer出现之前,就已经证明了捕获长期依赖关系对神经网络的重要性。一个值得注意的例子是 Non-local 神经网络,它已被证明对静态和序列图像识别都非常有效,即使只配备了一个non-local block。然而,CNN中最常用的方法仍然是堆叠多个3×3卷积层,以随着网络的深入逐渐增加网络的感受野。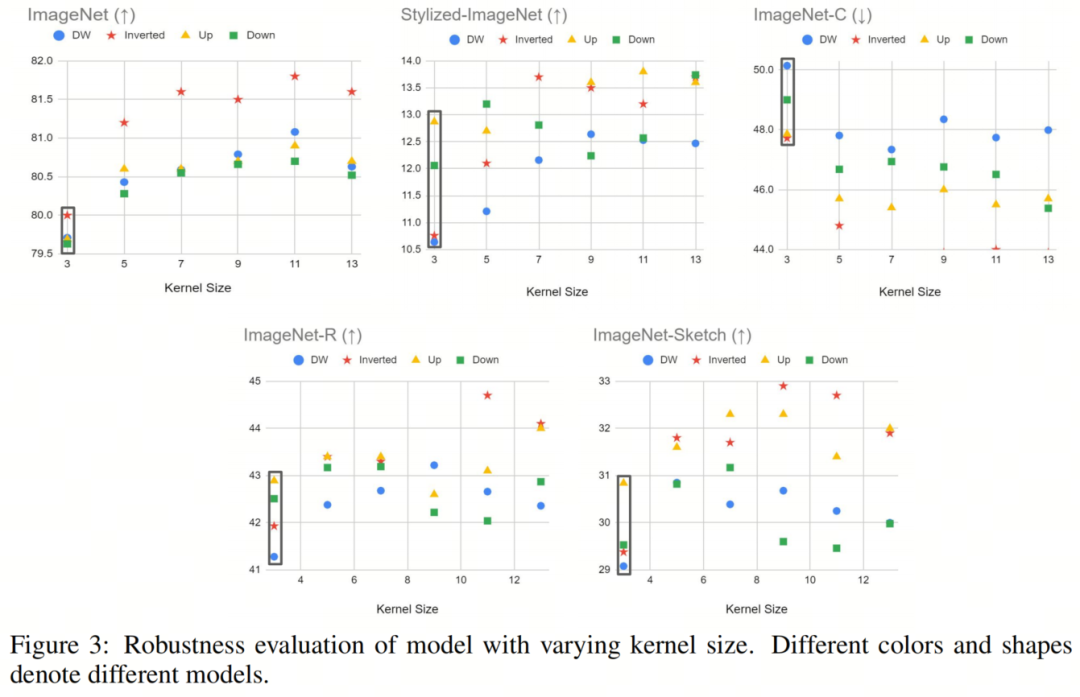
在本节中,作者旨在通过增加深度卷积层的内 kernel-size 来模拟Self-Attention块的行为。如图3所示,作者对不同大小的Kernel进行了实验,包括5、7、9、11和13,并在不同的鲁棒性基准上评估了它们的性能。作者的研究结果表明,较大的 kernel-size 通常会带来更好的clean精度和更强的鲁棒性。尽管如此,作者也观察到,当 kernel-size 变得太大时,性能增益会逐渐饱和。
值得注意的是,使用具有较大Kernel的(标准)卷积将导致计算量的显著增加。例如,如果作者直接将ResNet50中的 kernel-size 从3更改为5,则生成的模型的总FLOP将为7.4G,这比Transformer的对应模型大得多。
然而,在使用深度卷积层的情况下,将内 kernel-size 从3增加到13通常只会使FLOP增加0.3G,与DeiT-S(4.6G)的FLOP相比相对较小。
这里唯一的例外情况是ResNet-Inverted-DW:由于其Inverted Bottleneck设计中的大通道尺寸,将 kernel-size 从3增加到13带来了1.4G FLOP的增加,这在某种程度上是一个不公平的比较。顺便说一句,使用具有大Patchvsize的Patch Stem可以减轻大 kernel-size 所产生的额外计算成本。
因此,作者的最终模型仍将处于与DeiT-S相同的规模。对于具有多个拟议设计的模型。
3.3、减少激活层和规范化层
与ResNet块相比,典型的Vision Transformer块具有更少的激活和规范化层。这种架构设计选择也被发现在提高ConvNeXT的性能方面是有效的。受此启发,作者采用了在所有4个块实例化中减少激活和规范化层的数量的想法,以探索其对鲁棒性泛化的影响。具体而言,ResNet块通常包含一个规范化层和每个卷积层之后的一个激活层,导致一个块中总共有3个规范化和激活层。在作者的实现中,作者从每个块中移除了两个规范化层和激活层,从而只产生了一个规范化和激活层。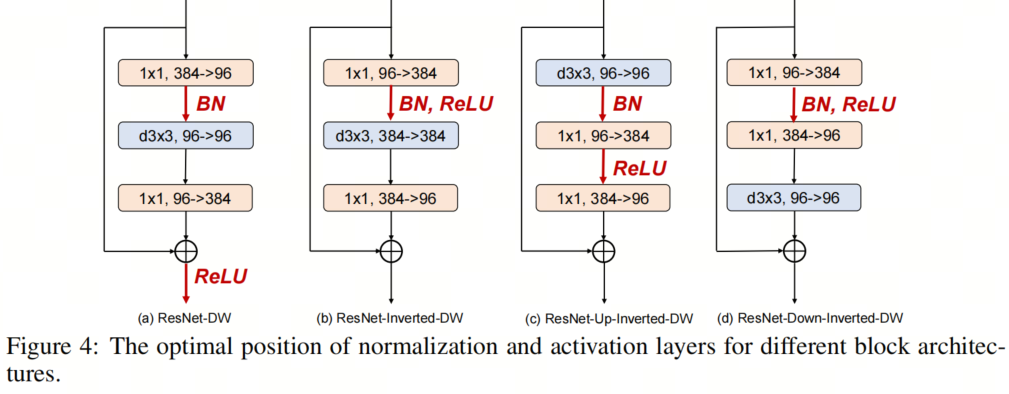 如图4所示,作者用去除激活层和规范化层的不同组合进行了实验,并根据经验发现,在通道维度扩展的卷积层之后只留下一个激活层(即输出通道的数量大于输入通道的数量),在第一次卷积之后留下一个规范化层,可以获得最佳结果层最佳配置。具有不同去除层的模型的结果如表3和表4所示。
如图4所示,作者用去除激活层和规范化层的不同组合进行了实验,并根据经验发现,在通道维度扩展的卷积层之后只留下一个激活层(即输出通道的数量大于输入通道的数量),在第一次卷积之后留下一个规范化层,可以获得最佳结果层最佳配置。具有不同去除层的模型的结果如表3和表4所示。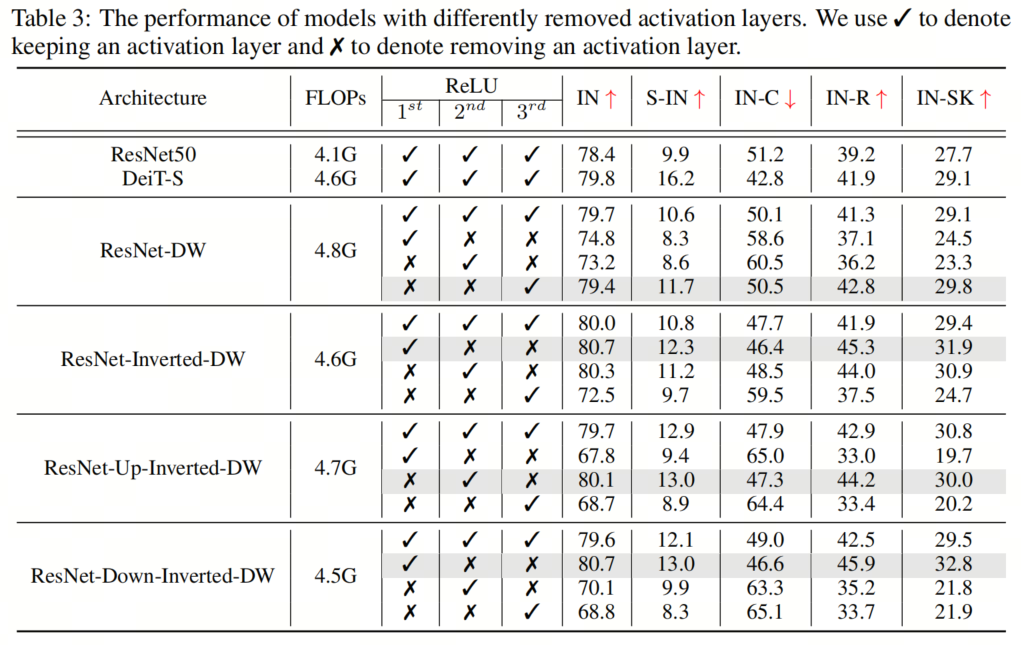
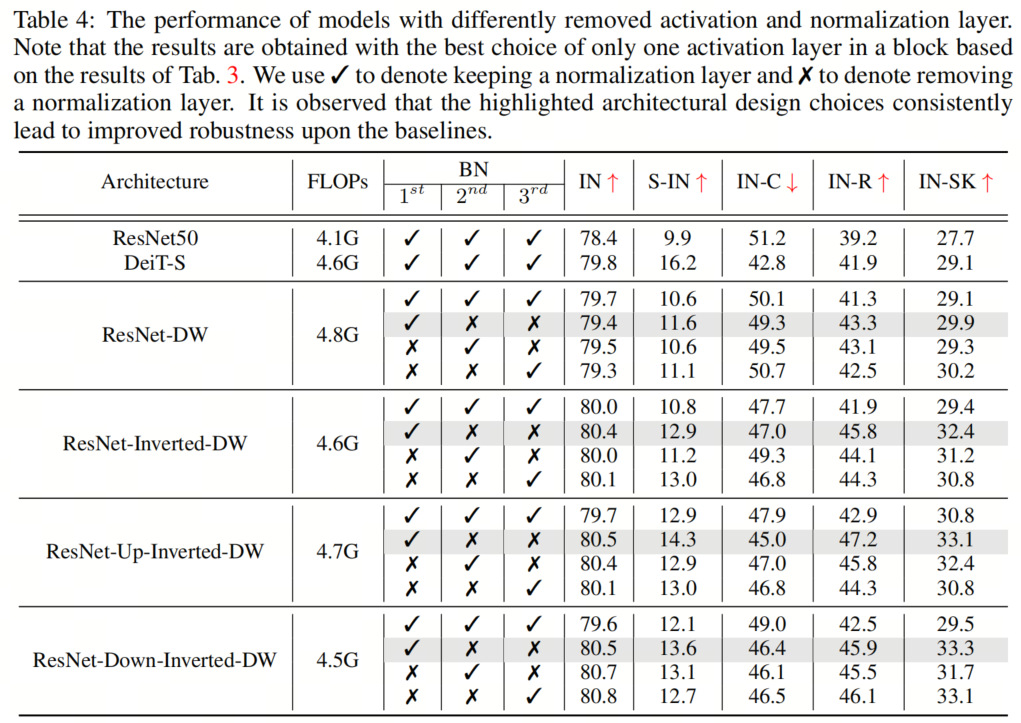 例如,对于 ResNet-Up-Inverted-DW,作者观察到Stylized-ImageNet上有1.4%的显著改进(14.3%对12.9%),ImageNet-C上有2.9%的改进(45.0%对47.9%),ImageNet-R上有4.3%的改进(47.2%对42.9%),而ImageNet Sketch上有2.3%的改进(33.1%对30.8%)。此外,减少规范化层的数量会降低GPU内存使用率并加快训练,通过简单地去除几个规范化层来实现高达23%的加速。
例如,对于 ResNet-Up-Inverted-DW,作者观察到Stylized-ImageNet上有1.4%的显著改进(14.3%对12.9%),ImageNet-C上有2.9%的改进(45.0%对47.9%),ImageNet-R上有4.3%的改进(47.2%对42.9%),而ImageNet Sketch上有2.3%的改进(33.1%对30.8%)。此外,减少规范化层的数量会降低GPU内存使用率并加快训练,通过简单地去除几个规范化层来实现高达23%的加速。4、组件组合
在本节中,作者将探讨组合所有建议的组件对模型性能的影响。具体来说,作者采用了16×16的Patch Stem和11×11的 kernel-size ,以及为所有架构放置规范化和激活层的相应最佳位置。这里的一个例外是ResNet-Inverted-DW,作者使用7×7的 kernel-size ,因为作者根据经验发现,使用过大的 kernel-size (例如,11×11)会导致不稳定的训练。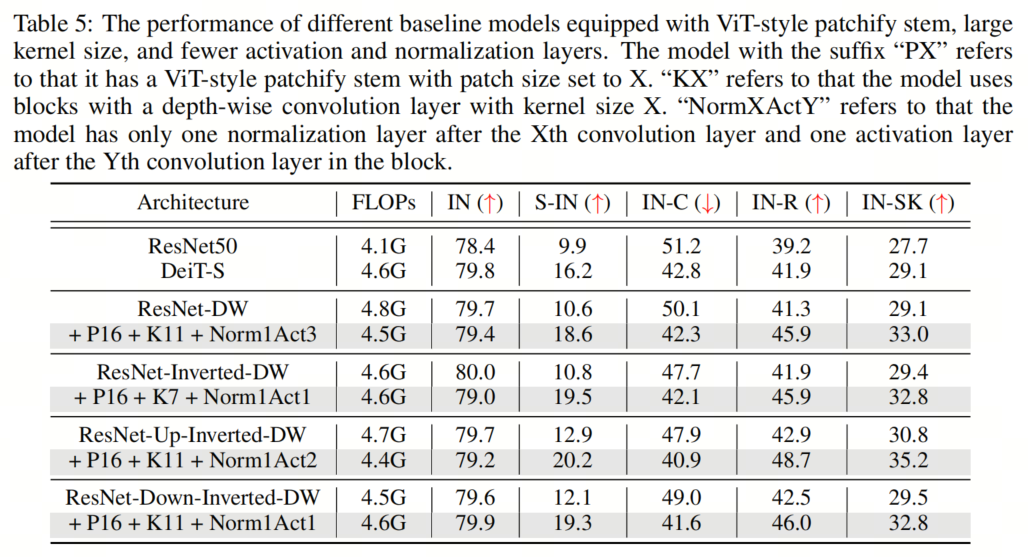
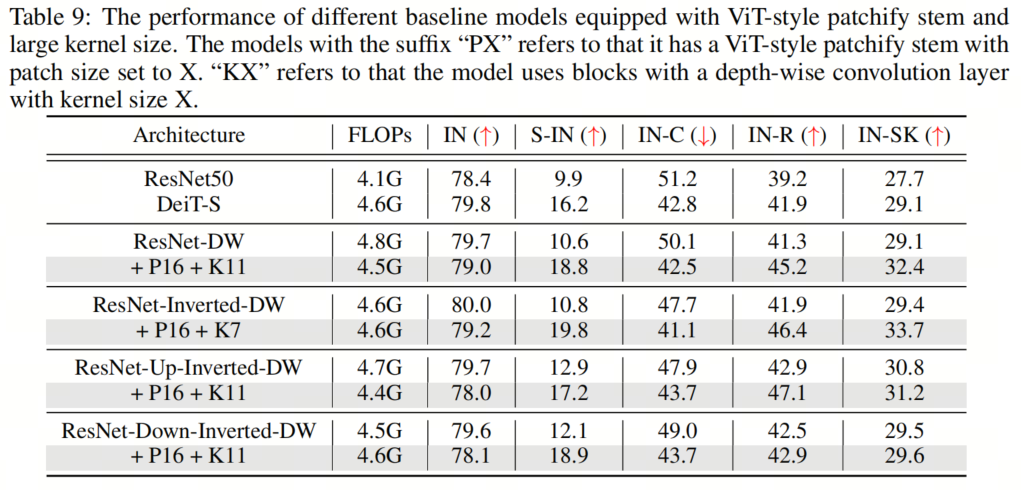
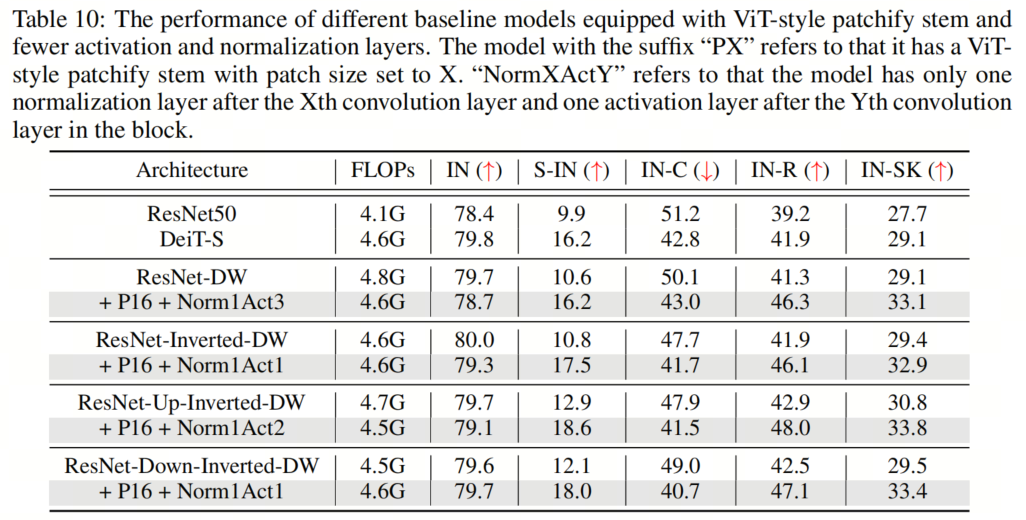
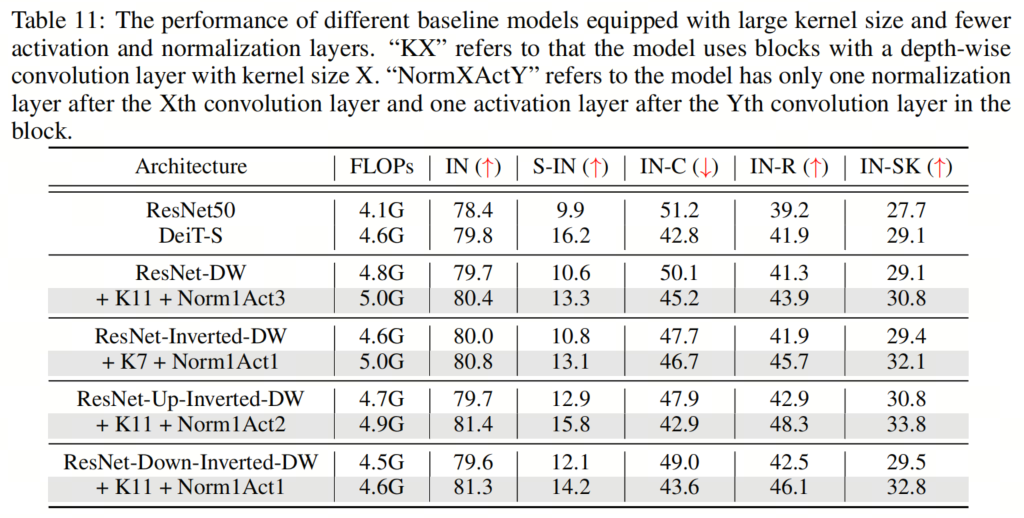 如表5和表9、表10、表11所示,作者可以看到这些简单的设计不仅在单独应用于ResNet时效果良好,而且在一起使用时效果更好。此外,通过采用所有3种设计,ResNet现在在所有4个out-of-distribution基准测试上都优于DeiT。这些结果证实了作者提出的架构设计的有效性,并表明没有任何类Self-Attention块的纯CNN可以实现与ViT一样好的鲁棒性。
如表5和表9、表10、表11所示,作者可以看到这些简单的设计不仅在单独应用于ResNet时效果良好,而且在一起使用时效果更好。此外,通过采用所有3种设计,ResNet现在在所有4个out-of-distribution基准测试上都优于DeiT。这些结果证实了作者提出的架构设计的有效性,并表明没有任何类Self-Attention块的纯CNN可以实现与ViT一样好的鲁棒性。5、知识蒸馏
知识蒸馏是一种通过转移更强的教师模型的知识来训练能力较弱的学生模型的技术。通常情况下,学生模型可以通过知识蒸馏获得与教师模型相似甚至更好的性能。然而,直接应用知识蒸馏让ResNet-50(学生模型)向DeiT-S(教师模型)学习在增强鲁棒性方面效果较差。
令人惊讶的是,当模型角色切换时,学生模型DeiT-S在一系列鲁棒性基准上显著优于教师模型ResNet-50,从而得出结论,实现DeiT良好鲁棒性的关键在于其架构,因此不能通过知识蒸馏将其转移到ResNet。
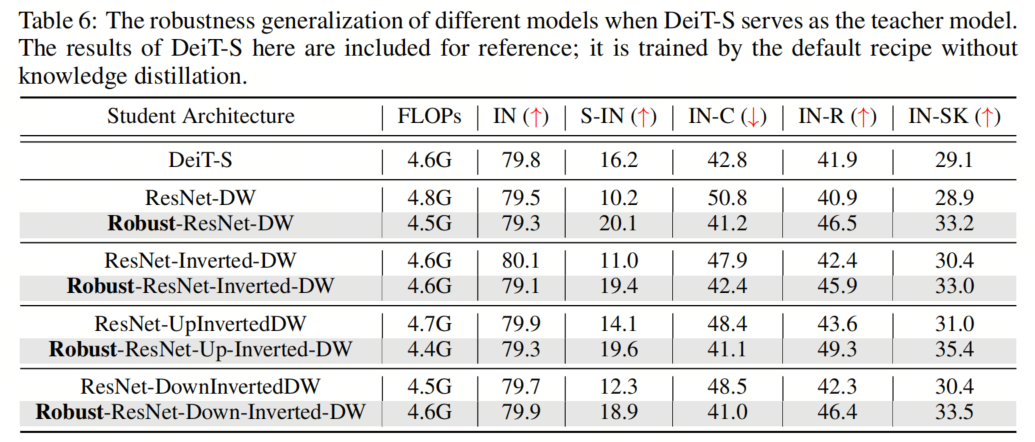 为了进一步研究这一点,作者用将所有3种提出的建筑设计相结合的模型作为学生模型,并用DeiT-S作为教师模型来重复这些实验。如表所示,作者观察到,在ViT提出的架构组件的帮助下,作者得到的Robust ResNet系列现在可以在out-of-distribution样本上始终比DeiT表现得更好。相比之下,尽管 Baseline 模型在clean ImageNet上取得了良好的性能,但不如教师模型DeiT那样鲁棒。
为了进一步研究这一点,作者用将所有3种提出的建筑设计相结合的模型作为学生模型,并用DeiT-S作为教师模型来重复这些实验。如表所示,作者观察到,在ViT提出的架构组件的帮助下,作者得到的Robust ResNet系列现在可以在out-of-distribution样本上始终比DeiT表现得更好。相比之下,尽管 Baseline 模型在clean ImageNet上取得了良好的性能,但不如教师模型DeiT那样鲁棒。6、更大的模型
为了证明作者提出的模型在更大尺度上的有效性,作者进行了实验来匹配DeiT Base的总FLOP。具体而言,作者将基本通道维度增加到(128、256、512和1024),并在网络的第3阶段添加20多个块,同时使用ConvNeXT-B配置进行训练。作者将调整后的模型的性能与DeiT-B进行了比较,如表7所示。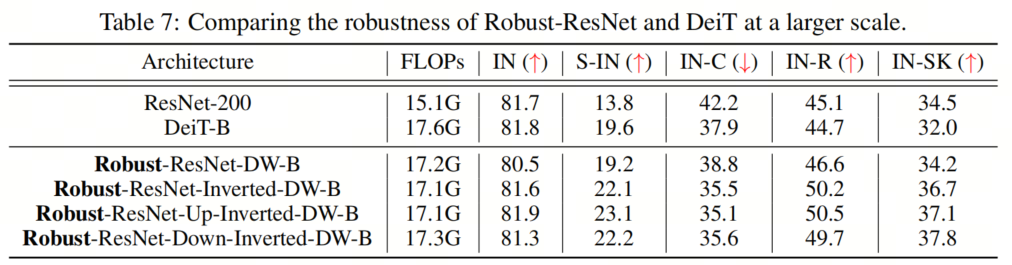 作者的结果表明,即使在更大的规模上,作者提出的Robust-ResNet家族也能很好地对抗DeiT-B,这表明作者的方法在扩大模型规模方面有很大的潜力。
作者的结果表明,即使在更大的规模上,作者提出的Robust-ResNet家族也能很好地对抗DeiT-B,这表明作者的方法在扩大模型规模方面有很大的潜力。7、更多STEM实验
最近的研究表明,用少量stacked 2-stride 3×3 convolution layers取代ViT-style patchify stem可以极大地简化优化,从而提高clean精度。为了验证其在鲁棒性基准上的有效性,作者还实现了ViT-S的卷积Backbone,使用4个3×3卷积层的堆栈,Stride为2。结果如表8所示。令人惊讶的是,尽管卷积stem的使用确实获得了更高的clean精度,但在out-of-distribution鲁棒性方面,它似乎不如ViT-style patchify stem有帮助。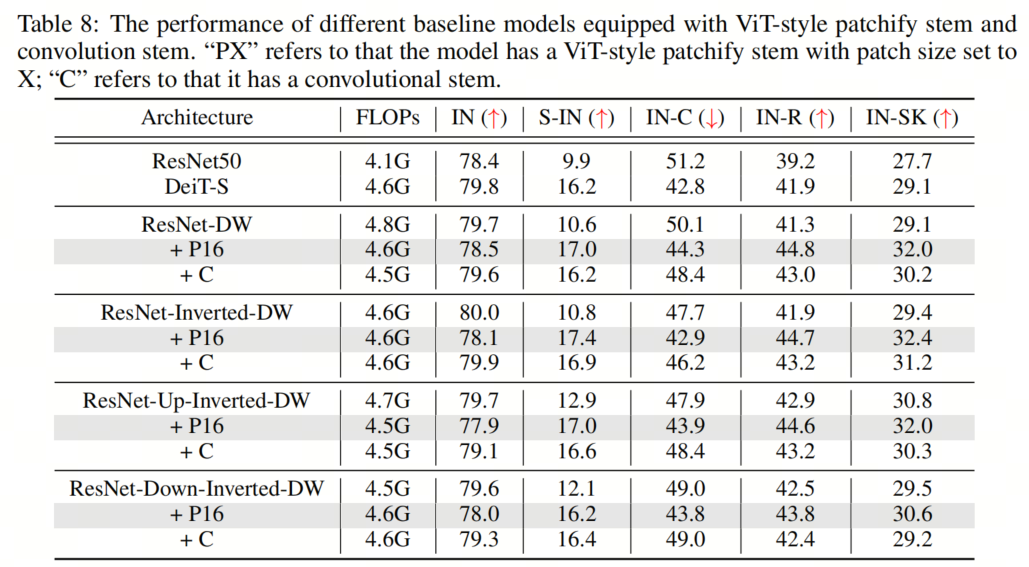
8、与其他模型的比较
除了DeiT,这里作者还评估了作者提出的Robust-ResNet模型,ConvNeXt和Swin-Transformer,在out-of-distribution鲁棒性。如表12中所示,4个模型中,所有的out-of-distribution测试的性能都类似于ConvNeXt或Swin-Transformer或更好。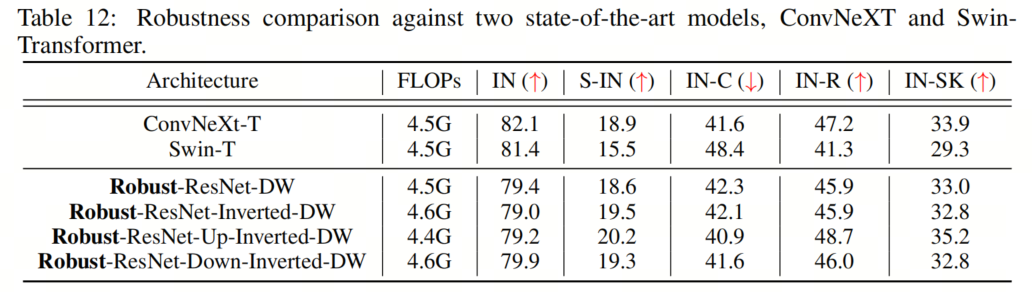
9、重复实验
为了证明作者提出的组件所实现的鲁棒性改进的统计意义,作者用不同的随机种子进行了3次实验,并在表13中报告了平均值和标准差。作者在3次运行中只观察到很小的变化,这证实了作者提出的模型实现了一致和可靠的性能增益。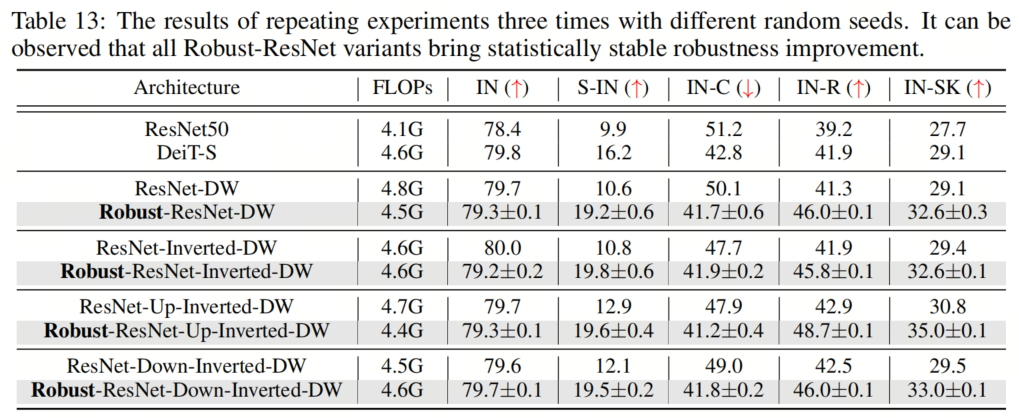
10、Imagenet评估
ImageNet-A数据集包括一组自然对抗性样本,这些样本对机器学习模型的性能有相当大的负面影响。在表14中,作者比较了作者的Robust-ResNet模型和DeiT在ImageNet-A数据集上的性能。值得注意的是,虽然Robust ResNet模型在输入分辨率为224的情况下不如DeiT执行得好,但将输入分辨率增加(例如,增加到320)显著缩小了Robust ResNet和ImageNet-A上的DeiT之间的差距。作者推测这是因为ImageNet-A中感兴趣的目标往往比标准ImageNet中的目标小。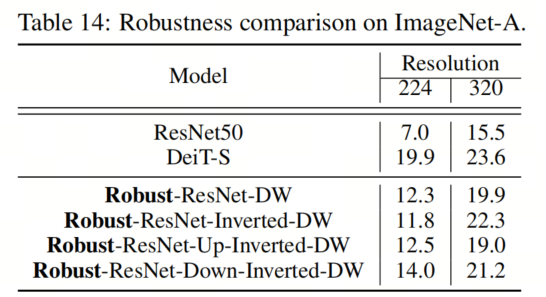
11、结构化重参
最近的一系列工作通过结构重参化促进了训练多分支但推理plain模型架构的想法。RepLKNet特别表明,使用小Kernel的重参化可以缓解与大Kernel卷积层相关的优化问题,而不会产生额外的推理成本。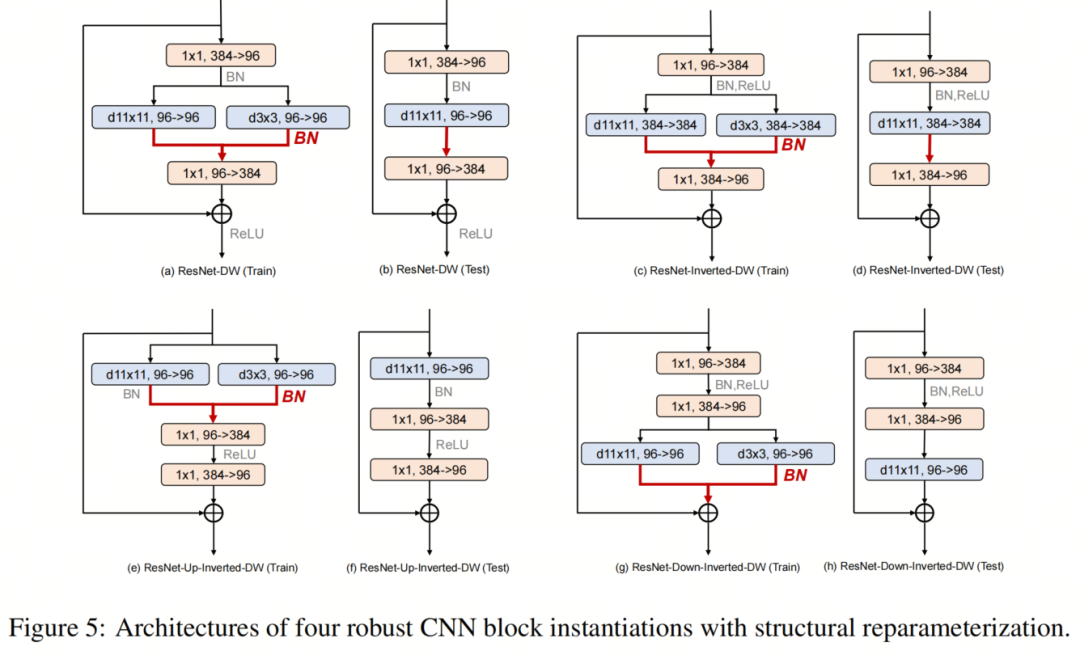 考虑到Robust ResNet模型也使用大Kernel,作者在这里试验了结构重参化的想法,并利用训练时间多分支块架构来进一步提高模型性能。块架构如图5所示。
考虑到Robust ResNet模型也使用大Kernel,作者在这里试验了结构重参化的想法,并利用训练时间多分支块架构来进一步提高模型性能。块架构如图5所示。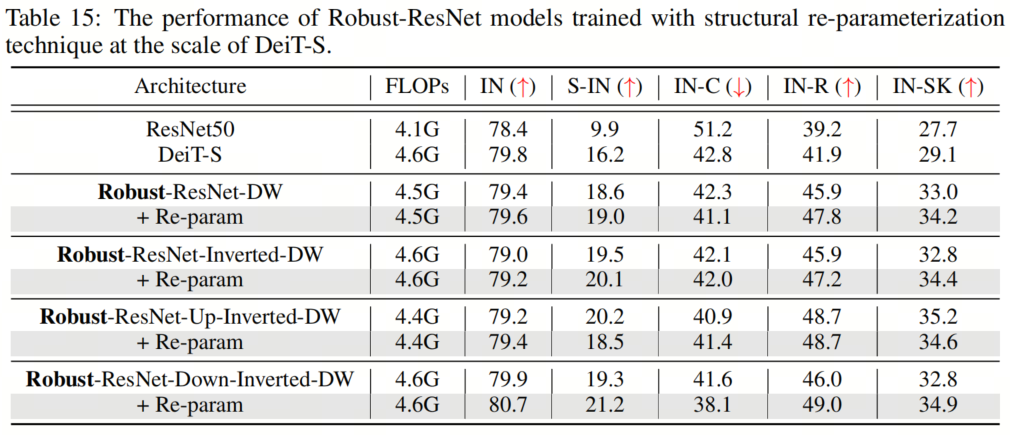
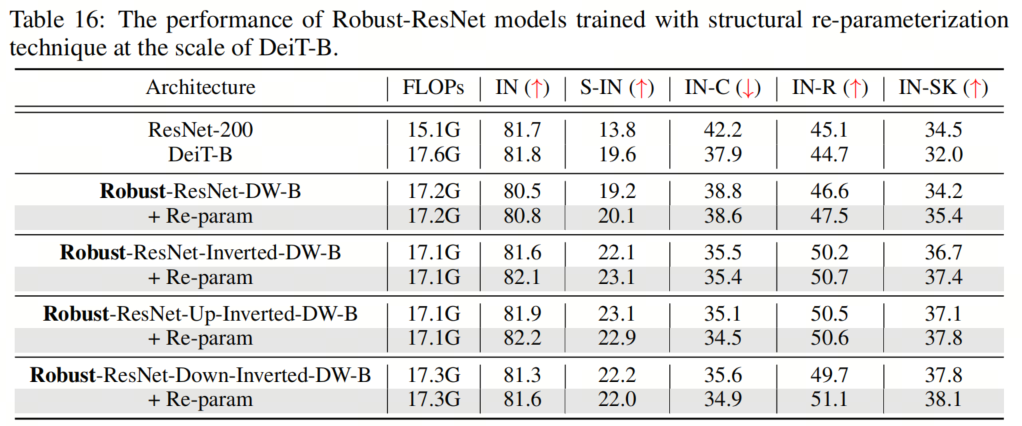 表15和表16显示了两种不同模型尺度的结果,表明这种重参化方法总体上提高了性能。一个例外可能是Robust ResNet-Up-Inverted-DW,它偶尔会在重参化的情况下表现出稍差的鲁棒性。值得注意的是,通过重参化技术,作者能够使用 kernel-size 为11的卷积来训练Robust-ResNet-Up-Inverted-DW模型。
表15和表16显示了两种不同模型尺度的结果,表明这种重参化方法总体上提高了性能。一个例外可能是Robust ResNet-Up-Inverted-DW,它偶尔会在重参化的情况下表现出稍差的鲁棒性。值得注意的是,通过重参化技术,作者能够使用 kernel-size 为11的卷积来训练Robust-ResNet-Up-Inverted-DW模型。12、总结
最近的研究声称,Transformer在out-of-distribution样本上的表现优于神经网络,类Self-Attention架构是主要因素。相比之下,本文更仔细地研究了Transformer架构,并确定了Self-Attention块之外的几个有益设计。通过将这些设计结合到ResNet中,作者开发了一种CNN架构,该架构可以匹配甚至超过同等大小的视觉Transformer模型的鲁棒性。作者希望作者的发现能促使研究人员重新评估Transformers和CNNs之间的鲁棒性比较,并启发人们进一步研究开发更具鲁棒性的架构设计。13、参考
[1].CAN CNNS BE MORE ROBUST THAN TRANSFORMERS?.14、Robust ResNet的实现
from collections import OrderedDict
from functools import partial
import torch
import torch.nn as nn
from timm.data import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
from .helpers import build_model_with_cfg
from .layers import SelectAdaptivePool2d, AvgPool2dSame
from .layers import RobustResNetDWBlock, RobustResNetDWInvertedBlock, RobustResNetDWUpInvertedBlock, RobustResNetDWDownInvertedBlock
from .registry import register_model
__all__ = ['RobustResNet'] # model_registry will add each entrypoint fn to this
def _cfg(url='', **kwargs):
return {
'url': url,
'num_classes': 1000, 'input_size': (3, 224, 224), 'pool_size': (7, 7),
'crop_pct': 0.875, 'interpolation': 'bicubic',
'mean': IMAGENET_DEFAULT_MEAN, 'std': IMAGENET_DEFAULT_STD,
'first_conv': 'stem.0', 'classifier': 'head.fc',
**kwargs
}
default_cfgs = dict(
small=_cfg(),
base=_cfg(),
)
def get_padding(kernel_size, stride, dilation=1):
padding = ((stride - 1) + dilation * (kernel_size - 1)) // 2
return padding
def downsample_conv(
in_channels, out_channels, kernel_size, stride=1, dilation=1, first_dilation=None, norm_layer=None):
norm_layer = norm_layer or nn.BatchNorm2d
kernel_size = 1 if stride == 1 and dilation == 1 else kernel_size
first_dilation = (first_dilation or dilation) if kernel_size > 1 else 1
p = get_padding(kernel_size, stride, first_dilation)
return nn.Sequential(*[
nn.Conv2d(
in_channels, out_channels, kernel_size, stride=stride, padding=p, dilation=first_dilation, bias=True),
norm_layer(out_channels)
])
def downsample_avg(
in_channels, out_channels, kernel_size, stride=1, dilation=1, first_dilation=None, norm_layer=None):
norm_layer = norm_layer or nn.BatchNorm2d
avg_stride = stride if dilation == 1 else 1
if stride == 1 and dilation == 1:
pool = nn.Identity()
else:
avg_pool_fn = AvgPool2dSame if avg_stride == 1 and dilation > 1 else nn.AvgPool2d
pool = avg_pool_fn(2, avg_stride, ceil_mode=True, count_include_pad=False)
return nn.Sequential(*[
pool,
nn.Conv2d(in_channels, out_channels, 1, stride=1, padding=0, bias=True),
norm_layer(out_channels)
])
class Stage(nn.Module):
def __init__(
self, block_fn, in_chs, chs, stride=2, depth=2, dp_rates=None, layer_scale_init_value=1.0,
norm_layer=nn.BatchNorm2d, act_layer=partial(nn.ReLU, partial=True),
avg_down=False, down_kernel_size=1, mlp_ratio=4., inverted=False, **kwargs):
super().__init__()
blocks = []
dp_rates = dp_rates or [0.] * depth
for block_idx in range(depth):
stride_block_idx = depth - 1 if block_fn == RobustResNetDWDownInvertedBlock else 0
current_stride = stride if block_idx == stride_block_idx else 1
downsample = None
if inverted:
if in_chs != chs or current_stride > 1:
down_kwargs = dict(
in_channels=in_chs, out_channels=chs, kernel_size=down_kernel_size,
stride=current_stride, norm_layer=norm_layer)
downsample = downsample_avg(**down_kwargs) if avg_down else downsample_conv(**down_kwargs)
else:
if in_chs != int(mlp_ratio * chs) or current_stride > 1:
down_kwargs = dict(
in_channels=in_chs, out_channels=int(mlp_ratio * chs), kernel_size=down_kernel_size,
stride=current_stride, norm_layer=norm_layer)
downsample = downsample_avg(**down_kwargs) if avg_down else downsample_conv(**down_kwargs)
if downsample is not None:
assert block_idx in [0, depth - 1]
blocks.append(block_fn(
indim=in_chs, dim=chs, drop_path=dp_rates[block_idx], layer_scale_init_value=layer_scale_init_value,
mlp_ratio=mlp_ratio,
norm_layer=norm_layer, act_layer=act_layer,
stride=current_stride,
downsample=downsample,
**kwargs,
))
in_chs = int(chs * mlp_ratio) if not inverted else chs
self.blocks = nn.Sequential(*blocks)
def forward(self, x):
x = self.blocks(x)
return x
class RobustResNet(nn.Module):
# TODO: finish comment here
r""" RobustResNetDW
A PyTorch impl of :
Args:
in_chans (int): Number of input image channels. Default: 3
num_classes (int): Number of classes for classification head. Default: 1000
depths (tuple(int)): Number of blocks at each stage. Default: [3, 3, 9, 3]
dims (tuple(int)): Feature dimension at each stage. Default: [96, 192, 384, 768]
drop_rate (float): Head dropout rate
drop_path_rate (float): Stochastic depth rate. Default: 0.
layer_scale_init_value (float): Init value for Layer Scale. Default: 1e-6.
head_init_scale (float): Init scaling value for classifier weights and biases. Default: 1.
"""
def __init__(
self, block_fn, in_chans=3, num_classes=1000, global_pool='avg', output_stride=32,
patch_size=16, stride_stage=(3, ),
depths=(3, 3, 9, 3), dims=(96, 192, 384, 768), layer_scale_init_value=1e-6,
head_init_scale=1., head_norm_first=False,
norm_layer=nn.BatchNorm2d, act_layer=partial(nn.ReLU, inplace=True),
drop_rate=0., drop_path_rate=0., mlp_ratio=4., block_args=None,
):
super().__init__()
assert block_fn in [RobustResNetDWBlock, RobustResNetDWInvertedBlock, RobustResNetDWUpInvertedBlock, RobustResNetDWDownInvertedBlock]
self.inverted = True if block_fn != RobustResNetDWBlock else False
assert output_stride == 32
self.num_classes = num_classes
self.drop_rate = drop_rate
self.feature_info = []
block_args = block_args or dict()
print(f'using block args: {block_args}')
assert patch_size == 16
self.stem = nn.Conv2d(in_chans, dims[0], kernel_size=patch_size, stride=patch_size)
curr_stride = patch_size
self.stages = nn.Sequential()
dp_rates = [x.tolist() for x in torch.linspace(0, drop_path_rate, sum(depths)).split(depths)]
prev_chs = dims[0]
stages = []
# 4 feature resolution stages, each consisting of multiple residual blocks
for i in range(4):
stride = 2 if i in stride_stage else 1
curr_stride *= stride
chs = dims[i]
stages.append(Stage(
block_fn, prev_chs, chs, stride=stride,
depth=depths[i], dp_rates=dp_rates[i], layer_scale_init_value=layer_scale_init_value,
norm_layer=norm_layer, act_layer=act_layer, mlp_ratio=mlp_ratio,
inverted=self.inverted, **block_args)
)
prev_chs = int(mlp_ratio * chs) if not self.inverted else chs
self.feature_info += [dict(num_chs=prev_chs, reduction=curr_stride, module=f'stages.{i}')]
self.stages = nn.Sequential(*stages)
assert curr_stride == output_stride
self.num_features = prev_chs
self.norm_pre = nn.Identity()
self.head = nn.Sequential(OrderedDict([
('global_pool', SelectAdaptivePool2d(pool_type=global_pool)),
# ('norm', norm_layer(self.num_features)),
('flatten', nn.Flatten(1) if global_pool else nn.Identity()),
('drop', nn.Dropout(self.drop_rate)),
('fc', nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity())
]))
self.resnet_init_weights()
def resnet_init_weights(self):
for n, m in self.named_modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
nn.init.zeros_(m.bias)
elif isinstance(m, nn.BatchNorm2d):
nn.init.ones_(m.weight)
nn.init.zeros_(m.bias)
def get_classifier(self):
return self.head.fc
def reset_classifier(self, num_classes=0, global_pool='avg'):
# pool -> norm -> fc
self.head = nn.Sequential(OrderedDict([
('global_pool', SelectAdaptivePool2d(pool_type=global_pool)),
('norm', self.head.norm),
('flatten', nn.Flatten(1) if global_pool else nn.Identity()),
('drop', nn.Dropout(self.drop_rate)),
('fc', nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity())
]))
def forward_features(self, x):
x = self.stem(x)
x = self.stages(x)
x = self.norm_pre(x)
return x
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x
def _create_robust_resnet(variant, pretrained=False, **kwargs):
model = build_model_with_cfg(
RobustResNet, variant, pretrained,
default_cfg=default_cfgs[variant],
feature_cfg=dict(out_indices=(0, 1, 2, 3), flatten_sequential=True),
**kwargs)
return model
@register_model
def robust_resnet_dw_small(pretrained=False, **kwargs):
'''
4.49GFLOPs and 38.6MParams
'''
assert not pretrained, 'no pretrained models!'
model_args = dict(block_fn=RobustResNetDWBlock, depths=(3, 4, 12, 3), dims=(96, 192, 384, 768),
block_args=dict(kernel_size=11, padding=5),
patch_size=16, stride_stage=(3,),
norm_layer=nn.BatchNorm2d, act_layer=partial(nn.ReLU, inplace=True),
**kwargs)
model = _create_robust_resnet('small', pretrained=pretrained, **model_args)
return model
@register_model
def robust_resnet_inverted_dw_small(pretrained=False, **kwargs):
'''
4.59GFLOPs and 33.6MParams
'''
assert not pretrained, 'no pretrained models!'
model_args = dict(block_fn=RobustResNetDWInvertedBlock, depths=(3, 4, 14, 3), dims=(96, 192, 384, 768),
block_args=dict(kernel_size=7, padding=3),
patch_size=16, stride_stage=(3,),
norm_layer=nn.BatchNorm2d, act_layer=partial(nn.ReLU, inplace=True),
**kwargs)
model = _create_robust_resnet('small', pretrained=pretrained, **model_args)
return model
@register_model
def robust_resnet_up_inverted_dw_small(pretrained=False, **kwargs):
'''
4.43GFLOPs and 34.4MParams
'''
assert not pretrained, 'no pretrained models!'
model_args = dict(block_fn=RobustResNetDWUpInvertedBlock, depths=(3, 4, 14, 3), dims=(96, 192, 384, 768),
block_args=dict(kernel_size=11, padding=5),
patch_size=16, stride_stage=(3,),
norm_layer=nn.BatchNorm2d, act_layer=partial(nn.ReLU, inplace=True),
**kwargs)
model = _create_robust_resnet('small', pretrained=pretrained, **model_args)
return model
@register_model
def robust_resnet_down_inverted_dw_small(pretrained=False, **kwargs):
'''
4.55GFLOPs and 24.3MParams
'''
assert not pretrained, 'no pretrained models!'
model_args = dict(block_fn=RobustResNetDWDownInvertedBlock, depths=(3, 4, 15, 3), dims=(96, 192, 384, 768),
block_args=dict(kernel_size=11, padding=5),
patch_size=16, stride_stage=(2,),
norm_layer=nn.BatchNorm2d, act_layer=partial(nn.ReLU, inplace=True),
**kwargs)
model = _create_robust_resnet('small', pretrained=pretrained, **model_args)
return model
- 相关推荐
- 热点推荐
- 神经网络
- 计算机视觉
- Transformer
-
大语言模型背后的Transformer,与CNN和RNN有何不同2023-12-25 6957
-
一文详解CNN2023-08-18 1246
-
BROCADE DCX 8510 BACKBONE 部署选项,运行可靠2019-07-04 1371
-
视觉新范式Transformer之ViT的成功2021-02-24 7789
-
我们可以使用transformer来干什么?2021-04-22 13556
-
如何使用Transformer来做物体检测?2021-04-25 3478
-
使用跨界模型Transformer来做物体检测!2021-06-10 3097
-
Pelee:移动端实时检测Backbone2022-02-07 524
-
利用Transformer和CNN 各自的优势以获得更好的分割性能2022-11-05 8261
-
BEV+Transformer对智能驾驶硬件系统有着什么样的影响?2023-02-16 4038
-
掌握基于Transformer的目标检测算法的3个难点2023-08-22 1321
-
基于M55H的定制化backbone模型AxeraSpine2023-10-10 1871
-
自动驾驶中一直说的BEV+Transformer到底是个啥?2024-11-07 2762
-
Transformer如何让自动驾驶变得更聪明?2025-11-19 2547
全部0条评论

快来发表一下你的评论吧 !
