

RISC-V 跑大模型(三):LLaMA中文扩展
描述
这是RISC-V跑大模型系列的第三篇文章,前面我们为大家介绍了如何在RISC-V下运行LLaMA,本篇我们将会介绍如何为LLaMA提供中文支持。
1.模型扩充
以下步骤在X86下进行:
1.1准备工作
安装最新版本的python和以下依赖库。
| pip install protobuf==3.20.0 | 结构化数据存储格式 |
| pip install transformers | 把原版模型转换为HF格式 |
| pip install sentencepiece | 无监督的文本标记器和去标记器 |
| pip install peft | 使用LoRA的工具 |
1.2模型下载
下载LLaMA原版模型和中文扩充
LLaMA原版模型:
https://ipfs.io/ipfs/Qmb9y5GCkTG7ZzbBWMu2BXwMkzyCKcUjtEKPpgdZ7GEFKm/
中文扩充:
下载后的目录如下:


1.3合并模型
(1) 将LLaMA原版模型转换为Huggingface格式。这一步需要借助transformers提供的脚本convert_llama_weights_to_hf.py。
下载链接:https://github.com/huggingface/transformers/blob/main/src/transformers/models/llama/convert_llama_weights_to_hf.py
请执行以下命令:
python convert_llama_weights_to_hf.py --input_dir path_to_original_llama_root_dir --model_size 7B --output_dir path_to_original_llama_hf_dir
命令解释:将原版LLaMA的tokenizer.model放在--input_dir指定的目录,其余文件放在${input_dir}/${model_size}下。执行以下命令后,--output_dir中将存放转换好的Huggingface版权重。
(2) 合并LoRA权重,生成Huggingface全量模型,这一步需要借助:merge_llama_with_chinese_lora.py。
下载链接:
https://github.com/ymcui/Chinese-LLaMA-Alpaca/blob/main/scripts/merge_llama_with_chinese_lora.py
执行命令:
python merge_llama_with_chinese_lora.py --base_model path_to_original_llama_hf_dir --lora_model chinese-alpaca-lora-7b --output_dir path_to_output_dir
命令解释:这一步的参数可以参照上一步。
2.移植模型
在完成前面的步骤后会得到一个path_to_output_dir的目录,目录内容如下:

将目录下的consolidate.00.path和params.json上传到RISC-V中的llama.cpp/models目录下,这一步可以借助scp来实现:scp “源文件路径” 账户@地址:目的路径。之后的步骤可以参考本系列的第二篇文章。链接如下:RISC-V 跑大模型(二):LLaMA零基础移植教程
最后的运行效果:
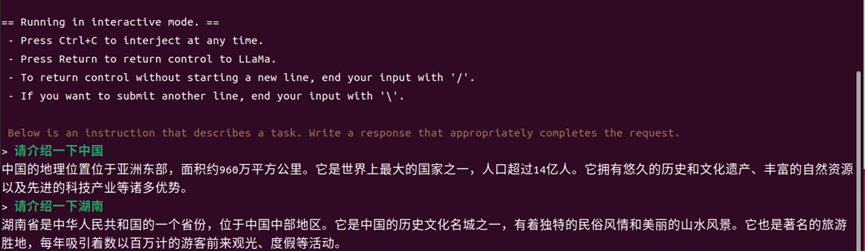
3.结语
我们也为大家准备好已经扩展了中文的LLaMA供大家使用,只要扫描下面的二维码,进群即可获得下载地址。之后我们还会对LLaMA进行优化加速,敬请期待。
另外,RISC -V跑大模型系列文章计划分为四期:
3.RISC-V跑大模型(三):LLaMA中文扩充(本篇)
4.更多性能优化策略。(计划)
审核编辑 黄宇
-
有用risc-v芯片跑系统的吗?2024-03-29 1078
-
risc-v的发展历史2024-07-29 1711
-
RISC-V B扩展介绍及实现2025-10-21 809
-
RISC-V你了解多少?2020-08-13 3065
-
最详细RISC-V中文手册2021-01-24 10562
-
RISC-V是什么2021-07-23 2283
-
RISC-V-Reader-Chinese-v2p1 RISC-V手册(中文) RISC-V开源指令集的指南2022-04-22 13086
-
risc-v是什么意思2023-03-30 2262
-
有RISC-V跑uCLinux或者NO MMU的Linux的项目吗?2023-04-03 1395
-
RISC-V 发展2023-04-14 1121
-
RISC-V规范的演进 RISC-V何时爆发?2021-02-11 4572
-
关于RISC-V的P扩展简述与实例解析2021-04-27 8977
-
RISC-V跑大模型(二):LLaMA零基础移植教程2023-07-10 2172
-
RISC-V 跑大模型(二):LLaMA零基础移植教程2023-07-17 2500
-
解锁RISC-V技术力量丨曹英杰:RISC-V与大模型探索2024-04-16 2402
全部0条评论

快来发表一下你的评论吧 !
