

大模型评测难度大吗 大模型的评测应该怎么弄?
人工智能
描述
大模型的评测应该怎么弄?
之前在Baichuan 7B的时候,有个哥们在github发布了一个issue,说这个模型有C-eval测试集泄漏的问题,具体证据为:

当然,百川也不避讳,让大家充分讨论这个问题。
官方给出了一个解释:
其实没什么毛病,另外我在刚发布的13B模型上测试了这个,还是存在同样的问题。另外我尝试了用13B的base模型让模型续写,一看就是训练了不少题库。。
首先C-eval本身题目是公开的离线测试,答案是不可见在线提交的形式来评测,这样能一定程度上规避泄漏的问题。
但由于大模型的特殊性,其训练数据讲究大而全,巴不得全网的数据都塞进去。
目前评测大模型的方法,除了手动体验,人工评测,其他都是数据集题目的形式。
数据集旨在考察大模型的百科全书式的知识理解程度,为了好评测,把他们转化成客观选择题的形式。
这样的排行榜会存在一个很尴尬的问题,那就是一众中文大模型在排行榜上吊打GPT3.5甚至GPT4,实际体验却不尽人意。
比如经典的C-eval排行榜目前是这样的:
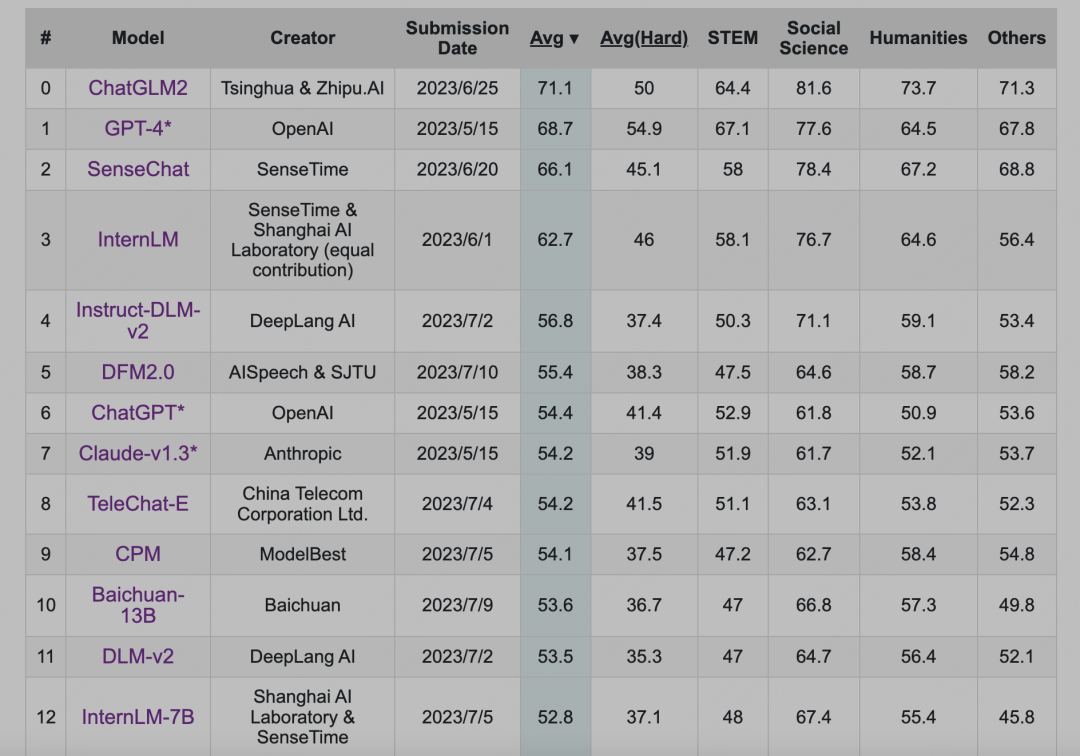
但大家心里都有一杆秤,几斤几两都门儿清。
这就是为什么现在卖数据最火的是题库数据,仔细想想,这就跟高考刷题一样。
这里引用下八友科技CEO(国内著名数据提供商,大模型数据市占率50%)的观点:
我认为大模型的主战场分3个阶段。
第一个阶段是重点突破“有正确答案”的领域。比如中高考,这个通过简单的得分情况,可以让模型的能力进行比较,这一步非常关键。现在教辅类数据非常关键,也就在于此。
除了这个,还有就是场景结合的,这个因为有场景优势的企业有独家数据,有独家业内人士,也就是有正确“答案”,可以判断好坏,因此这也是一个重点战场。
第二个阶段是重点突破“没有正确答案”的领域。这个阶段评价遇到了困难,但是基于第一个阶段,且有了足够多数据,可以认为大模型给出的预测,或者判断,理解是具有高水平的,只是这个没法或者很难给出标准答案,这个领域更加艺术的感觉,你会觉得大模型给出的回答更好,但是你也不知道最好是什么样子的。
第三个阶段是重点突破涉及生产力相关的领域,也就是跳过了第一阶段证明阶段,和第二阶段的炫耀阶段,直接推动社会生产力发展。
目前数据提供商最值钱的数据就是题库了,国内大模型很懂得投机取巧,反正你是知识类客观题评测,我把全网的题库数据都塞进去。
实在买不到买不全的数据,我还可以用测试集的每一道题目去反向爬取互联网相关内容,爬不到原题也能找到差不多的数据,再把他们都塞进去,针对性刷题。
这就是离线测试集问题的所在了,这对大模型来说,相当于开卷考试。
真正的考试连题干也不能让你看到。
所以针对客观题的大模型评测应该怎么做呢?
我们设想大模型参与的闭卷考试。
作为一个kaggle老玩家,这里推荐一个kaggle比赛,昨天刚上新的热乎的数据,https://www.kaggle.com/competitions/kaggle-llm-science-exam/ ,数据来自于参考维基百科话题,用gpt生成+人工过滤的科学领域多选题,附带参考训练集,测试集隐藏不可见,提交模型在线推断,最高支持10B左右模型推断。
众所周知,kaggle是谷歌家的,谷歌这是在众筹大模型了。。。
抛开数据本身质量不管,这个模式也存在一个问题,对发起方的经济实力有一定要求,比如上百B的模型咋推断?
另外如果模型对部署有特定要求怎么办?
还有就是提交模型和推断代码,无疑于把自己的核心科技提供给第三方了,所以这里存在一个信任的问题。
另外考察数据的话,kaggle上这个评测领域也过于局限了,不够全,更像是一个大榜单中小数据。
评测的数据本身要注意什么呢?这里引用了的一些思考 :
原文:https://mp.weixin.qq.com/s/Q4IU6dbwy5U-iQ0ah_TGBA
大模型评测其中四点比较重要:能力边界、case边界、指令形式、自动化量化。
能力边界
在今天这个大模型效果目前,我们需要测它的哪些能力?听到比较多的有代码能力,推理能力,写作能力,多轮对话能力等等,这些能力字面意思很好理解,但是如果我们想真真整理出一个好的技能树也是比较困难的,比如说文本分类和阅读理解这个归纳到哪个能力?有的会说放到NLP基本任务,那有的阅读理解case(比如先需要在文本中找到对应的信息,然后进行一定的加减等逻辑运算才能得到结果)需要很强的推理能力,这个是该放到阅读理解还是放到推理能力?
所以划分的能力是否具有一个很好的覆盖性和正交性是这里需要考虑的点。
case边界
假设当前我们在测两个模型的数学能力,极端情况下,测试的100道case都是类似 “1+1等于几?”,我们拿这些case同时问gpt4和市面上一个其他的模型,得到的回答都是2,于是我们得出结论:两个模型数学能力接近。这显然不靠谱 !!!
又或者我们现在在测试写作能力,测试case是“帮我写一个悬疑故事”,结果两个模型都写出来了,都是有点悬疑的,那么得到结论写作能力接近,这结论显然也不靠谱。
为什么不靠谱呢?假设我们现在同样是在考察数学能力和写作能力,但是case分别是:(104+903)*2-18^2-10、帮我写一个悬疑故事,故事背景发生在唐朝,主人公是一名锦衣卫,故事的开头要是从一件很小的事带入然后发现了更多背后的故事。写出前三章故事。
还有各种各样的复杂指令,比如中英混着问,就能更好的测评模型的双语能力。
随着测试的case变得复杂后模型所能cover的能力可能机会看出明显的差距,自然也就得到不同的结论了,起码不会草率的得出比如数学能力一样。
所以测试的case是否具有多样性和复杂性是这里需要考虑的点。
指令形式
这里单独把指令形式拿出来,是想提一下prompt engineering这件事。
我们知道如今这些大模型对prompt很是敏感,同一个问题回答错了,可能换种问法比如加个“一步步推理”引导语他就又能回答对了,又比如通过few-shot这种形式先给它几个例子然后再问类似的问题,就能很好的回答。
每个模型对prompt的敏感度又不一样,对于同一个问题,同一个模型得到的结论可能都是不一样的,那怎么办呢?
这里笔者的建议是不要本末倒置,我们现在做的事情是测评,尤其是在做多个模型之间的对比,那么prompt就应该是符合人提问习惯的指令形式,对于某个问题人类怎么喜欢问就怎么来,如果模型不能get到,那就是你的指令对齐或者泛化做的不好,而不是说要花很大力气去写prompt迎合各个模型。
那么返回头来说,如果现在的工作是在测当前这个模型到底有没有这个知识,举个不太恰当的例子,假设你正在研发一个大模型,发现问“中国的capital是哪里?”他居然回答是苹果,那这个时候需要定位这个问题,你就可以先用中文问问“中国的首都是哪里?”看看能不能回答对,又或者先举几个类似的例子告诉模型,然后再问它,如果能够回答说吗模型本身是有“北京是中国的首都”这个通用知识的,可能是英文或者双语能力不行,所以这里通常的做法是,会用few-shot的指令形式去测底座模型,先看看底座模型是否有这个能力,如果没有,那后面训练什么的都是很难。又比如你是一个运营工作人员,现在也只能用A这个模型来完成某一件事,那就可以花点时间来做prompt engineering,来使得输出最大化的满足你的需求。
所以作为测评,指令设计不应该特意过多的去迎合模型(除非有如上的特殊目的等等),甚至应该像上一节说的,要多样性,才能更好的探究到模型的理解能力
自动化量化
最后的评估都需要有一个量化的结论,理论来说,人工评估是最保险的,甚至一些能力需要一些专业人员(代码能力、各个学科的题目等等),但是这样效率过于低下且成本过高,尤其是对于模型的迭代。目前业界的做法通常是chatgpt或者gpt4去打分,所以这里的难度就变成了打分prompt怎么写,它需要考虑的点有两个,一个是怎么写使得gpt4能够更好的理解当前的,另外一个是怎么约束好输出,方便我们直接可以根据输出进行量化,比如做选择题等等。
怎么评价一个模型的好坏,不仅困难,而且十分重要,绝对是一个核心的科技,这现在也是除了oepnai各家没怎么搞定的一个问题。
这个问题很关键,是因为基座大模型的训练耗时耗力,如果不能想出很好的提早检验方式的话,做实验的速度会慢特别多,所有的时间成本都可以折合成算力上。
所以你做实验慢了,相当于比别人少了GPU,足够触目惊心吧。
openai不仅仅卡多,还有实验效率倍增的buff,相当于 卡 * 效率倍数。
我们从公开的资料能了解到,openai是通过小模型来推演大模型,训练的部分阶段推演全部阶段,从而预测最终大模型的好坏。
具体的技术细节openai也没有透露特别多,是核心科技之一,大模型评测是非常重要和有影响力的一个方向,建议大家持续关注。
编辑:黄飞
-
名单公布!【书籍评测活动NO.30】大规模语言模型:从理论到实践2024-03-11 16034
-
名单公布!【书籍评测活动NO.31】大语言模型:原理与工程实践2024-03-18 7839
-
【大语言模型:原理与工程实践】大语言模型的评测2024-05-07 1838
-
名单公布!【书籍评测活动NO.41】大模型时代的基础架构:大模型算力中心建设指南2024-08-16 4169
-
想用OPA657 TI自带的模型生成CIR文件,怎么弄?2024-09-06 349
-
名单公布!【书籍评测活动NO.49】大模型启示录:一本AI应用百科全书2024-10-28 2504
-
云计算弹性评测模型的研究与实现2017-11-27 672
-
OpenMMLab 各算法库的评测指标集成2022-11-03 1703
-
大语言模型“书生·浦语”多项专业评测拔头筹2023-08-25 1278
-
大模型开源开放评测体系司南正式发布2024-02-05 1976
-
商汤科技加入中国移动人工智能大模型评测联盟2024-07-12 1333
-
通用大模型评测标准正式发布2024-10-14 1707
-
商汤日日新多模态大模型权威评测第一2024-12-20 1811
-
云知声山海大模型多项评测名列前茅2024-12-24 1025
-
深兰科技医疗大模型荣获MedBench评测第一2025-04-30 1031
全部0条评论

快来发表一下你的评论吧 !
