

如何组织PID命名空间的各种ID?PID命名空间基本概念简析
电子说
描述
Linux 支持以下命名空间类型:
- Mount (CLONE_NEWNS;2.4.19,2002)
- UTS (CLONE_NEWUTS; 2.6.19,2006)
- IPC (CLONE_NEWIPC; 2.6.19,2006)
- PID (CLONE_NEWPID; 2.6.24,2008)
- Network(CLONE_NEWNET;2.6.29,2009)
- User (CLONE_NEWUSER;3.8,2013)
- Cgroup(CLONE_NEWCGROUP;4.6,2016)
命名空间 API 由三个系统调用(clone()、unshare()和setns())以及许多/proc文件组成。CLONE_NEW* 常量包括:
CLONE_NEWIPC,CLONE_NEWNS , CLONE_NEWNET , CLONE_NEWPID ,CLONE_NEWUSER和 CLONE_NEWUTS 。
int clone(int (*child_func)(void *), void *child_stack, int flags, void *arg);
有二十多个不同的CLONE_*标志 控制clone()操作的各个方面,包括父进程和子进程是否共享资源,例如虚拟内存、打开的文件描述符和信号配置。
如果在调用中指定了CLONE_NEW* 之一,则会创建相应类型的 新命名空间 ,并且新进程将成为该****命名空间的成员;可以在flags中指定多个 CLONE_NEW* 。
在本文中,我们将研究 clone系统调用的 PID 命名空间部分,以及内核如何组织 PID 命名空间的各种ID。本文分析基于内核版本 linux-5.15.60。
一、PID命名空间基本概念
PID命名空间隔离的全局资源是“进程ID编号”空间。这意味着“不同PID命名空间”中的进程可以具有“相同的进程ID”。PID命名空间用于“在主机系统之间迁移的容器”,同时保持容器内部进程的相同进程ID。
与传统Linux(或UNIX)系统上的进程一样,在PID命名空间中的进程ID是唯一的,并且从 PID 1开始按顺序分配。同样地,与传统Linux系统一样,PID 1——init进程是特殊的:它是在命名空间内创建的第一个进程,并且在命名空间内执行某些管理任务。
通过调用带有 CLONE_NEWPID 标志的clone()函数可以“创建一个新的PID命名空间”。我们将展示一个简单的示例程序,使用clone()函数创建一个新的PID命名空间,并使用该程序来解释PID命名空间的一些基本概念。
主程序使用clone()函数创建一个新的PID命名空间,并显示生成子进程的PID:
child_pid = clone(childFunc,
child_stack + STACK_SIZE, /* Points to start of downwardly growing stack */
CLONE_NEWPID | SIGCHLD, argv[1]);
printf("PID returned by clone(): %ldn", (long) child_pid);
新创建的子进程在childFunc()中开始执行,该函数接收clone()调用的最后一个参数(argv[1])作为它的参数。这个参数后面再解释。childFunc()函数显示由clone()创建的子进程的进程ID和父进程ID,并最后执行标准的sleep程序:
printf("childFunc(): PID = %ldn", (long) getpid());
printf("ChildFunc(): PPID = %ldn", (long) getppid());
...
execlp("sleep", "sleep", "1000", (char *) NULL);
当我们运行这个程序时,输出的前几行如下:
[root@haha demo]# ./pidns_init_sleep /proc30
PID returned by clone(): 25070
childFunc(): PID = 1
childFunc(): PPID = 0
Mounting
procfs at /proc30
前两行输出显示了从两个不同PID命名空间的角度来看子进程的PID:调用clone()的“调用者的命名空间”和“子进程所在的命名空间”。
换句话说,子进程有两个PID:在父命名空间中为 25070,在clone()调用创建的新PID命名空间中为1。下一行输出显示了子进程在所在PID命名空间中的父进程ID(即getppid()返回的值)。
父进程PID为0,展示了PID命名空间操作的一个小特殊情况。
正如我们后面详细介绍的那样,PID命名空间形成了一个层次结构:一个进程只能看到“自己所在的PID命名空间”和 嵌套在该PID命名空间下的“子命名空间中”的进程。
由于由clone()“创建的子进程的父进程”处于不同的命名空间中,子进程无法“看到”父进程;因此,getppid()将父进程PID报告为零。
要解释pidns_init_sleep的最后一行输出,我们需要回到一个我们在讨论childFunc()函数实现时跳过的代码片段。
在Linux系统上,每个进程都有一个特殊的目录路径"/proc/PID",其中PID表示进程的ID。这个目录包含了描述该进程的虚拟文件。
这个机制被称为PID命名空间模型。在一个PID命名空间中,只有属于该命名空间或其子命名空间的进程的信息会显示在对应的"/proc/PID"目录中。
[root@haha linux-5.15.60]# mount |grep "proc on /proc"
proc on /proc type proc (rw,nosuid,nodev,noexec,relatime)
proc on /proc2 type proc (rw,relatime)
proc on /proc2 type proc (rw,relatime)
proc on /proc10 type proc (rw,relatime)
proc on /proc20 type proc (rw,relatime)
proc on /proc30 type proc (rw,relatime)
[root@haha linux-5.15.60]#
但是,要使与PID命名空间对应的"/proc/PID"目录可见,需要将proc文件系统挂载到该PID命名空间。我们可以在一个PID命名空间内的shell中,运行 mount命令来实现:
mount -t proc proc /mount_point
另外,也可以使用mount()系统调用来挂载procfs,我们程序的childFunc()函数就是这样的:
char *mount_point = arg;
if (mount_point != NULL) {
mkdir(mount_point, 0555); /* Create directory for mount point */
if (mount("proc", mount_point, "proc", 0,NULL) == -1)
errExit("mount");
printf("Mounting procfs at %sn", mount_point);
}
在我们的shell会话中,在/proc上挂载的procfs将显示父PID命名空间中可见的进程的PID子目录,而在/proc30 上挂载的procfs将显示驻留在子PID命名空间中的进程的PID子目录。
让我们回到运行pidns_init_sleep的shell会话。我们停止程序并使用ps命令在父命名空间的上下文中检查父进程和子进程的一些细节。
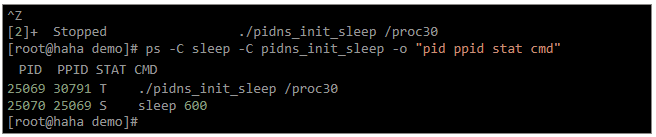
上述输出的最后一行中的"PPID"值(25069)显示“执行sleep的进程”的父进程是执行pidns_init_sleep的进程。
通过使用readlink命令来显示/proc/PID/ns/pid符号链接,我们可以看到这两个进程位于不同的PID命名空间中:
[root@haha demo]# readlink /proc/25069/ns/pid
pid:[4026531836]
[root@haha demo]# readlink /proc/25070/ns/pid
pid:[4026537948]
[root@haha demo]#
此时,我们还可以使用新挂载的procfs来获取有关新PID命名空间中进程的信息,从该命名空间的角度来看。首先,我们可以使用以下命令获取该命名空间中的PID列表:
[root@haha demo]# ls -d /proc30/[1-9]*
/proc30/1
如上所示,PID命名空间只包含一个进程,其PID(在该命名空间内)为1。我们还可以使用/proc/PID/status文件作为另一种方法,获取关于该进程的一些相同信息,就像我们之前在shell会话中看到的那样:
[root@haha demo]# cat /proc30/1/status | egrep '^(Name|PP*id)'
Name: sleep
Pid: 1
PPid: 0
[root@haha
demo]#
文件中的PPid字段为0,与getppid()报告子进程的父进程ID为0的事实相匹配。(子命名空间看不到父命名空间的进程)
二、嵌套的PID命名空间
如前所述,PID(进程标识符)命名空间以父子关系的层级嵌套方式存在。在一个PID命名空间内,可以看到同一命名空间中的所有其他进程,以及属于后代命名空间的所有进程。
在这里,“看到”意味着能够进行基于特定PID的系统调用(例如,使用kill()向进程发送信号)。子PID命名空间中的进程无法看到仅存在于父PID命名空间(或更远的祖先命名空间)中的进程。
一个进程在PID命名空间层级中的每一层都会有一个PID,从其所在的PID命名空间一直到根PID命名空间。调用getpid()始终报告与进程所在命名空间相关联的PID。
我们可以使用这里显示的程序(multi_pidns.c)来展示进程在每个可见的命名空间中具有不同的PID。为简洁起见,我们将简单地解释程序的功能,而不是逐行解析其代码。
该程序以嵌套PID命名空间中的子进程递归方式创建一系列子进程。在调用程序时指定的命令行参数确定要创建多少个子进程和PID命名空间:
./multi_pidns 5
除了创建一个新的子进程,每个递归步骤还在一个唯一命名的挂载点上挂载procfs文件系统。在递归的最后,最后一个子进程执行了sleep程序。上述命令行输出如下:
[root@haha demo]# ls -d /proc4/[1-9]*
/proc4/1 /proc4/2 /proc4/3 /proc4/4 /proc4/5
[root@haha demo]# ls -d /proc3/[1-9]*
/proc3/1 /proc3/2 /proc3/3 /proc3/4
[root@haha demo]# ls -d /proc2/[1-9]*
/proc2/1 /proc2/2 /proc2/3
[root@haha demo]# ls -d /proc1/[1-9]*
/proc1/1 /proc1/2
[root@haha demo]# ls -d /proc0/[1-9]*
/proc0/1
查看每个procfs中的PID,我们可以看到每个连续的procfs "级别"包含的PID越来越少,这也表示了每个PID命名空间只显示属于该PID命名空间或其后代命名空间的进程。
让我们看下在所有可见的命名空间中,递归结束时的PID:
[root@haha demo]# grep -H 'Name:.*sleep'/proc?/[1-9]*/status
/proc0/1/status:Name: sleep
/proc1/2/status:Name: sleep
/proc2/3/status:Name: sleep
/proc3/4/status:Name: sleep
/proc4/5/status:Name: sleep
[root@haha demo]#
换句话说,在最深层嵌套的 PID 命名空间 ( /proc0 ) 中,执行sleep的进程的 PID 为 1,而在创建的最顶层 PID 命名空间 ( /proc4 ) 中,该进程的 PID 为 5。
三、内核实现PID命名空间
要了解内核如何组织和管理进程ID,首先要知道进程ID 的类型:
内核中进程ID 的类型用 pid_type 来描述,它定义在 includelinuxpid.h 中
enum pid_type {
PIDTYPE_PID,
PIDTYPE_TGID,
PIDTYPE_PGID,
PIDTYPE_SID,
PIDTYPE_MAX,
};
- PID 是内核唯一区分每个进程的ID。使用 fork 或 clone 系统调用时生成的进程将被内核分配一个新的唯一 PID 值。
- TGID 是线程组ID。在一个进程中,如果使用 clone_THREAD 标志来调用 clone创建的进程,那么它就是该进程的一个线程(即轻量级进程,Linux没有严格的进程概念),它们在一个线程组中。同一线程组中所有进程都有相同的TGID,但由于是不同的进程,所以它们的PID不同;线程的领导者(也称为主线程)的TGID 与其 PID 相同。
- PGID 独立进程可以组成进程组(使用 setpgrp 系统调用),进程组可以简化向组内所有进程发送信号的操作。例如,通过管道连接的连接属于同一个进程组。进程组ID 称为 PGID。进程组中所有的进程都有相同的 PGID,等于组长的 PID。
- SID 可以将多个进程组组成一个会话组(使用 setsid 系统调用),可用于终端编程。会话组中所有进程都有相同的SID,该SID 存储在 task_struct 的 session 成员中。
PID命名空间的层级关系如下:有 4 个命名空间。父命名空间派生两个子命名空间,其中一个子命名空间派生另一个子命名空间。

由于每个命名空间是相互隔离的,所以每个命名空间可以有一个 PID 为1的进程。由于命名空间的层次性,父命名空间是知道子命名空间的存在的,所以子命名空间需要映射到父命名空间,
因此上图中 第 1 级 的两个两个子命名空间中的 6 个进程 都映射到 其父命名空间的 PID 号 5~ 10.
系统使用 struct task_struct 表示一个进程,进程中存储了全局ID 和 本地ID。
全局ID ---- 内核本身和初始命名空间中的唯一ID。 系统启动时 init 进程属于初始命名空间。全局ID 包括 pid_t pid 和 pid_t tgid 。默认情况下 pid_t 用 int 表示。
本地ID ---- 对于一个特定的命名空间来说,它在其命名空间中分配的ID就是本地ID。本地ID 用 struct pid * thread_pid 表示。

PID 数据结构
成员 tasks 是一个数组,每个数组项是一个哈希表头,对应一个ID 类型,因此一个ID 可用于多个进程(比如多个进程的进程组相同)。
struct upid {
int nr;// ID 的具体值
struct pid_namespace* ns;
};
struct pid {
refcount_t count;// 引用数, 一个PID 可能用于多个进程
unsigned int level;
spinlock_t lock;
/* lists of tasks that use this pid */
struct hlist_head tasks[PIDTYPE_MAX];
struct hlist_head inodes;
/* wait queue for pidfd notifications */
wait_queue_head_twait_pidfd;
struct rcu_head rcu;
struct upid numbers[1]; // 柔性数组,特定命名空间可见的信息, 数组大小为level
};
PID 命名空间结构
struct pid_namespace {
struct idr idr;
struct rcu_head rcu;
unsigned int pid_allocated; // 已分配多少个pid
struct task_struct* child_reaper; // 指向当前命名空间的 init 进程,每个命名空间都有一个相当于全局init进程的进程
struct kmem_cache* pid_cachep; // 指向分配pid 的slab地址
unsigned int level;// 当前命名空间的级别。初始命名空间的级别为0,其子命名空间级别为1,依次递增。
struct pid_namespace* parent; // 指向父命名空间
#ifdefCONFIG_BSD_PROCESS_ACCT
struct fs_pin* bacct;
#endif
struct user_namespace* user_ns;
struct ucounts* ucounts;
int reboot;/* group exit code if this pidns was rebooted */
struct ns_common ns;
} __randomize_layout;
假设一个进程组中有A、B 两个进程,且进程组组长为A,进程A 是在 2 级命名空间中创建的,它的pid为45 ,映射到1级命名空间,分配给它的pid为123;然后它被映射到级别 0 的命名空间,分配给它的 pid 是 27760。
进程A 创建了一个线程 A1, 那么 A, A1, B 的命名空间和进程的关系如下图所示:
- 进程 A 的成员 struct pid* thread_pid 是内核对进程标识符的内部表示方式。
- struct pid 以哈希链表的方式存储,可以通过数字pid值快速找到它和它所引用的进程。
- struct pid 保存了 嵌套的多个命名空间的指针 和 进程在此命名空间的进程标识符 nr。
- 命名空间使用基数树保存当前命名空间的 所有 struct pid,基数树的索引就是 进程在此命名空间的进程标识符。
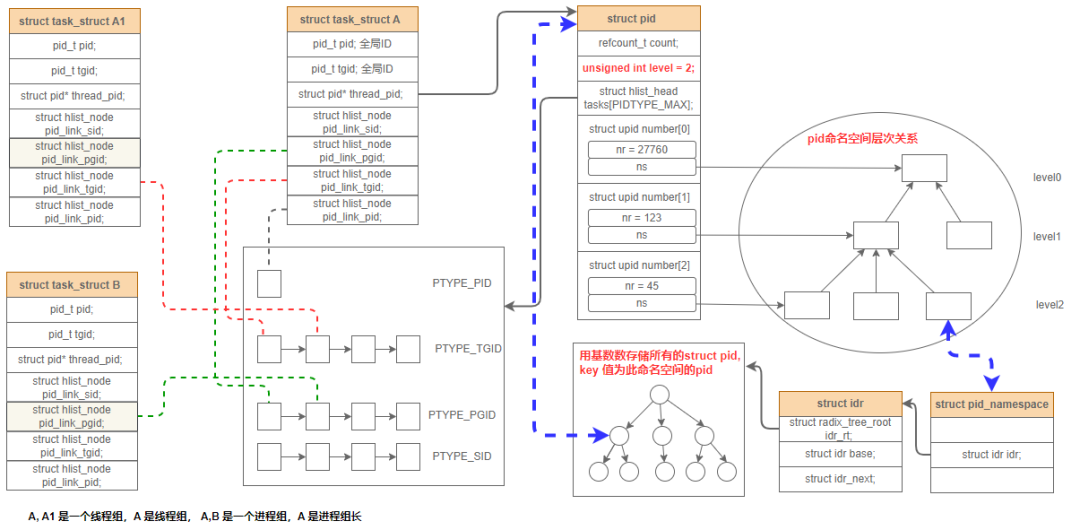
最后有个问题:如何通过PID 快速找到 task_struct?
内核代码通过 find_task_by_vpid 来实现这个功能,其实通过上面这张图就可以得出结论,简单的步骤如下:
首先,通过 pid 和 命名空间nr,在基数树上找到对应的 struct pid;
然后,通过 pid_type 在 struct pid 找到对应的节点struct hlist_node;
最后,根据内核的 container_of 机制 和 struct hlist_node 可以找到 struct task_struct 结构体。
struct task_struct* find_task_by_vpid(pid_t vnr) {
return find_task_by_pid_ns(vnr,task_active_pid_ns(current));
}
struct task_struct* find_task_by_pid_ns(pid_t nr, struct pid_namespace* ns) {
RCU_LOCKDEP_WARN(!rcu_read_lock_held(), "find_task_by_pid_ns() needs rcu_read_lock() protection");
return pid_task(find_pid_ns(nr, ns),PIDTYPE_PID);
}
struct pid* find_pid_ns(int nr, struct pid_namespace* ns) {
return idr_find(&ns- >idr, nr);
}
struct task_struct* pid_task(struct pid* pid, enum pid_type type) {
struct task_struct* result = NULL;
if (pid)
{
structhlist_node* first;
first = rcu_dereference_check(hlist_first_rcu(&pid- >tasks[type]),
lockdep_tasklist_lock_is_held());
if (first)
result =hlist_entry(first, struct task_struct, pid_links[(type)]);
}
return result;
}
#define hlist_entry(ptr, type, member) container_of(ptr,type,member)
-
鸿蒙TypeScript学习第19天【命名空间】2024-04-17 1882
-
C++笔记008:C++命名空间 namespace的作用和使用解析2018-08-11 3188
-
Linux的命名空间机制2019-03-18 1821
-
命名空间的实现2019-05-24 1627
-
hbase shell创建命名空间2021-07-28 1338
-
python常规包与命名空间包2022-03-11 3720
-
nvs_open和nvs_get从不存在的命名空间中工作是怎么回事?2023-04-14 433
-
模糊PID控制和空间矢量调制的通用变频器设计2016-04-13 1049
-
集群模式_Data_ONTAP_中的命名空间2016-12-28 682
-
《ASP.NET 2.0网络开发技术》 类、对象和命名空间2017-02-07 920
-
C++中命名空间的几大用法2017-09-28 711
-
基于PID调节相关的15个基本概念详解2018-01-08 7567
-
关于工业控制PID系统中的十五个基本概念2019-11-13 2657
-
一文了解C++的命名空间2020-06-29 3048
-
PID刚入门?新手必看的15个PID基本概念!2023-09-25 4359
全部0条评论

快来发表一下你的评论吧 !
