

大模型将会推动手机内存和AI加速器革新?
电子说
描述
人工智能已经成为半导体行业过去几年最重要的新推动力。而去年以ChatGPT为代表的大模型更是进一步点燃了人工智能以及相关的芯片市场,ChatGPT背后的大模型正在成为下一代人工智能的代表并可望进一步推进新的应用诞生。
说起大模型,一般我们想到的往往是在云端服务器上运行模型。然而,事实上大模型已经在走入终端设备。一方面,目前已经有相当多的工作证明了大模型经过适当处理事实上可以运行在终端设备上(而不局限于运行在云端服务器);另一方面,大模型运行在终端设备上也会给用户带来很大的价值。因此,我们认为在未来几年内,大模型将会越来越多地运行在终端设备上,而这也会推动相关芯片技术和行业的进一步发展。
智能汽车是大模型运行在终端的第一个重要市场。从应用角度来看,大模型运行在智能汽车的首要推动力就是大模型确实能给智能驾驶相关的任务带来客观的性能提升。去年,以BEVformer为代表的端到端鸟瞰摄像头大模型可以说是大模型在智能汽车领域的第一个里程碑,它把多个摄像头的视频流直接输入使用transformer模块的大模型做计算,最后的性能比之前使用传统卷积神经网络(CNN)模型的结果好了接近10个点,这个可谓是革命性的变化。而在上个月召开的CVPR上,商汤科技发布的UniAD大模型更是使用单个视觉大模型在经过统一训练后去适配多个不同的下游任务,最后在多个任务中都大大超越了现有最好的模型:例如,多目标跟踪准确率超越了20%,车道线预测准确率提升 30%,预测运动位移和规划的误差则分别降低了 38% 和 28%。
目前,汽车企业(尤其是造车新势力)已经在积极拥抱这些智能汽车的大模型,BEVformer(以及相关的模型)已经被不少车企使用,我们预计下一代大模型也将会在未来几年逐渐进入智能驾驶。如果从应用角度考虑,智能汽车上的大模型必须要在终端设备上运行,因为智能汽车对于模型运行的可靠性和延迟要求非常高,在云端运行大模型并且使用网络把结果传送到终端无法满足智能汽车的需求。
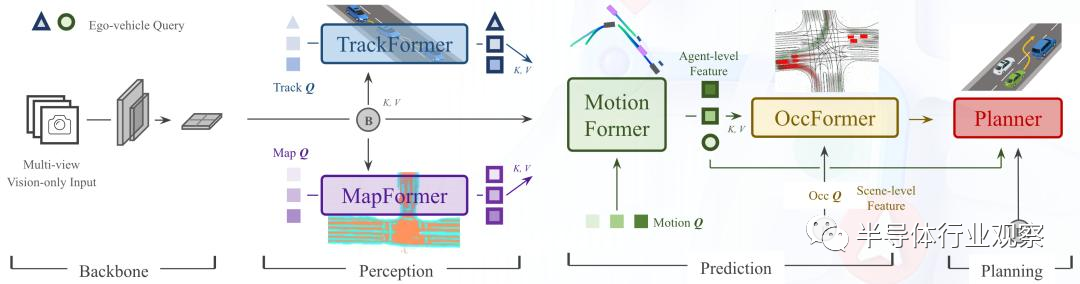
商汤科技提出的UniAD大模型架构,使用统一模型去适配多个任务
除了智能汽车之外,手机也是大模型进入终端的另一个重要市场。以ChatGPT为代表的语言类大模型事实上已经成为了下一代用户交互的重要组成部分,因此在手机上使用大语言模型将会能把这样的新用户交互体验带入手机操作系统中。而在手机设备终端直接运行大语言模型的主要好处在于能够在保护用户隐私的情况下给用户带来个性化的体验(例如归纳和某个用户的聊天记录等等)。目前,开源社区已经可以把Llama大语言模型能够运行在安卓手机上CPU,回答一个问题大约需要5-10秒的时间,我们认为未来的潜力巨大。
智能汽车芯片加速大模型:算力与功耗成为关键
目前,人工智能已经在智能汽车的辅助驾驶应用中得到了广泛应用,因此大多数智能汽车上使用的芯片也有对于人工智能的支持,例如加入人工智能加速器等。然而,这些人工智能加速器主要考虑的加速对象模型仍然是上一代以卷积神经网络为代表的模型,这些模型往往参数量比较小,对于算力的需求也比较低。
为了适配下一代大模型,智能汽车芯片会有相应的改动。下一代大模型对于智能汽车芯片的要求主要包括:
| 1 | 大算力: 由于智能汽车上的相关感知和规划任务都必须在实时完成,因此相关芯片必须能够提供足够的算力来支持这样的计算 |
|---|---|
| 2 | 低功耗: 智能汽车上的计算功耗仍然有限制,考虑到散热等因素,芯片不可能做到像GPU一样有几百瓦的功耗 |
| 3 | 合理的成本: 智能汽车上的芯片不能像GPU一样成本高达数千美元。因此,智能汽车上的大模型加速芯片主要考虑的就是如何在功耗和成本的限制下,实现尽可能高的算力。 |
我们可以从目前最成功的大模型加速芯片(即GPU)出发去推测支持大模型智能汽车芯片的具体架构,考虑GPU上有哪些设计思路需要进一步发扬光大,另外有哪些应该考虑重新设计。
首先, GPU上有海量的矩阵计算单元,这些计算单元是GPU算力的核心支撑(与之相对的,CPU上缺乏这些海量的矩阵计算单元因此算力无论如何不可能高上去),这些计算单元在智能汽车芯片上同样也是必须的;但是由于智能汽车芯片上的计算不用考虑GPU上对于数据流和算子通用性的支持,因此智能汽车芯片上无需做GPU上这样的大量stream core,因此从控制逻辑的角度可以做简化以减少芯片面积成本。
第二, GPU能成功运行大模型的另一个关键在于有超高速的内存接口和海量的内存,因为目前大模型的参数量动辄千亿级,这些模型必须有相应的内存支持。这一点在智能车芯片上同样需要,只是智能汽车芯片未必能使用GPU上的HBM这样的超高端(同时也是高成本)内存,而是会考虑和架构协同设计来尽可能地利用LPDDR这样的接口的带宽。
第三, GPU有很好的规模化和分布式计算能力,当模型无法在一个GPU上装下时,GPU可以方便地把模型分割成多个子模型在多个GPU上做计算。智能车芯片也可以考虑这样的架构,从而确保汽车可以在使用周期内满足日新月异的模型的需求。
综合上述考虑,我们推测针对大模型的智能车芯片架构中,可能会有多个人工智能加速器同时运行,每个加速器都有简单的设计(例如一个简单的控制核配合大量计算单元),搭配大内存和高速内存接口,并且加速器之间通过高速互联互相通信从而可以以本地分布计算的方法来加速大模型。从这个角度,我们认为智能驾驶芯片中的内存和内存接口将会扮演决定性的角色,而另一方面,这样的架构也非常适合使用chiplet的方式来实现每个加速器并且使用高级封装技术(包括2.5D和3D封装)来完成多个加速器的整合,换句话说大模型在智能汽车的应用将会进一步推动下一代内存接口和高级封装技术的普及和演进。
大模型将会推动手机内存和AI加速器革新
如前所述,大模型进入手机将会把下一代用户交互范式带入手机。我们认为,大模型进入手机将会是一个渐进的过程:例如,目前的大语言模型,即使是小版本的Llama 70亿参数的模型,也没法完全装入手机的内存中,而必须部分放在手机的闪存中运行,这就导致了运行速度比较慢。在未来的几年中,我们认为手机上面的大语言模型会首先从更小的版本(例如10亿参数以下的模型)开始进入应用,然后再逐渐增大参数量。
从这个角度来看,手机上运行大模型仍然会加速推动手机芯片在相关领域的发展,尤其是内存和AI加速器领域——毕竟目前主流运行在手机上的模型参数量都小于10M,大语言模型的参数量大了两个数量级,而且未来模型参数量会快速增大。这一方面将会推动手机内存以及接口技术以更快的速度进化——为了满足大模型的需求,未来我们可望会看到手机内存芯片容量增长更快,而且手机内存接口带宽也会加快发展速度,因为目前来看内存实际上是大模型的瓶颈。
除了内存之外,手机芯片上的人工智能加速器也会为了大模型而做出相关的改变。目前手机芯片上的人工智能加速器(例如各种NPU IP)几乎已经是标配,但是这些加速器的设计基本上是针对上一代卷积神经网络设计,因此在设计上并不完全针对大模型。为了适配大模型,人工智能加速器首先必须能有更大的内存访问带宽并减少内存访问延迟,这一方面需要人工智能加速器的接口上做出一些改变(例如分配更多的pin给内存接口),另一方面需要片上数据互联做出相应的改变来满足人工智能加速器访存的需求。
除此之外,在加速器内部逻辑设计上,我们认为可能会更加激进地推进低精度量化计算(例如4bit甚至2bit)和稀疏计算,目前的学术界研究表明大语言模型有较大的机会可以做这样的低精度量化/稀疏化,而如果能量化到例如4bit的话,就会大大减小相关计算单元需要的芯片面积,同时也能减小模型在内存中需要的空间(例如4bit量化精度相对于之前的标准8bit精度就会内存需求减半),这预计也会是未来针对手机端人工智能加速器的设计方向。
根据上述分析,我们预计从市场角度手机内存芯片将会借着手机大模型的东风变得更重要,预计会在未来看到相比之前更快的发展,包括大容量内存以及高速内存接口。另一方面,手机端人工智能加速器IP也会迎来新的需求和发展,我们预计相关市场会变得更加热闹一些。
审核编辑:刘清
-
边缘计算中的AI加速器类型与应用2025-11-06 1136
-
英伟达AI加速器新蓝图:集成硅光子I/O,3D垂直堆叠 DRAM 内存2024-12-13 1339
-
家居智能化,推动AI加速器的发展2024-02-23 6131
-
《 AI加速器架构设计与实现》+第2章的阅读概括2023-09-17 4012
-
Intel媒体加速器参考软件用户指南2023-08-04 865
-
【书籍评测活动NO.18】 AI加速器架构设计与实现2023-07-28 40834
-
使用AMD-Xilinx FPGA设计一个AI加速器通道2023-02-21 1470
-
#硬声创作季 电子制作:磁性加速器Mr_haohao 2022-10-19
-
一个模型带你了解#回旋加速器原理jf_49445761 2022-08-28
-
基于Fast Model的加速器软件开发2022-07-29 3540
-
什么是AI加速器 如何确需要AI加速器2022-02-06 6189
-
高价求购手机内存卡 大量回收手机内存卡2021-10-26 1333
-
手机内存不足的清理方法2020-05-20 10945
-
手机内存2009-12-19 606
全部0条评论

快来发表一下你的评论吧 !
