

APE:对CLIP进行特征提纯能够提升Few-shot性能
描述
本文介绍我们在ICCV 2023上接收的论文《Not All Features Matter: Enhancing Few-shot CLIP with Adaptive Prior Refinement》。这篇文章基于CLIP提出了一种特征提纯的方法为下游任务选择合适的特征,以此来提高下游任务的性能并同时提高计算效率。

论文: https://arxiv.org/pdf/2304.01195
代码: https://github.com/yangyangyang127/APE
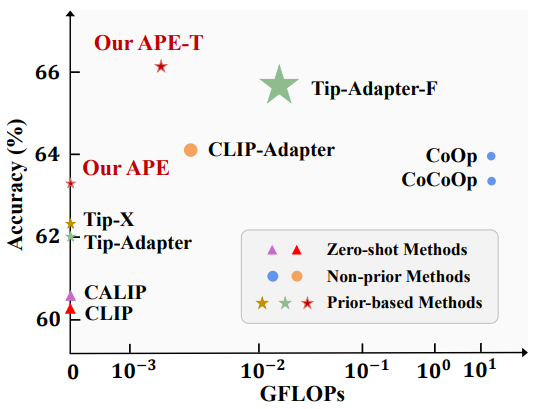
相比于其他方法,我们能够在性能和计算量上实现较好的均衡,如下图所示。
1. 概述
问题:大规模预训练的视觉-文本模型,如CLIP,BLIP等,能够在多种数据分布下表现出良好的性能,并已经有很多的工作通过few-shot的方式将它们应用于下游任务。但这些方法或者性能提升有限(如CoOp, CLIP-Adapter等),或者需要训练大量的参数(如Tip-Adapter等)。因此我们会问,能否同时实现高few-shot性能且少参数量呢?
出发点和思路:CLIP是一个通用的模型,考虑到下游数据分布的差异,对某个下游任务来说,CLIP提取的特征并不全是有用的,可能包含一部分冗余或噪声。因此,在这篇文章中,我们首先提出一种特征提纯的方法,为每个数据集提纯个性化的特征通道,从而减少了参数量,且提升了计算效率;然后设计了一种参数高效的few-shot框架,提升了CLIP在不同数据集上的few-shot性能,下图是论文的整体流程图。
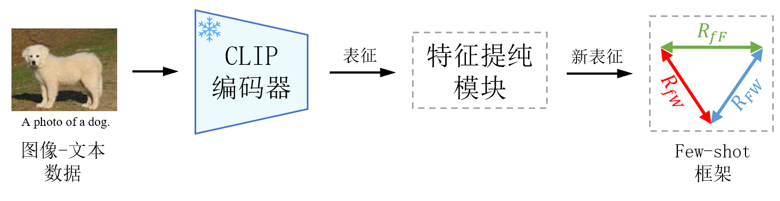
2. 方法
这一部分中,我们分别介绍特征提纯模块和新提出的few-shot框架。
2.1 特征提纯
CLIP是一个通用的模型,在下游任务上,考虑到数据分布,CLIP提取的特征可能并不全是有用的,因此我们试图为每个下游数据集提纯个性化的特征。我们通过最大化类间差异,或者说最小化类间相似度,来选择合适的特征。对于一个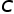 类的下游任务,我们计算所有类的所有样本表征之间平均相似度
类的下游任务,我们计算所有类的所有样本表征之间平均相似度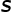 ,
,
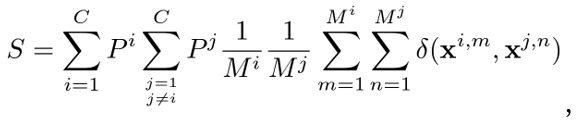
其中,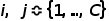 代表类的序号,
代表类的序号,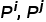 代表两个类的先验概率,
代表两个类的先验概率,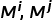 代表两个类中的样本数量,
代表两个类中的样本数量,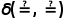 是相似度函数,
是相似度函数,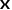 代表表征。假设
代表表征。假设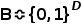 代表特征通道是否被选中,
代表特征通道是否被选中,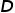 代表特征维度,
代表特征维度,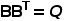 代表预先限制
代表预先限制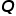 个特征被选中,则通过求解
个特征被选中,则通过求解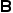 使得最小我们可以得到需要的特征,即求解以下优化问题:
使得最小我们可以得到需要的特征,即求解以下优化问题:
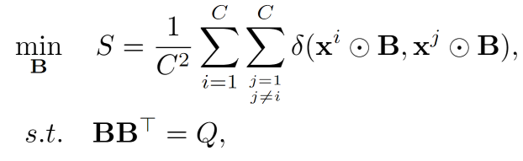
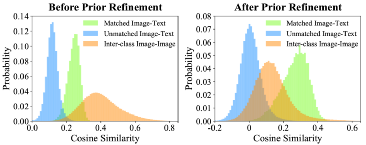
其中 代表逐元素相乘。最后,经过特征提纯,我们在ImageNet上统计了图像和文本相似度的变化,如下图所示。相比于没有特征提纯,我们选定的特征减小了类间相似度,同时增大了图像和文本的匹配程度。且我们提纯出的特征能够获得更好的similarity map。
代表逐元素相乘。最后,经过特征提纯,我们在ImageNet上统计了图像和文本相似度的变化,如下图所示。相比于没有特征提纯,我们选定的特征减小了类间相似度,同时增大了图像和文本的匹配程度。且我们提纯出的特征能够获得更好的similarity map。

2.2 三边关系的few-shot框架
CLIP等视觉文本模型一般基于测试图像和文本表征的相似度或距离来完成分类任。但除此之外,我们还可以使用测试图像和训练图像的相似度来校正,并使用训练图像和文本的相似度来为困难样本提供额外的信息。基于这种考虑,我们探究了测试图像、文本描述和训练图像之间的三边嵌入关系。
假设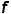 代表测试图像特征,
代表测试图像特征,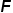 和
和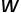 分别代表训练图像和文本描述的特征,
分别代表训练图像和文本描述的特征,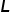 代表训练图像的label,则我们可以建立三边关系,
代表训练图像的label,则我们可以建立三边关系,
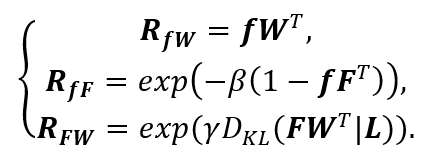
其中,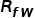 代表一般的CLIP基于视觉文本相似度的预测,
代表一般的CLIP基于视觉文本相似度的预测,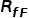 代表模态间的相似度,即测试图像和训练图像之间的相似度,
代表模态间的相似度,即测试图像和训练图像之间的相似度,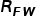 反映了训练图像对测试图像的贡献。基于以上三种关系,可以得到最终的预测为
反映了训练图像对测试图像的贡献。基于以上三种关系,可以得到最终的预测为
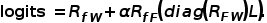
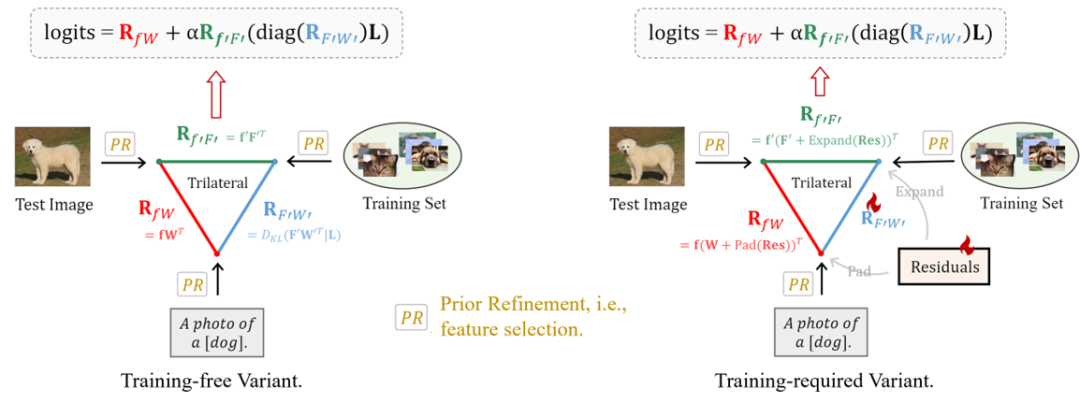
我们可以将特征提纯与三边关系结合起来,直接在选择出来的特征上进行三种关系的few-shot学习,这样可以减少参数和计算效率。我们提出了training-free和training-required两种框架,如下图,后者相比于前者增加了少量可训练的残差。
3. 结果
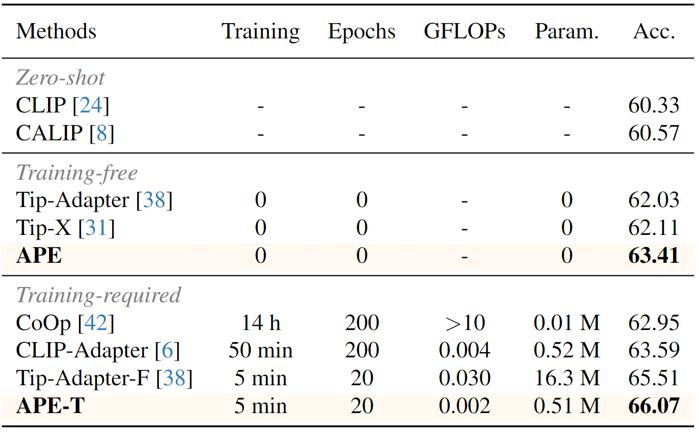
我们在11个分类数据集上研究了方法的性能,并提出了training-free和training-required两个版本,下图是11个数据集上的平均性能以及和其他方法的比较。
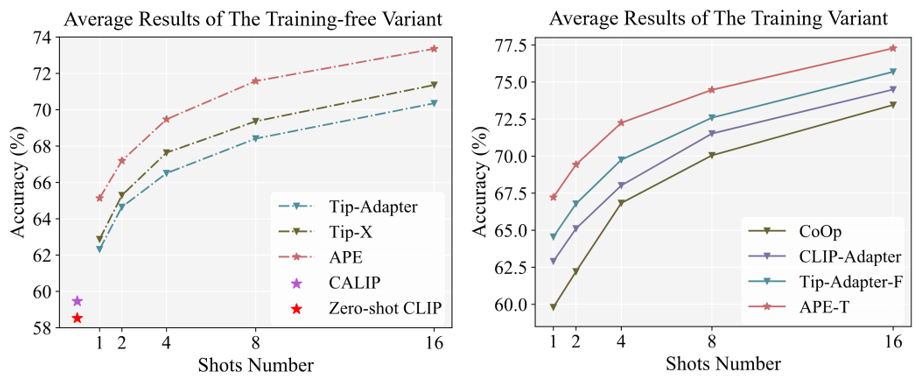
与其他方法相比,我们的计算效率和参数量都有所优化。
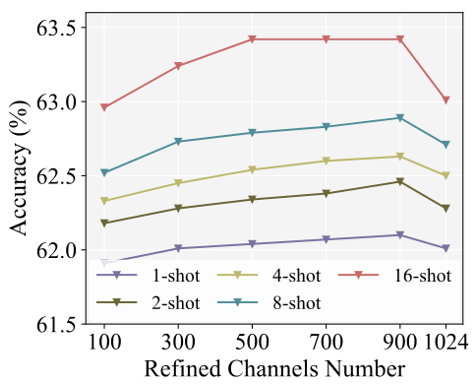
提纯的特征通道的数量对结果也有所影响:
感谢您的阅读,更多的实现细节和比较请看我们的文章,我们的代码已开源。感谢您提出宝贵意见。
-
1688 多模态搜索从 0 到 1:逆向接口解析与 CLIP 特征匹配实践2025-10-17 1696
-
更强!Alpha-CLIP:让CLIP关注你想要的任何地方!2023-12-10 2310
-
基于显式证据推理的few-shot关系抽取CoT2023-11-20 2117
-
语言模型性能评估必备下游数据集:ZeroCLUE/FewCLUE与Chinese_WPLC数据集2023-03-27 3133
-
使用MobileNet Single Shot Detector进行对象检测2022-11-09 604
-
介绍一个基于CLIP的zero-shot实例分割方法2022-10-13 6557
-
基于将 CLIP 用于下游few-shot图像分类的方案2022-09-27 6990
-
介绍两个few-shot NER中的challenge2022-08-24 1621
-
基于特征点精度提纯的图像配准改进算法2017-01-07 894
全部0条评论

快来发表一下你的评论吧 !
