

Unix操作系统及其文件系统讲解
嵌入式技术
描述
与大家分享一组文件系统考古文章
开篇将带大家回到1974年,
从Unix V7 文件系统开始。
有时,进步难以察觉,特别是当你正身处其中时。而对比新旧资料之间的差异,寻找那些推动变革的信息源,我们就可以清晰地看到进步的发生。在Linux(以及大部分Unix系统)中,都可以印证这一点。
Unix V7 是 Unix 操作系统的一个重要的早期版本,于 1979 年发布,是贝尔实验室最后一个广泛分发的版本。它是第一个真正可移植的 Unix 版本,被移植到了多种平台上,包括 DEC PDP-11, VAX, x86, Motorola 68000 等。Unix V7 的 VAX 移植版本,叫做 UNIX/32V,是流行的 4BSD 系列 Unix 系统的直接祖先。许多老牌的 Unix 用户认为 Unix V7 是 Unix 发展的顶峰。
Unix V7 Research Release 的源代码可以在 unix-history-repo^[3]^ 这个由 Diomidis Spinellis 维护的项目中找到。如果你想深入了解 Unix 的设计原理,可以参考 Maurice J. Bach 的经典著作 The Design of the Unix Operating System^[4]^,并查看 Research V7 Snapshot^[5]^ 这个分支的代码库。
Ken Thompson (坐着的) 和 Dennis Ritchie 在小型计算机 PDP-11 上工作,他们是贝尔实验室(Bell Labs)的研究员,在20世纪70年代早期开发了Unix操作系统及其文件系统。
Machines
1974 年,计算机拥有一个“核心”,即中央处理单元。然而,在某些计算机中,这个“核心”已经发生了变化。不再是由多个部件(如算术逻辑单元、寄存器、顺序控制器和微码存储器)组成的设备,而是一颗单一的集成芯片,单个芯片上集成了数千个晶体管。它们被叫做“小型计算机”。
Kernels
在 Unix 中,我们通过配置头文件(header file)来处理系统资源。如下图所示,这里显示了头文件中配置的默认值^[6]^,数据结构是数组,所示值是相应的数组大小。如果要更改它们,则需要编辑文件,重新编译和链接内核,然后重新启动系统。

它有一个文件系统缓冲区缓存(file system buffer cache),使用 NBUF(29)个磁盘块,每个磁盘块的大小是 512 字节,用来暂时存储磁盘上的数据块和 inode,从而加速文件系统访问。另外还有一个索引节点数组(inode array),它有 NINODE (200)个条目,每个条目对应一个文件的元数据,还可以同时挂载 NMOUNT (8)个文件系统。每个用户最多可以运行MAXUPRC(25)个进程,总共有 NPROC(150)个系统进程。每个进程最多可以打开 NOFILE(20)个文件。
阅读 Bach 的著作和 V7 源代码是很有趣的,尽管它们已经完全过时。因为这些源代码中呈现出的许多核心概念更加清晰,结构更简洁,有时甚至带有古老的风格。然而,正是这些概念定义了 Unix 文件系统。V7 Unix 被写入了 POSIX 标准,之后的每个文件系统都必须遵守它。如果您想了解更多相关示例,请参考 But Is It Atomic?^[8]^
核心概念
Unix 文件系统的基本概念和结构来自这个系统。其中一些概念甚在现代系统中依然存在。
磁盘由一系列数据块(block)组成,从第 0 块开始,一直到第 n 块结束。在文件系统的开始部分,我们可以找到超级块(superblock)。它位于文件系统的第 1 块。超级块存储了文件系统的一些基本信息,比如文件系统的大小、空闲块的数量、空闲索引节点的数量等。当我们执行挂载(mount)系统调用时,系统会找到一个空闲的挂载结构(mount structure^[8]^),并且从磁盘上读取超级块,把它作为挂载结构的一部分。
Inode
内存中的超级块(in-memory superblock)是磁盘上超级块的副本,用于加快文件系统的访问速度。它包含一个 short 类型的字段,用于存储一个索引节点数组(inode array)在磁盘上的位置。
索引节点(inode^[9]^)是一个描述文件内容和属性的结构,文件内容由一系列数据块(block)组成,每个数据块的大小是固定的(通常是 512 字节或 1024 字节),文件属性包含文件名、大小、权限、时间戳等元数据(metadata)。

磁盘上的 inode 如上图所示。每个 512 字节的磁盘块可以容纳 8 个 inode,因此它们在 64 字节边界上对齐。
文件系统中的 inode 数组是一个 short 类型的计数器,它的最大值是 65535,也就是说文件系统中最多只能有 65535 个 inode。由于每个文件都需要一个 inode,因此每个文件系统最多只能容纳 65535 个文件。
每个文件具有一些固定属性:
(2字节)mode,它包含了文件的类型和访问权限;
(2字节)nlink,它表示这个文件有多少个名字;
(2字节)uid,文件的所有者;
(2字节)gid,文件所有者的组 ID;
(4字节)size,文件的长度,以字节为单位(定义为 off_t,长整型);
(40字节)addr 数组,包含了文件的数据块在磁盘上的地址;
(3x 4字节)三个时间,atime(访问时间),mtime(修改时间)和 ctime(所谓的创建时间,但实际上是最后一个 inode 更改的时间)。
总大小为 64 字节。
bmap()
Addr 数组包含 40 个字节,但它存储了 13 个磁盘块地址,每个地址使用 3 个字节。这对于 24 位来说非常适用,或者说对应于 16 个大小为 512 字节的兆块,总文件系统大小为 8M 千字节,即 8GB。
小型计算机 PDP-11 RL02磁盘驱动器的前面板 (来自 pdp-11.nl [10])
PDP-11 RL02K磁盘盒^[11]^可容纳 10.4 MB,而更新的 RA92^[12]^ 可存储 1.5 GB。
Addr 数组在 bmap()^[13]^ 函数中被使用。该函数接收一个 inode(ip)和一个逻辑块号 bn,并返回一个物理块号。也就是说,它将文件中的一个块映射到磁盘上的一个块,因此得名。
前 10 个块指针直接存储在 inode 中。例如,要访问块 0,bmap() 将在 inode 中查找^[14]^ di_addr[0] 并返回该块号。
额外的块存储在一个间接块中,而间接块则存储在 inode 中。对于更大的文件,会分配一个双间接块,并指向更多的间接块,最终非常大的文件需要甚至三次间接块。
代码首先确定需要多少层间接寻址^[15]^,也就是要通过多少个间接块才能找到文件内容的磁盘块。然后,获取相应的间接块^[16]^。最后,代码按照适当的次数解析间接寻址^[17]^,也就是根据层数依次从间接块中读取其他间接块或直接块的地址,直到找到文件内容的磁盘块。
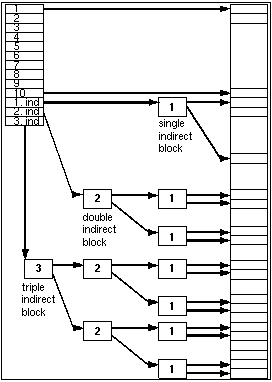
对于越来越大的文件,原始的 Unix 文件结构采用了逐渐增加的间接访问次数。这样形成了一个压缩的数组,其中较短的文件可以直接通过 inode 中的数据进行访问,而较大的文件则需要通过越来越多的间接访问来获取数据。为了提高性能,保持间接块在文件系统缓冲区高速缓存中是至关重要的。
这种扩展性取决于块大小(早期为 512 字节,现在为 4096 字节)和块号的字节大小(最初为 3 字节,后来为 4 字节甚至 8 字节)。
Atomic writes
文件的写入是在加锁的状态下进行的,因此它们始终具有原子性。即使是跨越多个数据块的写入操作,也是如此。这一点在 But Is It Atomic?^[18]^ 中有详细讨论。
这也意味着即使有多个写入进程,在单个文件上,任何时刻只能有一个磁盘写入操作处于活跃状态。这对数据库系统的开发者来说非常不便利。
Naming files
目录是一个具有特殊类型和固定记录结构^[19]^的文件。

一个目录条目包含一个inode号(一个无符号整数)和一个文件名,文件名的长度最多可以达到14个字节。这使得一个磁盘块可以容纳32个目录条目,而一个目录文件的直接块可以引用的10个磁盘块可以容纳320个目录条目。
下层(lower)的文件系统中充满了大量的文件。这些文件没有名称,只有编号。
上层 (upper)的文件系统使用一种特殊类型的文件,具有简单的16字节记录结构,用于为文件分配最多14个字符的名称。一个特殊的函数namei()将文件名转换为inode号。
传递给namei()的路径名具有层次结构:它们可以包含/作为路径分隔符,并以�(NUL)作为终止符。路径名若以/开头,则遍历将从文件系统的根目录开始,形成绝对路径名;若不以/开头,则遍历将从u.u_cdir,即当前目录开始。
该函数逐个消耗路径名的各个组成部分,使用当前活动目录,并在该目录中线性搜索当前组件的名称。当找到最后一个路径名组件或在任何阶段找不到组件时,该函数结束。如果在路径中的任何目录的任何点上,我们没有 x 权限^[20]^,它也会结束。
该函数按顺序逐个处理路径名的各个组成部分。它使用当前目录,并在该目录中线性搜索当前组成部分的名称。函数的结束条件有两种情况:一是找到了路径名的最后一个组成部分,二是在路径的任何目录中,出现了无法访问^[21]^的情况。
挂载点是特殊条目^[22]^,它会从当前节点和文件系统的目录条目切换到挂载文件系统的根inode。这使得Unix中的所有文件系统看起来像是一棵单一的树,如果要进行"硬盘修改"的操作,只需简单地切换到不同的目录。
最终,该函数将返回给定路径名的inode指针,根据需要和需求创建(或删除)inode(和目录条目)。它是目录遍历和访问权限检查的集中点。
一些创新的想法以及限制
这个早期的Unix文件系统具有许多很好的特性:
它将多个文件系统呈现为一个统一的树形结构;
文件是无结构的字节数组;
这些数组以可动态增加深度的动态数组的形式存储。它们内部使用一种逐渐嵌套的间接块系统,其中数组的元素可以是指向其他数组或数据的指针,从而形成层次嵌套的结构。这使得磁盘搜索的复杂度为O(1);
下层文件系统创建文件和上层的文件系统组织文件互相隔离,分工明确。获取inode的唯一方式是路径名遍历,并且在此过程中始终检查权限;
文件名中只有很少的特殊字符,即/和�(空字符)。
但也有明显的限制:
文件只能有16M个块;
文件系统只能有非常有限的65535个inode。
还有一些令人讨厌的限制:
文件只能有一个正在写入的进程,这会导致并发性受限;
目录查找是线性扫描,因此对于大型目录(超过320个条目),速度变得非常慢;
没有强制文件锁定系统。但存在几种用于咨询式文件锁定的系统。
还有一些特殊情况:
在 Unix V7 系统中,没有 delete() 系统调用,而是 unlink() 系统调用,它可以删除一个文件的名字,并且那些没有任何文件名和打开文件句柄的文件会被自动清理。这会导致一些不符合预期的结果,例如,只有当一个完全没有文件名的文件被完全关闭时,它占用的磁盘空间才会被释放。许多 Unix 系统管理员都曾经问过他们的磁盘空间去哪了,当他们删除了 /var/log 目录下的日志文件,却忘记了有一些进程还在使用它;
最初没有 mkdir() 和 rmdir() 系统调用,这导致了存在可被利用的竞态条件。竞态条件是指在多线程或多进程环境中,由于操作的顺序和时机不确定性,可能导致安全漏洞或错误行为的情况。这在 Unix 的后续版本中得到了修复;
有一些操作在特定条件下具有原子性(例如write(2)系统调用),或者经过修改后具有原子性(mknod(2)和mkdir(2))。
在结构上,inode表和块和inode的空闲映射位于文件系统的开头,磁盘空间也是从磁盘的前端线性分配的。这导致了频繁的寻址操作,并且可能导致文件系统的碎片化(即文件存储在非相邻的块中)。
遍历目录结构意味着从磁盘开头读取目录的inode,然后向后移动到更远的数据块,再从磁盘开头读取下一个路径名组成部分的下一个inode,并向后移动到相应的数据块。这个过程在每个路径名组成部分上来回进行,速度并不快。
改进
在之后的发展中,minix文件系统忠实继承了PDP-11 V7 Unix文件系统,保留了它的特性包括局限。然而,随着时间的推移,在现代的Linux系统中,由于其不再具备实用性,它已经从内核源代码中移除。
在稍后的一篇文章中,我们将会了解到关于BSD快速文件系统,如何更好地布局磁盘上的数据,如何实现更长的文件名、更多的inode,以及如何通过考虑磁盘的物理特性来加快速度。
要解决目录查找时间线性增长、单个写入者或有限的文件元数据这些问题需要更新的文件系统。
审核编辑:汤梓红
-
#硬声创作季 #操作系统 操作系统-31 目录与文件系统-2水管工 2022-11-04
-
Linux操作系统和文件系统的相关资料分享2021-12-16 898
-
什么是UNIX操作系统呢2021-11-04 1125
-
inode是理解Unix/Linux文件系统和硬盘储存的基础2021-04-04 2780
-
从vista、UNIx和Linux说起全面讲解操作系统2021-03-26 922
-
unix是什么操作系统_unix操作系统怎么安装2020-09-02 26245
-
请问操作系统中的文件系统是什么?2019-09-18 3369
-
unix操作系统有哪些2017-11-14 52948
-
【图书分享】《UNIX 操作系统设计》2014-03-21 3910
-
Linux源码分析系列之文件系统2011-11-03 599
-
见证Unix操作系统发展历史2010-01-29 1031
-
恢复Unix系统被删除地文件2010-01-11 1154
-
UNIX操作系统类型2009-12-26 2413
全部0条评论

快来发表一下你的评论吧 !
