

基于实时计算的汽车零件订单履行状况监控系统的设计与实现
描述
汽车零件订单履行是产销协同业务模式中重要的一环,过程中出现的异常状况(简称异况)如果不及时告警并后续调整,将会导致最终生产计划延期。本文提出了一种汽车零件订单履行状况实时监控告警的方法,通过实时监控过程异况,对异况根因实时分析,以便及时告警和调整后续节点过程,能最大限度规避生产计划延期风险。本文针对 Kubernetes 集群节点磁盘 I/O 及网络负载过大时,出现节点资源使用率和 Flink 任务运行效率降低的问题,提出了一种新的 Kubernetes 资源调度算法,通过实验论证,最终实现了更好的资源弹性伸缩效果,为营销业务模式的转型提供了更为可靠的技术支持。
引言
随着数字化浪潮席卷全球,汽车产业外部环境日趋复杂严峻,传统生产、制造及服务模式都面临着前所未有的挑战。汽车产业从依靠增量发展的阶段迈入了存量调整的时代,行业提质增效与转型升级已成为趋势。在新形势下,大数据开发和应用对汽车行业生态链,带来了机遇和挑战。
为了接近用户,拥有越来越多的用户去开拓市场,期望最终去提升产品销量,产销一体化成为了汽车营销的新模式。产销一体化中,生产制造是重要的组成部分,其中,汽车零件订单履行又是重中之重。汽车零件从下单到收货,是一个种类繁多、数目庞大、结构复杂及精细化程度高的物流过程。既要保证汽车零件订单履行的高效准确,又要控制降低相应成本投入,变成了汽车行业企业和个人日益关注的焦点。
除开业务模式上的变化,整条过程链路的数据类型也发生了改变。其中不再全部都是离线数据了,实时数据也越来越多。由此对实时数据的实时计算是必不可少的环节。
本文为了规避因汽车零件订单履行异常状况(下文简称异况)导致生产计划延期风险,基于 Flink 流处理引擎设计并实现了汽车零件订单履行状况监控系统。围绕汽车零件订单履行过程,构建订单的 One ID 数据模型,实现对订单生命周期管理、订单履行异况判定和订单履行监控告警。通过在 Kubernetes 默认调度器调度的各个阶段埋点测试后 , 优化了主要性能瓶颈的优选阶段。提出了一种改进后的 Kubernetes 资源调度算法,经过实验测试验证,相较 Kubernetes 默认资源调度算法,其对 Flink任务的运行性能和节点资源使用率有一定的提升。
目前国内外对于汽车零件物流的研究较为丰富。丁则宇将质量管理领域应用较广的鱼骨图分析法,引入到对汽车零件物流成本控制的影响因素分析中,并针对汽车零件物流成本的控制,提出了对储存与运输成本进行控制的策略。钟慧甄以一家汽车制造厂为研究对象,通过分析其精益供应链中汽车零件进口的管理现状,提出敏捷物流在其进口操作中的应用方案,使精益与敏捷相结合,达到降本增效的目的。周豪等针对传统采购平台的局限性,以供应商产能、项目供方唯一性、产品质量、产品按时到货率和价格折扣为约束,建立了 3 目标的 0 到 1 整数规划模型。针对该模型,设计了改进的混沌优化算法进行求解,有效解决了传统多目标优化过程中参数难以选择的问题,避免了人为干预。陈宇丹在考虑供应数量不确定性以及新能源系列零件采购特征的基础上,构建了新能源系列零件订单分配的多目标模型,并运用模糊数和构建隶属度函数从解集中丰富的新能源系列零件订单的分配方案选出最符合经营目标的分配方案。
目前 Kubernetes 的调度还存在有待提升的方面。Dong Li等提出了一种平衡磁盘 I/O 优先级的动态算法来改善节点之间的磁盘 I/O 平衡,和一种平衡 CPU 和磁盘 I/O 优先级的动态调度算法来解决单个节点上 CPU 和磁盘 I/O 负载不平衡。Gengsheng Zheng等提出了一种基于 Docker 集群的自定义 Kubernetes 调度器的调度策略,其可帮助节省更多的系统调度资源,提高集群调度的公平性和效率。Zhiheng Zhong等提出了一种容器化任务协同定位调度器,采用弹性任务协同定位策略来提高资源利用率,支持动态任务重新调度,有效防止频繁的任务逐出导致严重的 QoS 降低。Fabiana Rossi等提出了一种依赖于 Kubernetes 并通过自适应和网络感知放置功能对其进行扩展的编排工具,该工具考虑了计算资源之间不可忽略的网络延迟,以满足对延迟敏感的应用程序的服务质量要求。
动机
汽车零件物流是汽车零件供应商的运输供应物流,也是指上游供应商向整车厂提供汽车零件、生产材料和辅料到整车厂的仓库入口的流程。
汽车零件物流具备几个特点:
1)准时性。一般来说,汽车装配线的生产节拍是20 ~ 40 辆 /h,每种车型的装配零件是 3 000 多种。生产线旁的物流位置有限,需要连续不断地向生产线准时供货,但汽车零件物流过程会面临零件数量大和长距离运输等问题,所以供货的准时性决定了生产的准时性。
2)准确性。汽车装配的准确性是整车装配质量最基本的保证。在一条装配线上,混流装配 2 个或 2 个以上平台、十几种配置的汽车,上万种零件准确地送到消耗点,是物流配送的难点,它需要配送商对汽车生产有深刻的了解和丰富的经验。
3)质量保证性。汽车零件的质量是汽车质量的基本保证。零件在运输、搬运、更换包装容器和仓储的物流活动中,必须追求物流服务的质量。
目前汽车零件物流运输方式可分为 2 种,一种是直接运输,当供应商单次发货量比较大,能够形成一定的规模数量时,采用直接在供应商处将零件装载完毕后再直接送到主机厂的运输模式。这种运输方式的特点是能设定更便宜的费用,没有因重新装载而造成的损害,运输时间比较短。但会出现“高装载低频次”或“低装载高频次”的情况,从而导致仓储成本或运输成本增加。
另一种是混载运输,如图 1 所示,混载运输在路径联运上的表现形式是牛奶运输方式或设立中转仓库的形式,在装载形式上的表现是内外制件混载、不同材质的混载。混载运输方式与直接运输方式相比,不足之处是运输费用较高,由于运输地点较多,需要的时间比较长,其优点是能实行小量、多厂家运输,能实现中转仓库等干线的长距离运送。
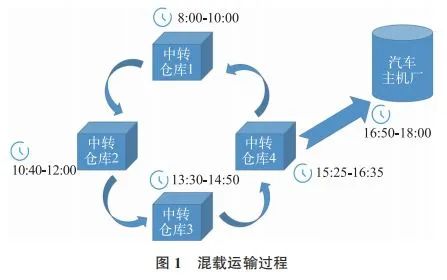
汽车零件订单履行精细化运营
3.1 数据采集接入
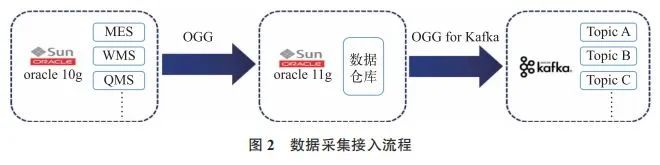
实际工作生产中,汽车零件订单需要和企业内部诸多生产制造相关系统产生关联关系,包括 MES(制造执行系统)、WMS(仓库管理系统)和 QMS(质量管理系统)等。这些生产制造系统的数据总量大、数据变动频次高及数据变动量大,平均日均数据变动总量能达到 TB级。这些生产制造系统的数据都存储在传统 Oracle 关系型数据库中,如果直接使用 Oracle 数据库去做数据关联,往往会因数据库性能瓶颈而出现“慢”和“失败”的情况。因此,在数据采集过程中,需要一个数据缓冲层,用于先把变动数据都存储下来。
Kafka 是一种高吞吐量的分布式发布订阅消息中间件,它可以处理消费所有变动的实时数据。Kafka 支持多主题多分区,能为多生产者生产数据,多消费者消费数据,具备高吞吐低延时、可拓展和持久可靠等优势,提升了并行处理大规模变动数据的能力。
由于数据源是存放在 Oracle 10g 中,和已有的 Kafka版本不兼容,所以 Oracle 10g 的源数据需要使用 OGG(Oracle GoldenGate)实时同步至 Oracle 11g 数据仓库中,然后 Oracle 11g 数据仓库中的数据再使用 OGG for Kafka实时同步至 Kafka 相应的 Topic 中,以供后续下游去消费,如图 2 所示。
3.2 数据实时处理
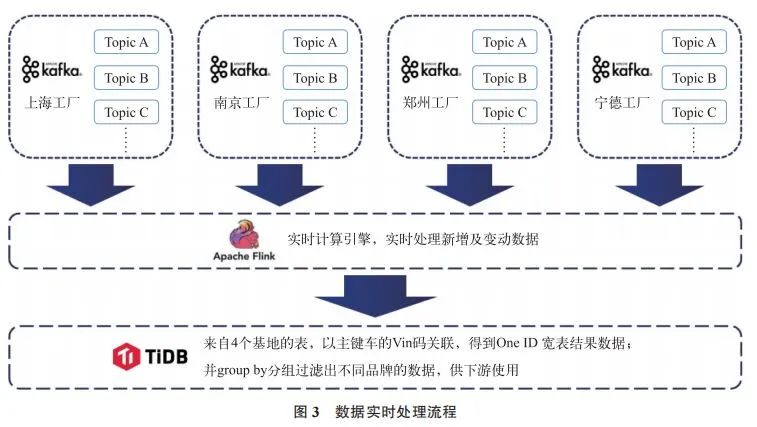
将各业务系统中的变动数据实时采集到 Kafka 后,下游将通过 Flink 实时计算引擎去处理及关联,最终得到以 One ID 为标准的结果数据。
One ID 把不同时期孤立建设的系统,用统一的 ID 串联起来,就可以更全面、更完整地了解数据本身,能够更加精准地评价数据的价值,为精细化运营夯实数据基础。
TiDB 是一款联机事务处理和联机分析处理的融合型数据库产品,实现了一键水平伸缩、强一致性的多副本数据安全、分布式事务和实时 OLAP 等重要特性。同时兼容 MySQL 协议和生态,迁移便捷,运维成本极低。
如图 3 所示,在实际情况中,有上海、南京、郑州和宁德 4 个工厂的生产制造数据,所以从 Oracle 数仓同步到 Kafka 有 4 份 Topic。通过 Flink KafkaConsumer 去实时处理新增及变动数据,将来自 4 个生产基地的数据,以主键车的 Vin 码(车辆识别代码)关联起来,最终得到 One ID 宽表结果数据存放在 TiDB 中,并分组过滤出不同品牌的数据,供下游使用。
3.3 汽车零件订单履行异况处理
(1)订单异况责任判定规则 汽车零件订单履行链路过程主要包含订单确认、供应商备货、自运发货、MR 提货、TDS 入厂和道口收货 6 个主要流程节点。
整个链路过程中,将会在每个节点进行到达时间、离开时间、零件数量和型号及零件质量状况的确认,这些确认情况都将会第一时间更新到业务系统数据中。实际汽车零件物流运输方式是混载运输,由于运输地点较多、时间长,订单异况的责任判定是必要的。
订单异况的责任主要分为时间计划延误、零件装配错误和零件破损 3 类。对于时间计划延误责任,如果当前节点到达时间晚于计划应到时间,将会追究上一节点承担方责任。如果当前节点离开时间晚于计划离开时间,将会追究当前节点承担方责任。对于零件装配错误和零件破损,如果当前节点收货前检查发现零件装配错误或零件破损,将会追究上一节点承担方责任。以上 3 种责任如果有连锁连带责任情况,都将会以首次发生责任的承担方判定为主。
汽车主机厂会和各物流承运商签订的合同中详细界定责任范围。物流运输途中发生异常状况都将由对应环节的物流承运商负责,零件到了中转节点之后将由专人验收和签署回单,专门人员会将相关零件信息录入更新至业务系统中。
(2)订单异况根因分析 1)异况知识图谱。零件订单在履行过程出现异况时,相关节点人员会将异况和原因录入到系统中,但由于人员文本描述情况不同,无法做到快速明确异况根因,此时需要建立相关知识图谱。
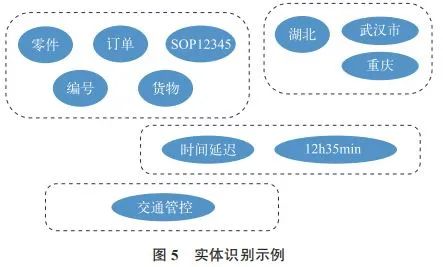
实体抽取要从文本数据集中自动识别出命名实体。实体抽取的质量对后续的知识获取效率和质量影响极大,是信息抽取中最为基础和关键的部分。初始业务系统数据库中节点人员录入的描述信息,首先会使用 CRF 对实体边界进行识别,如图 4 所示。

采用自适应感知机算法实现对实体自动分类,最终可以对图 4 所示的描述信息识别出实体并进行分类,如图 5 所示。
文本语料经过实体抽取,得到的是一系列离散的命名实体,为了得到语义信息,还需要使用高斯核函数提取出实体之间的关联关系,才能够形成网状的知识结构。如图 6 所示。
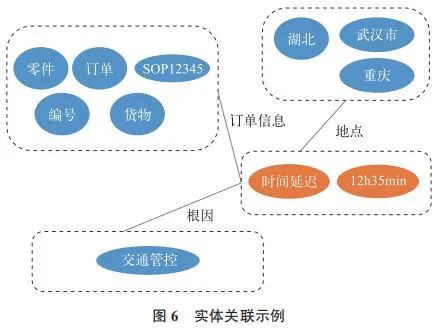
2)异况根因查询及更新。对建立好的异况知识图谱,会以异况、关系和异况根因三元组形式存储到关系型数据库中。
其中通过订单编号查询异况跟因,如果异况知识图谱有数据新增、更新和删除,将通过增量的方式进行人工干预。
3)异况告警。零件订单状态监控系统会将出现的异况第一时间告警至涉及人员,并基于异况根因分析情况进行后续的调整,力争不会对主机厂最终的生产计划造成影响。
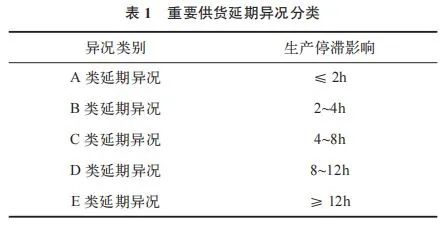
零件订单履行异况产生的供货延期主要分为 3 类。第一类是一般供货延期,是指影响到正常的库存量,但未对主机厂造成实际影响的供货延期。第二类是重要供货延期,是指影响到主机厂正常的生产计划,使生产计划延期完成或需调整生产计划的供货延期,其分类见表 1。第三类是严重供货延期,是指影响到主机厂正常生产计划的完成,同时影响到主机厂销售计划的供货延期。
改进的资源调度算法
4.1 算法设计
通过在本地 Kubernetes 集群加入性能测试集,对Kubernetes 默认调度器调度的各个阶段进行埋点测试。最终定位到主要的瓶颈是在优选阶段。
假定集群中 Pod 总数为 Np,平均每个 Pod 的AffinityTerm 数为 3,经过预选后的节点数为 Nn,节点的label 个数为 6,所有 Pod 中,与待调度 Pod 匹配的同组Pod 数为 Nsp,则优化后的优选算法复杂度为
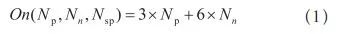
为了进一步更加直观的分析优化效果,假定集群总节点数为 N,每个节点上平均有 30 个 Pod,进入优选阶段的节点比例为 a,则可以得到:
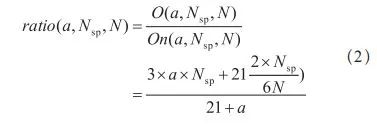
若假定 Nsp 及 a 为常数,则随着集群规模 N 增大,计算复杂度的优化倍数很快会收敛。
4.2 算法流程
Kubernetes 默认调度器 kube-scheduler 在优选时会调用自定义扩展程序进行给节点打分。优化后的优选算法执行流程如下:
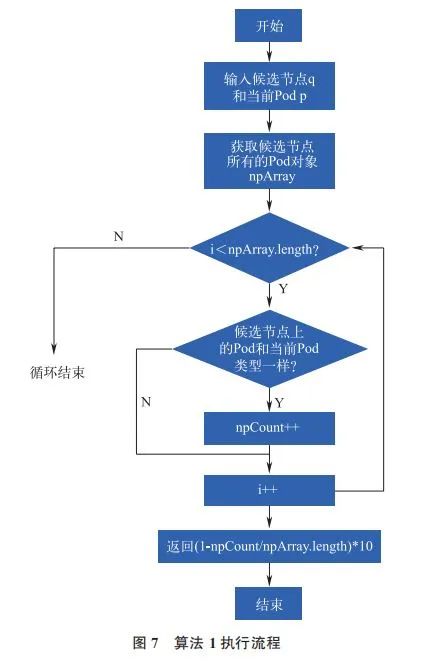
1)算法 1。根据每个节点上存在当前 Pod 对象类型的数量,计算节点分数,执行流程如图 7 所示。
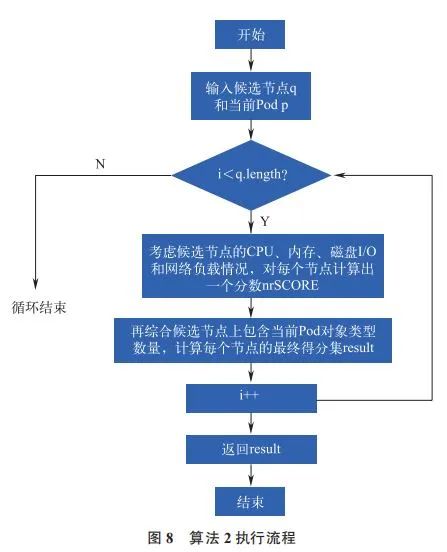
2)算法 2。根据每个节点上资源负载情况,计算节点的最终分数,执行流程如图 8 所示。
实验对比与分析
5.1 订单履行异况知识图谱测评
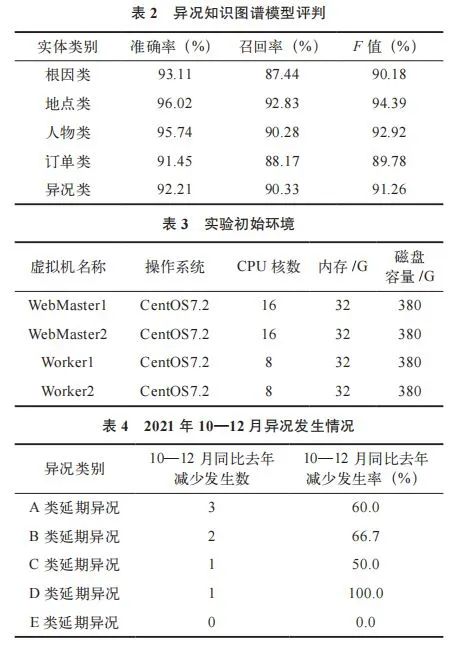
使用 20 000 条异况描述训练语料进行实体和关系抽取,构建异况知识图谱模型。以准确率、召回率和 F 值3 个指标来评估异况知识图谱模型的实际效果。验证结果见表 2。
5.2 订单履行状态监控系统测评
零件订单履行状态监控系统通过虚拟机本地部署,实验初始环境见表 3。选取对比了 2020 年 10—12 月零件订单履行情况,有效降低了异况的发生,减少了对生产计划的影响,具体情况见表 4。
5.3 Flink 资源调度改进算法测评
采用 Flink 1.12 和 Kubernetes 1.15 版本,Kubernetes通过虚拟机本地部署,集群初始共有 2 个 master 和 4 个worker 共 6 个节点,配置见表 5。
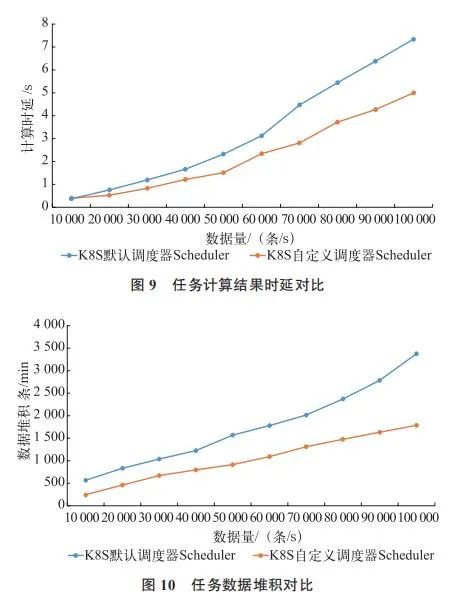
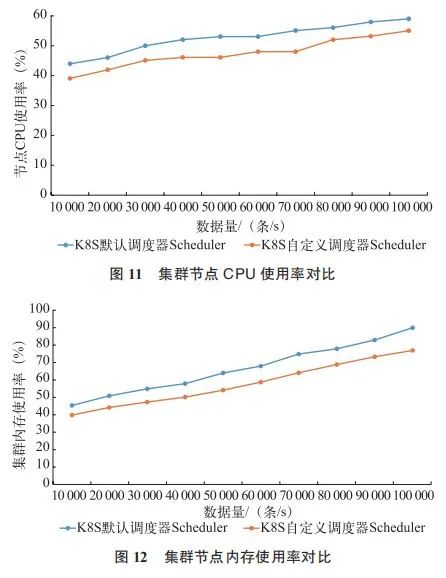
在数据量增大时,Flink 测试任务的计算结果时延、数据堆积、集群节点 CPU 使用率和内存使用率对比结果如图 9、图 10、图 11 和图 12 所示。从实验结果上来看,通过自定义优选调度算法,对任务运行性能和集群资源使用率上均有一定程度的提升,验证了本文方法的有效性。
需要说明的是,上述对比分析结果在程序中的实际表现会受到其他很多因素的影响导致偏差,但仍可以作为参考。
总结及展望
本文提出了一种实时监控汽车零件订单履行异常状况的方法,通过将业务系统数据实时同步至消息队列 Kafka中,并由 Flink 消费和实时计算,连接形成 One ID 标准的宽表结果数据,存放在 TiDB 中。对宽表结果数据中异况描述文本进行实体和关系的抽取,构建出零件订单履行异况知识图谱,最终基于异况知识图谱,实时分类得到异况根因,可以提前告警并及时规避生产计划的延期风险。实验表明,零件订单履行异况知识图谱在实际业务数据测试中,相关模型评价指标表现良好,同比去年同期未应用零件订单履行状况监控系统情况,由于零件订单履行异况而造成生产计划延期事件的发生次数和比例有所降低。
通过对Kubernetes默认调度器调度各阶段埋点测试,找到了需要优化的性能瓶颈。基于 Kubernetes 集群节点CPU、内存、磁盘 I/O 和网络负载情况,并考虑了节点上当前 pod 对象类型的数量,提出了一种新的优选阶段调度算法,最后通过实验对比分析,验证了算法的有效性。
-
Modbus转Profinet网关在汽车零件生产中的应用2023-11-17 1107
-
汽车制冷系统有哪些零件组成?汽车制冷系统的组成与工作原理2023-07-31 4255
-
实时计算汽车数量开源分享2023-06-28 732
-
全自动影像测量仪把控汽车零件尺寸细节,保证整车品质和性能2023-03-29 1384
-
PPI转以太网模块通过XD1.0替代EM277模块在汽车零件组装系统中的应用2022-08-10 2047
-
怎么实现汽车运行状况图像监测系统的设计?2021-05-18 2036
-
利用废弃的3D打印粉末和零件来制造注塑汽车零件2021-04-06 2885
-
汽车零件设计技术的振动性能研究2020-04-06 1360
-
基于Data Matrix的汽车零件管理系统2017-12-20 1082
-
三维检测汽车零件 帮助汽车性能达标2017-08-21 2698
-
小小零件,大大左右之AS50452014-03-26 3133
-
2012埃及汽车维修工具展/2012汽车零件展 埃及汽配展2012-05-03 1893
-
2012埃及汽车维修工具展/2012汽车零件展2012-04-28 1698
-
现代汽车全力发展尖端汽车电子零件2012-03-28 1061
全部0条评论

快来发表一下你的评论吧 !
