

gpt-4怎么用 英特尔Gaudi2加速卡GPT-4详细参数
人工智能
描述
在2023 人工智能大会上,据统计,有 24 款大模型新品在大会上发布或升级,发布主体不仅包括互联网龙头企业,也包括移动联通等运营商、创业公司及各大高校。 与国内大模型产品相比,chatGPT 效果依然最优。根据 InfoQ 数据显示,chatGPT 在大模型产品测评中分数最高,综合得分率为 77.13%,国内大模型产品文心一言正迅速追赶,在国内大语言模型中位列第一。
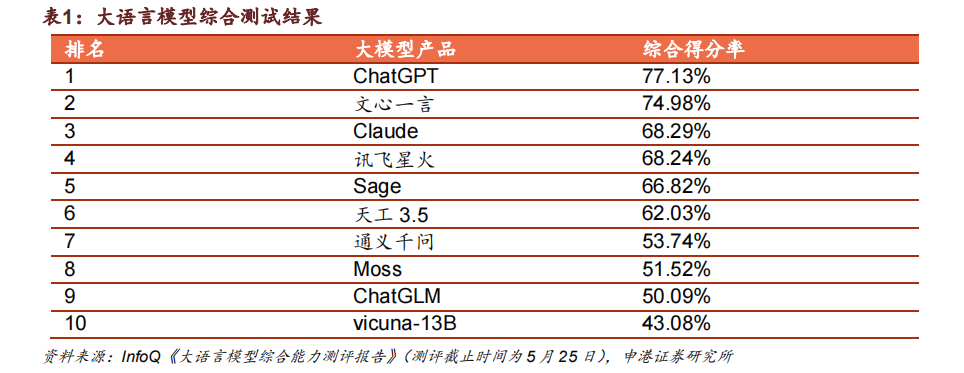
介绍GPT-4 详细参数及英特尔发布 Gaudi2 加速器相关内容,对大模型及 GPU 生态进行探讨和展望。英特尔发布高性价比Gaudi2加速卡GPT4详细参数分析。 与国内大模型产品相比,chatGPT 效果依然最优。根据 InfoQ 数据显示,chatGPT 在大模型产品测评中分数最高,综合得分率为 77.13%,国内大模型产品文心一言正迅速追赶,在国内大语言模型中位列第一。
在这一背景下,市场普遍认为 GPT-4 的模型架构、基础设施、参数设计等具有一定程度的领先。由于官方并未公布 GPT-4 的详细参数,业内人士对 GPT-4 的详细参数进行了推断. 参数量:GPT-4 的大小是 GPT-3 的 10 倍以上,包含 1.8 万亿个参数; 混合专家模型:OpenAI 使用混合专家(MoE)模型,依此保持相应的成本。混合专家模型使用了 16 个专家模型,每个模型大约有 111B 个参数,每次计算将其中两个专家模型通过前向传递的方式将结果进行反馈; 数据集:GPT-4 的训练数据集将多个 epoch 中的 token 计算在内包含约 13万亿个 token; 推理:相较于纯密集模型每次前向传递需要大约 1.8 万亿个参数和约 3700TFLOP 的计算量,GPT-4 每次前向传递(生成 1 个 token)仅利用约 2800 亿个参数和约 560 TFLOP 的计算量; 并行策略:为了在所有 A100 GPU 上进行并行计算,GPT-4 采用了 8 路张量并行,因为这是 NVLink 的极限。
除此之外,GPT-4 采用了 15 路流水线并行; 训练成本:OpenAI 在 GPT-4 的训练中使用了大约 2.15e25 的 FLOPS,使用了约 25,000 个 A100 GPU,训练了 90 到 100 天,利用率(MFU)约为32% 至 36%。假定云端的每个 A100 GPU 的成本大约为每小时 1 美元,那么单次训练的成本将达到约 6300 万美元,如果使用约 8192 个 H100 GPU进行预训练,用时约为 55 天左右,成本为 2150 万美元,每个 H100 GPU的计费标准为每小时 2 美元;
推理成本:GPT-4 的推理成本是 1750 亿参数模型的 3 倍,这主要是因为GPT-4 的集群规模更大,并且利用率很低。根据测算,在用 128 个 A100GPU 进行推理的情况下,8k 版本 GPT-4 推理的成本为每 1,000 个 token0.0049 美分。如果使用 128 个 H100 GPU 进行推理,同样的 8k 版本 GPT-4推理成本为每 1,000 个 token 0.0021 美分; 推理架构:推理运行在由 128 个 GPU 组成的集群上。在不同地点的多个数据中心存在多个这样的集群。
推理过程采用 8 路张量并行(tensor parallelism)和16 路流水线并行(pipeline parallelism)。 视觉多模态:独立于文本编码器的视觉编码器,二者之间存在交叉注意力。该架构类似于 Flamingo。这在 GPT-4 的 1.8 万亿个参数之上增加了更多参数,经过了纯文本的预训练之后,又新增了约 2 万亿个 token 的微调。 由于大模型训练成本较高,性价比问题凸显。7 月 11 日,Intel 面向国内提出了新的解决方案,推出了第二代 Gaudi 深度学习加速器 Habana Gaudi2。Gaudi2深度学习以第一代 Gaudi 高性能架构为基础,多方位性能与能效比提升,加速高性能大语言模型运行。该加速器具备以下性能:
24 个可编程 Tensor 处理器核心(TPCs);
21 个 100Gbps(RoCEv2)以太网接口;
96GB HBM2E 内存容量;
2.4TB/秒的总内存带宽;
48MB 片上 SRAM;
集成多媒体处理引擎。
Habana Gaudi2 深度学习加速器和第四代英特尔至强可扩展处理器在 MLPerfTraining 3.0 基准测试上表现优异。
在大语言模型 GPT-3 的评测上,Gaudi2 也展示了其较优的性能。它是仅有的两个提交了 GPT-3 LLM 训练性能结果的解决方案之一(另一个是英伟达H100)。在 GPT-3 的训练上,英特尔使用 384 块 Gaudi 2 加速器使用 311 分钟训练完成,在 GPT-3 模型上从 256 个加速器到 384 个加速器实现了近线性 95%的扩展。
目前,已有部分厂商推出了基于英特尔 AI 加速卡的产品。在发布活动中,英特尔宣布 Gaudi2 首先将通过浪潮信息向国内客户提供,打造并发售基于 Gaudi2深度学习加速器的浪潮信息 AI 服务器 NF5698G7。其服务器集成了 8 块 Gaudi2加速卡 HL-225B,还包含两颗第四代英特尔至强可扩展处理器。 编辑:黄飞
-
微软Copilot全面更新为OpenAI的GPT-4 Turbo模型2024-03-13 1594
-
ChatGPT plus有什么功能?OpenAI 发布 GPT-4 Turbo 目前我们所知道的功能2023-12-13 2269
-
GPT-4没有推理能力吗?2023-08-11 1906
-
GPT-3.5 vs GPT-4:ChatGPT Plus 值得订阅费吗 国内怎么付费?2023-08-02 5643
-
英特尔面向中国市场发布Gaudi2处理器,加速大模型训练和推理2023-07-17 3094
-
英特尔推出AI加速器性价比产品Gaudi22023-07-14 2037
-
OpenAI宣布GPT-4 API全面开放使用!2023-07-12 2100
-
GPT-4已经会自己设计芯片了吗?2023-06-20 2173
-
微软提出Control-GPT:用GPT-4实现可控文本到图像生成!2023-06-05 1903
-
GPT-4 的模型结构和训练方法2023-05-22 3769
-
GPT-4是这样搞电机的2023-04-17 1897
-
关于GPT-4的产品化狂想2023-03-26 4005
-
GPT-4发布!多领域超越“人类水平”,专家:国内落后2-3年2023-03-16 6001
-
ChatGPT升级 OpenAI史上最强大模型GPT-4发布2023-03-15 3694
全部0条评论

快来发表一下你的评论吧 !
