

飞速发展的HBM仍面临着一些挑战
描述
飞速发展的HBM仍面临着一些挑战。
高带宽内存 (HBM) 正在成为超大规模厂商的首选内存,但其在主流市场的最终命运仍存在疑问。虽然它在数据中心中已经很成熟,并且由于人工智能/机器学习的需求而使用量不断增长,但其基本设计固有的缺陷阻碍了更广泛的采用。一方面,HBM提供紧凑的 2.5D 外形尺寸,可大幅减少延迟。
Rambus产品营销高级总监Frank Ferro在本周的 Rambus 设计峰会上的演讲中表示:“HBM 的优点在于,您可以在很小的占地面积内获得所有这些带宽,而且还可以获得非常好的能效。”
缺点是它依赖昂贵的硅中介层和 TSV 来运行。
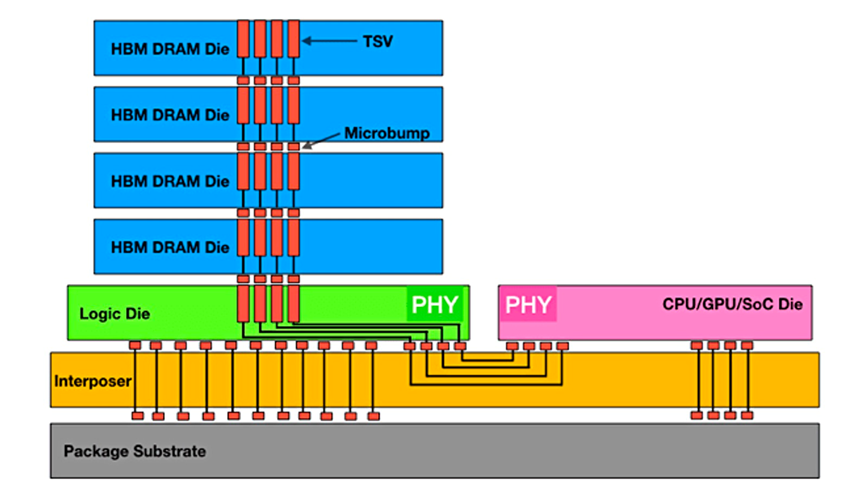
图 1:实现最大数据吞吐量的 HBM 堆栈。来源:Rambus
CadenceIP 团队产品营销总监 Marc Greenberg 表示:“目前困扰高带宽内存的问题之一是成本。”。“三维堆叠的成本很高。在堆叠芯片的底部有一个逻辑芯片,这是需要额外付出的硅片。然后是硅中介层,它位于 CPU 或 GPU 以及 HBM 存储器的下方。这些都需要成本。然后,你需要更大的封装等等。这些系统成本使 HBM 现在已经脱离了消费领域,而更多地应用于服务器机房或数据中心。相比之下,GDDR6等显存虽然性能不如 HBM,但成本却低得多。实际上,GDDR6的单位成本性能比 HBM 好得多,但 GDDR6 设备的最大带宽却比不上 HBM 的最大带宽。"
Greenberg表示,这些差异为公司选择 HBM 提供了理由,即使HBM可能不是他们的第一选择。“HBM 提供了大量的带宽,并且点对点传输的能量极低。使用 HBM 是因为必须这样做,没有其他解决方案可以提供相同的带宽或相同的功率配置文件。”
HBM 只会变得越来越快。“我们预计 HBM3 Gen3 的带宽将提高 50%,”美光计算产品事业部副总裁兼总经理 Praveen Vaidyanathan 说道。“从美光的角度来看,我们预计 HBM3 Gen2 产品将在 2024 财年期间实现量产。我们预计, 2024年年初将开始为预期的数亿美元收入机会做出贡献。此外,我们预测美光的 HBM3 将贡献比 DRAM 更高的利润。”
尽管如此,经济因素可能会迫使许多设计团队考虑价格敏感应用的替代方案。
他指出:"如果可以将问题细分为更小的部分,可能会发现HBM更具成本效益。例如,当必须在一个硬件上执行所有这些操作,而且必须在那里拥有 HBM,也许可以将其分成两部分,让两个进程并行运行,也许连接到 DDR6。如果能将问题细分为更小的部分,就有可能以更低的成本完成相同的计算量。但是,如果你需要巨大的带宽,如果你能承受成本,那么 HBM 就是你的最佳选择。”
散热挑战
另一个主要缺点是 HBM 的 2.5D 结构会产生热量,而靠近 CPU 和 GPU 的布局又会加剧这种情况。事实上,当前的布局就不太合理,因为当前的布局是将 HBM 及其堆叠的热敏 DRAM 放在计算密集型热源附近。
“最大的挑战是热量,”Greenberg说。"一个 CPU会产生大量的数据。每秒要通过这个接口传输太比特的数据。即使每笔数据交换只产生少量的微焦耳,每秒也要处理十亿次,因此 CPU 的温度非常高。而且,CPU 的工作不仅仅是转移数据,它还必须进行计算。除此之外,最不耐热的半导体元件是 DRAM。它在 85°C 左右开始遗失数据,而在 125°C 左右就会完全无法存储。”
有一点值得庆幸。“拥有 2.5D 堆栈的优点是,CPU 很热,而 HBM 位于 CPU 旁边,因此喜欢冷,之间有一定的物理隔离,”他说。
在延迟和热量之间的权衡中,延迟是不可变的。“我没有看到任何人愿意放弃优化延迟,”Synopsys 内存接口 IP 解决方案产品线总监 Brett Murdock说道。“我看到他们推动物理团队寻找更好的冷却方式,或者更好的放置方式,以保持较低的延迟。”
考虑到这一挑战,多物理场建模可以提出减少热问题的方法,但会产生相关成本。“这就是物理学变得非常困难的地方,” Ansys产品经理 Marc Swinnen 说。“功率可能是集成所能实现的最大限制因素。任何人都可以设计一堆芯片并将它们全部连接起来,所有这些都可以完美工作,但无法冷却它。散发热量是可实现目标的根本限制。”
潜在的缓解措施可能很快就会变得昂贵,从微流体通道到浸入非导电液体,再到确定散热器上需要多少个风扇,以及是否使用铜或铝。
可能永远不会有完美的答案,但模型和对期望结果的清晰理解可以帮助创建合理的解决方案。“必须定义最佳对你来说意味着什么,”Swinnen说。“你想要最好的热量吗?最好的成本?两者之间的最佳平衡?你将如何衡量它们?答案依赖于模型来了解物理学中实际发生的情况。它依靠人工智能来处理这种复杂性并创建元模型来捕捉这个特定优化问题的本质,并快速探索这个广阔的空间。”
HBM 和 AI
虽然计算是AI/ML最密集的部分,但如果没有良好的内存架构,这一切都无法实现。存储和检索万亿次计算需要内存。事实上,增加 CPU 并不能提高系统性能,因为内存带宽不足以支持这些 CPU。这就是臭名昭著的 "内存墙 "瓶颈。
Quadric首席营销官 SteveRoddy 表示,从最广泛的定义来看,机器学习只是曲线拟合。“在训练运行的每次迭代中,你都在努力越来越接近曲线的最佳拟合。这是一个 X,Y 图,就像高中几何一样。大型语言模型基本上是同一件事,但是是 100 亿维,而不是 2 维。”
因此,计算相对简单,但内存架构可能令人难以置信。
Roddy 解释说:“其中一些模型拥有 1000 亿字节的数据,对于每次重新训练迭代,都必须通过数据中心的背板从磁盘上取出1000 亿字节的数据并放入计算箱中。在两个月的训练过程中,你必须将这组巨大的内存值来回移动数百万次。限制因素是数据的移入和移出,这就是为什么人们对 HBM 或光学互连等从内存传输到计算结构的东西感兴趣。所有这些都是人们投入数十亿美元风险投资的地方,因为如果能缩短距离或时间,就可以大大简化和缩短训练过程,无论是切断电源还是加快训练速度。”
出于所有这些原因,高带宽内存被认为是 AI/ML 的首选内存。“它提供了某些训练算法所需的最大带宽,”Rambus 的 Ferro 说。“从你可以拥有多个内存堆栈的角度来看,它是可配置的,这为你提供了非常高的带宽。”
这就是人们对 HBM 如此感兴趣的原因。“我们的大多数客户都是人工智能客户,”Synopsys 的默多克说。“他们正在 LPDDR5X 接口和HBM 接口之间进行一项重大的基本权衡。唯一阻碍他们的是成本。”然而,人工智能的需求如此之高,以至于 HBM 减少延迟的前沿特征突然显得过时且不足。这反过来又推动了下一代 HBM 的发展。
“延迟正在成为一个真正的问题,”Ferro说。“在 HBM 的前两代中,我没有听到任何人抱怨延迟。现在我们一直收到有关延迟的问题。”Ferro 建议,鉴于当前的限制,了解数据尤为重要。“它可能是连续的数据,例如视频或语音识别。它可能是事务性的,就像财务数据一样,可能非常随机。如果知道数据是随机的,那么设置内存接口的方式将与流式传输视频不同。这些是基本问题,但也有更深层次的问题。我要在存储中使用的字长是多少?内存的块大小是多少?对此了解得越多,设计系统的效率就越高。如果了解它,那么就可以定制处理器以最大限度地提高计算能力和内存带宽。我们看到越来越多的 ASIC 式 SoC 正在瞄准特定市场细分市场,以实现更高效的处理。”
降低成本
如果经典的 HBM 实现是使用硅中介层,那么就有希望找到成本更低的解决方案。“还有一些方法可以在标准封装中嵌入一小块硅,这样就没有一个完整的硅中介层延伸到所有东西下面,”格林伯格说。“CPU 和 HBM 之间只有一座桥梁。此外,在标准封装技术上允许更细的引脚间距也取得了进展,这将显着降低成本。还有一些专有的解决方案,人们试图通过高速 SerDes 类型连接来连接存储器,沿着 UCIE 的路线,并可能通过这些连接来连接存储器。目前,这些解决方案是专有的,但我希望它们能够标准化。”
Greenberg表示,可能存在平行的发展轨迹:“硅中介层确实提供了尽可能细的引脚间距或线间距——基本上是用最少的能量实现最大的带宽——所以硅中介层将永远存在。但如果一个行业能够聚集在一起并决定一个适用于标准封装的内存标准,那么就有可能提供类似的带宽,但成本却要低得多。”
人们正在不断尝试降低下一代的成本。“台积电已宣布他们拥有三种不同类型的中介层,”Ferro 说。“他们有一个 RDL 中介层,他们有硅中介层,他们有一些看起来有点像两者的混合体。还有其他技术,例如如何完全摆脱中介层。可能会在接下来的 12 或 18 个月内看到一些如何在顶部堆叠 3D 内存的原型,理论上可以摆脱中介层。”
解决该问题的另一种方法是使用较便宜的材料。“正在研究非常细间距的有机材料,以及它们是否足够小以处理所有这些痕迹,”Ferro说。“此外,UCIe是通过更标准的材料连接芯片的另一种方式,以节省成本。但同样,仍然必须解决通过这些基材的数千条痕迹的问题。”
Murdock希望通过规模经济来削减成本。“随着 HBM 越来越受欢迎,成本方面将有所缓解。HBM 与任何 DRAM 一样,归根结底都是一个商品市场。在中介层方面,我认为下降速度不会那么快。这仍然是一个需要克服的挑战。”
但原材料成本并不是唯一的考虑因素。“这还取决于 SoC 需要多少带宽,以及电路板空间等其他成本,”Murdock 说。“对于那些想要高速接口并需要大量带宽的人来说,LPDDR5X 是一种非常受欢迎的替代方案,但与 HBM 堆栈的通道数量相匹配所需的 LPDDR5X 通道数量相当大。虽然有大量的设备成本和电路板空间成本,这些成本可能令人望而却步。仅就美元而言,也可能是一些物理限制促使人们转向 HBM,尽管从美元角度来看它更昂贵。”
其他人对未来成本削减则不太确定。Objective Analysis 首席分析师 Jim Handy 表示:“降低HBM 成本将是一项挑战。由于将 TSV 放置在晶圆上的成本很高,因此加工成本已经明显高于标准 DRAM。这使得它无法拥有像标准 DRAM 一样大的市场。由于市场较小,规模经济导致成本在一个自给自足的过程中更高。体积越小,成本越高,但成本越高,使用的体积就越少。没有简单的方法可以解决这个问题。”
尽管如此,Handy 对 HBM 的未来持乐观态度,并指出与 SRAM 相比,它仍然表现出色。“HBM 已经是一个成熟的 JEDEC 标准产品,”他说。“这是一种独特的 DRAM 技术形式,能够以比 SRAM 低得多的成本提供极高的带宽。它还可以通过封装提供比 SRAM 更高的密度。它会随着时间的推移而改进,就像 DRAM 一样。随着接口的成熟,预计会看到更多巧妙的技巧来提高其速度。”
事实上,尽管面临所有挑战,HBM 还是有理由保持乐观。“标准正在迅速发展,” Ferro补充道。“如果你看看 HBM 如今的发展,会发现它大约以两年为间隔,这确实是一个惊人的速度。”
审核编辑:刘清
-
移动电视射频技术面临什么挑战2019-06-03 2130
-
5G无线通信网络的挑战2019-06-18 3647
-
复杂RF环境下的RFID测试面临哪些挑战?2019-08-08 2453
-
处理器在低功耗物联网应用面临什么挑战?2019-08-12 3162
-
电力系统设计面临什么挑战?2019-08-20 2849
-
比特币的媒体区块链正面临着扩容问题的挑战2018-09-27 885
-
物联网软件开发的主要挑战是什么2019-07-15 1950
-
工业控制系统的设计过程将面临着严峻挑战2019-12-28 1392
-
我国5G牌照发牌一年,5G发展面临着哪些机遇与挑战2020-06-08 3112
-
电源产品的PCB设计需要面临什么样的挑战2020-08-29 1154
-
我国在医用传感器的研发上面临着哪些挑战?2020-09-24 3559
-
格芯:整个半导体产业面临着新的挑战和机遇2020-11-05 2973
-
集成电路产业不仅面临着新的挑战,还有新的机遇2021-03-28 4194
-
设计医疗PCB面临着一些挑战 医疗PCB技术的新兴趋势2023-07-27 1692
-
苹果AI服务在华面临挑战,寻求本土合作新机遇2024-06-22 2057
全部0条评论

快来发表一下你的评论吧 !
