

一文解析百度知道上云与架构演进
嵌入式技术
描述
作者 | 百度Geek说-百度知道研发组
导读
百度知道作为上线十多年的老产品线,业务场景多、架构老旧、代码风格不统一,同时业务迭代较快,整体承载流量大,稳定性要求高,给业务全面上云带来不小的挑战。本文基于实践,介绍知道如何进行上云方案的选型和落地,并同步进行架构演进,提升线上服务稳定性和容灾能力。
01 背景与挑战
1.1 背景
随着集团 PaaS 化战略和云上百度战略推进,当前在线运行平台 ORP 已正式进入维稳阶段,不再进行功能更新和安全修复;同时 ORP 接入层在稳定性、变更效率等方面也无法满足云上部署要求。OXP 逐渐成为业务发展和迭代的瓶颈。为了解决这一问题,同时增强资源弹性,降低业务资源成本,接入各类云原生能力,提升部署效率,保障线上服务稳定性,知道启动去 OXP 专项,将逐步完成整体上云及架构演进工作。
1.2 挑战
1、知道产品线老旧,历史债务多。 百度知道是一个已有十八年历史的老产品线,业务模式繁杂,上下游依赖较多,不同时期的重点方向不一样,架构老旧,代码风格不统一,改造成本高;
2、知道业务发展快,迭代变化快。 虽然产品线历史久远,为了适应新变化,业务迭代敏捷,核心场景更新换代频繁,年均上线业务需求 780 + 个,需在保证业务目标达成前提下完成上云迁移,使业务全程无感;
3、知道流量大,商业收入多,稳定性要求高。 作为知识类流量收入双 TOP 产品线,知道日均 pv 过亿,迁移过程中不能影响任何流量和商业收益,核心服务稳定性目标需在四个 9 以上;
4、上云同时架构合理演进。 上云迁移作为知道历史上一次重大技术变革,除了能给老产品线带来先进的云原生能力,优化 IT 成本以外,还希望借此推动知道整体架构优化演进,提升容灾能力及线上服务稳定性。
1.3 收益
1、全部流量上云,为知道带来先进的资源弹性供给能力,大幅提升扩缩容效率,避免流量波动带来的线上容量风险,提升在线服务稳定性;
2、引入容器弹性售卖能力,按需使用、按量付费、动态调整,优化线上服务整体资源量级;腾退大批量 OXP 机器,大幅降低知道 IT 成本;
3、知道架构随上云持续演进,将 0 到 1 实现核心流量三地四机房云上部署,降低核心页端到端耗时,使核心页面具备 N+1 冗余灾备能力,提升业务抗风险能力。
02 概念介绍
2.1 知道业务简介
知道是传统的图文知识类内容生产业务。首先通过用户自发提问,或者对搜索每日 query 筛选挖掘,获取到待解决问题;其次引导各类生产者,在不同页面、后台对问题进行解答,生产回答内容;再次将生产好的问答对推送至搜索、Feed 等场景供用户浏览消费,用户点击进入问答页后获得解答,同时靠广告点展为知道带来商业收入。
知道经过多年经营,积累了海量问答资源,在搜索生态中稳定覆盖了众多长尾需求;同时通过识别用户需求,挖掘高价值线索,引入机构或 MCN 账号,建设了多垂类优质内容,逐渐形成了相对稳定的多层次内容生态和品牌认知。
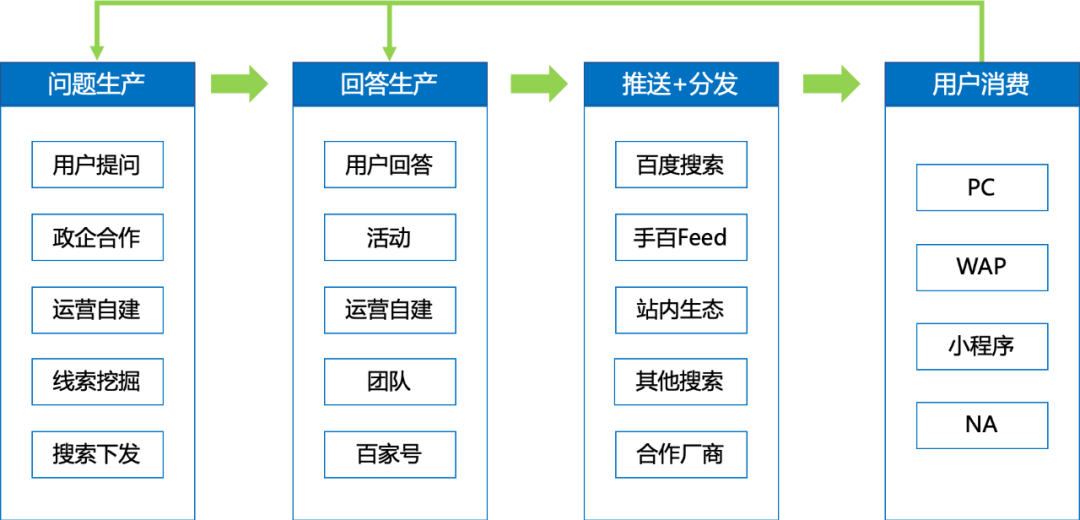
2.2 业务架构
知道整体业务架构如下图所示:
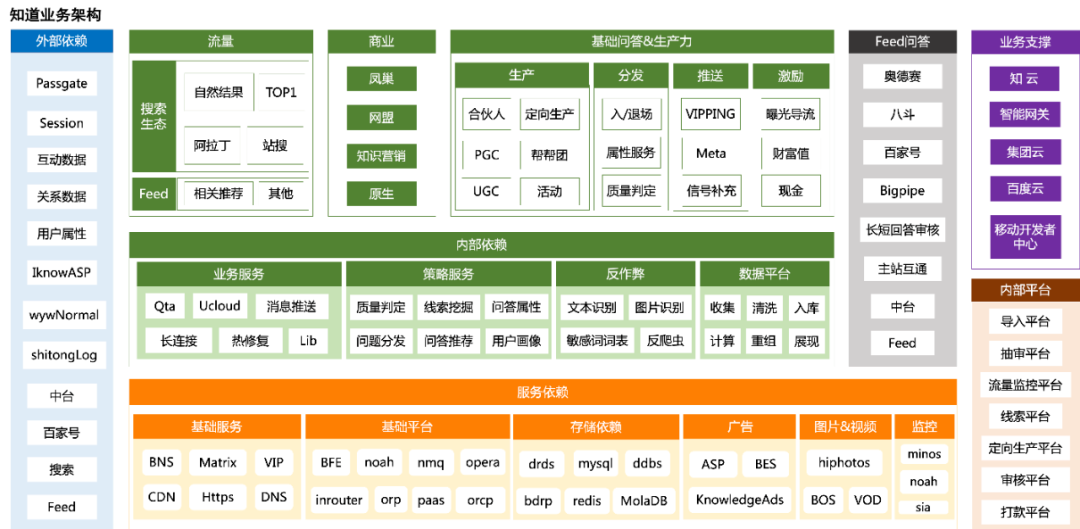
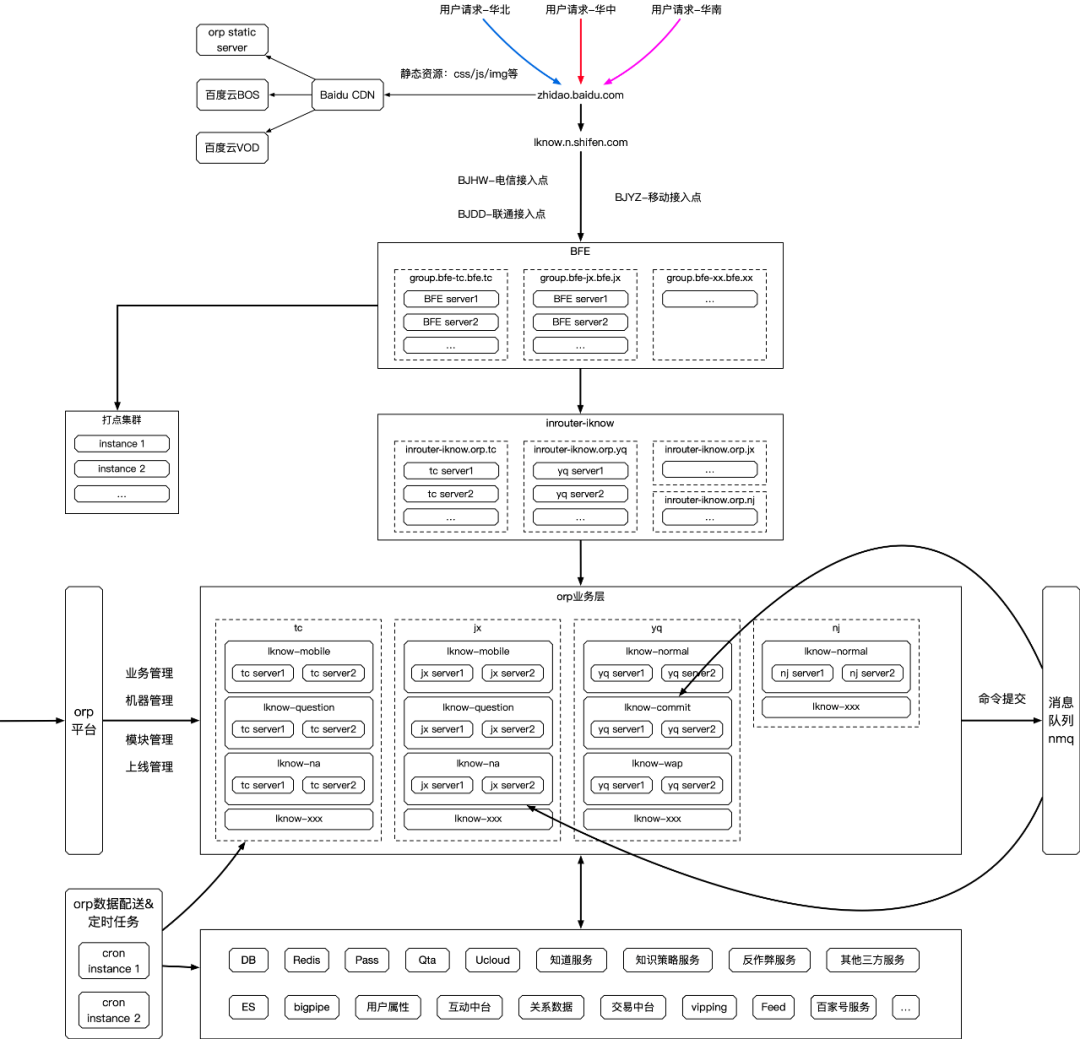
2.3 流量架构
上云前知道整体流量架构如下图所示:
03 上云设计与实践
3.1 上云方案选型
知识垂类内 php 模块广泛使用的 PaaS 平台 orp 已公告于 2022 年底停止维护,同时现有的 orp 系统在容器编排管理层面存在一些问题,预算资源管理也和现有公司的机制流程不通。知道的现有架构基于 odp 原生实现,更多体现成一个大型大单体应用,通过本次升级,知道需迁移至更加接近云原生环境的 PaaS 平台上,进行新一轮的架构迭代,打造符合业务现状的架构理想态。
虽然管理容器化应用程序的开源系统 Kubernetes 作为社区和未来发展趋势,但综合考虑改造成本、时间节点、开发人力等因素,知道本次上云与其他知识垂类产品线迁移最终选型保持一致:底层使用 pandora,资源管理及上线使用 “知云平台”。
3.1.1 why pandora
主要有几个方面考虑:
1、pandora 适应公司内主要的 C 端业务,如大搜、feed、手百、百家号、视频(好看)等,这些业务在场景上与知识体系更加接近,详细调研和评估可支持现有变更方案;
2、pandora 在现有 PaaS 内唯一能够支持较多模块同时部署(最大支持 2K),而无需业务过多改造合并,更适应现 odp 大单体的架构;
3、易用性层面 pandora 暂时不及 opera,但已通过知云解决;同时知云会提供 orp 的包括接入、静态资源、代理、数据配送等服务,故不影响最终选型结论。
3.1.2 why 知云
知识垂类及其他 oxp-based 业务有个比较明显的架构:大单体模式下的多 APP 同构,这部分需求在现有的 PaaS 平台均无支持。同时,因为 pandora 底层对打包和服务的规范,业务线需要针对性的进行代码改造和回归,这部分工作存在明显的重复性。知云平台旨在提供一套更符合知识业务(及 oxp-based)的上云解决方案,主要具备以下几类优势:
1、上线变更:除基础上线、配置管理及回滚等外,核心支持多 APP 同构的模式,及支持多模块部署。可以做到 oxp 项目迁移至知云成本降低,理想情况下无需合并 / 拆分代码库,可以平移支持;
2、平台服务:对标 oxp 现有服务,提供包括日志切分、定时任务、接入层、静态资源、飞线、中控等的支持和解决方案,同时基于云原生思想开放服务模式,支持业务部署自定义服务;
3、业务运行时环境:odp 基础运行环境快速部署和定制;
4、基础环境(容器):整合入口,在日常运维时提供更方便的操作方案。
3.2 切流与扩量实践
3.2.1 上云前改造
对各流量集群,在迁移 Pandora 之前,主要涉及以下几方面工作:
1、知云创建产品线及应用。 需在知云平台搭建知道产品线基础环境,创建 APP 基础信息,申请 ECI 各机房资源 2 及实例配置,添加 ODP 基础运行环境及数据配送容器相关信息,创建容器组件相应配置,添加静态文件存储地址,修改部署路径及配置派生 conf,创建上线模板等;
2、接入层改造及授权。 接入层创建对应新 APP 的 BNS 变量,并针对新的 BNS 进行各类 DB、redis 授权,涉及新机房,还需要对各 mysql 及 redis 配置进行升级适配;
3、业务层改造及测试。 知道本次上云会同步完成后端语言 HHVM->PHP7 升级改造,语言版本更新会带来安全及性能方面的进一步提升,同时 PHP7 还提供了众多新的语法特型,老旧版本无法使用。需完成对应模块 PHP7 兼容性问题改造,并完成线下测试;
4、添加监控及日志采集。 需添加对应 APP 的各级 noah、sia 监控,对各监控项进行调整,对监控阈值进行优化;修改相应日志采集路径,合并各服务组,并离线进行入库效果验证。
3.2.2 切流方案
小流量实验方案如下图所示:
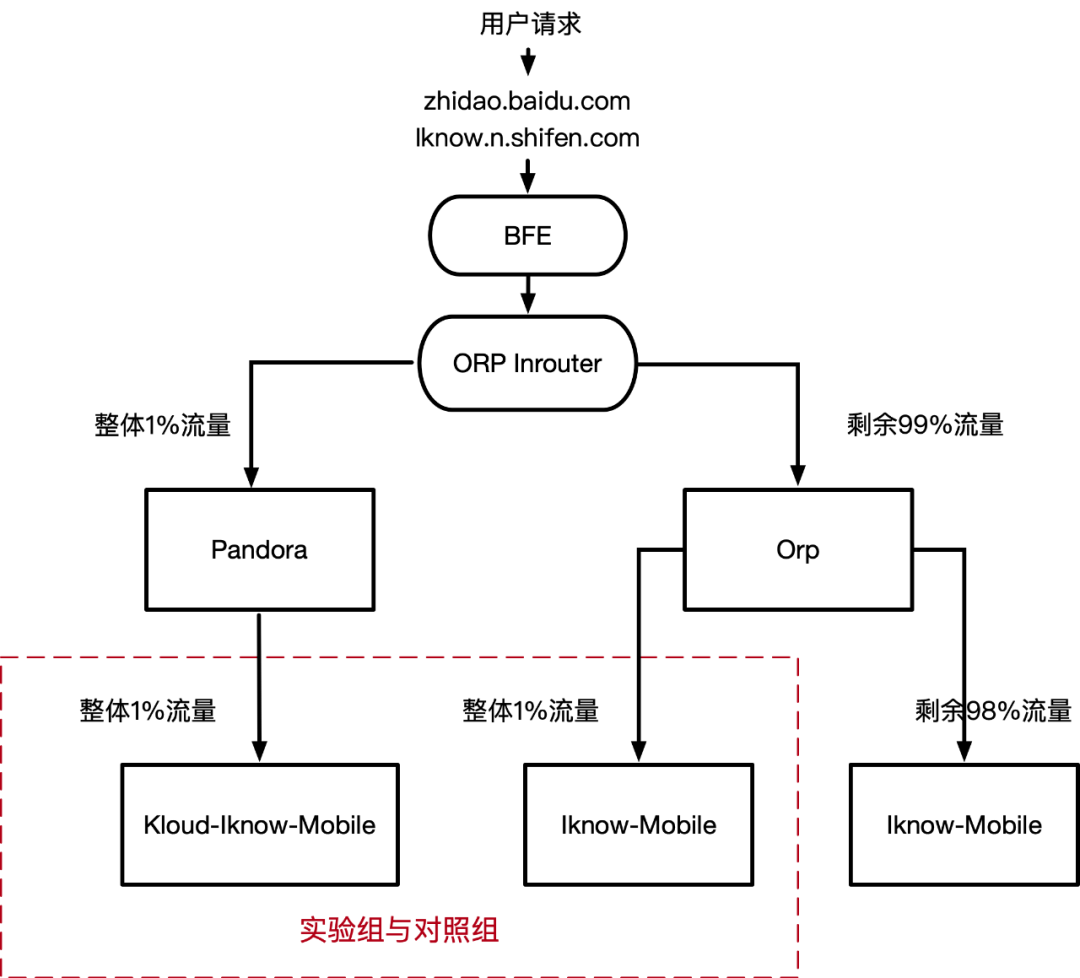
接入层改造:
可借助接入层的 lua 脚本实现小流量切流,脚本实现了以下规则:
['strategy_1_1_98'] = {1, 1, 98}, ['strategy_5_5_90'] = {5, 5, 90}, ['strategy_10_10_80'] = {10, 10, 80}, ['strategy_20_20_60'] = {20, 20, 60}, ....., ['strategy_80_20_0'] = {80, 20, 0}, ['strategy_95_5_0'] = {95, 5, 0}, ['strategy_100_0_0'] = {100, 0, 0} 返回值有三种结果:"opera", "abtest", "orp",从左到右分别对应三段数字,即每种结果出现的概率,从而可以根据返回的结果实现流量控制; 使用新增变量 $upstream_target 来标记最终 proxy 值,四种取值分别对应 pc 端和移动端实验组 / 对照组流量:
#设置最终proxy的值:pc_orp、pc_pandora、wap_orp、wap_pandora set $upstream_target "${terminal_target}_${target_cluster}"; #知道上云切流实验配置结束
新增给业务传递标记,取值为 "pandora"、"abtest"、"orp",分别用来标识实验组、对照组、无关组流量。
业务层改造
业务层捕获上述流量标记,分别创建并使用新的 Eid 发起商业请求,即可获得当前实验组 / 对照组各页面商业流量数据。
if ($_SERVER['HTTP_X_BD_TARGET'] == 'pandora') { $adsEids = array( 'asp' => array(50001), ); } else if ($_SERVER['HTTP_X_BD_TARGET'] == 'abtest') { $adsEids = array( 'asp' => array(50002), ); }
3.2.3 扩量相关
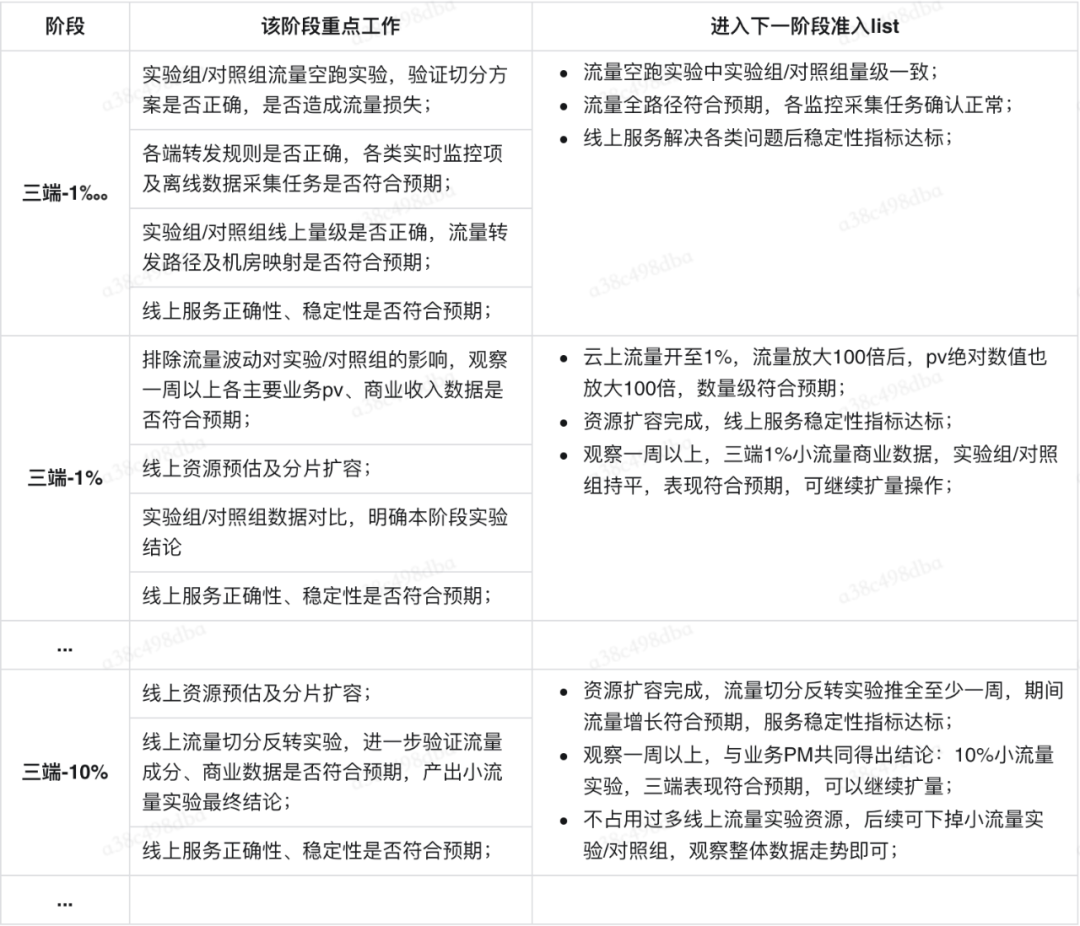
以知道核心问答页为例,扩量的每个阶段都有该阶段需重点关注的工作内容,及进入下一个阶段的准入 list,需要 list 内容全部达标,才可开启下一阶段扩量实验。具体说明如下:
3.2.4 云上网关切换
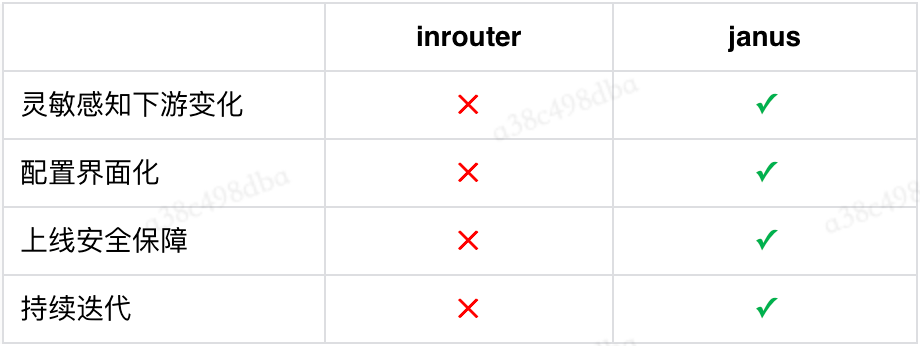
在业务层上云后,网关下游由原本几乎不发生迁移的 orp 环境,变成了迁移频繁的云上环境,原 orp 接入层对频繁的下游变化无法做到灵敏感知,因此需对原 orp 接入层进行上云切换。Janus 网关已经广泛使用在了如手百、百科、问一问、经验、百家号等产品线中,与原 inrouter 对比具有以下优势,同时经过了大量的实践验证,因此知道上云选择了知云体系中的 Janus 来进行网关切换。
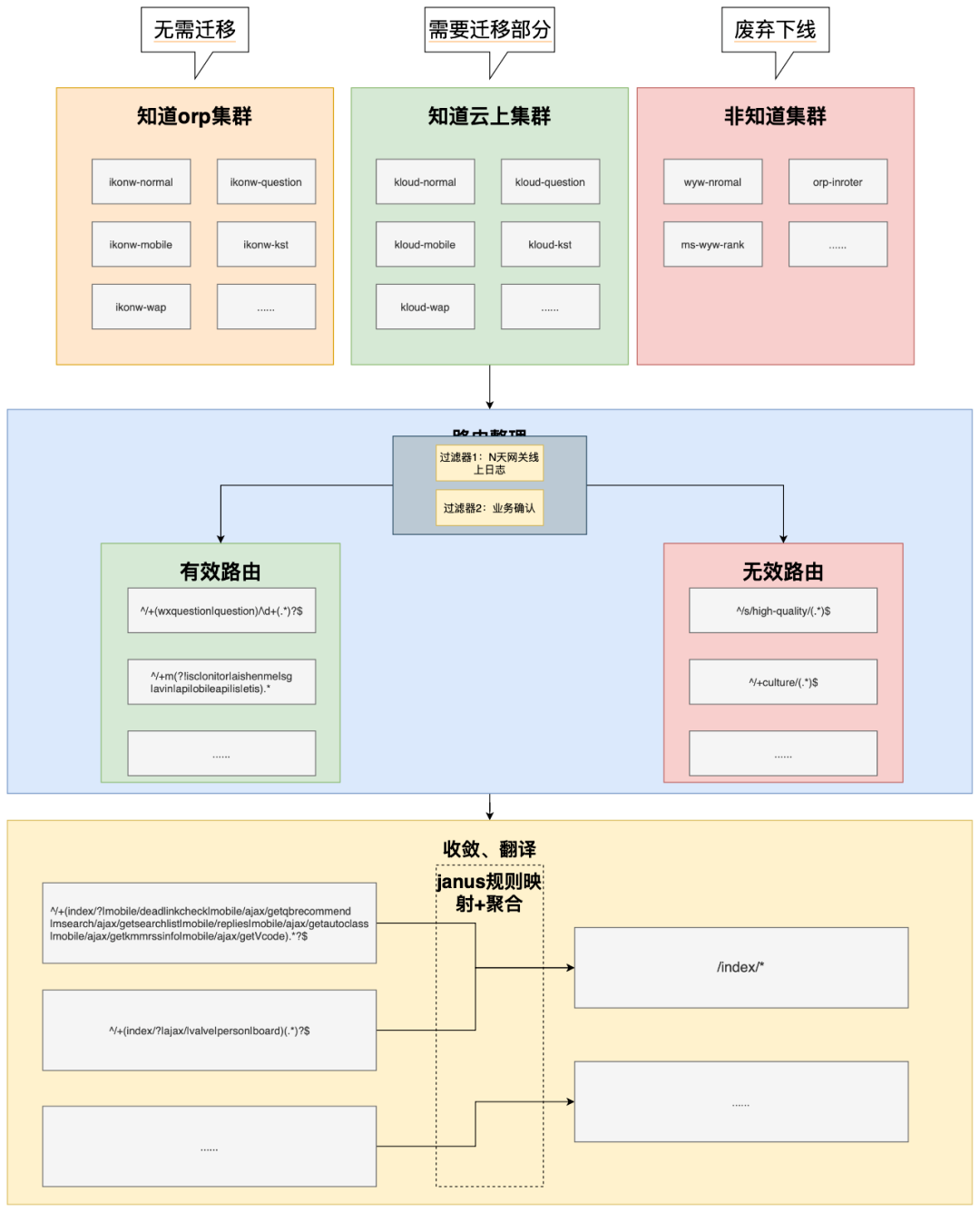
知道经历了 18 年的迭代,网关的路由转发规则已经臃肿不堪,逻辑繁琐,维护成本非常高,稍有不慎就会引发严重线上事故。网关作为对流量转发控制的服务,应当尽可能地简单、清晰,具备较好的可读性和可维护性。因此在网关上云切换时,应当同步进行路由的深度重构治理,而不是简单的平迁。迁移重构核心流程如下:
最终达到的效果:
1、下游感知灵敏:新网关对下游实例漂移感知灵敏,叠加重试策略,实例漂移对业务 SLA 几乎无影响;
2、大大增强可维护性:将预览、内网、外网三类域名隔离建设,划分清晰,使用和维护都一目了然。将原 nginx 转发规则 2768 行 conf 文件整合收敛至 18 条规则,清理了 18 年来的历史包袱;
3、安全性得到进一步增强:上线细化至每个服务、每条路由、每条转发规则,影响面可控。除了分级发布,叠加 checker、上线巡检、测试用例等手段,大大增强了网关上线变更的安全性。
3.3 架构演进
3.3.1 现状 & 问题
知道长久以来 95% 以上主体流量集中在北方,核心流量打到 tc+jx 机房,非核心流量打到 yq 机房。从外网接入点,到实际业务层,到底层依赖基础服务,再到重要的第三方依赖服务,均没有搭建其他地域资源和服务。这就造成一个非常明显的安全隐患,一旦华北地域出现故障,无法进行彻底的切流来规避线上损失。
3.3.2 演进方案
1. 知道三端 QB 页核心流量,占知道总体流量 80% 以上,是知道 99% 以上商业收入来源,自然流量大,用户交互多,对线上事故敏感,稳定性要求四个 9 以上。这部分是知道的生命线,本次伴随上云迁移,会同步建设三地四机房,使 QB 页具备单地域故障快速切流其他两地能力,提升系统整体可靠性;
2. 除 QB 页以外非核心流量,由于时间久,涉及模块多,底层资源类型繁杂,同时又基本不贡献商业收入,各子系统流量占比较低,考虑改造成本及性价比,本次上云迁移将非核心流量迁至华北双机房,具备同地域不同机房冗余灾备能力,暂不建设其他地域;
3. 针对核心流量,需进行 “外网接入点 ->BFE-> 接入层 -> 业务层 -> 依赖自身服务 -> 依赖三方服务 -> 依赖底层存储” 全链路三地资源建设,并进行连通性测试;
4. 针对核心流量,各级服务资源到位后,需进行全方位压测及灾备演练,确保新地域机房流量承压能力,并达到单地域故障时可自由切换至其他两地域状态。针对重要的、且无法线上压测演练的三方服务例如商业广告请求,协同对方 OP、RD、QA 等角色共同制定切流观察方案,以免流量分布改变后造成线上安全隐患;
5. 针对核心流量,设计切流方案并建立各三方服务同步机制,切流期间共同观察,上下游各子系统是否符合预期。
3.3.3 具体实现
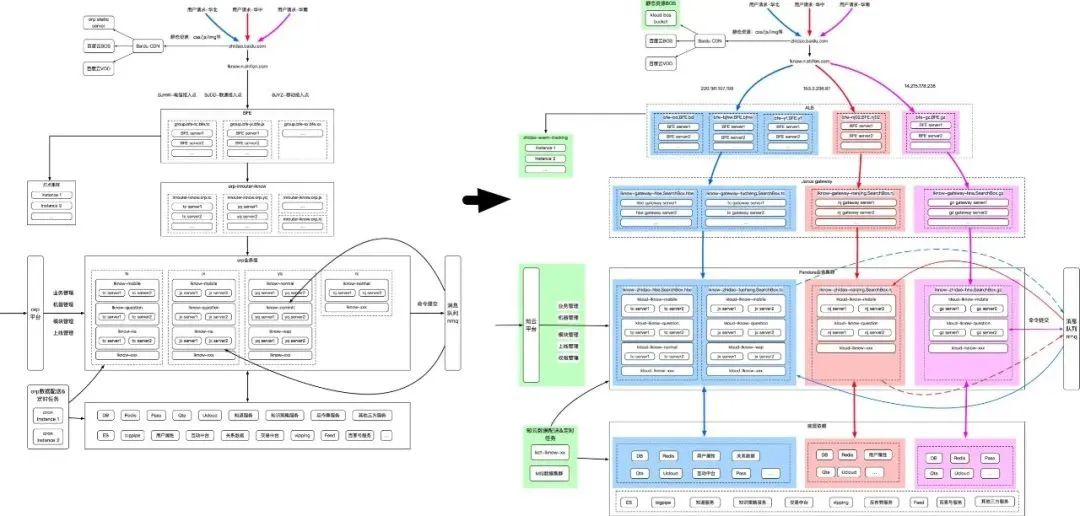
知道核心流量三地域建设完成后流量架构演进如下所示:
04 总结与收益
1. 截至 23 年 3 月 31 日,知道云上流量占比已达 100%,知道业务已全面上云。
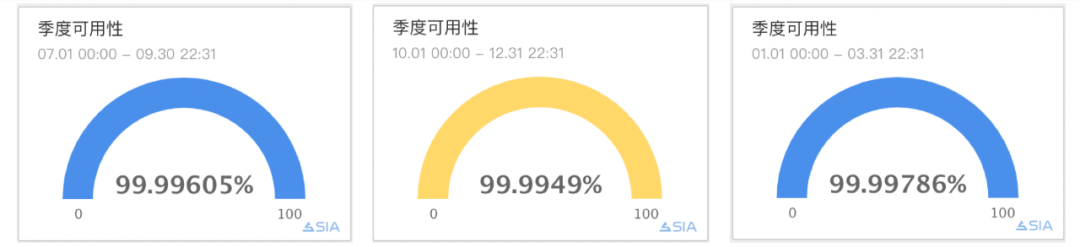
2.2022 年 Q3 知道开始切流上云,连续三个季度 SLA 满足四个 9,由上云引入线上问题数 0。
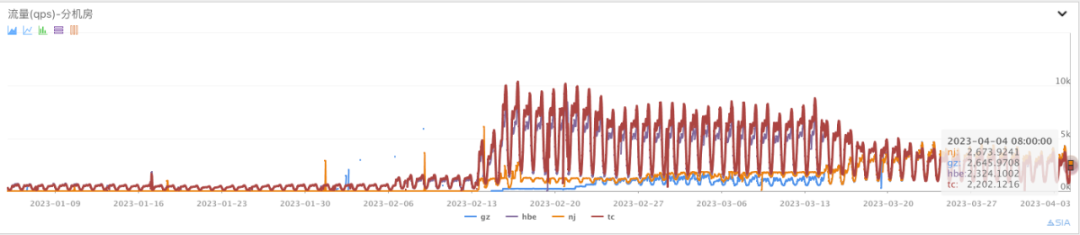
3. 知道核心页已完成三地四机房建设,知道线上核心流量分布比例为华北:华中:华南 = 43,知道历史上首次具备了 N+1 跨地域冗余灾备能力。
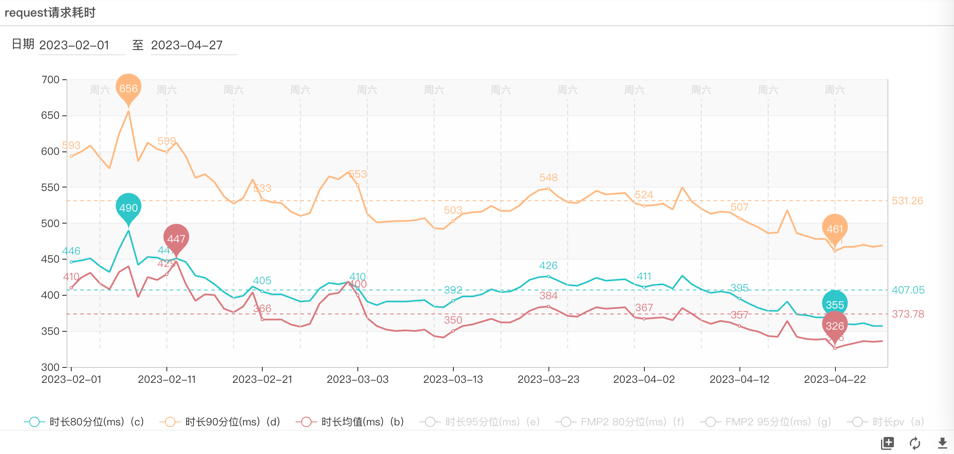
4. 小程序 QB 核心接口端到端耗时均值下降 12%,FMP80 分位稳定 1S 内,不需要其他技术优化即达成秒开。
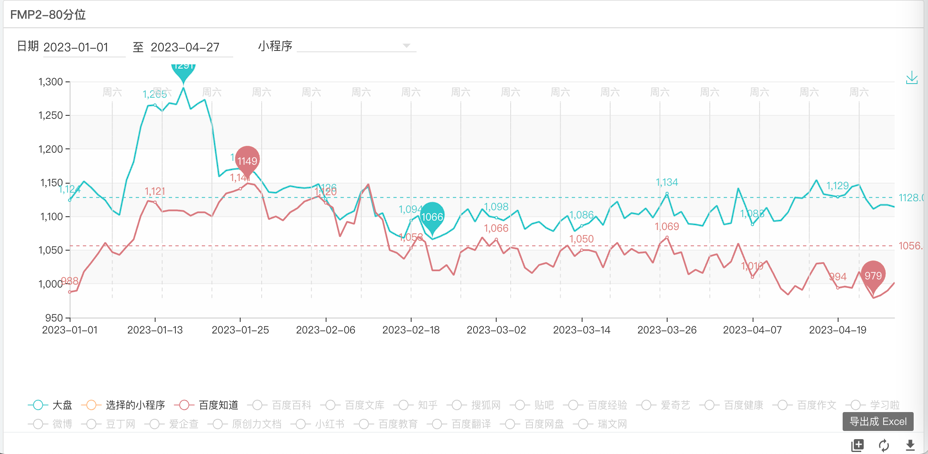
5. 完成 GTC 接入点三地调整,公网 IP 均摊费用自 2023 年以来逐月下降,同时批量交付下线 OXP 机器,节省了大量研发成本。
编辑:黄飞
-
百度云服务器怎么使用nfs ,tftp2020-04-24 2823
-
基于互联网云脑架构,对百度的未来发展趋势进行分析2018-01-11 5756
-
百度云物流接入区块链技术 共建下一代云计算架构2018-07-07 1371
-
百度正式推出百度云ABC 3.0,与各行业结合实现产业变革2018-09-05 5693
-
AI技术的推动下 百度智能云将迎来新的机会2019-12-20 909
-
百度智能云进行架构调整 技术和销售整合为一体2020-03-14 3170
-
云计算重要性更加凸显 百度如何迎新机遇2020-03-16 3767
-
阿里巴巴推出自主研发的新一代云基础架构百度“太行”2020-08-24 2910
-
新基建时代 百度如何加速百度智能云发展2020-11-11 2561
-
百度云计算to B,AI成为标配2020-10-21 4422
-
百度智能云发布“云智一体3.0”架构全新升级2022-09-07 2391
-
国产ChatGPT=百度智能云+文心一言?“文心一言”将通过百度智能云对外服务2023-02-18 3215
-
GTC 2023:百度智能云DPU落地实践2023-03-24 4792
-
百度世界2023看点 文心大模型4.0正式发布 百度文库变身生产力工具2023-10-17 2271
-
百度智能云正式发布Hogee2026-05-15 976
全部0条评论

快来发表一下你的评论吧 !
