

大算力芯片龙头股
描述
1 关于计算架构阶段的划分

图灵奖获得者John Hennessy总结了计算机体系结构的四个时代和即将兴起的第五个时代:
第一代,晶体管时代,指令集架构出现之前,计算机架构各不相同;
第二代,小规模和中等规模集成电路时代,出现支持指令集架构的CPU处理器;
第三代,大规模和超大规模集成电路时代,指令级并行以及CISC和RISC混战;
第四代,超大规模集成电路的多核处理器并行时代;
第五代,从2016年超大规模的领域专用处理器(DSA)时代。
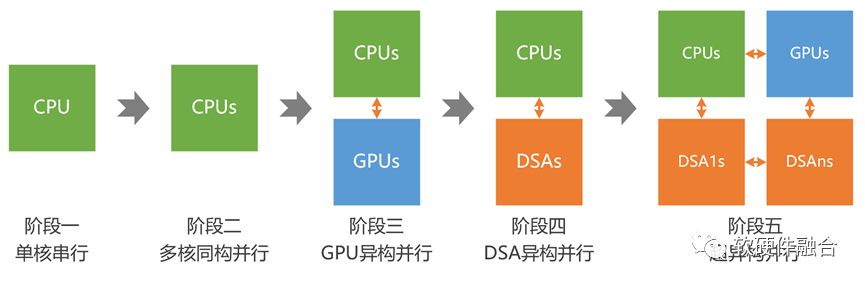
上面计算机体系结构的时代划分,是站在单处理器引擎视角进行的。我们参考上述五个时代的划分,并且站在多处理器引擎计算架构从简单到复杂的发展视角,重新进行了如下的发展阶段划分:
第一阶段,单CPU的串行计算;
第二阶段,多CPU的同构并行计算;
第三阶段,CPU+GPU的异构并行计算;
第四阶段,CPU+DSA的异构并行计算;
第五阶段,(还在萌芽期的)多种异构融合的超异构并行计算。
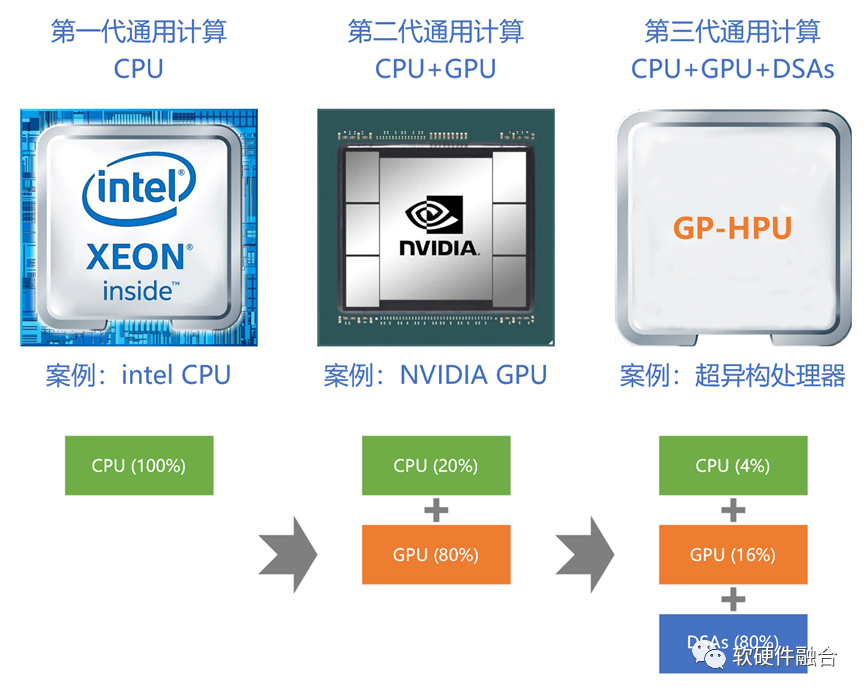
如果我们为计算架构再加一个约束——通用,则计算架构可以划分为三个阶段:
第一阶段,CPU同构计算(单核CPU阶段可以合并进CPU同构计算);
第二阶段,基于GPU的同构计算(DSA是一种偏定制的架构,单个DSA的异构不属于通用计算范畴);
第三阶段,基于CPU+GPU+DSAs的超异构计算。
“二八定律”无处不在:随着系统的扩大,会逐渐沉淀许多共性的计算任务。我们定性的分析一下,依据二八定律:
在CPU同构计算阶段,100%工作由CPU完成;
但在GPU异构阶段,80%工作由GPU完成,CPU只完成剩余的20%的工作;
而在超异构计算阶段,则80%的工作由各类更高效的DSA完成,GPU只完成剩余20%工作的80%,即16%的工作,剩余的4%交给CPU。
2 从异构到超异构
2.1 CPU性能瓶颈,异构计算成为主流

上世纪80-90年代,每18个月,CPU性能提升一倍;如今,CPU性能提升每年只有3%,要想性能翻倍,需要20年。虽然CPU的性能提升几乎停滞,但对性能和算力的更高需求,是永无止境的,例如:
2012-2018年共6年时间里,人们对于AI算力的需求增长了超过30万倍;随着BERT、GPT等大模型的发展,算力需求每2个月就翻一倍。
随着大模型的发展,对算力的需求水涨船高,要想实现L5级别的自动驾驶算力,则需要上万TOPS。与此同时,随着自动驾驶进入L5阶段,对娱乐的需求必然猛增。多域融合的智能汽车综合算力需求预计会超过两万TOPS。
Intel前SVP拉加·库德里表示,要想实现元宇宙级别的用户体验,需要当前的算力提升1000倍。
从2012年深度学习兴起开始,随着AI等大算力场景的算力需求越来越大,异构计算已经成为计算架构的主流。
2.2 异构计算的问题
性能和灵活性的矛盾:系统越复杂,越需要灵活的处理器;性能挑战越大,越需要定制的加速处理器。问题的本质在于:单一的处理器是无法兼顾性能和灵活性的。
由于在异构计算系统中,CPU不承担主要的计算任务,因此加速处理器决定了异构系统的性能/灵活性特征:
GPU灵活性较好,但性能效率不够极致;并且性能也逐渐接近瓶颈。
DSA性能好;但灵活性差,难以适应算法的多变;架构碎片化;落地困难。
FPGA功耗和成本高,定制开发,落地案例少,通常用于原型验证。
ASIC功能完全固定,无法适应灵活多变的复杂计算场景。
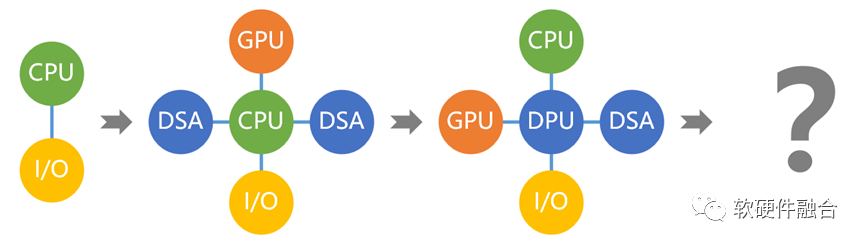
随着异构计算成为主流,异构的系统越来越多。多异构共存的异构计算孤岛问题凸显:
加速处理器只考虑本领域问题,难以考虑全局协同;
各领域加速器之间交互困难;
中心单元的性能瓶颈问题;
物理空间有限,无法容纳多个物理的异构加速卡。
2.3 多种异构的融合:超异构
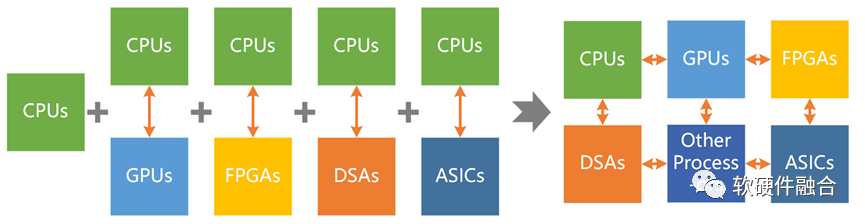
要想高性能,需要硬件层次的更高集成度,更需要系统层次的多种异构融合(即超异构)。
超异构计算:系统复杂度显著上升,系统更难驾驭。如何在快速提升性能的同时,让系统更好驾驭,是超异构计算要解决的关键问题。
3 大算力芯片的核心能力:通用、通用,还是通用
3.1 系统越来越大,对通用灵活性的要求远高于对性能的要求
在云和边缘数据中心,都是清一色的服务器。这些服务器,可以服务各行各业、各种不同类型的场景的服务端工作任务的处理。CSP每年投入数以亿计资金,上架数以万计的各种型号、各种配置的服务器的时候,严格来说,它并不知道,具体的某台服务器最终会售卖给哪个用户,这个用户到底会在服务器上面跑什么应用。并且,未来,这个用户的服务器资源回收之后再卖个下一个用户,下一个用户又用来干什么,也是不知道的。因此,对CSP来说,最理想的状态是,存在一种服务器,足够通用,即不管是哪种用户哪种应用运行其上,都足够高效快捷并且低成本。只有这样,系统才够简单而稳定,运维才能简单并且高效。然后要做的,就是把这种服务器大规模复制(大规模复制意味着单服务器成本的更快速下降)。
云和边缘服务器场景,对系统的灵活性的要求远高于对性能的要求,需要提供的是综合性的通用解决方案。最直接的例子就是以CPU为核心的服务器:CPU通用灵活性是最好的,如果CPU的性能够用,大家绝对不喜欢用各种加速;如今是CPU性能不够,逼迫着大家不得不去使用各种硬件加速。
数据中心硬件加速最大的教训是:在提升性能的同时,最好不要损失系统的灵活性。其言下之意就是:目前各类加速芯片的优化方案损失了灵活性,从而使得芯片的落地很困难。这是目前全行业的痛点所在。
3.2 集群计算,对芯片的弹性可扩展能力提出了更高的要求
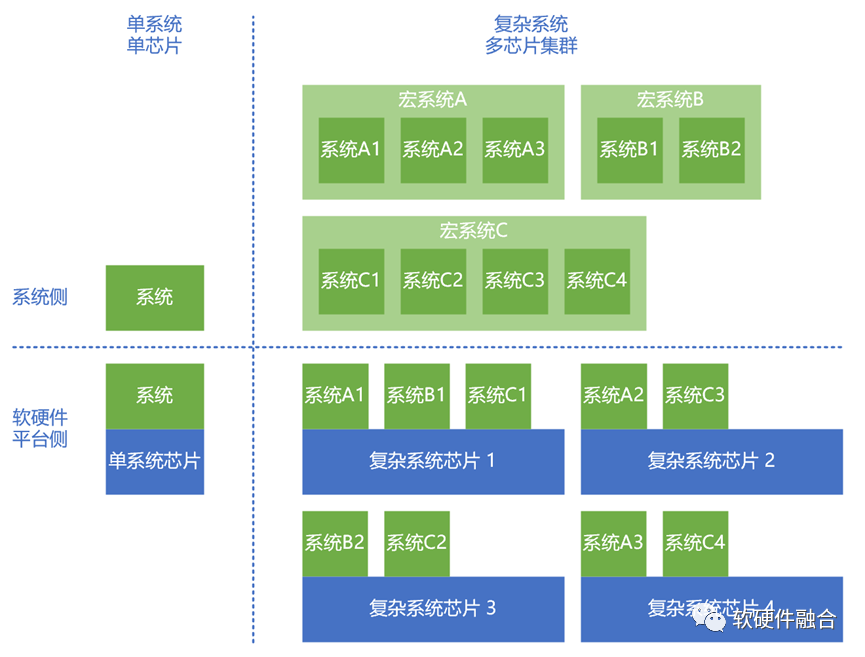
传统的情况下,一个芯片对应一个系统。我们关注业务常见的需求,并把它实现在芯片的功能和特征里。但在集群计算,特别是目前云网边端不断融合的超大集群计算形式下,则需要关注的是“以不变应万变”,即足够通用的、数以万计的计算设备组成的大规模计算集群,如何去覆盖数以百万计的众多计算场景的问题。
这样,对芯片内的资源弹性和芯片的可扩展性就提出了很高的要求,我们需要把数以万计的计算芯片的计算资源合并到一个计算资源池,然后还可以非常方便的快速切分和重组,供不同规格计算任务的使用。
3.3 芯片研发成本越来越高,需要芯片的大规模落地,来摊薄研发成本
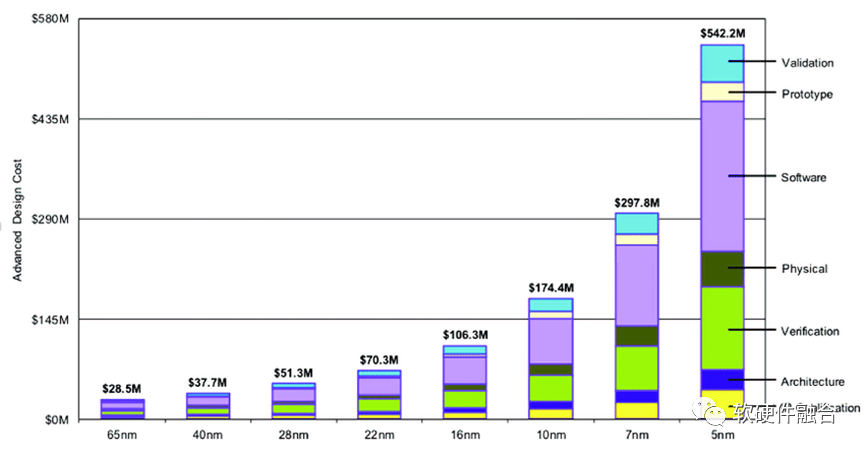
摩尔定律预示了:芯片工艺的发展,会使得晶体管数量大约每两年提升一倍。虽然工艺的进步逐步进入瓶颈,但Chiplet越来越成为行业发展的重点,这使得芯片的晶体管数量可以再一次数量级的提升。
在先进工艺的设计成本方面,知名半导体研究机构Semiengingeering统计了不同工艺下芯片所需费用(费用包括了):
28nm节点开发芯片只需要5130万美元;
16nm节点则需要1亿美元;
7nm节点需要2.97亿美元;
到了5nm节点,费用高达5.42亿美元;
3nm节点的研发费用,预计将接近10亿美元。
就意味着,大芯片需要足够通用,足够大范围落地,才能在商业逻辑上成立。做一个保守的估算:
终端场景,(大)芯片的销售量至少需要达到数千万级才能有效摊薄一次性的研发成本;
在数据中心场景,则需要50万甚至100万以上的销售量,才能有效摊薄研发成本。
4 超异构计算的载体:通用的超异构处理器
通用的超异构处理器(GP-HPU, General Purpose Hyper-heterogeneous Processing Unit, 通用超异构处理器),即能够覆盖几乎所有场景的、以超异构计算为基础架构的、综合性的大算力单芯片。
4.1 超异构计算的关键,在于各类加速处理器的高效交互
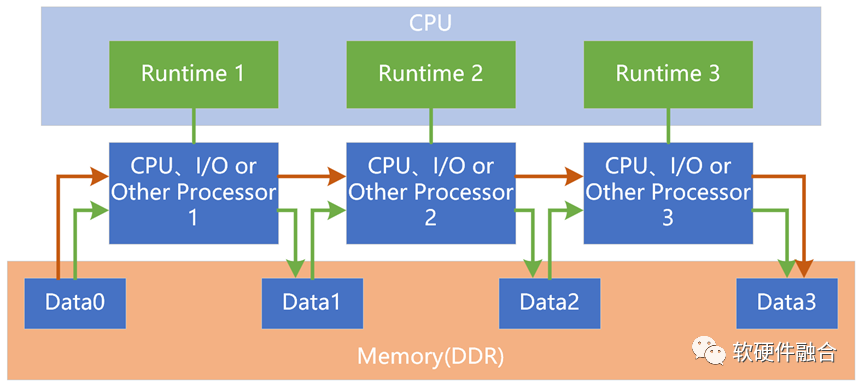
SOC和HPU都是多异构组成的混合计算,但SOC本质上属于异构计算,而HPU属于超异构计算。SOC仅仅是异构的集成,而HPU则需要实现异构的融合。
在SOC系统里,每个加速单元可以看做是CPU+加速单元组成一个异构子系统;不同的异构子系统之间在硬件上是没有必然联系,需要通过软件构建异构子系统之间的交互和协同。在CPU性能逐渐瓶颈的当下,这通常也意味着性能的约束。
而在HPU里,需要实现硬件层次的不同加速单元之间的直接的、高效的数据交互,不需要CPU的参与。在硬件层次,超异构需要实现CPU、GPU以及各种其他加速单元之间的对等的深度交互、协同和融合。
4.2 目前,多个独立芯片组成超异构计算,还比较难
依据性能/灵活性特征,可以将系统分为三个层次:
基础设施层。随着系统越来越复杂,在系统中,有很多非常确定性的任务,比如虚拟化、网络、存储等,这些可以称为基础设施型任务。这类任务因为其确定性的特点,特别适合DSA/ASIC级别的加速处理器处理。
另一个极端,即不太好加速的应用部分。在硬件平台上到底会运行什么样的应用,通常是不可预知的,或者说应用是非常不确定的。因此,针对应用,最好是用CPU(+协处理器)平台。CPU平台还有另外一个价值,兜底,凡是无法加速或者不存在合适加速处理器的工作任务都可以放在CPU平台处理。
处于两个极端之间的部分任务,则通常是性能敏感的应用任务,比如AI训练、视频图形处理、语音处理等。这类任务具有一定的确定性,但通常还是需要平台的一些弹性的能力,其性能/灵活性特征处于前面两个极端的中间。因此比较适合GPU、FPGA这样的处理器平台。
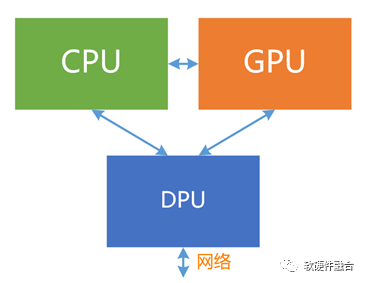
理论上,我们可以按照超异构计算的功能划分和系统交互,把三类功能实现在CPU、GPU和DPU三芯片里,但目前三者处于相互竞争的状态,三芯片协作的方式,本质上只能实现以CPU为中心的异构计算形态,而无法实现三者深度协同的超异构计算形态。
并且,三颗芯片,通常来自于不同的芯片公司,各个芯片都很难放弃以自己为核心的系统运行方式。要想这些芯片公司能够更多的考虑和其他芯片的协同,从而实现三芯片的通力合作,很难很难。
基于CPU、GPU和DPU三芯片的超异构计算,还有很长的路要走。
4.3 在单芯片层次,实现相对简单的超异构计算,是可行的路径

单芯片,不需要考虑和外部芯片的协同,只需要考虑内部不同单元间的深度交互。一切都在自己的掌控之下,因此单芯片超异构计算,是相对容易落地的实现方式。
此外,单芯片方式,也有其他的好处:
更高集成度,代表着更高的性能,以及更低的成本;
内部交互更高效,代表着没有各类性能瓶颈约束,可以实现更高的性能。
5 超异构计算的挑战,不在芯片集成,而在系统的融合和系统的可驾驭
5.1 硬件层次的多异构集成,不是难度
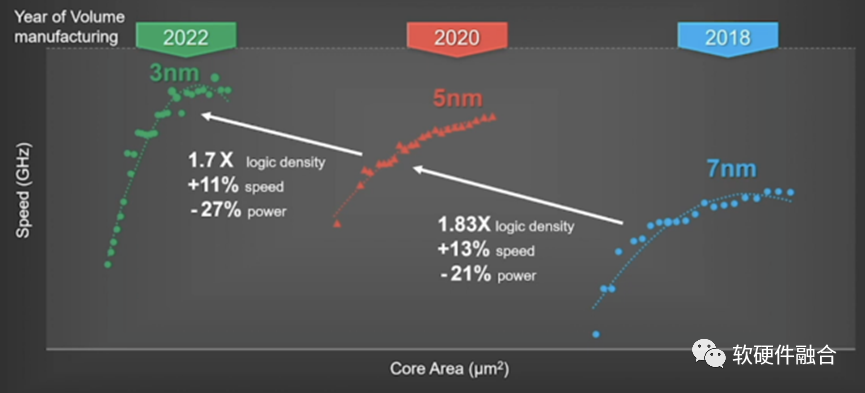
工艺持续进步、3D堆叠以及Chiplet多Die互联,使得芯片从2D->3D->4D。这些技术的进步,意味着在芯片这个尺度,可以容纳更多的晶体管,也意味着芯片的规模越来越大。
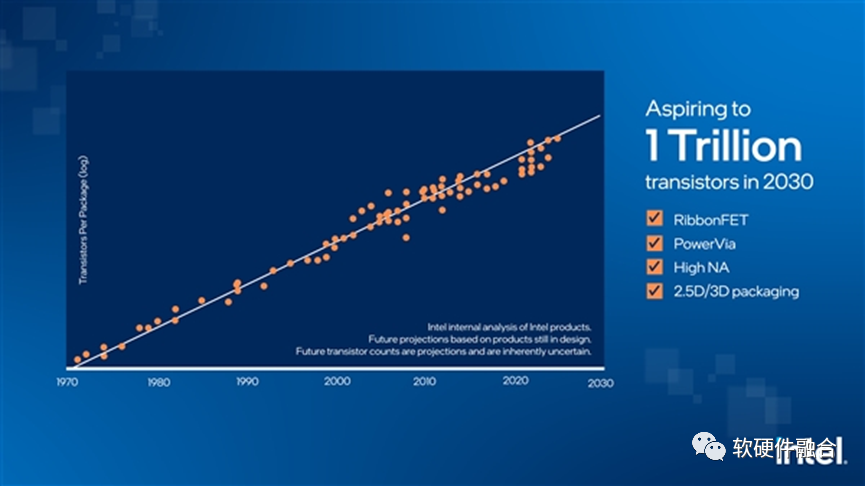
Intel宣布,在2030年,将实现单芯片层次集成1万亿晶体管,这意味着在单芯片层次,可以构建,相比目前,规模数量级提升的系统。
实现更多异构的集成,是芯片制造和封装的核心竞争力,不是芯片设计公司(Fabless)的核心竞争力。
5.2 挑战在于,软件层次,如何把多个系统整合到一个宏系统

我们以自动驾驶汽车中央控制器CCU为例。Thor能够实现多域融合计算,它可以为自动驾驶和车载娱乐划分任务。通常,这些各种类型的功能由分布在车辆各处的数十个控制单元控制。制造商可以利用Thor实现所有功能的融合,来整合整个车辆,而不是依赖这些分布式的ECU/DCU。
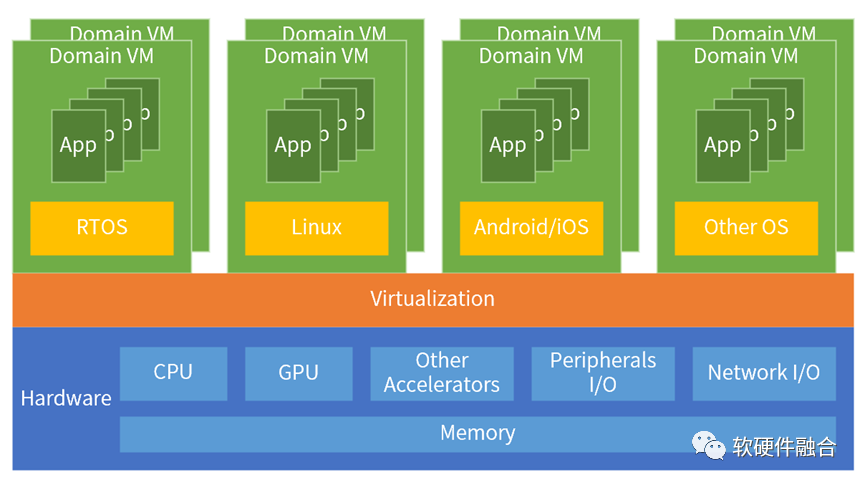
传统SOC是单芯片单系统,而Thor实现了单芯片多个系统共存。在一个硬件上,把多个架构不同的系统整合成一个宏系统,则涉及到整个系统软硬件架构的重构。
在系统和架构层面,如何实现更多系统的融合,是芯片设计公司的核心竞争力。
5.3 更大的挑战在于,如何让超异构更好驾驭
串行计算符合人类思维,编程相对最简单;同构并行的编程,就要复杂很多;异构并行,则更是难上加难;那么超异构并行呢?那就是难上加难再加难。
要想驾驭超异构,核心的思路跟驾驭异构计算的思路一致,就是要想方设法降低软硬件系统的复杂度。一些典型的降低复杂度的方法:
复杂大系统分解成简单小系统,实现芯片内部的分布式计算,每个内部子节点的复杂度较低,更加可控一些。
依据系统的性能/灵活性特征进行分层。不同层次,采用不同的处理策略。
开放:让处理器架构和生态收敛,防止碎片化。同时,行业内也能相互分工协作,而不是一家公司面对所有问题。
软硬件深度融合,让硬件具有更多软件的能力。
6 第三代通用计算,“大算力芯片”的未来
CPU同构是第一代通用计算,成就了Intel的王者地位;GPU异构是第二代通用计算,随着人工智能的火爆,远超Intel、AMD和高通的总和。
但技术发展不会停止。随着AI大模型、自动驾驶、元宇宙等超高算力需求的领域快速发展,算力仍需持续快速提升,算力成本必须数量级下降,计算架构需要从同构、异构走向多种异构融合的超异构。
审核编辑:刘清
-
最新半导体芯片龙头股有哪些2021-12-14 46673
-
芯片板块龙头股一览表2021-12-13 39960
-
芯片股份龙头股一览表2021-12-10 8146
-
电子芯片龙头股票有哪些2021-12-09 4135
-
最新芯片龙头股一览表2021-12-08 20490
-
PCB概念上涨的逻辑是什么_龙头股有哪些?2018-07-23 17427
-
最新大数据概念股龙头_大数据概念龙头股有哪些2018-01-05 49242
-
2017年智能医疗龙头股_最新智能医疗概念龙头股一览2018-01-02 45716
全部0条评论

快来发表一下你的评论吧 !
