

浅析HLS的任务级并行性
描述
HLS的任务级并行性(Task-level Parallelism)分为两种:一种是控制驱动型;一种是数据驱动型。对于控制驱动型,用户要手工添加DATAFLOWpragma,工具会在该pragma指定的区域内判别任务之间的并行性,生成各进程之间的模块级控制信号。对于数据驱动型,用于需要明确指定可并行执行的任务。
从描述手段来看,控制驱动型本质上是由工具判定各任务能否并行执行。用户在对各函数描述时只要遵守DATAFLOW的要求即可。例如:读取输入数据应该位于DATAFLOW区域的起始位置,写入输出数据应位于该区域的终止位置。DATALOW区域内的所有变量遵循“一次读一次写”原则。除非使用hls::stream,否则不支持反馈支路。不支持在指定条件下才执行函数。不支持for在指定条件下退出(使用break语句)。但控制驱动型比较灵活,这是因为DATAFLOW的作用对象可以是for循环也可以是函数。
控制驱动器适合于顺序执行的C函数。控制驱动型模型带来的好处包括:当前函数在结束执行之前后续函数可以开始执行;函数在结束执行之前可以重新开始执行;两个或更多顺序函数可以同时开始执行。我们看一个例子。如下图所示,顶层函数diamond调用了4各函数funcA~funcD。
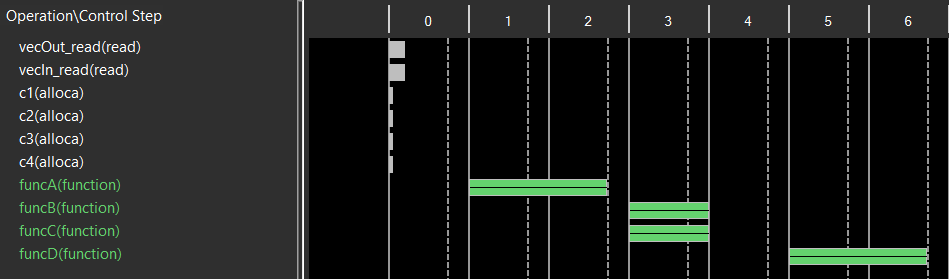
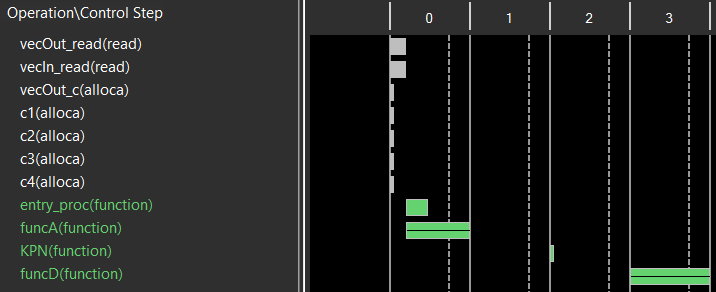
在没有添加DATAFLOW的情况下,工具能自动探测出funcB和funcC的并行性,这可从Schedule视图中看到,如下图所示。
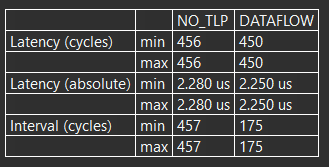
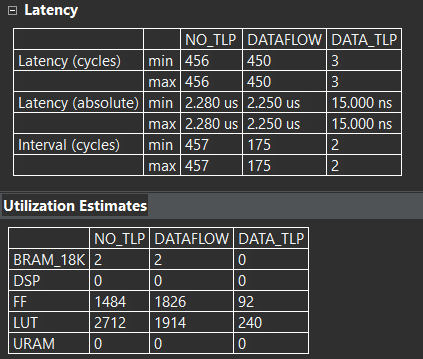
添加DATAFLOW之后,对两者性能进行对比,如下图所示(NO_TLP为没有添加DATAFLOW的solution),从Latency角度看,两者相当,但从interval角度看,DATAFLOW带来的效果还是很明显的。Interval从457降到了175。
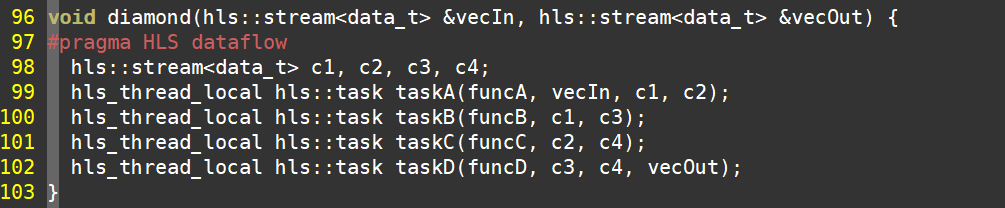
再看数据驱动型。数据驱动型要求任务之前以stream作为接口,允许反馈支路。用户需要明确通过hls::task指定可并行执行的任务。对于上述函数,我们可以将其改造为数据驱动型,如下图所示。代码第98行声明了4个stream,第99行~第102行通过hls::task指定并行任务。
将三者放在一起对比,如下图所示。可以看到数据驱动型无论在性能还是资源上都获得最佳表现。
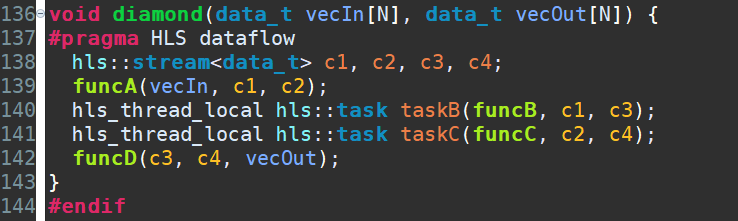
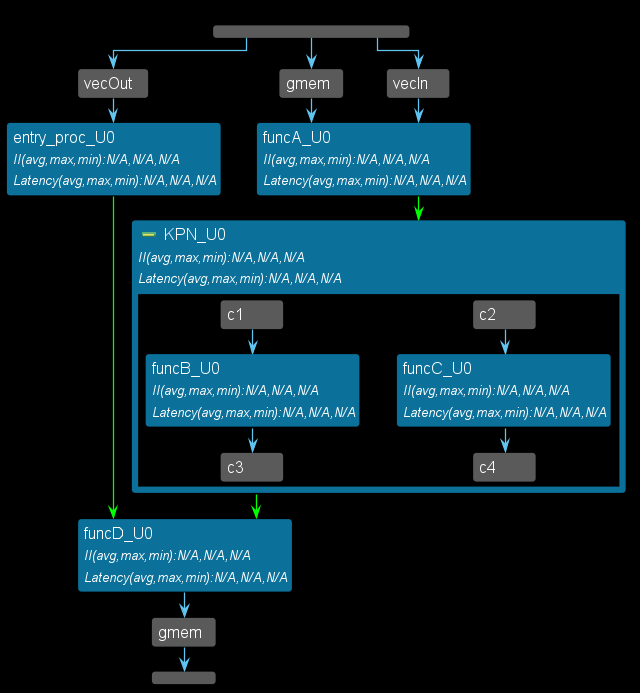
那么两种类型能否混合使用呢?答案是肯定的,但是有限制的,这源于两者的自身特征。可以在控制驱动型中嵌入数据驱动型,但反过来是不允许的。我们将上面的例子改造为控制驱动型嵌入数据驱动型的模式,如下图所示。这里需要注意的是代码第137行的DATAFLOWpragma,同时代码第141行和第142行都设置了task,task接口为stream。此外也给出了Vitis HLS的Schedule视图和Dataflow视图。Dataflow视图中也显示了KPN。
审核编辑:刘清
-
基于HLS之任务级并行编程2023-07-27 2312
-
Python中的并行性和并发性分析2020-08-21 3412
-
阻止任务级别并行性的常见情况2021-03-09 11125
-
浅析java异步回调和同步回调2021-10-19 1147
-
HLS-1Hin人工智能训练系统2023-08-04 3478
-
算法隐含并行性的物理模型2009-10-21 516
-
英特尔架构中的多线程优化和扩展并行性的编程技术2018-11-01 3544
-
矢量化数据并行性的程序方面的作用2018-11-06 3142
-
如何在不需要特殊库或类的情况下实现C代码并行性?2021-02-11 2063
-
Dataflow | 粗粒度并行优化的任务级流水2021-03-02 1145
-
HPEC应用子程序线程推测并行性实验分析2021-03-30 1016
-
通过利用现代处理器架构的并行性提高SDR的性能2022-06-14 1964
-
研讨会:如何利用最新Vitis HLS提高任务级并行性?2023-07-05 1464
-
Vitis HLS:使用任务级并行性的高性能设计2023-09-13 612
全部0条评论

快来发表一下你的评论吧 !
