

Meta:正在多款自研芯片上使用RISC-V
EDA/IC设计
描述
在DAC 2023上,Meta 的 ASIC 工程经理 Himanshu Sanghavi 谈到了 Meta 正在使用 RISC-V 开展的各种项目。他表示,定制指令是“我们决定采用 RISC-V 架构的关键因素”,因为 Meta 从 IP 提供商处定制 RISC-V 内核,“以加速计算、降低能耗并创建更灵活的 ASIC”。
Sanghavi 进行了更详细的介绍:“我在 Meta 的团队正在开发基于 RISC-V 的 ASIC,用于视频转码以及机器学习应用。这些 ASIC 正在我们的数据中心运行一些计算最密集的工作负载。这些是大型、高性能的设备,由多个不同的处理器、硬件加速器、内存系统、接口 IP 组成,全部位于一个芯片上。大约四年前,当我们开始这项工作时,我们评估了多种不同的处理器架构,并决定对这些 SoC 的一些关键插槽采用 RISC-V。这一选择的驱动因素是 RISC-V 是一种开放架构,并且有多个处理器 IP 提供商实现了该架构。快进到今天,Meta现在有几个可用的 ASIC,它们使用 RISC-V 处理器进行控制处理和数据处理。特别是后者确实使用自定义指令。为一些对我们的工作负载很重要的专门计算定义的自定义指令,以及在同一芯片上的处理器内核和硬件加速器之间构建自定义接口。”
Meta自研芯片计划详情
Meta 最近发布了一系列与其内部 AI 基础设施和芯片相关的公告。其中一些主题包括迁移到具有更多液体冷却、更高功率和设施级别变化的数据中心。在硅方面,有趣的是,Meta 正在采取与谷歌完全相同的策略。
Meta 只是在谈论他们已经拥有的旧芯片,就像新的东西已经准备就绪一样。例如,他们在去年使用 16,000 个 Nvidia A100 构建的研究集群上发布了整个博客,只是在他们已经开始使用 H100 构建更大的集群之后。正如我们过去报道的一样,H100 集群的基础设施设置非常奇怪。
本问将涵盖 Meta 自 2021 年以来拥有的旧芯片以及 Meta 目前正在开发的新芯片。我们将讨论架构、路线图、各种设计合作伙伴和未来的抱负。
Meta可扩展视频处理器 (MSVP)
Meta 展示了他们自 2021 年以来一直在部署的视频编码 ASIC。视频编码 ASIC 对公司来说是非常重要的基础设施。例如,这是亚马逊不得不通过 Twitch 提供比谷歌的 YouTube 差得多的直播服务的主要原因。
谷歌是第一个设计视频编码芯片的公司,代号为 Argos,我们在多年前就介绍过了Google的布局。大规模部署的谷歌 Argos VPU 完成了超过 1000 万个英特尔 CPU 的 VP9 编码工作.,这为谷歌节省了数十亿美元的成本。我们 We have 还介绍了 NetInt 的 VCU,这是一家拥有类似视频编码 ASIC 的初创公司,他们设计的产品正在出售给字节跳动、百度、腾讯和阿里巴巴等公司。
Meta 有大量视频上传到 Instagram 和 Facebook,因此该产品对于降低成本至关重要。此外,第二M代ndMeta 的可扩展视频处理器使他们能够如此普遍地在卷轴中部署 AV1。注意 Meta今天只公开了第一代。
Meta 声称该芯片是内部开发的,但事实并非如此。宣布的 MSVP 和即将推出的下一代版本都是与 Broadcom 共同设计的。Google 的前两代视频编码 ASIC 也是与 Broadcom 共同设计的。
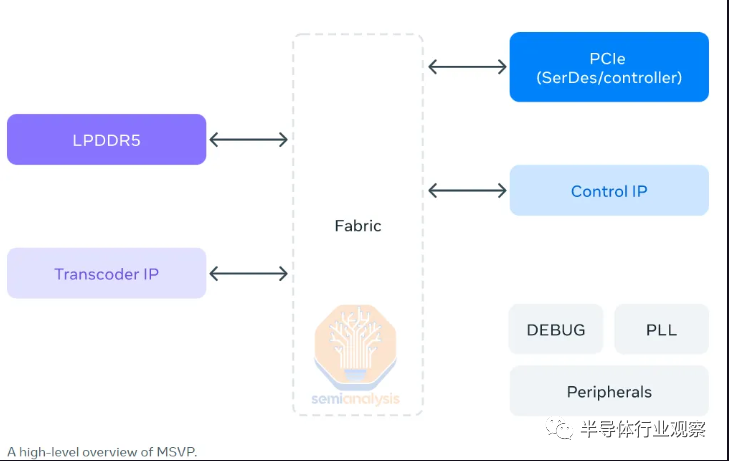
每个 MSVP ASIC 芯片都拥有 4K 的最大转码能力,在最高质量设置下以 15fps 的速度运行,配置为一个输入流到五个输出流。它能够在标准质量配置下以 60fps 的速度扩展到 4K。Meta 声称性能随着分辨率的增加而统一。所有这些都是通过 PCIe 模块大约 10W 的功率使用来实现的。H.264 性能提升 9 倍,VP9 性能提升 50 倍。
该芯片采用 M.2 22110 格式,支持 4 条 PCIe Gen 4 通道,即 8GB/s。展示的主板中还有 2 个 4GB 的 Micron LPDDR5,总共 8GB,内存带宽为 88GB/s。封装约为 24mm x 19mm,芯片尺寸约为 112mm^2。
Meta训练和推理加速器 (MTIA)
人工智能是Meta 数据中心中最重要、成本最高的工作负载。Meta 至少从 2019 年就开始开发他们的 AI 芯片。第一代刚刚发布,虽然处理器类别被命名为 Meta Training 和 Inference Accelerator,但需要明确的是,第一代仅可用于推理。
Meta 的主要工作负载是当今的推理DLRM inference,因此,他们尝试构建他们的芯片,尤其是针对该工作负载。提醒一下,DLRM 模型仍然是最大的大规模 AI 工作负载。这些 DLRM 是百度、Meta、字节跳动、Netflix 和谷歌等公司的支柱。它是广告、搜索排名、社交媒体订阅等方面年收入超过一万亿美元的引擎。
虽然生成式人工智能很快就会在硬件需求方面超过它,但这种转变还没有完全发生。
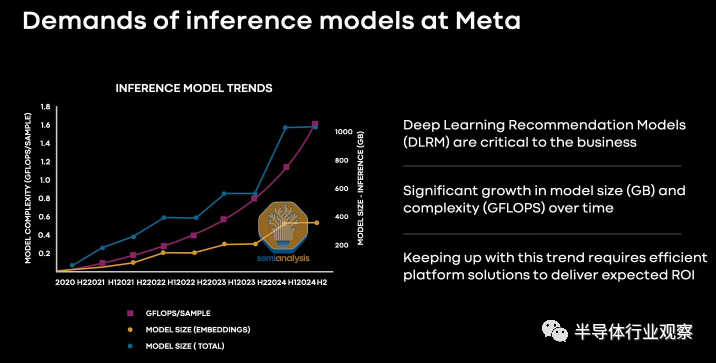
DLRM 模型正在持续增长,这导致 Meta 的基础架构发生重大变化。有一段时间,他们大量使用英特尔的 NNP-I 推理加速器,但很快就让位给了 GPU。在某些方面,第一代 MTIA 可以被认为是第二代 NNP-I,因为系统架构(不是 uarch)非常相似。
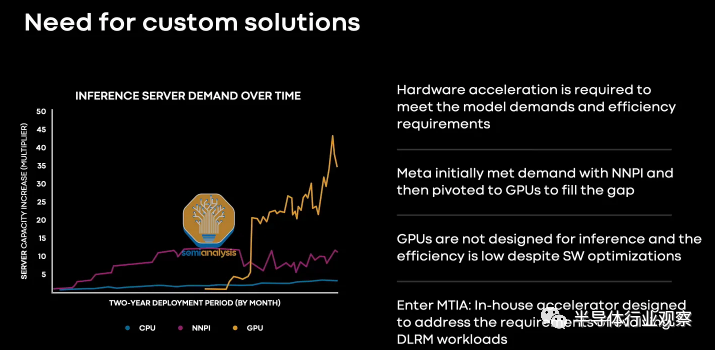
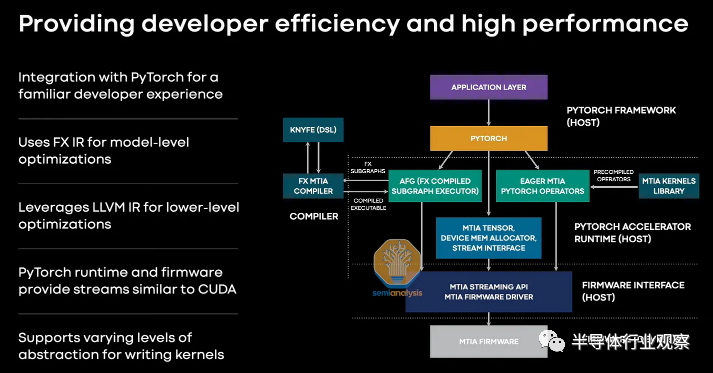
Meta 多年前就推出了他们的半定制 AI 加速器项目,他们的目标非常明确。更好的 DLRM 模型和易用性的推理成本更低。他们的第一代可以被认为是一种软件工具,用于开发利用 PyTorch 2.0 的急切模式和全图模式与 LLVM 编译器的能力。他们正在致力于实施 Dynamo、Inductor 和 Triton。
我们的数据显示,Meta 是今年 Nvidia H100 GPU 的最大个人买家。这不是巧合。Meta 需要 GPU 来进行训练和推理,而在大多数情况下,H100 是满足这种需求的最具成本效益的方式。
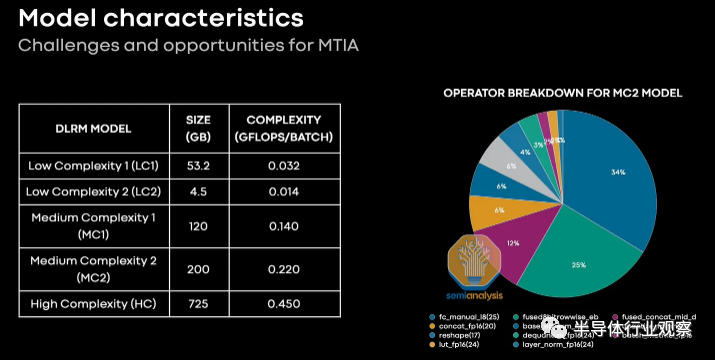
Meta 分享了他们各种生产推荐模型的概况。这些模型具有不同的大小和复杂性。Meta 还分享了各种硬件在这些工作负载中的性能。
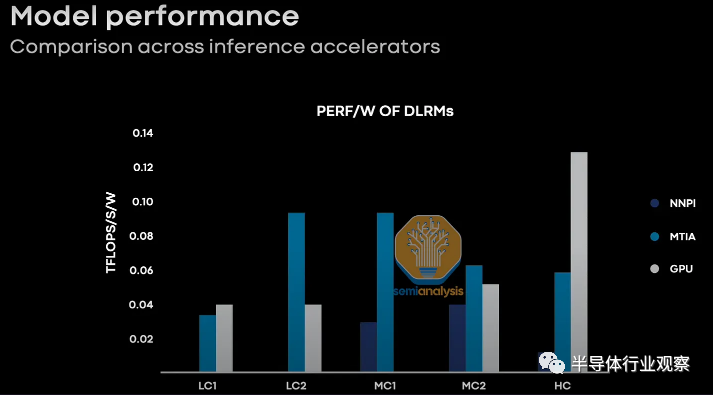
虽然 Meta 没有分享他们比较的 GPU,但我们四处询问,似乎是旧的 Ampere GPU,而不是新的 Hopper 和 Lovelace GPU。虽然这看起来不公平,但请记住 Meta 的第一代stMTIA 也是一款较旧的芯片。一旦您叠加了新的 Nvidia 芯片的额外性能,第一代 MTIA 在每瓦性能方面失去了大部分工作负载。
话虽如此,第一代 MTIA 只是一个开始。
Meta 在 2021 年获得了视频中的芯片。MTIA 在台积电的 7nm 晶圆厂制造,并由 Amkor 封装。芯片标记表明这发生在 2021 年 8 月 23 日至8 月 29日。
该芯片具有 102.4 TOPS 的 INT8 和 51.2 TFLOPS 的 FP16 以及 25W TDP。共有 128 MB SRAM,运行速度为 800GB/s。该 SRAM 位于内存控制器旁边,可以充当直接寻址为可寻址内存的内存端缓存。在以 176GB/s 运行的 256 位总线上还有高达 128GB 的 LPDDR5-5500。值得注意的是,Meta 使用了能够达到 6400 MT 的 LPDDR5,但以降频运行。还有 8 个 PCIe 4.0 通道。

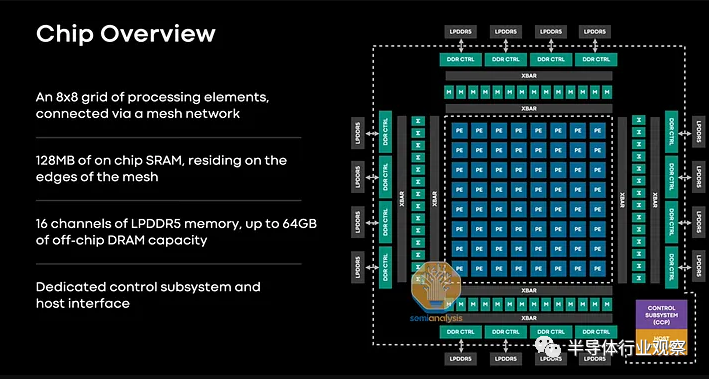
内存和 IO 位于处理元件周围。这些处理元素是一个 8 x 8 的网格,其中包含一个命令处理器、本地内存和两个不同的 RISC-V CPU。一个内核只有标量能力,而另一个内核既可以标量也可以矢量。这些内核是从第三方 IP 机构获得许可的。该第三方不协助后端。
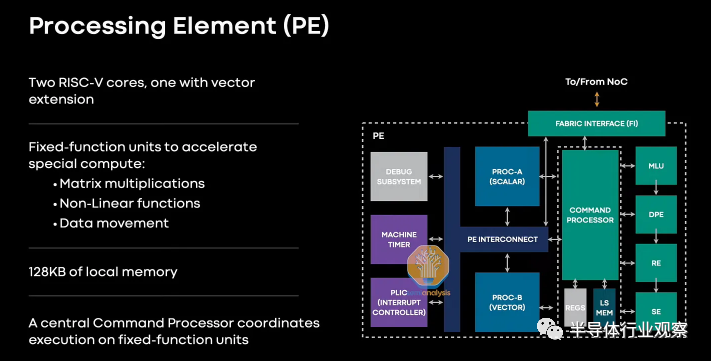
还有各种固定加速器来加速矩阵乘法、非线性函数和数据移动。
实际上,该芯片位于 Delta Lake 服务器中的 PCIe Gen 4x8 双 m.2 卡上,连接到 Intel Copper Lake CPU,具有 96GB DDR4 和 PCIe 3.0 x24 连接到嵌套交换机(80 通道 Broadcom PCIe4 交换机)。
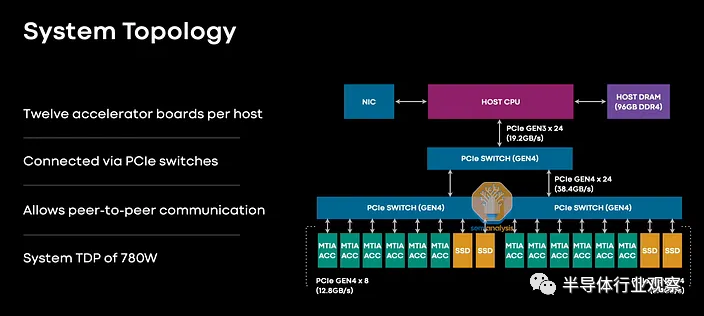
每台主机有12x MTIA,整个系统功耗780W。
审核编辑:刘清
-
印度靠RISC-V走上自主之路2022-09-19 2779
-
从授权到自研内核,汽车MCU大厂倒戈RISC-V?2023-12-05 3351
-
学习RISC-V单片机的感想2024-02-17 5238
-
瑞萨电子推出采用自研RISC-V CPU内核的通用32位MCU2024-03-30 1344
-
RISC-V Summit China 2024 | 青稞RISC-V+接口PHY,赋能RISC-V高效落地2024-08-30 1830
-
关于RISC-V芯片的应用学习总结2025-01-29 1921
-
沁恒微电子受邀参加首届RISC-V中***会2021-06-17 5652
-
RISC-V应用领域的拓展2021-06-18 2760
-
RISC-V,正在摆脱低端2023-05-30 2161
-
时擎科技研:RISC-V指令架构对智能芯片的赋能2023-03-31 795
-
Meta自研RISC-V AI推理芯片2023-05-20 3294
-
爱普特MCU的“国产创新”:纯国产RISC-V内核+全自研IP库2022-04-15 2741
-
瑞萨推出采用自研CPU内核的通用32位RISC-V MCU 加强RISC-V生态系统布局2024-03-28 1491
-
瑞萨电子推出业界首款自研通用型32位RISC-V MCU内核2024-05-17 2350
-
原来,它们用的都是国产RISC-V芯片2025-04-02 1546
全部0条评论

快来发表一下你的评论吧 !
