

【AI简报20230728期】医疗领域中的AI大模型,详解C++从零实现神经网络
描述
1. 生成式AI如何在智能家居中落地?
原文:https://mp.weixin.qq.com/s/hW7z0GFYe3SMKRiBizSb0A
作为一种通过各种机器学习方法从数据中学习对象的组件,进而生成全新的、完全原创的内容(如文字、图片、视频)的AI。生成式AI近年来发展非常迅速,它可以实现新的应用和用途,创造新内容的能力为新的应用开辟了许多可能性,尤其在智能家居中,生成式AI更是大有可为。
通过生成式AI,智能家居可以学习家庭成员的行为模式,了解他们的喜好和需求,并根据这些信息来自主地控制家庭设备和环境,让智能家居更好地为用户服务。例如,生成式AI可以用于智能音箱、家庭陪护机器人等为代表的智能家居产品。
生成式AI如何赋能智能家居
尽管从2022年底的ChatGPT爆火以后,人们对于生成式AI已经不陌生,但大多数应用依然聚焦在文字应用或图片创作上,想要将这种AI进行实际应用,业内还在探索中。为此,电子发烧友网采访到了思必驰IoT产品总监任毫亮,探讨如何让生成式AI赋能智能家居。
生成式AI必然会对智能家居行业带来不小的影响,任毫亮表示,思必驰正在从多方面设计和思考它在行业内的应用,目前主要集中在两个方面。
一个是智能语音交互,生成式AI能够更加智能地理解和回应用户的语音指令,以更加智能和自然的方式与智能家居进行交互,实现更高效、便捷的控制和操作,在语音交互上会有显著的提升。
另一个则是针对方案设计、产品设计,生成式AI能够为用户提供完整科学的智能家居方案,依据不同场景、不同设备以及用户个性化偏好进行方案和产品设计,提升家居设计师的工作效率,精准匹配用户需求,为用户提供更加智能、便捷、安全和个性化的智能家居体验。
7月12日,思必驰推出了自研对话式大模型DFM-2(Dialogue Foundation Model),中文直译为“通用对话基础模型”。未来将围绕“云+芯”战略,以对话式AI为核心,将DFM-2大模型技术与综合全链路技术进行结合,不断提升AI软硬件产品的标准化能力和DUI平台的规模化定制能力,快速满足智能汽车、智能家居、消费电子,以及金融、轨交、政务等数字政企行业场景客户的复杂个性化需求,打造行业语言大模型,赋能产业升级。
为进一步满足市场的个性化需求,思必驰将DUI平台与DFM-2大模型相结合,推出DUI 2.0,完成对话式AI全链路技术的升级,推进深度产业应用,未来也将继续深入到智能家居等应用场景,解决行业问题。
解决智能家居智能化与个性化难题
想要将生成式AI彻底融入进智能家居体系当中,厂商们也做了许多思考。任毫亮认为,生成式AI主要可以解决智能家居中智能化与个性化难题。
在智能交互上,生成式AI能够更加智能地理解用户的内容,同时结合用户的设备、场景、习惯等内容综合分析判断,给出更准确和个性化的回复;用户可以输入更长的文本、更个性化的内容,针对不同用户、不同时间、不同内容,生成式AI会给出不同的回答、不同的音色;同时AI具有更强的学习能力,在使用中会感受到越来越懂你的AI管家。
任毫亮表示生成式AI会是更加智能更加专属的AI管家;思必驰的DFM-2也给DUI带来了2.0的升级,基于深度认知的泛化语义理解、外部资源增强的推理问答、基于文档的知识问答、个性化的多人设交互、模糊语义自学习,会将以上特性应用在智能家居、智能家电、智能车载等解决方案中。
在智能识别场景中,生成式AI通过学习和分析大量数据,并根据识别结果进行自动化调节和控制,提供更加个性化和智能化的服务。同时,生成式AI还可以帮助智能家居系统进行能源消耗的优化管理,通过对居住者行为的学习和分析,系统可以自动调整能源使用模式,减少不必要的能源浪费,实现智能节能管理。
而在这些场景中,都是依靠AI的学习能力、理解能力以及越来越多传感器数据的输入与分析,来实现自动化的设备控制和场景控制,同时基于用户的反馈机制,不断提升主动智能的体验,达到真正的全屋智能化。
小结
随着未来Matter等通用协议将智能家居体系完全打通,生成式AI将为智能家居的体验带来飞跃式提升,包括在智能语音交互、智能化、个性化等方面。随着AI技术的进一步增强,生成式AI也将成为智能家居未来重要的一环。
2. 高通:未来几个月有望在终端侧运行超100亿参数的模型
原文:https://mp.weixin.qq.com/s/63Pm51oisGr03fl2bSoJ0w
日前,在2023世界半导体大会暨南京国际半导体博览会上,高通全球副总裁孙刚发表演讲时谈到,目前高通能够支持参数超过10亿的模型在终端上运行,未来几个月内超过100亿参数的模型将有望在终端侧运行。
大模型在终端侧运行的重要性
生成式AI正在快速发展,数据显示,2020年至2022年,生成式AI相关的投资增长425%,初步预估生成式AI市场规模将达到1万亿美元。
然而孙刚指出,云经济难以支持生成式AI规模化拓展,为实现规模化拓展,AI处理的中心正在向边缘转移。比如XR、汽车、手机、PC、物联网,生成式AI将影响各类终端上的应用。
高通在这方面展示出了领先的优势,高通AI引擎由多个硬件和软件组件组成,用于在骁龙移动平台上为终端侧AI推理加速。它采用异构计算架构,包括高通Hexagon处理器、Adreno GPU、Kryo CPU和传感器中枢,共同支持在终端上运行AI应用程序。
在7月初的2023年世界人工智能大会上,高通就已经展示了全球首个在终端侧运行生成式AI(AIGC)模型Stable Diffusion的技术演示,和全球最快的终端侧语言-视觉模型(LVM)ControlNet运行演示。这两款模型的参数量已经达到10亿-15亿,仅在十几秒内就能够完成一系列推理,根据输入的文字或图片生成全新的AI图像。
今年7月18日,Meta官宣将发布其开源大模型LLaMA的商用版本,为初创企业和其他企业提供了一个强大的免费选择,以取代OpenAI和谷歌出售的昂贵的专有模型。随后,高通发布公告称,从2024年起,Llama 2将能在旗舰智能手机和PC上运行。
高通技术公司高级副总裁兼边缘云计算解决方案业务总经理Durga Malladi表示,为了有效地将生成式人工智能推广到主流市场,人工智能将需要同时在云端和边缘终端(如智能手机、笔记本电脑、汽车和物联网终端)上运行。
在高通看来,和基于云端的大语言模型相比,在智能手机等设备上运行Llama 2 等大型语言模型的边缘云计算具有许多优势,不仅成本更低、性能更好,还可以在断网的情况下工作,而且可以提供更个性化、更安全的AI服务。
如何让大模型在终端规模化扩展
生成式AI进入未来生活的趋势已经不可阻挡,为了让生成式AI规模化扩展到更多终端设备中,高通提出了混合AI架构的运行方式,即在云端和设备终端的边缘侧之间分配算力,协同处理AI工作负载。
所谓混合AI,是指充分利用边缘侧终端算力支持生成式AI应用的方式,相比仅在云端运行的AI,前者能够带来高性能、个性化且更安全的体验。
比如,如果模型、提示或生成内容的长度小于某个限定值,且精度足够,推理就可以完全在终端侧进行;如果任务相对复杂,则可以部分依靠云端模型;如果需要更多实时内容,模型也可以接入互联网获取信息。
在未来,不同的生成式AI用不同分流方式的混合AI架构,AI也能在此基础上持续演进:大量生成式AI的应用,比如图像生成或文本创作,需求AI能够进行实时响应。在这种任务上,终端可通过运行不太复杂的推理完成大部分任务。
在AI计算的实现上,软件和硬件同样重要,因为必须在端侧做到运算更快,效率更高,并推动AI应用在广泛终端上的部署和普及。
高通在2022年6月推出AI软件栈(Qualcomm AI Stack),其支持包括TensorFlow、Pytorch和ONNX在内的所有主流开发框架,所有runtimes(运行时,即某门编程语言的运行环境)和操作系统。借助高通AI软件栈,开发者在智能手机领域开发的软件可以快速扩展至汽车、XR、可穿戴设备等其他产品线进行使用。
高通技术公司产品管理高级副总裁兼AI负责人Ziad Asghar表示,未来公司需要加大终端侧技术上的研发,尤其是进一步提升量化的算法。例如服务器上训练的模型一般采用32位浮点运算(FP32),而我们在手机端现在能够支持INT4计算,这能大大提高端侧的处理能力。
小结
不仅仅是大模型的训练需要极大的算力和功耗,部署也同样如此。如果要让大模型在更多的领域实现落地应用,除了在云端部署之后,在终端侧部署也很关键。目前已经有诸多厂商在该领域进行探索,包括高通,期待未来大模型能够走进人们生活的方方面面。
3. AI大模型在医疗领域起飞
原文:https://mp.weixin.qq.com/s/yNRpRIVntYv2cmU9GOCLzg
ChatGPT等大型语言模型在语言理解、生成、知识推理等方面正展现出令人惊艳的能力。近段时间,各企业开始探索大模型在不同行业中的应用落地,并针对不同领域推出相对应的行业大模型,包括在医疗领域。
众多企业宣布推出医疗大模型
日前,京东发布了京东言犀大模型、言犀AI开发计算平台,同时基于京东言犀通用大模型,京东健康发布了“京医千询”医疗大模型,可快速完成在医疗健康领域各个场景的迁移和学习,实现产品和解决方案的全面AI化部署。
与通用大模型相比,京东言犀大模型融合70%通用数据与30% 数智供应链原生数据,具有“更高产业属性、更强泛化能力、更多安全保障”的优势。在医疗服务领域,京东言犀AI开发计算平台为客户的大模型开发和行业应用提供了定制化解决方案。
在2023京东全球科技探索者大会暨京东云峰会现场,京东演示了将通用大模型转化为健康产业大模型的操作。通常来说,从数据准备、模型训练到模型部署,客户完成这套流程需要10余名科学家花费一周时间,而利用言犀AI开发计算平台,只需要1-2名算法人员在数分钟就能完成;通过平台模型加速工具的优化,还能节省90%的推理成本。
在前不久的2023世界人工智能大会健康高峰论坛上,联影智能联席CEO周翔表示,医疗领域不同于其他垂直领域,目前通用的语言大模型还不能完全满足医疗场景的精准需求。联影智能正与复旦大学附属中山医院共同携手开发多模态、多病种的“全病程智医诊疗大模型”。
该款AI大模型汇聚中山医院优质诊疗经验,是覆盖患者入院到出院的全生命周期的智能化辅助系统。在患者入院阶段,该模型可基于医生与患者的沟通对话、体格检查及病史等信息,辅助生成医疗级结构化入院记录,智能推荐术前检查,并作出鉴别诊断建议及手术计划初稿;在术中通过多模态信息整合完成手术记录稿;在患者出院阶段,可以起草出院记录及术后随访计划。目前该款大模型已完成第一阶段的站点试用。
东软也于近日表示面向医疗领域推出多款AI+医疗行业应用,包括添翼医疗领域大模型、飞标医学影像标注平台4.0、基于WEB的虚拟内窥镜等。
添翼医疗领域大模型是东软基于30多年的医疗行业积累,构建的医疗垂直领域大模型,全面融入医疗行业解决方案、产品与服务,赋能医院高质量发展,引领医疗智能化转型。面向医生,添翼让诊疗更高效。医生通过自然语言与添翼交互,快速、精准地完成医疗报告与病历、医嘱开立;面向患者,添翼让问诊更便捷,成为患者全天私人专属医生,提供全面的诊后健康饮食、营养与运动建议等服务。添翼的多模态数据融合能力,也将为医院管理者提供对话式交互与数据洞察,简化数据利用,让医院管理更精细。
大模型在医疗领域的优势和不足
大模型在医疗领域可以有很好的表现,此前,谷歌和DeepMind的科研人员在《自然》杂志上发表了一项研究,根据其研究结果,一组临床医生对谷歌和DeepMind团队的医疗大模型Med-PaLM回答的评分高达92.6%,与现实中人类临床医生的水平(92.9%)相当。
此外谷歌医疗大模型Med- PaLM仅5.9%的答案被评为可能导致“有害”结果,与临床医生生成的答案(5.7%)的结果相似。
不过相较于其他领域,大模型在医疗领域的落地会面临更加复杂的挑战。比如,医疗行业的专业性更高,医疗场景对问题的容错率较低,这对大语言模型有更高的要求,需要更专业的语料来给出更专业、更精准的医疗建议;不同模态的医疗数据之间,成像模式、图像特征都有较大差异,医疗长尾问题纷繁复杂;医疗数据私密性、安全性要求高,满足医疗机构本地环境部署要求也是大模型落地的重要考虑因素等。
针对各种问题,不少企业已经做了很多工作,比如商汤借助商汤大装置的超大算力和医疗基础模型群的坚实基础,打造了医疗大模型工厂,基于医疗机构的特定需求帮助其针对下游临床长尾问题高效训练模型,辅助机构实现模型自主训练。
商汤科技副总裁、智慧医疗业务负责人张少霆表示,该模式突破了医疗长尾问题数据样本少、标注难度高的瓶颈,实现了针对不同任务的小数据、弱标注、高效率的训练,同时显著降低了大模型部署成本,满足不同医疗机构个性化、多样化的临床诊疗需求。
小结
可以看到,当前大模型应用落地是业界探索的重点,而医疗行业成了众多企业关注的垂直领域之一。研究显示,大模型在医疗领域将会有着非常优秀的表现。同时医疗领域也不同于其他行业,它具有更强的专业性、安全性要求,这也是医疗大模型落地需要解决的问题。
4. GPT-4里套娃LLaMA 2!OpenAI创始成员周末爆改「羊驼宝宝」,GitHub一日千星
原文:https://mp.weixin.qq.com/s/Tp4q8VflEZ7o8FgpZfrNgQ
大神仅花一个周末训练微型LLaMA 2,并移植到C语言。
推理代码只有500行,在苹果M1笔记本上做到每秒输出98个token。
作者是OpenAI创始成员Andrej Karpathy,他把这个项目叫做Baby LLaMA 2(羊驼宝宝)。
虽然它只有1500万参数,下载下来也只有58MB,但是已经能流畅讲故事。

所有推理代码可以放在C语言单文件上,没有任何依赖,除了能在笔记本CPU上跑,还迅速被网友接力开发出了各种玩法。
llama.cpp的作者Georgi Gerganov搞出了直接在浏览器里运行的版本。

提示工程师Alex Volkov甚至做到了在GPT-4代码解释器里跑Baby LLaMA 2。
羊驼宝宝诞生记
据Karpathy分享,做这个项目的灵感正是来自llama.cpp。
训练代码来自之前他自己开发的nanoGPT,并修改成LLaMA 2架构。
推理代码直接开源在GitHub上了,不到24小时就狂揽1500+星。
训练数据集TinyStories则来自微软前一阵的研究。
2023新视野数学奖得主Ronen Eldan、2023斯隆研究奖得主李远志联手,验证了**1000万参数以下的小模型,在垂直数据上训练也可以学会正确的语法、生成流畅的故事、甚至获得推理能力。**

此外,开发过程中还有一个插曲。
Karpathy很久不写C语言已经生疏了,但是在GPT-4的帮助下,还是只用一个周末就完成了全部工作。
对此,英伟达科学家Jim Fan评价为:现象级。
最初,在CPU单线程运行、fp32推理精度下,Baby LLaMA 2每秒只能生成18个token。
在编译上使用一些优化技巧以后,直接提升到每秒98个token。
优化之路还未停止。
有人提出,可以通过GCC编译器的-funsafe-math-optimizations模式再次提速6倍。
除了编译方面外,也有人提议下一步增加LoRA、Flash Attention等模型层面流行的优化方法。
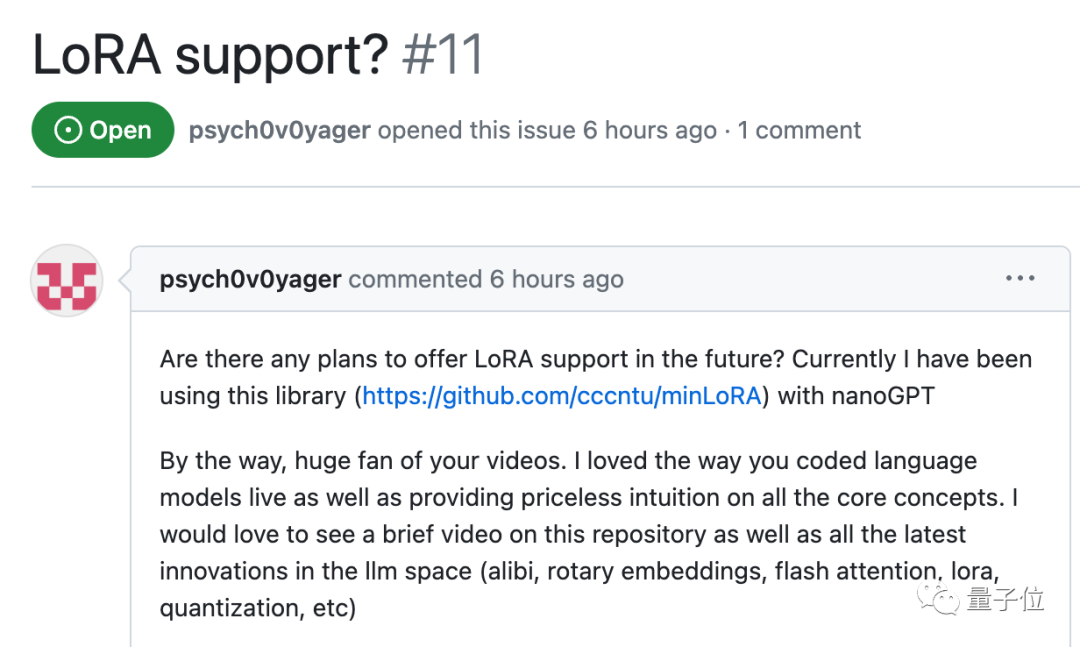
Baby LLaMA 2一路火到Hacker News社区,也引发了更多的讨论。
有人提出,现在虽然只是一个概念验证,但本地运行的语言模型真的很令人兴奋。
虽然无法达到在云端GPU集群上托管的大模型的相同功能,但可以实现的玩法太多了。
在各种优化方法加持下,karpathy也透露已经开始尝试训练更大的模型,并表示:
70亿参数也许触手可及。
GitHub:https://github.com/karpathy/llama2.c
在浏览器运行Baby LLaMA 2:https://ggerganov.com/llama2.c
参考链接:[1]https://twitter.com/karpathy/status/1683143097604243456[2]https://twitter.com/ggerganov/status/1683174252990660610[3]https://twitter.com/altryne/status/1683222517719384065[4]https://news.ycombinator.com/item?id=36838051
6. 对标Llama 2,OpenAI开源模型G3PO已在路上
原文:https://mp.weixin.qq.com/s/hXsKm1M_2utRmj_y9MOBzw
这一次,OpenAI 成了跟进者。
上个星期,Meta 在微软大会上发布的 Llama 2 被认为改变了大模型的格局,由于开源、免费且可商用,新版羊驼大模型立刻吸引了众多创业公司、研究机构和开发者的目光,Meta 开放合作的态度也获得了业内的一致好评,OpenAI 面临着回应 Meta 开源人工智能技术战略的压力。
GPT-4 虽然被一致认为能力领先,但 OpenAI 却并不是唯一一个引领方向的公司。在大模型领域,开源预训练模型一直被认为是重要的方向。
GPT-4 因为不提供开源版本而时常受到人们诟病,但 OpenAI 并不一定会坚持封闭的道路,其正在关注开源的影响。两个月前,有消息称该公司打算发布自己的开源模型以应对竞争。近日,据外媒 Information 报道,OpenAI 内部已有具体计划,未来即将开源的大模型代号为「G3PO」。
此前,Meta 的开源策略在机器学习的很多领域取得了成功。起源于 Meta 的开源软件项目包括 React、PyTorch、GraphQL 等。
在开源问题上,OpenAI 尚未准备好承诺发布自己的开源模型,并且内部尚未决定开源的时间表。
众所周知,大模型领域最近的发展速度极快。OpenAI 虽然已经转向,但并没有快速出手回应 Llama 系列,Information 在此引用了两个可能的驱动因素:
-
OpenAI 的团队规模较小,并不专注于推出为客户提供定制化大模型的商店。虽然这将是吸引开发者,并抵御 Meta 和 Google 的另一种途径。
-
OpenAI 还希望打造个性化的 ChatGPT Copilot 助手。据消息人士透露,推出真正的「Copilot」将使 OpenAI 与微软直接竞争,有一些左右互搏的意思,而且这一努力「可能需要数年时间」。
开源的 OpenAI 版大模型可能会在不久之后问世,但 OpenAI 仍然希望坚持「开发先进闭源模型和非先进开源模型」的思路,这将产生足够收入,形成技术开发的正循环,并且更容易让开发者倾向于为最先进模型付费。
不过正如 Llama 2 推出时人们所讨论的,大模型的发展并不一定会朝着科技巨头 + 高投入 + 闭源的方向一直前进下去,随着利用 Llama 2 的商业应用程序开始传播,大模型技术的世界可能会发生重组。
在 OpenAI 看来,开发人员快速采用开源模型已经被视为一种威胁,目前该公司也正在尝试一系列方向。
最近,OpenAI 成立了一个新的小组 Superalignment,希望在四年内实现 AGI(通用人工智能)。此外,有传言称 OpenAI 可能很快就会推出应用程序商店和个性化版本的 ChatGPT。所以目前来说,G3PO 只是他们众多未来项目之一。
谁将首先实现 AGI?看起来这个问题目前还没有明确的答案。
7. 两万字长文详解:如何用C++从零实现神经网络
原文:https://mp.weixin.qq.com/s/FgRuI9nnC-Zh30ghO6q22w一、Net类的设计与神经网络初始化既然是要用C++来实现,那么我们自然而然的想到设计一个神经网络类来表示神经网络,这里我称之为Net类。由于这个类名太过普遍,很有可能跟其他人写的程序冲突,所以我的所有程序都包含在namespace liu中,由此不难想到我姓刘。在之前的博客反向传播算法资源整理中,我列举了几个比较不错的资源。对于理论不熟悉而且学习精神的同学可以出门左转去看看这篇文章的资源。这里假设读者对于神经网络的基本理论有一定的了解。
 在真正开始coding之前还是有必要交代一下神经网络基础,其实也就是设计类和写程序的思路。简而言之,神经网络的包含几大要素:
在真正开始coding之前还是有必要交代一下神经网络基础,其实也就是设计类和写程序的思路。简而言之,神经网络的包含几大要素:- 神经元节点
- 层(layer)
- 权值(weights)
- 偏置项(bias)
#ifndef NET_H #define NET_H #endif // NET_H #pragma once #include #include #include //#include #include"Function.h" namespace liu { class Net { public: std::vector<int> layer_neuron_num; std::vector<cv::Mat> layer; std::vector<cv::Mat> weights; std::vector<cv::Mat> bias; public: Net() {}; ~Net() {}; //Initialize net:genetate weights matrices、layer matrices and bias matrices // bias default all zero void initNet(std::vector<int> layer_neuron_num_); //Initialise the weights matrices. void initWeights(int type = 0, double a = 0., double b = 0.1); //Initialise the bias matrices. void initBias(cv::Scalar& bias); //Forward void forward(); //Forward void backward(); protected: //initialise the weight matrix.if type =0,Gaussian.else uniform. void initWeight(cv::Mat &dst, int type, double a, double b); //Activation function cv::Mat activationFunction(cv::Mat &x, std::string func_type); //Compute delta error void deltaError(); //Update weights void updateWeights(); }; } 说明:以上不是Net类的完整形态,只是对应于本文内容的一个简化版,简化之后看起来会更加清晰明了。成员变量与成员函数现在Net类只有四个成员变量,分别是:
- 每一层神经元数目(layerneuronnum)
- 层(layer)
- 权值矩阵(weights)
- 偏置项(bias)
- initNet():用来初始化神经网络
- initWeights():初始化权值矩阵,调用initWeight()函数
- initBias():初始化偏置项
- forward():执行前向运算,包括线性运算和非线性激活,同时计算误差
- backward():执行反向传播,调用updateWeights()函数更新权值。
//Initialize net void Net::initNet(std::vector<int> layer_neuron_num_) { layer_neuron_num = layer_neuron_num_; //Generate every layer. layer.resize(layer_neuron_num.size()); for (int i = 0; i < layer.size(); i++) { layer[i].create(layer_neuron_num[i], 1, CV_32FC1); } std::cout << "Generate layers, successfully!" << std::endl; //Generate every weights matrix and bias weights.resize(layer.size() - 1); bias.resize(layer.size() - 1); for (int i = 0; i < (layer.size() - 1); ++i) { weights[i].create(layer[i + 1].rows, layer[i].rows, CV_32FC1); //bias[i].create(layer[i + 1].rows, 1, CV_32FC1); bias[i] = cv::zeros(layer[i + 1].rows, 1, CV_32FC1); } std::cout << "Generate weights matrices and bias, successfully!" << std::endl; std::cout << "Initialise Net, done!" << std::endl; }权值初始化initWeight()函数权值初始化函数initWeights()调用initWeight()函数,其实就是初始化一个和多个的区别。偏置初始化是给所有的偏置赋相同的值。这里用Scalar对象来给矩阵赋值。
//initialise the weights matrix.if type =0,Gaussian.else uniform. void Net::initWeight(cv::Mat &dst, int type, double a, double b) { if (type == 0) { randn(dst, a, b); } else { randu(dst, a, b); } } //initialise the weights matrix. void Net::initWeights(int type, double a, double b) { //Initialise weights cv::Matrices and bias for (int i = 0; i < weights.size(); ++i) { initWeight(weights[i], 0, 0., 0.1); } }偏置初始化是给所有的偏置赋相同的值。这里用Scalar对象来给矩阵赋值。
//Initialise the bias matrices. void Net::initBias(cv::Scalar& bias_) { for (int i = 0; i < bias.size(); i++) { bias[i] = bias_; } }至此,神经网络需要初始化的部分已经全部初始化完成了。初始化测试我们可以用下面的代码来初始化一个神经网络,虽然没有什么功能,但是至少可以测试下现在的代码是否有BUG:
#include"../include/Net.h" // using namespace std; using namespace cv; using namespace liu; int main(int argc, char *argv[]) { //Set neuron number of every layer vector<int> layer_neuron_num = { 784,100,10 }; // Initialise Net and weights Net net; net.initNet(layer_neuron_num); net.initWeights(0, 0., 0.01); net.initBias(Scalar(0.05)); getchar(); return 0; }二、前向传播与反向传播前言前一章节中,大部分还是比较简单的。因为最重要事情就是生成各种矩阵并初始化。神经网络中的重点和核心就是本文的内容——前向和反向传播两大计算过程。每层的前向传播分别包含加权求和(卷积?)的线性运算和激活函数的非线性运算。反向传播主要是用BP算法更新权值。本文也分为两部分介绍。前向过程如前所述,前向过程分为线性运算和非线性运算两部分。相对来说比较简单。线型运算可以用
Y = WX+b来表示,其中X是输入样本,这里即是第N层的单列矩阵,W是权值矩阵,Y是加权求和之后的结果矩阵,大小与N+1层的单列矩阵相同。b是偏置,默认初始化全部为0。不难推知,W的大小是(N+1).rows * N.rows。正如上一篇中生成weights矩阵的代码实现一样:weights[i].create(layer[i + 1].rows, layer[i].rows, CV_32FC1);非线性运算可以用
O=f(Y)来表示。Y就是上面得到的Y。O就是第N+1层的输出。f就是我们一直说的激活函数。激活函数一般都是非线性函数。它存在的价值就是给神经网络提供非线性建模能力。激活函数的种类有很多,比如sigmoid函数,tanh函数,ReLU函数等。各种函数的优缺点可以参考更为专业的论文和其他更为专业的资料。我们可以先来看一下前向函数forward()的代码://Forward void Net::forward() { for (int i = 0; i < layer_neuron_num.size() - 1; ++i) { cv::Mat product = weights[i] * layer[i] + bias[i]; layer[i + 1] = activationFunction(product, activation_function); } }for循环里面的两句就分别是上面说的线型运算和激活函数的非线性运算。激活函数
activationFunction()里面实现了不同种类的激活函数,可以通过第二个参数来选取用哪一种。代码如下://Activation function cv::Mat Net::activationFunction(cv::Mat &x, std::string func_type) { activation_function = func_type; cv::Mat fx; if (func_type == "sigmoid") { fx = sigmoid(x); } if (func_type == "tanh") { fx = tanh(x); } if (func_type == "ReLU") { fx = ReLU(x); } return fx; }各个函数更为细节的部分在
Function.h和Function.cpp文件中。在此略去不表,感兴趣的请君移步Github。需要再次提醒的是,上一篇博客中给出的Net类是精简过的,下面可能会出现一些上一篇Net类里没有出现过的成员变量。完整的Net类的定义还是在Github里。反向传播过程反向传播原理是链式求导法则,其实就是我们高数中学的复合函数求导法则。这只是在推导公式的时候用的到。具体的推导过程我推荐看看下面这一篇教程,用图示的方法,把前向传播和反向传播表现的清晰明了,强烈推荐!Principles of training multi-layer neural network using backpropagation。一会将从这一篇文章中截取一张图来说明权值更新的代码。在此之前,还是先看一下反向传播函数backward()的代码是什么样的://Backward void Net::backward() { calcLoss(layer[layer.size() - 1], target, output_error, loss); deltaError(); updateWeights(); }可以看到主要是是三行代码,也就是调用了三个函数:
-
第一个函数
calcLoss()计算输出误差和目标函数,所有输出误差平方和的均值作为需要最小化的目标函数。 -
第二个函数
deltaError()计算delta误差,也就是下图中delta1*df()那部分。 -
第三个函数
updateWeights()更新权值,也就是用下图中的公式更新权值。
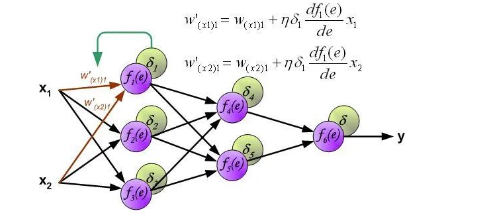 再看下updateWeights()函数的代码:
再看下updateWeights()函数的代码://Update weights void Net::updateWeights() { for (int i = 0; i < weights.size(); ++i) { cv::Mat delta_weights = learning_rate * (delta_err[i] * layer[i].t()); weights[i] = weights[i] + delta_weights; } }注意需要注意的就是计算的时候输出层和隐藏层的计算公式是不一样的。另一个需要注意的就是......难道大家没觉得本系列文章的代码看起来非常友好吗至此,神经网络最核心的部分已经实现完毕。剩下的就是想想该如何训练了。这个时候你如果愿意的话仍然可以写一个小程序进行几次前向传播和反向传播。还是那句话,鬼知道我在能进行传播之前到底花了多长时间调试!更加详细的内容,请查看原文。 点击阅读原文进入官网
原文标题:【AI简报20230728期】医疗领域中的AI大模型,详解C++从零实现神经网络
文章出处:【微信公众号:RTThread物联网操作系统】欢迎添加关注!文章转载请注明出处。
-
神经网络模型的原理、类型及应用领域2024-07-02 3290
-
NanoEdge AI的技术原理、应用场景及优势2024-03-12 1733
-
卷积神经网络模型的优缺点2023-08-21 6819
-
卷积神经网络模型发展及应用2022-08-02 13420
-
STM32Cube.AI工具包使用初探2022-02-22 1227
-
嵌入式AI在linux芯片平台上的部署方案分享2021-12-14 917
-
嵌入式Linux平台部署AI神经网络模型Inference的方案2021-11-02 891
-
如何使用stm32cube.ai部署神经网络?2021-10-11 4863
-
在STM32上验证神经网络模型2021-08-03 1932
-
《来来来,成为AI的良师益友》高焕堂老师AI学习资料大集合2020-11-26 2079
-
【AI学习】第3篇--人工神经网络2020-11-05 4336
全部0条评论

快来发表一下你的评论吧 !
