

华南理工贾奎团队ICCV'23新作:支持重新照明、编辑和物理仿真
描述
【导读】来自华南理工大学的研究团队提出了一种基于文本驱动的三维模型及材质生成方法Fantasia3D,是第一个被接收的能够产生逼真效果的AIGC3D工作。
受益于预训练的大型语言模型和图像扩散模型(Satble Diffusion等)的可用性,自动化三维内容生成近期取得了快速进展。
现有的文本到三维模型的生成方法通常使用NeRF等隐式表达,通过体积渲染将几何和外观耦合在一起,但在恢复更精细的几何结构和实现逼真渲染方面存在不足,所以在生成高质量三维资产方面效果较差。
在这项研究中,华南理工大学提出了一种用于高质量文本到三维内容创建的新方法Fantasia3D,关键之处在于对几何和外观进行解耦的建模和学习。

项目地址:https://fantasia3d.github.io/
对于几何学习,Fantasia3D依赖于显隐式结合的表达,并提出将渲染的表面法线图编码为Satble Diffusion的输入;对于外观建模,Fantasia3D引入了空间变化的双向反射率分布函数(BRDF)到文本生成三维模型的任务中,并学习生成表面的逼真渲染所需的表面材质。
解耦框架兼容目前的图形引擎,支持生成的三维资源的重新照明、编辑和物理仿真。
研究人员也进行了全面的实验,展示了该方法在不同的文本到三维生成任务设置下相对于现有方法的优势。
模型效果
对于给定的文本,Fantasia3D能够生成具有不同拓扑形状的三维模型以及具有照片级真实感的渲染表面。
同时,如下图1中右上角的狮子所示,由于使用了BRDF建模表面,Fantasia3D能产生较强的金属反射效果。

图1:三维模型生成效果
同时,Fantasia3D支持根据用户给定的粗糙三维物体和文本进行生成。
如下图2所示,给定一个粗糙的三维模型,Fantasia3D可将输入的粗糙模型作为初始化生成三维模型,这种优化方式可让生成过程更加快速和稳定,缓解文本到三维模型生成中的多面问题(Janus Problem)。

图2:根据用户给定的粗糙三维模型和文本进行生成。
另外,不同于现有的基于隐式表达(NeRF等)的方法,Fantasia3D采用了显隐式相结合的表达,生成的3D资产可以很好地与现有的图形渲染和仿真引擎相结合。
如下图3 (a) (b) 所示,生成的三维模型可以导入Blender中进行布料和软体的物理仿真,图3 (c) 则展示了用Blender替换生成材质的实验结果。

图3: 在Blender中进行编辑。
如下图4 (a) 所示,Fantasia3D生成的模型还可在Blender中替换不同的光照,从而产生不同的渲染效果。
(b) 中展示了将Fantasia3D生成的物体插入其他场景中的能力,插入的物体能与原环境中的光照环境进行交互,从而产生自然的反射效果。
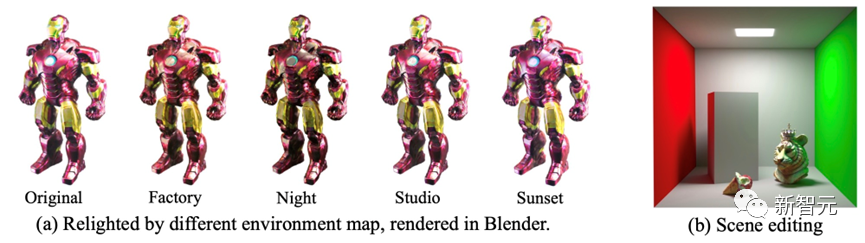
图4: 给生成物体进行重新打光。
原理方法
Fantasia3D的方法概览如下图5所示。我们的方法可以根据文本提示生成解耦的几何和外观(见图 (a) ),二者分别通过 (b) 几何建模和 (c) 外观建模生成。
在 (b) 中,我们采用DMTet作为我们的三维几何表示,这里初始化为一个三维椭球体。
为了优化DMTet的参数,我们将从DMTet提取的网格的法线贴图(在早期训练阶段还会同时使用物体掩码)渲染为Stable Diffusion的形状编码。
在 (c) 中,对于外观建模,我们引入了空间变化的双向反射率分布函数(BRDF)建模,并学习预测外观的三个分量(即kd、krm和kn)。几何和外观建模都由分数蒸馏采样损失函数(SDS loss)进行监督。
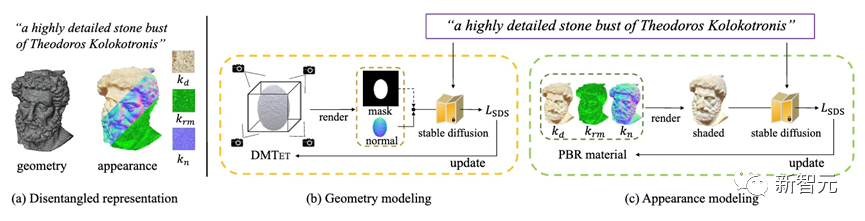
图5: Fantasia3D流程图。
总结
本文介绍了一种名为Fantasia3D的自动化文本到三维生成的新方法,基于DMTet的混合表达,采用几何和外观的解耦建模和学习,能够生成精细的表面和丰富的材质/纹理。
对于几何学习,研究人员提出将渲染的法线贴图编码,并将法线的形状编码作为预训练的Stable Diffusion的输入。
对于外观建模,引入了空间变化的BRDF到文本生成三维对任务中,从而实现对学习表面的逼真渲染所需的材质的学习。
除了文本提示外,该方法还可以根据自定义的三维形状来生成,这对用户来说更加灵活,可以更好地控制生成的内容。
另外,该方法还方便支持生成的三维资产的重新照明、编辑和物理仿真。
-
第三届华南理工大学“紫光同创杯”FPGA大赛成功举办2026-02-02 1187
-
【AI大讲堂】中星联华走进高校系列-华南理工大学2025-12-24 781
-
国际权威学术刊物刊发稳石氢能与华南理工研究成果,创新螺旋流道设计提升AEM电解槽性能。2025-09-26 864
-
华南理工大学EDP同学会理事会走进虹科电子2025-06-24 1358
-
奥迪威携手华南理工大学共建联合创新实验室,校企深度合作助力产业升级2025-05-23 2250
-
曙光液冷ParaStor存储系统为华南理工大学实现全栈式液冷数据中心建设2023-11-26 2057
-
雷曼与华南理工大学联动打造LED全系列产品和解决方案生态2023-07-04 1558
-
【节能学院】安科瑞远程预付费系统在华南理工国际校区的设计与应用2023-01-30 1618
-
普渡科技和华南理工大学再次达成友好合作2022-04-27 3203
-
华南理工大学硕士学位论文基于ARM和DSP的嵌入式DVR硬件设...2012-08-17 4249
-
华南理工大学叶建山教授:电化学传感器发展步入“春天”2012-04-27 7007
-
C++(华南理工课件)2009-04-09 858
-
制冷技术试卷试题-(含工程热力学)华南理工大学2004年研究2009-01-08 1578
全部0条评论

快来发表一下你的评论吧 !
