

什么情况下对极几何约束会不成立?
描述
问题一:什么情况下对极几何约束会不成立?
答案摘要:对极几何约束在以下情况下不成立:纯旋转运动时,当相机基线长度为0时,或者当两个相机的成像平面平行时。在这些情况下,对极几何约束无法提供准确的几何关系。
问题二:为什么使用5张相移和7张互补格雷码的图像标定DLP结果错误?
答案摘要:使用5张相移和7张互补格雷码的图像标定DLP,结果错误。可能的原因有两个。首先,相移周期和互补格雷码的偏移量可能没有正确对应,导致像平面坐标计算错误。其次,互补格雷码可能错位,需要确保投影仪的分辨率是格雷码数量的倍数。如果投影仪分辨率不满足条件,可以生成更高分辨率的格雷码并进行裁切。

问题三:如何将目标检测的结果和场景流估计结合?
答案摘要:目标检测的结果可以和场景流估计结合,可以通过多任务框架将两个任务统一到一个网络框架中。例如,一种方法是使用"PillarFlowNet",它同时进行LiDAR场景流估计和目标检测,并实现了实时性和精度的提升。另外,还可以先进行目标检测,然后将检测结果输入到场景流估计中进行进一步处理。这种方法的时间复杂度可能较高,但可以实现物体状态检测。还可以在两帧点云数据上标注出目标框的位置信息,然后在输出中可视化标记的场景流,以实现物体运动状态检测。
问题四:在垃圾分拣分类抓取中,使用目标检测算法和6D位姿估计算法能结合吗?是否有一种能直接同时完成目标检测和6D位姿估计的网络?哪种技术路线比较可行?
答案摘要:两种技术路线都是可行的。一种是将目标检测算法和6D位姿估计算法分开处理,并在后处理中进行结合。另一种是使用一些能同时完成目标检测和6D位姿估计的网络,如YOLO+anygrasp,或结合常见的目标检测算法(如YOLO、Faster R-CNN、SSD)和6D位姿估计算法(如DeepIM、PoseCNN)。具体哪种路线更可行,可以根据实际情况和实验结果来选择。
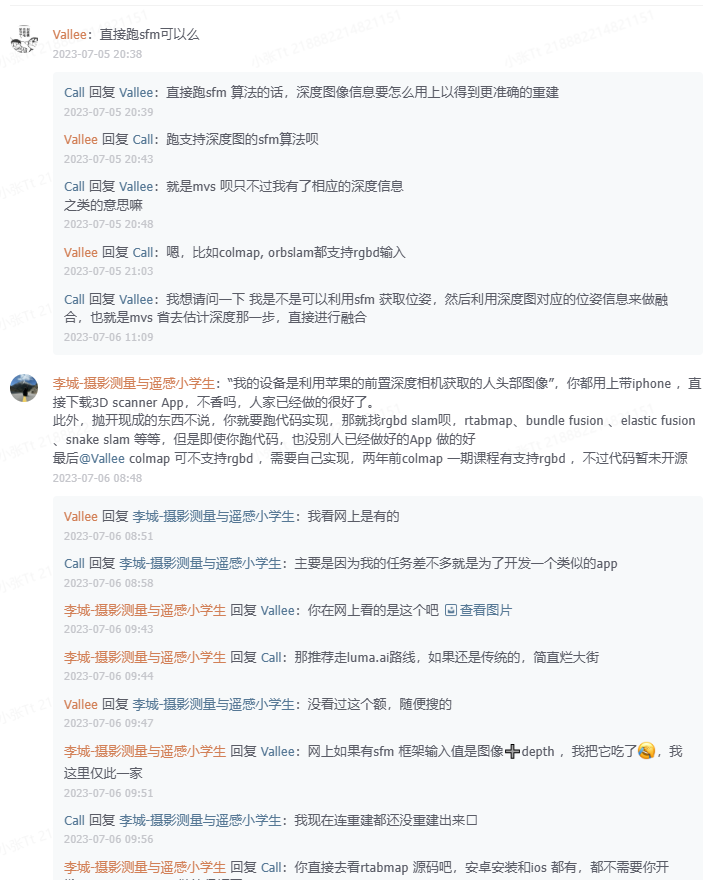
问题五:现在有批量的深度图和与之对应的彩色图,如何去做位姿估计和重建?所用的设备是利用苹果的前置深度相机获取的人头部图像。
答案摘要:关于使用深度图和彩色图进行位姿估计和重建的问题中,一种方法是建议直接跑基于深度图的Structure from Motion (SFM) 算法,而一种方法是可以使用支持深度图的SFM算法,如colmap和orbslam。还提到了一些RGBD SLAM算法,例如rtabmap、bundle fusion、elastic fusion和snake slam等。对于开发类似App的任务,有人推荐利用luma.ai路线,或者尝试使用现成的3D scanner App。对于重建结果,建议可以尝试photogrammetry路线,或者直接利用rtabmap进行RGBD SLAM。同时,也提到了使用基于深度图的位姿估计算法,例如基于PointNet改进的算法,以及其他一些深度学习方法,如DeepIM和PVNet。有关基于深度图的位姿估计的文章也得到了推荐。总体而言,可以根据具体需求和实验结果选择适合的方法。

-
运放虚短 不成立2014-09-07 4436
-
请问什么情况下AD549会输出饱和?2018-09-10 2511
-
C语言调试时遇到的if语句不成立,但是可以执行2018-12-18 8887
-
电源电路为什么不成立2019-04-19 1388
-
什么情况下选用PCI板卡?什么情况下选用PXI板卡?2020-03-31 2757
-
什么情况下数据能恢复和不能恢复2010-03-29 3144
-
volte语音通话有什么用,什么情况下可以开/关volte2019-10-21 18836
-
什么情况下使用示波器2022-02-01 6926
-
什么情况下要进行电能质量检测?2022-09-08 1186
-
什么情况下选用工业主板2023-02-14 1713
-
什么情况下需要使用微机消谐装置2023-03-06 1505
-
电机什么情况下需要配减速机?2023-05-26 3427
-
应急灯什么情况下才会亮?2023-07-25 23302
-
什么情况下选择热电偶?什么情况下选择热电阻?哪个更合适?2023-10-26 3252
-
什么情况下电容器会被击穿2024-02-19 5481
全部0条评论

快来发表一下你的评论吧 !
