

谷歌DeepMind发布机器人大模型RT-2,提高泛化与涌现能力
机器人
描述
AI模型将视觉和语言转化为机器人动作。
7月28日,谷歌DeepMind推出了一款新的机器人模型Robotics Transformer 2(RT-2)。
这是一个全新的视觉-语言-动作(VLA)模型,从网络和机器人数据中学习,并将这些知识转化为机器人控制的通用指令。
高容量视觉-语言模型(VLMs)在web-scale数据集上训练,使得这些系统非常擅长识别视觉或语言模式并跨不同语言进行操作。但是,要使机器人达到类似的能力水平,需要收集每个物体、环境、任务和情况的第一手机器人数据。
在Google DeepMind的论文中介绍了Robotics Transformer 2(RT-2),一个全新的视觉-语言-动作(VLA)模型,它从网络和机器人数据中学习,并将这些知识转化为机器人控制的通用指令,同时保留了web-scale能力。
一个在web-scale数据上进行预训练的视觉-语言模型(VLM)正在从RT-1的机器人数据中学习,以成为可以控制机器人的视觉-语言-动作(VLA)模型,RT-2。
这项工作建立在Robotic Transformer 1(RT-1)的基础上。RT-1是一个经过多任务演示训练的模型,可以学习机器人数据中看到的任务和对象的组合。更具体地说,Google DeepMind的工作使用了在办公室厨房环境中用13台机器人在17个月的时间内收集的RT-1机器人演示数据。
RT-2表现出了更好的泛化能力,超越了它所接触到的机器人数据的语义和视觉理解,包括解释新命令并通过执行基本推理(例如关于对象类别或高级描述的推理)来响应用户命令。
Google DeepMind研究团队还展示了将思维链推理纳入RT-2中使其能够进行多阶段语义推理,例如决定哪种物体可以用作一把临时锤子(石头),或者哪种饮料最适合疲倦的人(能量饮料)。
1.采用视觉语言模型进行机器人控制
RT-2以视觉-语言模型(VLMs)为基础,将一个或多个图像作为输入,并生成一系列通常表示自然语言文本的标记。此类VLMs已经在大规模网络的数据上成功训练,用于执行视觉问答、图像字幕或对象识别等任务。在Google DeepMind的工作中,将Pathways Language and Image model(PaLI-X)和 Pathways Language model Embodied(PaLM-E)作为RT-2的支柱。
要控制一个机器人,必须对其进行训练以输出动作。Google DeepMind研究团队通过将动作表示为模型输出中的标注(类似于语言标记)来解决这一挑战,并将动作描述为可以由标准自然语言标记化处理的字符串,如下所示:
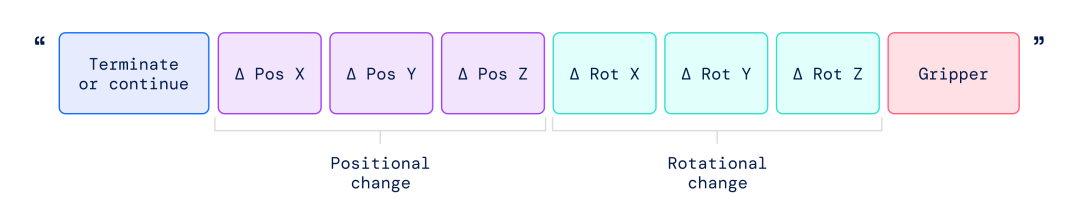
在RT-2的训练中,动作字符串的表示方式。这种字符串的示例可以是机器人动作标记编号的序列,例如:“1 128 91 241 5 101 127 217”。
该字符串以一个标志开始,指示是继续,还是终止当前情节不执行后续命令,然后机器人根据指示更改末端执行器的位置和旋转以及机器人抓手所需伸展的命令。
Google DeepMind研究团队使用与RT-1中相同的机器人动作离散版本,并表明将其转换为字符串表示使得可以在机器人数据上训练VLM模型,因为此类模型的输入和输出空间无需改变。
RT-2的架构和训练:对一个预训练的VLM模型在机器人和网络数据上进行共同微调。生成的模型接收机器人摄像头图像并直接预测机器人要执行的动作。
2.泛化和涌现能力
Google DeepMind研究团队对RT-2模型进行了一系列定性和定量实验,涵盖了超过6000次机器人试验。在探索RT-2的涌现能力时,首先寻找了需要将web-scale数据和机器人的经验相结合的任务,然后定义了三类技能:符号理解、推理和人类识别。
每个任务都需要理解视觉-语义概念,并具备执行机器人控制以对这些概念进行操作的能力。例如,“拿起即将从桌子上掉下来的袋子”或“将香蕉移动到2加1的和”,要求机器人对机器人数据中从未见过的对象或场景上执行操作任务,这需要从网络数据转化而来的知识进行操作。
机器人数据中不存在的涌现能力示例,需要从网络预训练中进行知识转移。
在所有类别中,与之前的基线相比(例如之前在大规模视觉数据集上预训练的RT-1模型和Visual Cortex(VC-1)等模型),RT-2的泛化性能提高到了3倍以上。
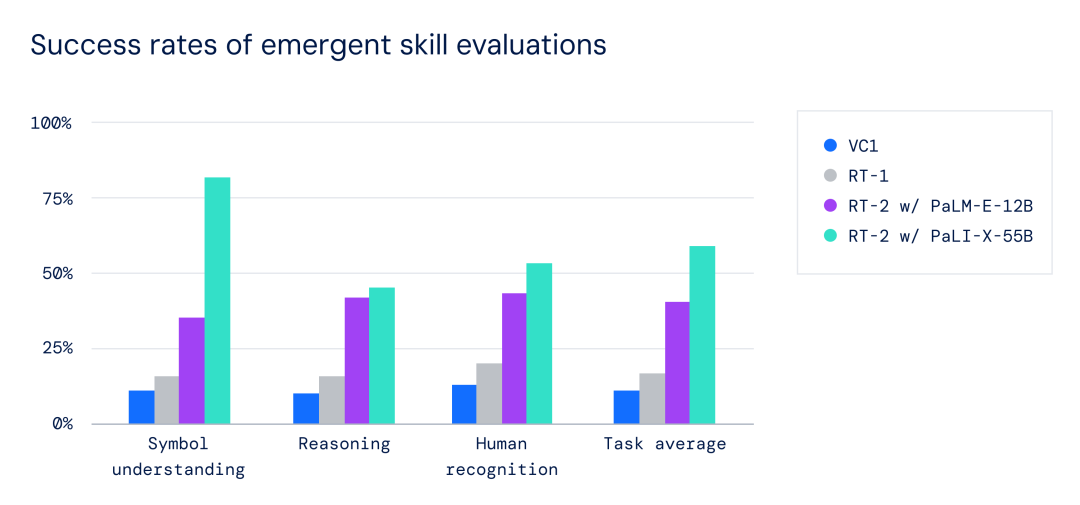
涌现能力评估的成功率:RT-2模型优于之前的RT-1和VC-1基线。
Google DeepMind研究团队还进行了一系列的定量评估,首先从最初的RT-1任务开始,这些任务在机器人数据中有示例,然后继续进行对机器人来说之前从未见过的不同程度的对象、背景和环境的评估,要求机器人从VLM预训练中学习泛化能力。
机器人以前未见过的环境示例,RT-2可以推广到新的情况。
RT-2在机器人数据中保持了对原始任务的性能,并提高了机器人在之前未曾见过的情景上的性能,从RT-1的32%提高到62%,显示了大规模预训练的显著好处。
此外,Google DeepMind研究团队还观察到与仅在视觉任务上预训练的基准模型相比有显著改进,例如VC-1和机器人操作的Reusable Representations for Robotic Manipulation(R3M),以及用VLM进行对象识别的算法,例如Manipulation of Open-World Objects(MOO)。 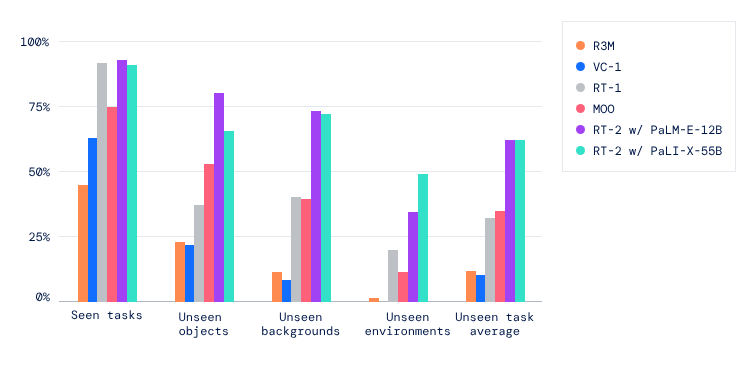
RT-2在分布内可见的任务上实现了高性能,在分布外不可见的任务上优于多个基线。
在开源的“Language Table”机器人任务套件上评估模型,Google DeepMind研究团队在模拟环境中取得了90%的成功率,明显优于以前的基线,包括BC-Z(72%)、RT-1(74%)和LAVA(77%)。
然后研究团队在真实世界中评估了相同的模型(因为它是在模拟和真实数据上进行训练的),并展示了它泛化到新物体的能力,如下所示,训练数据集中除蓝色立方体外,没有其他对象存在。
RT-2在真实机器人Language Table任务中表现良好。在训练数据中,除了蓝色立方体之外,没有其他对象存在。
受到LLM中使用的思维链提示方法的启发,研究团队对模型进行了探测,将机器人控制与思维链推理相结合,使得学习长期规划和简易技能可以在单个模型中实现。
具体而言,研究团队对RT-2的一个变体进行了几百个梯度步骤的微调,以增强其联合使用语言和动作的能力。然后对数据进行扩充,加入一个额外的“计划”步骤,首先用自然语言描述机器人即将采取的动作的目的,然后是“动作”和动作标注。下面是一个这样的推理示例和机器人的行为结果:
思维链推理可以学习一个独立的模型,既可以规划长期技能序列,又可以预测机器人的动作。
通过这个过程,RT-2可以执行更复杂的命令,需要推理完成用户指令所需的中间步骤。得益于其VLM主干,RT-2可以从图像和文本命令进行规划,从而实现视觉基础规划,而当前的计划和执行方法(如SayCan)无法看到真实世界,完全依赖于语言。
3.推进机器人控制
RT-2表明,视觉-语言模型(VLMs)可以转变为强大的视觉-语言-动作(VLA)模型,通过将VLM预训练与机器人数据相结合,直接控制机器人。
通过基于PaLM-E和PaLI-X的两个VLA实例,RT-2导致了高度改进的机器人策略,并且更重要的是,它具有显着更好的泛化性和涌现能力,这些能力继承自web-scale的视觉-语言预训练。
RT-2不仅是现有VLM模型简单而有效的修改,而且显示了构建通用型物理机器人的前景,这种机器人可以进行推理、问题解决并解释信息,以在真实世界中执行各种任务。
审核编辑:刘清
-
《具身智能机器人系统》第7-9章阅读心得之具身智能机器人与大模型2024-12-24 2465
-
【「具身智能机器人系统」阅读体验】2.具身智能机器人大模型2024-12-29 1968
-
机器人大赛展架2014-05-17 5375
-
中国教育机器人大赛介绍2016-03-24 4848
-
机器人大赛2017-06-09 4550
-
未来的AI 深挖谷歌 DeepMind 和它背后的技术2020-08-26 2739
-
谷歌人工智能又出新花样 DeepMind为机器人“造梦”2016-11-30 1494
-
如何提高事件检测(ED)模型的鲁棒性和泛化能力?2020-12-31 4247
-
2022 年及以后的趋势,机器人和协作机器人大量涌现2022-12-28 1409
-
谷歌发布人工智能学习模型机器人转换器使其机器人更智能2023-08-01 1758
-
阿里云开源AI大模型,挑战Meta、OpenAI2023-08-04 1679
-
谷歌发布又一AI大模型黑科技丨小美AI城APP带你开启AI新时代2023-09-13 1587
-
AI人形机器人研究:与汽车行业联动,主机厂押注人形机器人赛道2023-11-20 2555
-
谷歌DeepMind推新AI模型Genie,能生成2D游戏平台2024-02-27 1747
-
谷歌借助Gemini AI系统深化对机器人的训练2024-07-12 1793
全部0条评论

快来发表一下你的评论吧 !
