

Focus-DETR:30%Token就能实现SOTA性能,效率倍增
描述
目前 DETR 类模型已经成为了目标检测的一个主流范式。但 DETR 算法模型复杂度高,推理速度低,严重影响了高准确度目标检测模型在端侧设备的部署,加大了学术研究和产业应用之间的鸿沟。
来自华为诺亚、华中科技大学的研究者们设计了一种新型的 DETR 轻量化模型 Focus-DETR 来解决这个难题。
为实现模型性能和计算资源消耗、显存消耗、推理时延之间的平衡,Focus-DETR 利用精细设计的前景特征选择策略,实现了目标检测高相关特征的精确筛选;继而,Focus-DETR 进一步提出了针对筛选后特征的注意力增强机制,来弥补 Deformable attention 远距离信息交互的缺失。相比业界全输入 SOTA 模型, AP 降低 0.5 以内,计算量降低 45%,FPS 提高 41%,并在多个 DETR-like 模型中进行了适配。
作者对多个 DETR 类检测器的 GFLOPs 和时延进行了对比分析,如图 1 所示。从图中发现,在 Deformable-DETR 和 DINO 中,encoder 的计算量分别是 decoder 计算量的 8.8 倍和 7 倍。同时,encoder 的时延大概是 decoder 时延的 4~8 倍。这表明,提升 encoder 的效率至关重要。 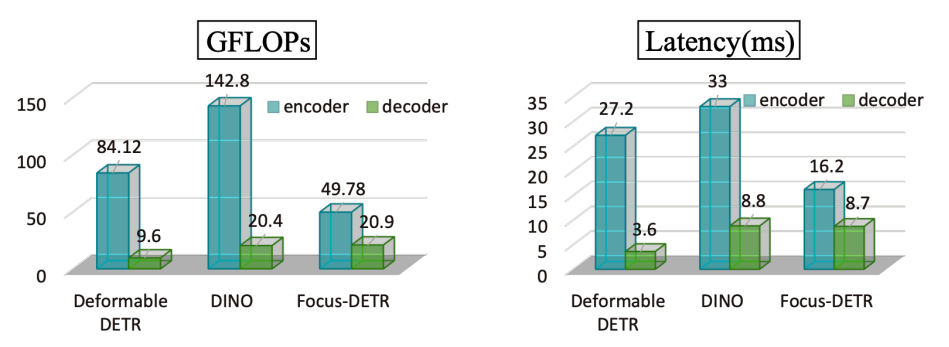
图 1:多个 DETR 类检测器的计算量和时延对比分析
网络结构
Focus-DETR 包括一个 backbone,一个由 dual-attention 组成的 encoder 和一个 decoder。前景选择器(Foreground Token Selector)在 backbone 和 encoder 之间,是一个基于跨多尺度特征的自顶向下评分调制,用来确定一个 token 是否属于前景。Dual attention 模块通过多类别评分机制,选择更细粒度的目标 token,然后将其输入到一个自注意模块来弥补 token 交互信息的缺失。 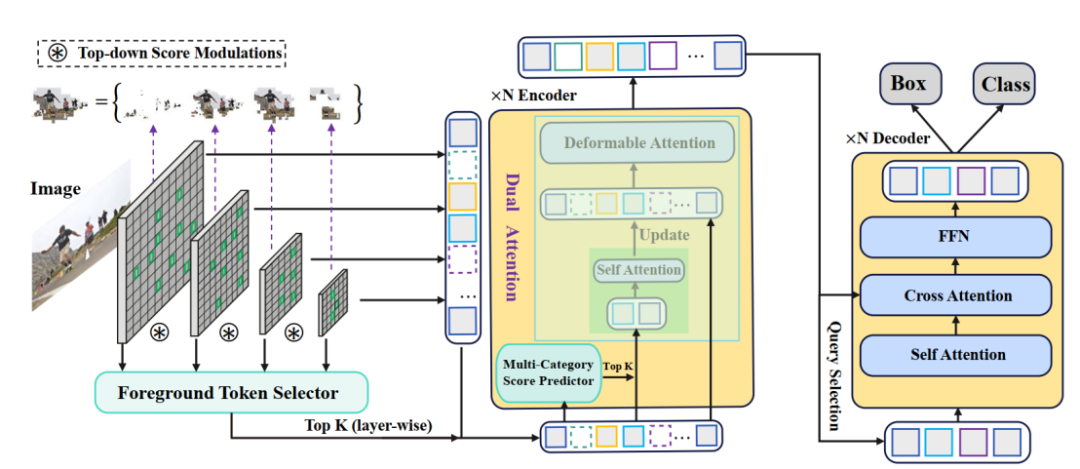
图 2 :Focus-DETR 整体网络结构
计算量降低:前景筛选策略
目前已经有一些对于前景 token 进行剪枝提升性能的方法。例如,Sparse DETR(ICLR2022)提出采用 decoder 的 DAM(decoder attention map)作为监督信息。然而作者发现,如图 3 所示,Sparse DETR 筛选的 token 并不都是前景区域。作者认为,这是由于 Sparse DETR 使用 DAM 来监督前景 token 导致的,DAM 会在训练的时候引入误差。而 Focus-DETR 使用 ground truth(boxes 和 label)来监督前景的 token 的筛选。 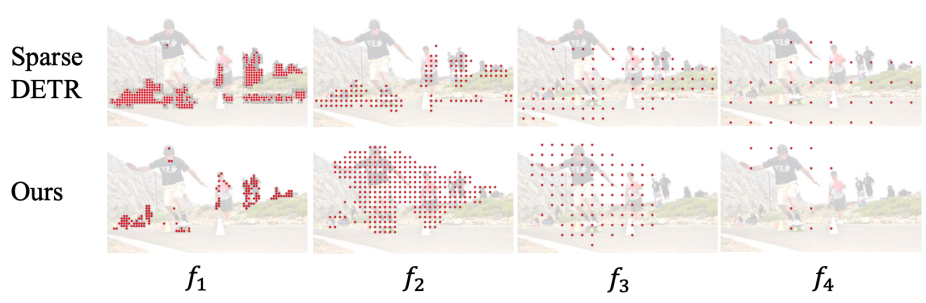
图 3:Focus-DETR 和 Sparse DETR 在不同 feature map 上保留的 token 对比
为了更好地训练前景筛选器,作者优化了 FCOS 的前背景标签分配策略,如图 4 所示。作者首先为不同特征映射的包围框设置了一个大小范围。与传统的多尺度特征标签分配方法不同,它允许相邻两个特征尺度之间的范围重叠,以增强边界附近的预测能力。
对每个拥有步长 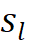 的特征
的特征 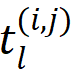 ,其中
,其中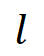 代表多尺度特征的层级序号,
代表多尺度特征的层级序号,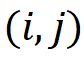 代表在二维特征图上的位置坐标,作者定义该特征在原图上的映射位置为
代表在二维特征图上的位置坐标,作者定义该特征在原图上的映射位置为 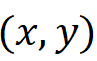 ,那么
,那么 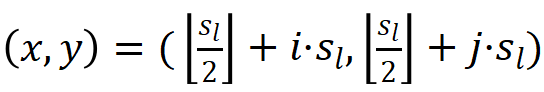 ,因此 特征所对应的标签应该为:
,因此 特征所对应的标签应该为:
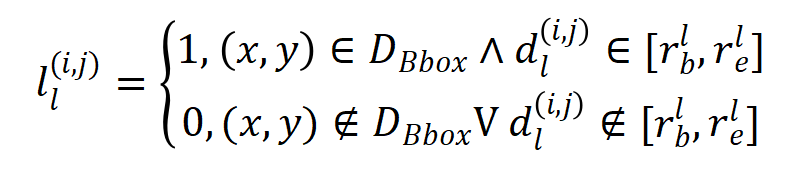
其中 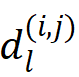 代表坐标和真值框中心之间的最大棋盘距离,
代表坐标和真值框中心之间的最大棋盘距离,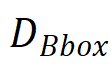 代表真值目标框,
代表真值目标框,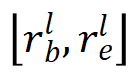 分别代表被第层特征图预测的目标的尺度的最大值和最小值,由于尺度重叠设置,
分别代表被第层特征图预测的目标的尺度的最大值和最小值,由于尺度重叠设置,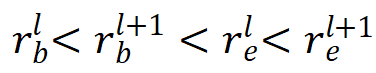 。
。 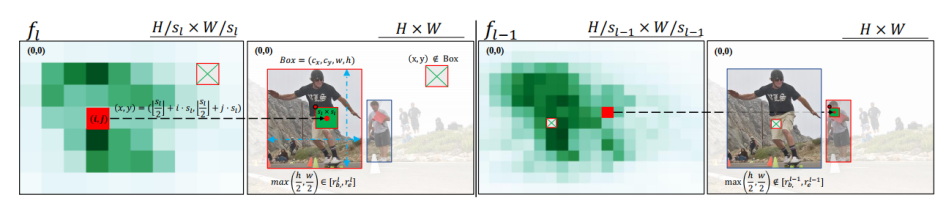
图 4. 前背景标签分配可视化
此外,来自不同特征映射的特征选择的差异也被忽略,这限制了从最合适的分辨率选择特征的潜力。
为弥补这一差距,Focus-DETR 构造了基于多尺度 feature map 的自顶向下的评分调制模块,如图 5 所示。
为了充分利用多尺度特征图之间的语义关联,作者首先使用多层感知器 (MLP) 模块来预测每个特征图中的多类别语义得分。
考虑到高层语义特征,低层语义特征包含更丰富的语义信息,作者利用高层 feature map 的 token 重要性得分,作为补充信息来调制低层 feature map 的预测结果。
图 5:top-down 前景筛选评分调制策略
细粒度特征增强策略
在依靠前期设计的前景筛选器得到较为准确的前景特征后,Focus-DETR 使用一种有效的操作来获得更为细粒度的特征,利用这些细粒度特征以获得更好的检测性能。直观地说,作者假设在这个场景中引入更细粒度的类别信息将是有益的。基于这一动机,作者提出了一种新的注意力机制,并结合前景特征选择,以更好地结合利用细粒度特征和前景特征。
如图 2 所示,为了避免对背景 token 进行冗余的计算,作者采用了一种同时考虑位置信息和类别语义信息的堆叠策略。具体来说,预测器 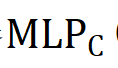 (・) 计算出的前景评分
(・) 计算出的前景评分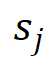 和类别评分
和类别评分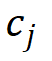 的乘积将作为作者最终的标准
的乘积将作为作者最终的标准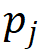 来确定注意力计算中涉及的细粒度特征,即:
来确定注意力计算中涉及的细粒度特征,即:
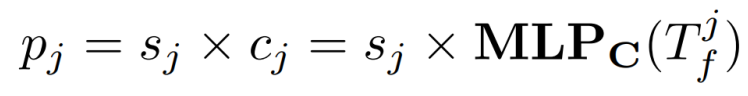
其中和分别代表前景得分和类别概率。
与两阶段 Deformable DETR 的 query 选择策略不同,Focus-DETR 的多类别概率不包括背景类别 (∅)。该模块可以被视为一个 self-attention ,对细粒度特征进行增强计算。然后,已增强的特征将被 scatter 回原始的前景特征并对其进行更新。
实验结果
主要结果
如表一所示,作者将 Focus-DETR 在 COCO 验证集上和其他模型的性能进行比较。可以发现同样基于 DINO,Focus-DETR 仅使用 30% token 的情况下,超过 Sparse DETR 2.2 个 AP。相比原始 DINO,仅损失 0.5 个 AP,但是计算量降低 45%,推理速度提升 40.8%。 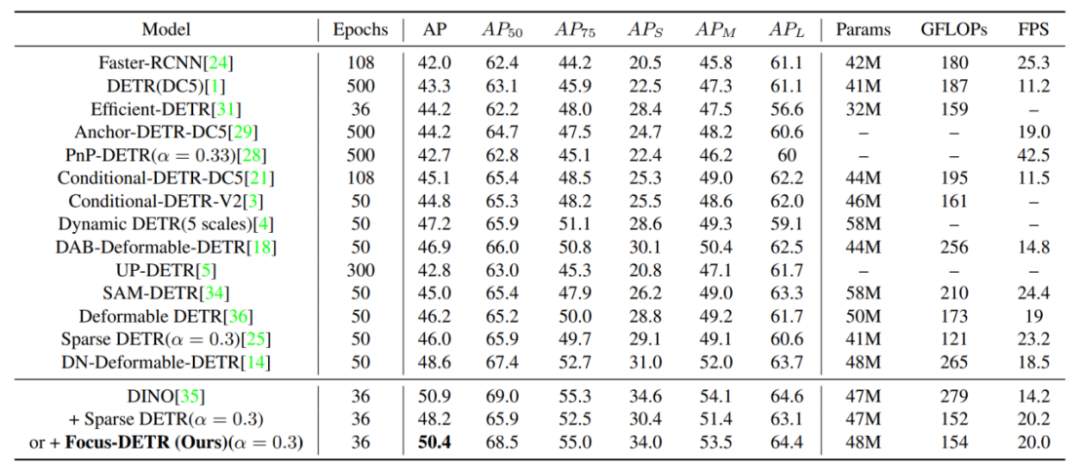
表 1:总体对比实验结果
模型效能分析
在图 6 中,从不同模型的精度和计算量之间的关系来看,Focus-DETR 在精度和计算复杂度之间达到了最好的平衡。整体来看对比其他模型,获得了 SOTA 的性能。
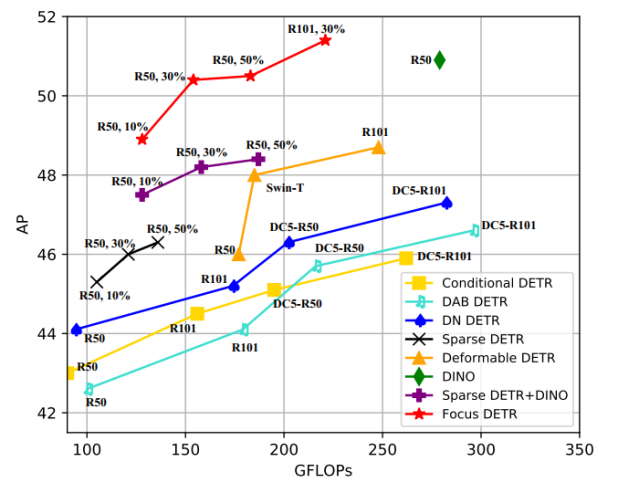
图 6 不同模型测试精度和计算复杂度之间的关联分析
消融实验
如表 2 所示,作者针对模型设计进行消融实验,以验证作者提出的算法的有效性。

表 2 本研究提出的前景特征剪枝策略和细粒度特征自注意力增强模块对实验性能的影响
1. 前景特征选择策略的影响
直接使用前景得分预测 AP 为 47.8,增加 label assignment 策略生成的标签作为监督,AP 提升 1.0。增加自上而下的调制策略,能够提升多尺度特征图之间的交互,AP 提升 0.4。这表明提出的策略对于提升精度是非常有效的。
如图 7 可视化可以发现,Focus-DETR 可以精确地选择多尺度特征上的前景 token。并且可以发现,在不同尺度的特征度之间,可以检测的物体存在重叠,这正是因为 Focus-DETR 使用了交叠的设置导致的。
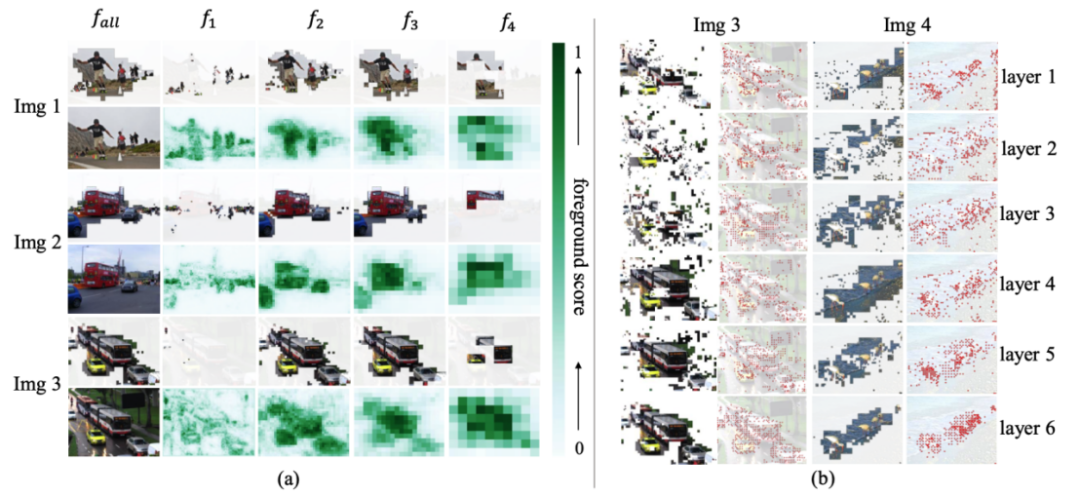
图 7 多尺度特征保留的 token
2. 自上而下的评分调制策略的影响
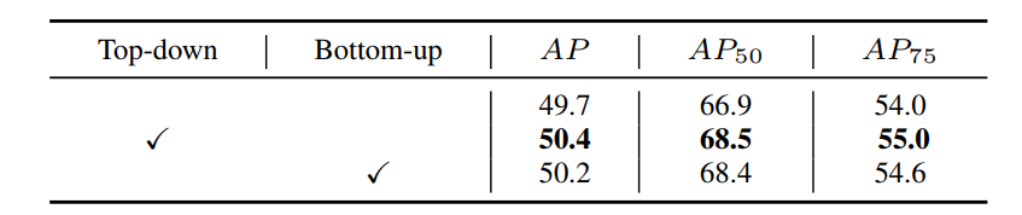
表 3. 多尺度特征图前景评分的关联方法,作者尝试自顶向下和自底向上的调制。
作者对比了自上而下的调制策略和自下而上的调制策略的影响,对比结果可以发现,作者提出的自上而下的调制策略可以获得更好的性能。
3. 前景保留比率对实验性能的影响
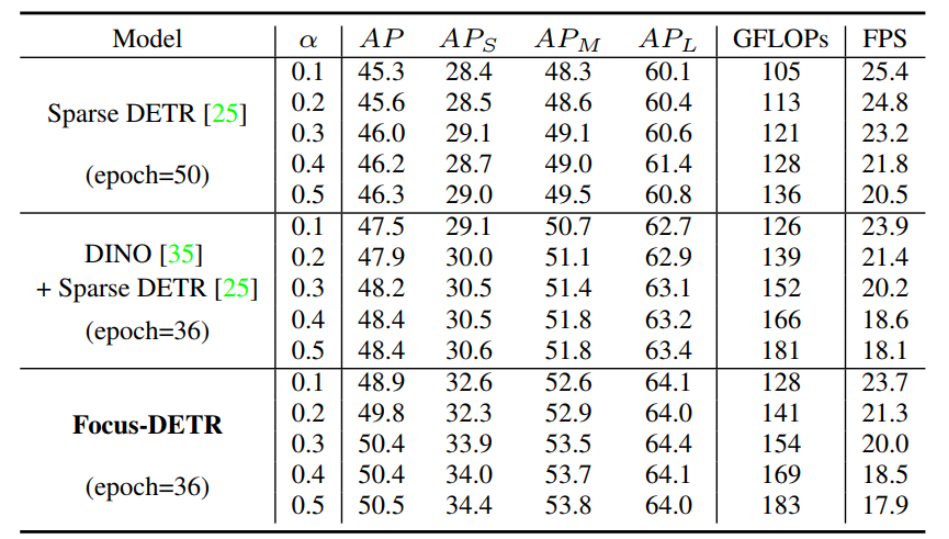
表 4.Focus-DETR、Sparse DETR 和 DINO+Sparse DETR 保留前景 token 的比例
作者对比了不同的剪枝比例的性能,从实验结果可以发现,Focus-DETR 在相同的剪枝比例情况下,均获得了更优的结果。
总结
Focus-DETR 仅利用 30% 的前景 token 便实现了近似的性能,在计算效率和模型精度之间取得了更好的权衡。Focus-DETR 的核心组件是一种基于多层次的语义特征的前景 token 选择器,同时考虑了位置和语义信息。Focus-DETR 通过精确地选择前景和细粒度特征,并且对细粒度特征进行语义增强,使得模型复杂度和精度实现更好平衡。
审核编辑:刘清
-
微软与Anthropic深度绑定,Maia 200芯片每美元Token效率飙升30%2026-05-26 336
-
使用OpenVINO™进行优化后,为什么DETR模型在不同的硬件上测试时显示不同的结果?2025-03-05 445
-
NB81是否支持OneNet SOTA功能?应该如何激活SOTA?2024-06-04 590
-
MS-DETR和其他SOTA方法的对比2024-01-23 1574
-
基于OpenVINO C# API部署RT-DETR模型2023-11-10 2121
-
基于OpenVINO C++ API部署RT-DETR模型2023-11-03 2526
-
基于OpenVINO Python API部署RT-DETR模型2023-10-20 2627
-
DETR架构的内部工作方式分析2023-08-30 2285
-
人工智能SOTA什么意思2023-08-22 27316
-
一种新型的DETR轻量化模型Focus-DETR2023-08-02 2004
-
通过A2B更新软件—A2B如何给汽车应用中的SOTA带来变革2023-06-15 3135
-
RT-DETR用114FPS实现54.8AP远超YOLOv82023-04-20 2887
-
SOTA的定义是什么?常规的实现方式有哪些2022-02-14 1440
-
SOTA机制详解2021-12-09 992
全部0条评论

快来发表一下你的评论吧 !
