

如何打通机器学习的三大玄关
描述
随着时下智能时代的发展,机器学习已成为不少专业人士的“必备技能”。尽管如此,可它在实用性上仍然存在一些问题。因而设计师们采取了架构精简、压缩、以及硬件加速等三种途径。都有啥特点呢?请往下看~
精简架构设计,输入/输出的极致简化
设计师减少层数或网络中各层之间连接数量的任何努力,都会直接降低推理的内存要求和计算量。因此,我们很难预测指定网络设计在指定问题和训练集上的作用,除非有经验可供参考。确定您是否需要特定深度学习网络设计中全部 16 层的唯一方法,是以网络的数层为样本对其进行训练和测试。但由于此类探索工作的费用较高,设计师往往更倾向于使用他们熟悉的网络架构;当然,探索也可能有助于节省大量成本。
让我们以 ImageNet 当前面临的众所周知的静态图像分类挑战为例。深度学习网络一般从上一层的每个节点为自身的每个节点获取加权输入,而图像分类研究人员有了重大发现,即使用卷积神经网络 (CNN) 可以化繁为简(图 3)。
在其初层中,CNN 使用较少的卷积引擎替代完全连接的节点。卷积引擎并不为每项输入提供权重,仅具有小型卷积核心。它可使用输入图像对核心进行卷积处理,生成特征图—一种 2D 数组,表示图像和图像各点处核心之间的相似度。然后,特征图可收到非线性化信息。卷积层的输出是一个三维数组:该层中每个节点的 2D 特征图。然后,该数组将经过池化运算降低分辨率,从而缩减 2D 特征图的大小。
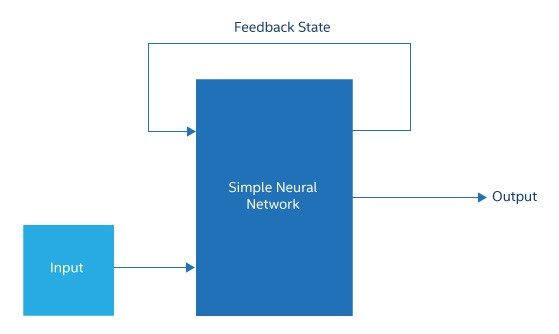
图 3. 递归神经网络通常只是将其部分中间状态或输出馈送回输入的简单神经网络
现代 CNN 可能具有许多卷积层,每个卷积层跟着一个池化层。在靠近网络输出端的位置,卷积和池化层终止,其余层是完全连接的。因此,网络从输入端到输出端逐渐变细,最终形成一个完全连接的层,其宽度刚好足以为每个所需的标记生成一个输出。与具有相似深度的完全连接的深度学习网络相比,该网络能够大幅减少权重、连接数和节点数。
“压缩”技术,突破推理的上限
机器学习社区使用压缩表示与卷积数据压缩截然不同的概念。该语境下的压缩包含一系列技术,用于减少生成推理所需的计算数量并降低其难度,修剪便是此类技术之一。在进行修剪时,深度学习网络训练通常会在权重矩阵中产生多个零或非常小的数值。实际上,这意味着无需计算将乘以权重的输入。因此,表示推理计算的数据流图表可被剪下一整个分支。经验表明,如果一个网络被修剪后再重新训练,其精度实际上可以提高。
另一种压缩方法是减少权重中的位数。虽然数据中心服务器可能将所有值保持在单精度浮点中,但研究人员发现,更低的权重精度和几个位足以实现与 32 位浮点几乎相同的精度。同样,在应用非线性之后,节点的输出可能只需要几个位。如果推理模型将在服务器上执行,这几乎没有帮助。然而,该方法在一个 MCU 上非常有用,一个能够非常有效地实施 2 位或 3 位乘法器的 FPGA 加速器可以充分利用这种压缩形式。
总之,在某些情况下,修剪技术、大幅减少位数和相关技术已经被证明可以减少 20 到 50 倍的推理工作。这些技术可以把经过训练的网络的推理工作控制在一些边缘计算平台的范围内。当压缩不足以达成目的时,设计师可以转向硬件加速,而且硬件加速有越来越多的替代方案。
硬件加速的新风标!
推理所需的计算既不多样也不复杂,主要包括许多乘积和 — 乘积累加 (MAC) — 运算,用于将输入乘以权重和在每个节点将结果相加。该计算任务还包括所谓的修正线性单元 (ReLU) — 用于将所有负值设置为零 — 等非线性函数、双曲正切或 sigmoid 函数 — 用于注入非线性 — 以及用于池化的最大值函数。总之,该计算任务看起来很像一个典型的线性代数工作负载。
应用超级计算领域的硬件思想。最简单的方法是将输入、权重和输出作为向量进行组织,并使用内置到大型 CPU 中的向量 SIMD 单元。为了提高速度,设计师在 GPU 中使用了大量着色引擎。通过在 GPU 的内存层次结构中安排输入、权重和输出数据避免抖动或高缺失率,(绝非无足轻重的小问题,)但这并没有阻止 GPU 成为数据中心深度学习领域使用最广泛的非 CPU 硬件。最近几代的 GPU 取得了长足进步,增加了更小的数据类型和矩阵数学块来补充浮点着色单元,能够更好地适应该应用。
这些调整说明了加速硬件设计师使用的基本策略:减少或消除指令获取和解码,减少数据移动,尽可能多地使用并行性,以及利用压缩。难点在于确保这些操作在实施时不会互相干扰。
使用这些策略有几种架构方法:
1、在芯片上对大量的乘法器、加法器和小型 SRAM 块进行实例化,并通过片上网络将它们链接起来。这为执行推理提供了原始资源,但存在一个关键挑战,即从计算元件中高效获取数据,以及将数据传输至计算元件及程序员。这些设计是过去许多大规模并行计算芯片的后继者,所有这些芯片都遭遇了难以攻克的编程挑战。
2、Google 张量处理单元(TPU)等芯片采用了进一步依托应用的方法,按照深层学习网络的固有结构组织计算元件。这类架构将网络的输入权重乘法视为非常大的矩阵乘法,并创建硬件矩阵乘法器来执行它们。在 TPU 中,乘法是在一个收缩乘法器数组中完成的,在这个数组中,操作数自然地从一个单元流到另一个单元。数组被缓冲区包围,以馈入激活和权重值,后面是激活函数和池化硬件。
通过对芯片进行特定的组织在一定程度上自动实施矩阵运算,TPU 可让程序员免于通过计算元件和 SRAM 对数据移动进行精细安排。编程变得非常简单,基本就包括将输入和权重分组成矩阵并按下按钮,但存在一个问题。如上所述,修剪会产生非常稀疏的矩阵,简单地将这些矩阵馈入像 TPU 一样的设备会导致大量毫无意义的乘法和加法。在模型开发的压缩阶段,可能需要将这些稀疏矩阵重新排列为更小的密集矩阵,以便充分利用硬件。
3、将推理任务作为一系列矩阵乘法建模,而非作为数据流图表建模。加速器被设计成一个数据流引擎,数据从一侧进入,通过可配置的链接流经一个类似于图表的处理元件网络,然后进行输出。这种加速器可以配置为仅执行所修剪网络需要的操作。
一旦选择了架构,接下来的问题就是实施。在开发过程中,许多架构源于 FPGA,以满足成本和调度要求。在一些情况下,一些架构将留在 FPGA 中——例如,当深度学习网络模型预计会发生一个加速器设计无法完全处理的过多改变。但是,如果模型的改变很小,例如层排列有所不同和权重发生改变,ASIC 或 CPU 集成加速器可能是首选项。
这又回到了边缘计算及其限制的话题。如果机器学习网络要在一组服务器上执行,那么在服务器 CPU、GPU、FPGA 或大型 ASIC 加速器芯片上执行都是可行的选择。但是,如果必须在一个更为有限的环境中执行,例如车间机器、无人机或摄像头,则需要一个小型的 FPGA 或 ASIC。
对于极其有限环境中的小型深度学习模型,例如手机,内置于应用处理器 SOC 中的低功耗 ASIC 或加速器块可能是唯一的选择。尽管到目前为止,这些限制往往会促使设计师努力设计简单的乘法器数组,但神经形态设计的卓越能效可能会使它们对下一代深度嵌入式加速器非常重要。
无论如何,机器学习都不再局限于数据中心范畴,推理正迈向边缘。随着研究人员不再聚焦当前的传统深度学习网络,将视线投向更多概念,边缘的机器学习问题有望成为架构开发的前沿课题。
审核编辑:汤梓红
-
沐曦开发者社区与启悟学习社区打通SSO互联2026-05-13 362
-
离线语音能为玄关灯带来升级2023-08-30 1485
-
机器学习和深度学习的区别2023-08-17 5912
-
如何打通机器学习的“三大玄关”,你该这样Get新技能!2023-08-05 1232
-
高效理解机器学习2023-05-08 1467
-
人工智能与机器学习、深度学习的区别2023-03-29 2673
-
什么是机器学习? 机器学习基础入门2022-06-21 3078
-
详谈机器学习及其三大分类2020-08-14 26132
-
“中间三天”问题 最对机器学习“胃口”2020-03-25 2651
-
深度解析机器学习三类学习方法2018-05-07 15264
-
人工智能、机器学习、深度学习三者关系分析2018-01-04 7677
-
【下载】《机器学习》+《机器学习实战》2017-06-01 199270
全部0条评论

快来发表一下你的评论吧 !
