

risc-v架构是哪个国家的
描述
随着苹果基于ARM的硅和新的RISC-V CPU的推出,对于CPU开发来说,这是一个令人兴奋的时刻,尽管开发人员的旅程目前对后者来说有点坎坷。
我最喜欢的理论是,没有发生是孤独的,而只是重复了以前发生过的事情,也许经常发生过。
马克·吐温认为,生活有重演的倾向。我们可以在苹果Macintosh的CPU架构变化中看到这一点的证据,如图1所示,1994年,最初的CISC(复杂指令集计算机)摩托罗拉68000被RISC(简化指令集计算机)摩托罗拉PowerPC取代。这反过来又在2005年被CISC Intel x86取代,并在2020年推出了基于ARM CPU的Apple Silicon,从而回归了RISC。
在2005年至2020年期间,英特尔x86作为笔记本电脑、台式机、企业服务器和HPC机器的首选CPU的主导地位似乎无懈可击,尽管ARM在移动设备中占据主导地位。此外,在此期间,我们看到了企业服务器和HPC域中竞争的RISC CPU架构的消亡,如Sun SPARC、MIPS和DEC Alpha,这表明CISC也许是CPU架构的未来。

图1-苹果Macintosh CPU过渡时间线。
然而,对于台式机和笔记本电脑来说,随着基于ARM的Apple Silicon M1片上系统(SoC)的推出,苹果在2020年对这一假设提出了挑战。与之前基于英特尔的版本相比,这不仅使基于M1的MacBook Pro的功耗降低了约90%,而且还将运行时性能提高了约75%[2]。此外,基于富士通ARM的超级计算机Fugaku的推出,在2021年11月的Top500排行榜上排名第一[3],进一步加强了x86作为CISC CPU架构的主导地位的挑战。
虽然Fugaku在2022年6月的Top500榜单中被基于x86的Frontier系统取代,但它仍然位居第2位,并表明ARM将成为x86的重要竞争对手,也许会让RISC成为高性能机器的主导CPU架构。RISC CPU架构比CISC架构更易于实现,需要更小的硅面积,并降低功耗。与CISC架构相比,这可以增加CPU时钟频率和模具上更多的内核,从而提高性能。
虽然领先的SPARC、MIPS和Alpha RISC架构已经倒在一边,使ARM成为x86的主要RISC挑战者,但它并不是唯一获得牵引力的RISC架构。来自加州大学伯克利分校的RISC-V是伯克利RISC CPU架构系列的第五个版本,目前正在引起大量关注。人们普遍认为,这种兴趣是由于RISC-V指令集架构(ISA)是开源的,允许其不受约束地使用。然而,其他CPU架构也是开源的,例如SPARC(OpenSPARC [4])。
RISC-V的关键区别在于其ISA是模块化的。目前有五个已批准的基ISA:RVM0(弱内存排序)、RV32I(基32位整数)、RV32E(只有16个寄存器的基32位基)、RV64I(基64位整数)和RV64E(只有16个寄存器的基64位整数)。如图2所示,还定义了一些ISA扩展[5],包括支持单精度和双精度浮点(分别为“F”和“D”),压缩指令(“C”)和矢量指令(“V”),使CPU设计人员能够选择基本ISA和扩展,以提供满足其需求的特定功能。例如,RV32E基础ISA只支持16个寄存器,而不是32个寄存器,通过相应的功率降低,节省了大约25%的核心硅面积[6]。这对于需要非常低功耗的电池供电的嵌入式或边缘设备是有益的。由于这些是单独的扩展,GCC和LLVM/Clang等编译器提供了根据需要选择这些扩展的任意组合的选项。这种模块化方法不仅为硬件制造商提供了更大的灵活性,还允许在不影响现有ISA规范的情况下创建和批准新的扩展。
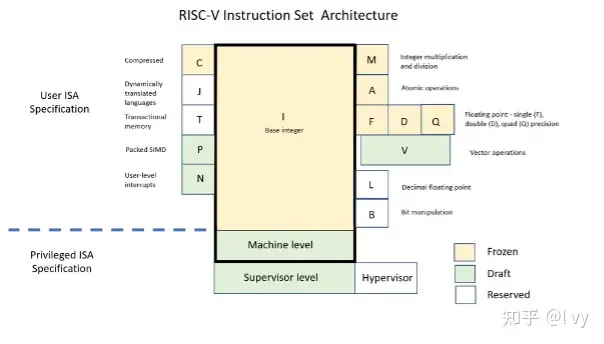
图2:基础RISC-V ISA和扩展[7]。
目前有一些嵌入式和低端RISC-V CPU/SoC可用,如64位Allwinner D1(基于XuanTie C906)和64位四核SiFiveU740。还有大量的软核,从RV32E(例如PicoRV32)到RV64GC(例如XuanTie C910和Andes X45)的变体。
然而,RISC-V ISA扩展的萌芽性质给开发人员带来了一些困难。例如,“V”矢量扩展,通常称为“RVV”,于2021年9月下旬在1.0版本中被冻结。虽然这是一个伟大的里程碑,但它与以前的RVV版本不兼容的事实是不幸的,因为目前唯一可用的支持RVV的硬CPU,C906,使用不兼容的v0.7规范。由于GCC和LLVM / Clang编译器都针对冻结或批准的ISA扩展,在这种情况下是RVV v1.0,开发人员无法使用主线编译器版本针对D1提供的矢量支持,并被迫依赖XuanTie开发的GCC v8.4。不幸的是,这不再从制造商那里公开提供,但可以从爱丁堡大学的DataShare网站下载[8]。当针对C906设备(如Allwinner D1)时,使用XuanTieGCC编译器生成矢量化代码可以获得明显的运行时性能优势,如一些RAJAperf[9]基准内核的图3所示[10]。
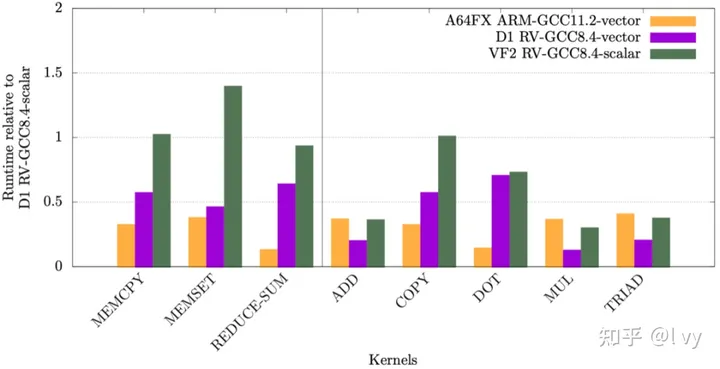
图3:矢量化RISC-V与标量代码的相对运行时性能[10]。
利用Allwinner D1矢量化支持的另一种方法是使用RVV v1.0到v0.7回滚工具[11],该工具由Joseph Lee博士开发,作为ExCALIBUR H&ES RISC-V测试台项目的一部分[12]。在这里,主线GCC和LLVM/Clang编译器可用于自动编码,该工具将生成的RVV v1.0汇编语言“.s”文件转换为RVV v0.7“.s”源文件。然后由XuanTieGCC编译器组装,以生成对象“.o”文件/二进制文件,以在基于Allwinner D1的板上执行。
虽然这仍然需要使用XuanTie GCC编译器,但原始源代码是使用最新的主流编译器版本编译的。有关使用RVV回滚工具的更多信息以及有关汇编RISC-V矢量代码的一般信息,请参阅RISC-V测试台网站[13]。
更一般地说,已经提供了RISC-V测试台,以支持那些希望在当前可用的RISC-V硬件上测试其代码的研究人员。目前,测试台在贫民窟集群中拥有24个RISC-V内核,2023年4月和5月将有额外的板,使核心总数达到72个。您可以使用网站上概述的步骤申请访问RISC-V测试台[14]。
当我们考虑20世纪90年代末和21世纪初的原始RISC架构的全盛时期,以及目前基于RISC的ARM和RISC-V CPU架构的兴起时,Mark Twain似乎是对的。
审核编辑 黄宇
-
Arm与RISC-V架构的优劣势比较2025-02-01 1786
-
【RISC-V开放架构设计之道|阅读体验】 RISC-V设计必备之案头小册2024-01-22 2046
-
最近的RISC-V架构情况2023-07-14 998
-
谈一谈RISC-V架构的优势和特点2023-05-14 2001
-
RISC-V架构2023-04-03 2044
-
RISC-V架构芯片的相关资料分享2021-11-11 2689
-
RISC-V架构简介2021-07-28 3869
-
分析RISC-V架构的不同之处2021-07-26 1805
-
RISC-V是什么2021-07-23 2273
-
risc-v架构是哪个国家的_risc-v架构优缺点2021-06-22 69541
-
ARM与RISC-V架构的区别是什么?2021-04-25 6558
-
科普RISC-V生态架构(认识RISC-V)2020-08-02 7006
-
RISC-V 生态架构浅析2020-06-22 3115
-
正式的RISC-V基础指令集架构与特权架构规范来了,RISC-V基金会已正式批准2019-07-11 11596
全部0条评论

快来发表一下你的评论吧 !
