

Linux实现原理—虚拟内存技术简析
嵌入式技术
描述
虚拟内存技术
虚拟内存技术是操作系统实现的一种高效的物理内存管理方式,具有以下作用:
- 使得进程间彼此隔离 :通过将物理内存和虚拟地址空间联系起来,并将虚拟地址空间与进程一一对应,每个进程都认为自己拥有了整个物理内存,使得进程之间彼此隔离。这让操作系统在运行多个进程的同时也保障了内存访问的安全。
- 使得进程共享物理内存 :将物理内存进行虚拟化后,多个进程可以同时共享同一块物理内存。
- 提升物理内存利用率 :有了虚拟地址空间后,操作系统只需要将进程当前正在使用的部分数据或指令加载入物理内存,没有在使用的部分数据或指令则可以存储在外存中,而不需要将整个进程的数据或指令全部载入物理内存。这使得操作系统可以在相对较小的物理内存下运行更多的进程,从而提升了物理内存的利用率。
- 方便内存管理 :虚拟内存技术将物理内存分割成若干块,每块都可以分配给不同的进程使用,这使得操作系统可以更加灵活地管理内存。如物理内存分配、回收等。
页式内存管理技术
页式内存管理技术是 Linux 实现的一种虚拟内存技术,其基本思想是将物理内存和虚拟内存都分割成多个固定大小的 Page(页),然后对这些 Pages 进行编址,并通过 Page Table(页表)将它们一一映射起来。当 CPU 访问虚拟地址空间时,Linux 会通过 Page Table 将虚拟地址转换为物理地址。
- Virtual Address(虚拟地址) :操作系统和应用程序使用的虚拟内存地址。
- Physical Address(物理地址) :实际的物理内存地址。
Linux 通过页式内存管理技术,除了能够高效地管理物理内存之外,还提供了许多额外的虚拟内存功能,例如:进程隔离、内存保护、共享物理内存等。
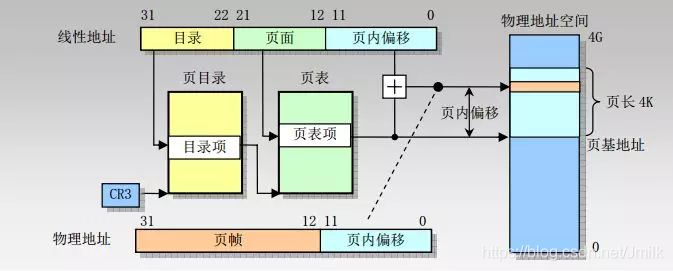
虚拟地址格式与页表(32bit 系统)
在 x86 32bit Linux 系统中,虚拟地址(也称为线性地址,Linear Address)的格式由 3 部分组成,总长度为 32bit,寻址范围为 2^32,最大可描述空间为 4G。
- Page Table Directory(10bit)
- Page Table Entry(10bit)
- Offset(12bit)
在 Kernel 中用于对虚拟地址进行寻址的数据结构称为 Kernel Page Table(内核页表),包括:
- 页表目录(Page Directory):可包含 1024 个目录项。
- 目录项(Directory Entry):每个目录项指向一个页表,即有 1024 个页表。
- 页表(Page Table):大小为 4KB,页表项的大小为 4B,即一个页表可包含 1024 个页表项。
- 页表项(Page Table Entry):每个页表项指向一个页。
- 属性标记:用于将每个页表项标记为只读、可写、只执行等,以控制内存的访问权限和缓存行为。
可见,32bit 系统中的 2 级页表结构,最多可以映射 1024*1024 个 Pages。而对于大于 4GB 的物理地址空间,则需要使用多级级页表结构,以支持更大的物理内存空间。
虚拟地址格式与页表(64bit 系统)
在 x86 64bit 系统中,可以描述的最长地址空间为 2^64(16EB),远远超过了目前主流内存卡的规格,所以在 Linux 中只使用了 48bit 长度,寻址空间为 2^48(256TB),User Space 和 Kernel Space 各占 128T。寻址空间分别为:
- User Space :0x0000 0000 0000 0000~0x0000 7FFF FFFF F000,高 16bit 全 0。
- Canonical Address Space :0x0000 7FFF FFFF F000 - 0xFFFF 8000 0000 0000,无效地址空间。
- Kernel Space :0xFFFF 8000 0000 0000~0xFFFF FFFF FFFF FFFF,高 16bit 全 1。
由于内存空间的扩大,x86 64bit 系统中的虚拟地址格式由 5 部分组成,占 64bit 中的 48bit。相应的,Linux Kernel 在 v2.6.10 中实现了四级页表,后来又在 v4.11 中引入了五级的页表结构。
就四级页表而言,虚拟内存空间被划分成了 4 个层次结构,每一级都有一个页表来记录该层次的映射关系。
- PGD(Page Global Directory,全局页目录)
- PUD(Page Upper Directory,上级页目录)
- PMD(Page Middle Directory,中间页目录)
- PTE(Page Table Entry,页表项)
当 CPU 需要访问一个虚拟地址时,会执行以下页表遍历流程:
- 首先根据虚拟地址的 GLOBAL DIR(9bit) ,确定在 PGD 中的页表项,开始寻址 PUD。
- 再根据虚拟地址中的 UPPER DIR(9bit) ,确定 PUD 中的页表项,开始寻址 PMD。
- 再根据虚拟地址中的 MIDDLE DIR(9bit) ,确定 PMD 中的页表项,开始寻址 PTE。
- 再根据虚拟地址中的 TABLE ID(9bit) ,确定 PTE 中的页表项,开始寻址 Physical Page(物理内存页框)。
- 最后根据虚拟地址中的 OFFSET(12bit) ,确定 Physical Page 中的 Page Lane(页条)。
在页表遍历的过程中,如果找到对应的物理页框,则可以进行对应的内存读写操作。反之,如果遇到了寻址失败的情况,则说明对应的物理页框没有被分配或者被换出到外存了,此时需要进行相应的页表调度和页表交换操作。

四级页表的优点是它可以映射非常大的虚拟内存空间,并且每个进程的页表都是独立的,相互干扰。缺点是每次访问内存都需要遍历四级页表,这会导致一定的性能损失。并且,当 Linux 设定的虚拟页大小越小时,单个进程中的页表项和虚拟页也就越多,页表的层级也可能越多,查询性能就越低。同时也需要注意,页面并非是越大越好,因为过大的页面会造成内存碎片,降低了内存的利用率。
因此,Linux 采用了一些优化措施,如 TLB(Translation Look-aside Buffer)缓存等,来加速页表遍历的过程。

CPU MMU 虚实地址转换
Linux 虚实地址转换功能,除了需要由 Kernel 实现的内核页表(Page Table)数据结构之外,还需要硬件层面的 CPU MMU(Memory Management Unit,存储管理单元)支持。
MMU(Memory Management Unit,内存管理单元)内嵌在 CPU 芯片上,它是一个专用的硬件,利用存放在 Main Memory 中的 Page Table 来辅助完成虚实地址之间的动态翻译,而 Page Table 的内容就交由 Kernel 来统一管理。
当 CPU 访问虚拟地址时,MMU 首先将虚拟地址的高位部分作为页表的索引,查找对应的页表项。页表项中存储了与虚拟页对应的物理页的起始地址以及一些标志位,如是否可读、可写等。然后,MMU 将虚拟地址的低位部分作为偏移量,加上物理页的起始地址,得到实际的物理地址。

TLS 快表转换
TLB(Translation Look-aside Buffer,翻译旁路缓冲器)同样是内嵌在 CPU 芯片上的一个专用硬件,作为缓存,旁挂在 MMU 上,缓存了最近访问过的虚拟地址与物理地址之间的映射关系,以便在下次访问时快速地进行翻译。TLB 的空间非常有限,一般只可缓存几十个到数百个条目。
通过 TLB,操作系统可以旁路掉多级页表遍历的流程,只需要在 TLB 中执行一次高速访问即可,前提是没有 TLB Miss(缓存失效)。如果 Miss 的话,就会回到常规的页表遍历流程,然后再利用局部性原理去更新 TLB。

虚拟地址空间与 CPU 运行模式

为了保障多任务实时操作系统运行的安全性和稳定性,Intel x86 CPU 提供了 Ring0-3 这 4 种不同的运行模式,而 Linux 只使用了其中的 Ring0(特权指令模式)和 Ring3(非特权指令模式),为虚拟地址空间提供了 2 级保护机制。

相应的,在 32bit Linux 系统中,大小为 4G 的虚拟地址空间,被分成了 2 个部分:
- User Space(0x0~0xBFFF FFFF,0~3G) :每个 User Process 都有自己的 User Space 且互相隔离。运行在 CPU Ring3(用户模式)模式,User Process 的代码被限制了可以执行的操作以及可以访问的资源范围;
- Kernel Space(0xC000 0000~0xFFF FFFF,3~4G) :属于 Kernel 的 Kernel Space。运行在 CPU Ring0(内核模式)模式,Kernel 代码没有被限制,可以执行任何操作并且可以访问任何资源。
所以,Linux 中的 Page Table 也可以被分为 2 种:
- 内核页表区 :用于 Kernel Space 高端内存映射区与物理地址空间之间的映射。
- 进程页表区 :每个 User Process 拥有自己的页表,用于进程虚拟地址空间与物理地址空间之间的映射。

另外,User Space 可以通过 SCI(系统调用接口)来访问或操作 Kernel Space 的代码和数据,同时也会触发 CPU 运行模式的切换。例如:C 标准库中的 malloc() 函数底层调用了 sbrk() 或 brk() SCI 来分配堆内存;printf() 函数底层调用了 wirte() SCI 来输出字符串等等。

虚拟地址空间的布局(32bit 系统)

从上图可以看出 Linux 对虚拟地址空间作了复杂的分段布局,主要是为了实现更加高效的内存管理和保护机制。
以 User Space 为例:
- 持久化的程序流代码(顺序程序流、条件程序流、循环程序流)存储在 Test Segment 中。
- 持久化的、且初始化的常量、全局变量、静态变量(包括静态全局变量、静态局部变量)存储在 Data Segment 中。
- 持久化的、但未初始化的全局变量、静态变量(包括静态全局变量、静态局部变量)存储在 BSS Segment 中。
- 临时的函数局部变量存储在 Stack Segment 中。
- 临时由用户自主申请的数据存储 Heap Segment 或 MMAP Segment 中。
划分不同的存储空间更有助于针对不同的数据内容进行合理的访问和存储规划。例如:
- 提高 CPU Cache 利用率 :将指令区、持久数据区、动态数据区进行分离,有利于应用局部性原理来发挥出 CPU Instruction Cache(指令缓存)和 Data Cache(数据缓存)的优势。
- 节省内存空间 :如果系统中运行多个该程序的副本时,指令区中的 Read Only 数据可被共享,物理内存实际上只需要存储一份。
User Space
在 User Space 中,每个 User Process 都有一个 task_struct(进程描述符)。
struct task_struct {
pid_t pid; // User Process ID
pid_t tgid; // Kernel Thread ID
struct files_struct *files; // 文件描述符
struct mm_struct *mm; // 内存映射描述符
...
}
其中,除了 Environment Variables(程序运行时环境变量)和 Command-line arguments(程序运行指令行参数)之外,进程虚拟地址空间的内存布局都通过 mm_struct 结构体来进行描述。

Stack Segment(用户栈)
User Process 下属的每个 User Thread 都有属于自己的用户线程栈。主要用于存储以下信息:
- 存储函数调用信息(Procedure Activation Record,过程活动记录)或栈帧(Stack Frame)。
- 存储函数内部的非静态(Non-static)变量;
- 提供临时存储区,使用 C 标准库 alloca() 函数可动态申请栈内内存。
Stack Segment 的空间具有 “静态分配" 和 “动态分配” 这 2 种使用形势。其中,静态分配由 C 编译器自动分配和管理,主要应用在函数处理流程。而动态分配则由程序通过 alloca() 函数主动申请和释放。
例如:在一次函数调用中,C 编译器依次入栈的数据包括:
- 主调函数下一条语句(指令);
- 被调函数的返回值地址;
- 被调函数的实际参数;
- 被调函数局部变量等。
通过先进后出(FILO)的数据结构,使得被调函数退出后,可以继续执行主调函数的语句。
Stack Segment 是一块连续的空间,运行时大小可以由 Kernel 动态调整(向下增长),且最大容量 RLIMIT_STACK(8M)由系统预先定义,用户也可以通过 ulimit -s 指令来查看和设定栈的最大值。
$ ulimit -s
8192
当程序入栈数据超出容量之后,就会触发 Stack Overflow(溢出)错误,此时程序收到一个 Segmentation Fault(段错误)异常。
函数调用栈的工作原理
程序每执行一次函数调用都会在 Stack 中生成一个栈帧(Stack Frame),对应着一个未运行完的主调函数,用于存储被调函数的执行环境信息,包括:函数实际参数、函数局部变量、函数返回值地址等等。
栈帧主要通过两个指针寄存器来实现:
- ebp(帧指针) :指向帧底,作为基址指针,不会移动。
- esp(栈指针) :指向栈顶,可以移动,通过移动 esp 来访问栈帧中的数据。
ebp 到 esp 之间的地址空间就是用于存储当前被调函数执行环境信息的空间。
另外,Stack Segment 很可能会同时存在多个栈帧(函数嵌套调用),此时多个栈帧会根据函数调用顺序在 Stack Segment 中先入后出。
例如:虽然 esp 会随着当前函数的入栈和出栈而不断移动,但由于 ebp 的存在,所以当前函数栈帧的边界始终是清晰的。当被调函数退出后,ebp 就会跳到主函数栈帧的底部,esp 也会随其自然的来到主函数栈帧的头部。

Memory Mapping Segment(内存映射段)
Memory Mapping Segment(内存映射段)的空间通过 mmap() SCI(系统调用接口)来使用,用于将外存(e.g. 硬盘)中的一个文件、或一段物理内存直接映射到 Memory Mapping Segment 中,而后 User Process 就可以采用指针的方式来访问一段内存,而不必再调用 read() / write() 等 SCI。mmap() 是一种高效的 I/O 方式。

Memory Mapping Segment 主要有 2 类应用场景:
- File mappings(文件映射) :在程序装载过程中,将程序所需要 #include 的 .so 动态共享库文件(Dynamic share libraries)加载到 Memory Mapping Segment 内存空间。
- Anonymous mappings(匿名内存映射) :C 标准库 malloc() 函数的底层实现方式之一就是对大于 MMAP_THRESHOLD(默认为 128KB)的空间申请,会调用 mmap() SCI 从 Memory Mapping Segment 中分配,而不是调用 sbrk() 或 brk() SCI 从 Heap 申请。
Memory Mapping Segment 的空间大小同样可以由 Kernel 动态调整(向上增长)。
Heap Segment(运行时堆)
Heap Segment(运行时堆)的空间由程序自行使用,包括分配和释放。例如:开发者可通过 C 标准库 malloc() 函数申请并返回 void*(无类型指针),且无名称,只能通过指针访问。
在 Kernel 层面通过堆管理器来管理 Heap Segment 的空间。堆管理器通过链表存储结构来记录 Heap Segment 空间的使用情况,记录了包括:空闲的内存地址、已使用的内存地址等。
当程序申请一块内存时,堆管理器会遍历链表寻找第一个空间大于所申请空间的节点,并返回地址给程序,然后将该节点从空闲链表中删除。所以 Heap 空间中的多个内存块之间很可能是不连续的。
当目前的 Heap Segment 已经没有足够的空间时(可能由于内存碎片太多导致的),那么堆管理器可能会通过 brk() 或 sbrk() SCI 进行动态调整(向上增长),实际上是通过调整 Heap Segment 末端的 break 指针来实现。
Heap Segment 的空间总大小受到 CPU 架构和操作系统位数影响,例如:32bit 架构的 Heap Segment 最大可达 2.9G 空间。
应用程序装载与数据段
当开发者经过编码、编译、汇编、链接一个 C 程序后就得到了一个可执行程序的文件。然后,就需要通过程序装载器(Loader)将可执行文件加载到 User Space 中并启动一个 User Process。在 Linux 上,可执行文件采用的是 ELF(Executable and Linkable File Format,可执行与可链接文件格式)格式。
ELF 文件由 4 部分组成,分别是:
- ELF Header
- Program Header Table(程序头表)
- Sections(节)
- Section Header Table(节头表)

其中,位于 Program Header Table 和 Section Header Table 之间的都是 Sections,这些 Sections 中的数据会在程序启动时被加载到相应的进程虚拟地址空间中。
关键的 Sections 包括以下几个:
- .bss :存储未初始化的全局变量和静态变量。
- .data :存储已初始化的全局变量和静态变量。
- .rodata :存储只读数据(e.g. 常量)。
- .text :存储已编译程序的机器指令代码。
- .debug :调试符号表,调试器用此段的信息帮助调试。

数据段(BSS Segment 和 Data Segment)
BSS Segment 和 Data Segment 常被合并称为 “数据段”,都用于存储全局变量和静态变量,区别于存储在 Stack Segment 中的函数局部变量。
- BSS(Block Started by Symbol,未初始化的数据段) :可读写,主要存储了从 ELF .bss section 中加载的数据,包括:1)已定义,但未初始化的全局变量和静态变量;2)已定义,且初始值为 0 的全局变量和静态变量,例如 C 编译器中的空指针。
- Data Segment(已初始化的数据段) :可读写,主要存储了从 ELF .data section 中加载的数据,包括:已定义、且已初始化、且初值不为 0 的全局变量、静态变量和常量。所以,Data Segment 也被称为 “静态存储区(Static data area)”。
ELF .bss section 的特别之处在于没有具体的数值,所以只需要记录下全局变量和静态变量所需要的内存空间大小即可,但并不会分配真实的内存空间,即:只记录了全局变量和静态变量在虚拟地址空间中的开始和结束地址。
当程序加载器(Loader) 将 ELF .bss section 加载到 BSS Segment 后,这些数据会被 C 编译器自动的初始化为 0 或 NULL。这样可以有效的减少了 C object file 的体积。
例如:对于 int arr0[10000] = {1, 2, 3, …} 和 int ar1[10000] 这两个数组而言:
- arr0 存储在 Data Segment,记录了每个数组元素的数值。
- arr1 存储在 BSS Segment,只记录了 arr1 的起始和结束地址,直到程序启动时才被编译器在相应的虚拟地址空间中刷 0。显著的减少了可执行文件的大小。
Text Segment(代码段)
Text Segment(代码段)主要存储了从 ELF .text section 中加载的机器指令。
Text Segment 中的数据只能读不能写,但可以被执行,即:Text Segment 中的数据是可共享的,可以被其他的进程执行。例如:机器中有数个进程运行相同的一个程序,那么它们就可以使用同一个代码段。
可见,User Space 划分了明确的 “数据区” 和 “指令区",且数据区对于进程而言可读写,而指令区对于进程只读,以防止程序指令被误改。
内存缺页中断
基于 Linux 虚拟内存管理技术,每个 User Process 都拥有自己独立的虚拟地址空间,当一个 User Process 被 Kernel 加载并运行时,无需要一次性将 User Process 所有数据都加载到 Main Memory 中,而是当通过 Page Table 缺页中断的方式来动态加载。
虚拟地址的页表遍历过程中,当访问到某个页面时,通过页表项中的有效位,可以得知此页面是否在内存中,如果不存在,则通过缺页异常,将磁盘对应的数据拷贝到内存中,如果没有空闲内存,则选择牺牲页面,替换掉其他页面。在这个时候,被内存映射的文件实际上成了一个分页交换文件。

Kernel Space

Kernel Space 与物理地址空间的映射关系
区别于 User Space 只拥有虚拟地址空间。Kernel Space 除了虚拟地址空间之外,还直接拥有一部分的物理地址空间。也就是说 Kernel Space 具有 2 种地址映射关系,如下图所示。
- 直接映射(Linear Mapped) :Kernel Space 虚拟地址空间中的 3G~3G+896M 与物理地址空间的 0~896M 直接一对一映射,拥有最高的效率。
- 动态映射(Dynamic Mapped) :Kernel Space 虚拟地址空间中的高端内存映射区(0xF800 0000 ~ 0xFFFF FFFF)动态的与物理地址空间 896M~4G 中的某块物理页面建立映射(通过 Page Table),即:在有需要的时候才建立映射,待使用完之后就释放映射,以供其它物理页面映射。

物理地址空间布局
基于不同的用途,Linux 将物理内存划分为 3 个 ZONEs,从地址低到高为:
- ZONE_DMA(0~16M) :是 Kernel 直接映射的物理地址空间。
- ZONE_NORMAL(16M~896M) :是 Kernel 直接映射的物理地址空间,Kernel 将需要频繁使用的数据存放于此。
- ZONE_HIGHMEM(896M~4G) :是 Kernel 动态映射到物理地址空间,Kernel 将不常用数据存放于此,只在要访问这些数据时才建立映射关系。

最终,通过结合两种映射方式,Linux Kernel 可以完全接管整个 4G 物理内存空间。如下图所示,蓝色区域为直接映射空间,绿色区域为动态映射空间,棕色区域为动态映射页面。

物理直接映射区
根据 User Process 对 Kernel Space 访问权限的不同,还可以将 Kernel Space 分为 “进程私有” 和 “进程共享” 这 2 块区域。
- 进程私有区域 :每个进程都有单独的内核栈、页表、task 结构以及 mem_map 结构等。
- 进程共享区域 :属于所有进程共享的内存区域,包括:物理存储器、内核数据和内核代码区域。

Kernel Space 中的物理直接映射区,属于 “进程共享区域",是为了让 Kernel Space 或者 User Space 可以直接访问某些特殊的物理内存区域。这些物理内存区域包括:
- ZONE_DMA :NIC、GPU 此类 I/O 外设所提供的 DMA Controller 只能对内存的前 16M 进行寻址。为了方便设备驱动程序的实现,Linux 通过物理直接映射区,使得 Kernel 和 User Process 可以直接访问这些外设的存储器。此外,在 ZONE_DMA 中还划分了用于 BIOS ROM 和 VGA 适配器的区域,地址为 640K~1M 。
- ZONE_NORMAL :常规内存区域,没有特殊的使用限制,主要用于 User Process 和 Kernel 之间的交互,以及作为文件缓存加快文件系统的访问速度,避免频繁地读写磁盘。例如:存放 Kernel Image(内核代码)、mem_map 数组等数据。
可见,物理直接映射区使得 Kernel 和 User Process 得以更方便地访问一些特殊的物理内存区域,从而简化了操作系统和设备驱动程序的编写。
DMA 直接内存访问
DMA(Direct Memory Access,直接内存访问)指的是主机的 I/O 外设对 Main Memory 的直接访问。有了 DMA 机制之后,外设跟主存之间的数据交互主要由 DMA Controller 来完成的,从而避免了 CPU(包括 MMU)的参与。

高端内存映射区
物理内存中的 ZONE_NORMAL(高端内存区域)大小为 4G - 896M = 3200M,远远大于 Kernel Space 剩余的 1G - 896M = 128M 虚拟地址空间。所以 Kernel 对 ZONE_NORMAL 的访问需要采用动态映射的方式。
Kernel Space 中的 128M 统称为 “高端内存映射区”,主要有以下 3 个部分组成:
- Fixing Kernel Mapping(固定映射区)/ Temporary Kernel Mapping(临时映射区)
- Persistent Kernel Mapping(持久映射区)
- Vmalloc Area / Loremap Area(动态映射区)

Fixing Kernel Mapping(固定映射区)/ Temporary Kernel Mapping(临时映射区)
Fixing Kernel Mapping(固定映射区)通常用于静态分配内存,例如:驱动程序需要一段固定大小的内存来存储数据结构或缓冲区,它可以使用 Fixing Kernel Mapping 将一段物理内存空间映射到内核虚拟地址空间中,并在整个生命周期中保持映射关系。
Temporary Kernel Mapping(临时映射区)通常用于动态分配内存,例如:驱动程序需要在运行时创建一个临时缓冲区来存储数据,它可以使用 Temporary Kernel Mapping 来创建一个临时的虚拟内存区域,映射到物理内存空间中,并在使用完毕后释放虚拟内存空间。
Persistent Kernel Mapping(持久映射区)
Persistent Kernel Mapping(持久映射区)用于在 Kernel Space 中维护一组持久性的映射关系。这些映射通常是针对硬件设备或驱动程序的,允许 Kernel 直接访问这些设备或驱动程序的存储器区域。例如:用于 PCI I/O 外设进行内存映射的区域,大小由 PCI 规范决定。
Vmalloc Area(动态映射区)
Vmalloc Area(动态映射区)用于 Kernel 动态分配内存,例如:当 Kernel 需要访问 I/O 外设的存储空间时,就会使用 ioremap() SCI 将位于物理地址空间中的 MMIO 内存映射到 Kernel Space 的 vmalloc area 中,并在使用完之后释放映射关系。
vmalloc() 和 kmalloc() 内存分配函数
vmalloc() 和 kmalloc() 函数都用于从 Kernel Space 中申请内存,但两者有很大的不同:
- vmalloc() 用于从动态内存映射区申请非连续的物理内存(通过内核页表映射),可以最大限度的使用高端物理内存空间。通常应用于为活动的 Swap 交换分区分配数据结构、或为某些 I/O 驱动程序分配缓冲区、或为内核模块分配空间。
- kmalloc() 用于从直接内存映射区申请连续的物理内存(通过 Slab 分配器分配)。
与 User Space 中的 malloc() 不同,在 Kernel Space 进行内存申请是直接分配的,区别于 User Space 的延迟分配(通过缺页机制来反馈)方式。一旦 vmalloc() 和 kmalloc() 申请内存,那么 Kernel 就必须立刻满足。

-
虚拟内存的作用和原理 如何调整虚拟内存设置2024-12-04 6064
-
一文详解Linux虚拟内存技术2023-07-17 1400
-
Linux虚拟内存管理技术的相关资料分享2021-12-22 933
-
Linux的虚拟内存究竟是什么?2021-06-21 2767
-
一篇文章带你吃透Linux虚拟内存2021-06-07 2795
-
进程虚拟内存布局以及进程的虚拟内存分配释放流程,涉及的代码2020-06-28 5815
-
Linux:测试进程占用的虚拟内存大小2020-06-23 3687
-
虚拟内存怎么设置_虚拟内存注意事项2020-06-11 2818
-
虚拟内存不足怎么解决2019-03-14 14527
-
虚拟内存是什么_虚拟内存有什么用2017-11-01 10205
全部0条评论

快来发表一下你的评论吧 !
