

RT-Thread内存管理算法源码阅读
电子说
描述
之前对RT-Thread中如何解决
分配内存时间的确定性问题
内存碎片问题
资源受限的设备的内存管理问题
比较好奇,所以查看了RT-Thread关于内存管理算法的源码,在此和官方文档一起整理出来。
RT-Thread对于内存管理主要有三种方式:小内存管理算法、slab管理算法和memheap管理算法,分别在src/mem.c、src/slab.c和src/memheap.c中。
小内存管理算法
小内存管理算法是一个简单的内存分配算法。初始时,它是一块大的内存。当需要分配内存块时,将从这个大的内存块上分割出相匹配的内存块,然后把分割出来的空闲内存块还回给堆管理系统中。并有一个指针指向空闲内存块的第一个。
struct rt_small_mem
{
struct rt_memory parent; / < inherit from rt_memory /
rt_uint8_t heap_ptr; / < pointer to the heap */
struct rt_small_mem_item *heap_end;
struct rt_small_mem_item *lfree;
rt_size_t mem_size_aligned; /< aligned memory size */
};
每个内存块都包含一个管理用的数据头,而通过这个数据头和数据大小计算来偏移得到下一个内存块,本质上是通过数组的方式。
每个内存块(不管是已分配的内存块还是空闲的内存块)都包含一个数据头,其中包括:
1)magic:变数(或称为幻数),它会被初始化成 0x1ea0(即英文单词 heap),用于标记这个内存块是一个内存管理用的内存数据块;变数不仅仅用于标识这个数据块是一个内存管理用的内存数据块,实质也是一个内存保护字:如果这个区域被改写,那么也就意味着这块内存块被非法改写(正常情况下只有内存管理器才会去碰这块内存)。
2)used:指示出当前内存块是否已经分配。
struct rt_small_mem_item
{
rt_ubase_t pool_ptr; / < small memory object addr /
#ifdef ARCH_CPU_64BIT
rt_uint32_t resv;
#endif / ARCH_CPU_64BIT /
rt_size_t next; / < next free item */
rt_size_t prev; / < prev free item /
#ifdef RT_USING_MEMTRACE
#ifdef ARCH_CPU_64BIT
rt_uint8_t thread[8]; / < thread name */
#else
rt_uint8_t thread[4]; /< thread name /
#endif / ARCH_CPU_64BIT /
#endif / RT_USING_MEMTRACE */
};
内存管理算法的初始化和删除比较简单,主要是对rt_small_mem和第一个内存块的初始化,以及对内核对象的操作。
内存管理的表现主要体现在内存的分配与释放上,小型内存管理算法可以用以下例子体现出来。
如下图所示的内存分配情况,空闲链表指针 lfree 初始指向 32 字节的内存块。当用户线程要再分配一个 64 字节的内存块时,但此 lfree 指针指向的内存块只有 32 字节并不能满足要求,内存管理器会继续寻找下一内存块,当找到再下一块内存块,128 字节时,它满足分配的要求。因为这个内存块比较大,分配器将把此内存块进行拆分,余下的内存块(52 字节)继续留在 lfree 链表中,如下图分配 64 字节后的链表结构所示。
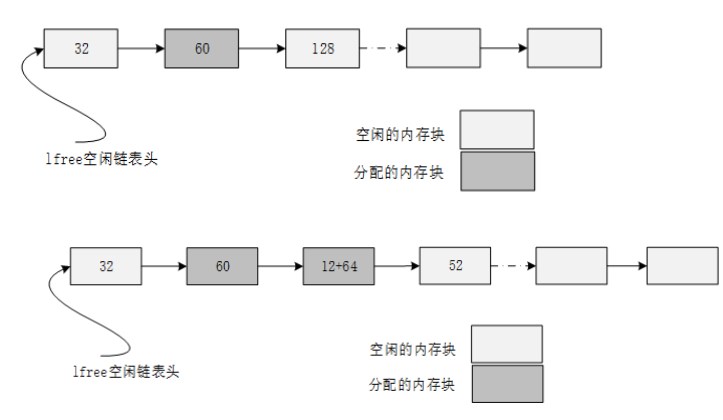
另外,在每次分配内存块前,都会留出 12 字节数据头用于 magic、used 信息及链表节点使用。返回给应用的地址实际上是这块内存块 12 字节以后的地址,前面的 12 字节数据头是用户永远不应该碰的部分(注:12 字节数据头长度会与系统对齐差异而有所不同)。
总的来说,大致有以下几步:
首先是基本条件的判定和操作,如内存对齐和大小等
遍历空闲的内存块链表
这里本质上不是链表,而是数组
所以是通过计算偏移完成遍历的
速度十分快
如果内存块足够大,那就进行切割
否则就不切割
然后更新内存的基本信息
更新当前空闲内存块链表(数组)的头结点
void *rt_smem_alloc(rt_smem_t m, rt_size_t size)
{
rt_size_t ptr, ptr2;
struct rt_small_mem_item *mem, *mem2;
struct rt_small_mem *small_mem;
if (size == 0)
return RT_NULL;
RT_ASSERT(m != RT_NULL);
RT_ASSERT(rt_object_get_type(&m->parent) == RT_Object_Class_Memory);
RT_ASSERT(rt_object_is_systemobject(&m->parent));
if (size != RT_ALIGN(size, RT_ALIGN_SIZE))
{
RT_DEBUG_LOG(RT_DEBUG_MEM, ("malloc size %d, but align to %dn",
size, RT_ALIGN(size, RT_ALIGN_SIZE)));
}
else
{
RT_DEBUG_LOG(RT_DEBUG_MEM, ("malloc size %dn", size));
}
small_mem = (struct rt_small_mem )m;
/ alignment size /
size = RT_ALIGN(size, RT_ALIGN_SIZE);
/ every data block must be at least MIN_SIZE_ALIGNED long */
if (size < MIN_SIZE_ALIGNED)
size = MIN_SIZE_ALIGNED;
if (size > small_mem->mem_size_aligned)
{
RT_DEBUG_LOG(RT_DEBUG_MEM, ("no memoryn"));
return RT_NULL;
}
for (ptr = (rt_uint8_t *)small_mem->lfree - small_mem->heap_ptr;
ptr <= small_mem->mem_size_aligned - size;
ptr = ((struct rt_small_mem_item *)&small_mem->heap_ptr[ptr])->next)
{
mem = (struct rt_small_mem_item )&small_mem->heap_ptr[ptr];
if ((!MEM_ISUSED(mem)) && (mem->next - (ptr + SIZEOF_STRUCT_MEM)) >= size)
{
/ mem is not used and at least perfect fit is possible:
mem->next - (ptr + SIZEOF_STRUCT_MEM) gives us the 'user data size' of mem /
if (mem->next - (ptr + SIZEOF_STRUCT_MEM) >=
(size + SIZEOF_STRUCT_MEM + MIN_SIZE_ALIGNED))
{
/ (in addition to the above, we test if another struct rt_small_mem_item (SIZEOF_STRUCT_MEM) containing
at least MIN_SIZE_ALIGNED of data also fits in the 'user data space' of 'mem')
-> split large block, create empty remainder,
remainder must be large enough to contain MIN_SIZE_ALIGNED data: if
mem->next - (ptr + (2*SIZEOF_STRUCT_MEM)) == size,
struct rt_small_mem_item would fit in but no data between mem2 and mem2->next
@todo we could leave out MIN_SIZE_ALIGNED. We would create an empty
region that couldn't hold data, but when mem->next gets freed,
the 2 regions would be combined, resulting in more free memory
/
ptr2 = ptr + SIZEOF_STRUCT_MEM + size;
/ create mem2 struct */
mem2 = (struct rt_small_mem_item )&small_mem->heap_ptr[ptr2];
mem2->pool_ptr = MEM_FREED();
mem2->next = mem->next;
mem2->prev = ptr;
#ifdef RT_USING_MEMTRACE
rt_smem_setname(mem2, " ");
#endif / RT_USING_MEMTRACE /
/ and insert it between mem and mem->next */
mem->next = ptr2;
if (mem2->next != small_mem->mem_size_aligned + SIZEOF_STRUCT_MEM)
{
((struct rt_small_mem_item )&small_mem->heap_ptr[mem2->next])->prev = ptr2;
}
small_mem->parent.used += (size + SIZEOF_STRUCT_MEM);
if (small_mem->parent.max < small_mem->parent.used)
small_mem->parent.max = small_mem->parent.used;
}
else
{
/ (a mem2 struct does no fit into the user data space of mem and mem->next will always
be used at this point: if not we have 2 unused structs in a row, plug_holes should have
take care of this).
-> near fit or excact fit: do not split, no mem2 creation
also can't move mem->next directly behind mem, since mem->next
will always be used at this point!
*/
small_mem->parent.used += mem->next - ((rt_uint8_t )mem - small_mem->heap_ptr);
if (small_mem->parent.max < small_mem->parent.used)
small_mem->parent.max = small_mem->parent.used;
}
/ set small memory object /
mem->pool_ptr = MEM_USED();
#ifdef RT_USING_MEMTRACE
if (rt_thread_self())
rt_smem_setname(mem, rt_thread_self()->parent.name);
else
rt_smem_setname(mem, "NONE");
#endif / RT_USING_MEMTRACE /
if (mem == small_mem->lfree)
{
/ Find next free block after mem and update lowest free pointer */
while (MEM_ISUSED(small_mem->lfree) && small_mem->lfree != small_mem->heap_end)
small_mem->lfree = (struct rt_small_mem_item *)&small_mem->heap_ptr[small_mem->lfree->next];
RT_ASSERT(((small_mem->lfree == small_mem->heap_end) || (!MEM_ISUSED(small_mem->lfree))));
}
RT_ASSERT((rt_ubase_t)mem + SIZEOF_STRUCT_MEM + size <= (rt_ubase_t)small_mem->heap_end);
RT_ASSERT((rt_ubase_t)((rt_uint8_t *)mem + SIZEOF_STRUCT_MEM) % RT_ALIGN_SIZE == 0);
RT_ASSERT((((rt_ubase_t)mem) & (RT_ALIGN_SIZE - 1)) == 0);
RT_DEBUG_LOG(RT_DEBUG_MEM,
("allocate memory at 0x%x, size: %dn",
(rt_ubase_t)((rt_uint8_t *)mem + SIZEOF_STRUCT_MEM),
(rt_ubase_t)(mem->next - ((rt_uint8_t )mem - small_mem->heap_ptr))));
/ return the memory data except mem struct */
return (rt_uint8_t *)mem + SIZEOF_STRUCT_MEM;
}
}
return RT_NULL;
}
释放时则是相反的过程,但分配器会查看前后相邻的内存块是否空闲,如果空闲则合并成一个大的空闲内存块。
主要就是把要释放的内存块放入空闲内存块链表
调用plug_holes合并空闲内存块
只会判断前后内存块,保证了效率
void rt_smem_free(void *rmem)
{
struct rt_small_mem_item *mem;
struct rt_small_mem small_mem;
if (rmem == RT_NULL)
return;
RT_ASSERT((((rt_ubase_t)rmem) & (RT_ALIGN_SIZE - 1)) == 0);
/ Get the corresponding struct rt_small_mem_item ... */
mem = (struct rt_small_mem_item *)((rt_uint8_t )rmem - SIZEOF_STRUCT_MEM);
/ ... which has to be in a used state ... */
small_mem = MEM_POOL(mem);
RT_ASSERT(small_mem != RT_NULL);
RT_ASSERT(MEM_ISUSED(mem));
RT_ASSERT(rt_object_get_type(&small_mem->parent.parent) == RT_Object_Class_Memory);
RT_ASSERT(rt_object_is_systemobject(&small_mem->parent.parent));
RT_ASSERT((rt_uint8_t *)rmem >= (rt_uint8_t *)small_mem->heap_ptr &&
(rt_uint8_t *)rmem < (rt_uint8_t *)small_mem->heap_end);
RT_ASSERT(MEM_POOL(&small_mem->heap_ptr[mem->next]) == small_mem);
RT_DEBUG_LOG(RT_DEBUG_MEM,
("release memory 0x%x, size: %dn",
(rt_ubase_t)rmem,
(rt_ubase_t)(mem->next - ((rt_uint8_t )mem - small_mem->heap_ptr))));
/ ... and is now unused. /
mem->pool_ptr = MEM_FREED();
#ifdef RT_USING_MEMTRACE
rt_smem_setname(mem, " ");
#endif / RT_USING_MEMTRACE /
if (mem < small_mem->lfree)
{
/ the newly freed struct is now the lowest */
small_mem->lfree = mem;
}
small_mem->parent.used -= (mem->next - ((rt_uint8_t )mem - small_mem->heap_ptr));
/ finally, see if prev or next are free also */
plug_holes(small_mem, mem);
}
static void plug_holes(struct rt_small_mem *m, struct rt_small_mem_item *mem)
{
struct rt_small_mem_item *nmem;
struct rt_small_mem_item *pmem;
RT_ASSERT((rt_uint8_t *)mem >= m->heap_ptr);
RT_ASSERT((rt_uint8_t *)mem < (rt_uint8_t )m->heap_end);
/ plug hole forward */
nmem = (struct rt_small_mem_item *)&m->heap_ptr[mem->next];
if (mem != nmem && !MEM_ISUSED(nmem) &&
(rt_uint8_t *)nmem != (rt_uint8_t )m->heap_end)
{
/ if mem->next is unused and not end of m->heap_ptr,
combine mem and mem->next
*/
if (m->lfree == nmem)
{
m->lfree = mem;
}
nmem->pool_ptr = 0;
mem->next = nmem->next;
((struct rt_small_mem_item *)&m->heap_ptr[nmem->next])->prev = (rt_uint8_t )mem - m->heap_ptr;
}
/ plug hole backward */
pmem = (struct rt_small_mem_item )&m->heap_ptr[mem->prev];
if (pmem != mem && !MEM_ISUSED(pmem))
{
/ if mem->prev is unused, combine mem and mem->prev */
if (m->lfree == mem)
{
m->lfree = pmem;
}
mem->pool_ptr = 0;
pmem->next = mem->next;
((struct rt_small_mem_item *)&m->heap_ptr[mem->next])->prev = (rt_uint8_t *)pmem - m->heap_ptr;
}
}
slab 管理算法
RT-Thread 的 slab 分配器实现是纯粹的缓冲型的内存池算法。slab 分配器会根据对象的大小分成多个区(zone),也可以看成每类对象有一个内存池,如下图所示:
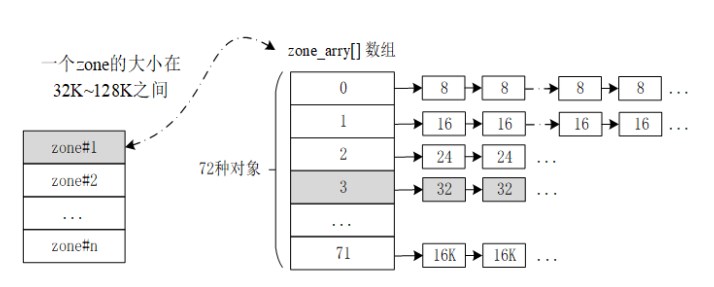
一个 zone 的大小在 32K 到 128K 字节之间,分配器会在堆初始化时根据堆的大小自动调整。系统中的 zone 最多包括 72 种对象,一次最大能够分配 16K 的内存空间,如果超出了 16K 那么直接从页分配器中分配。每个 zone 上分配的内存块大小是固定的,能够分配相同大小内存块的 zone 会链接在一个链表中,而 72 种对象的 zone 链表则放在一个数组(zone_array[])中统一管理。
整个slab由rt_slab进行管理,zone_array存放着所有zone,zone_free存放着空闲的zone。每个zone当中的基本单位又是rt_slab_chunk,作为最低一级内存分配单位。
struct rt_slab
{
struct rt_memory parent; / *< inherit from rt_memory /
rt_ubase_t heap_start; / < memory start address */
rt_ubase_t heap_end; / **< memory end address */
struct rt_slab_memusage *memusage;
struct rt_slab_zone zone_array[RT_SLAB_NZONES]; / linked list of zones NFree > 0 */
struct rt_slab_zone zone_free; / whole zones that have become free /
rt_uint32_t zone_free_cnt;
rt_uint32_t zone_size;
rt_uint32_t zone_limit;
rt_uint32_t zone_page_cnt;
struct rt_slab_page page_list;
};
struct rt_slab_zone
{
rt_uint32_t z_magic; / < magic number for sanity check */
rt_uint32_t z_nfree; / *< total free chunks / ualloc space in zone /
rt_uint32_t z_nmax; / < maximum free chunks */
struct rt_slab_zone *z_next; / **< zoneary[] link if z_nfree non-zero /
rt_uint8_t z_baseptr; / < pointer to start of chunk array */
rt_uint32_t z_uindex; / *< current initial allocation index /
rt_uint32_t z_chunksize; / < chunk size for validation */
rt_uint32_t z_zoneindex; / **< zone index /
struct rt_slab_chunk z_freechunk; / < free chunk list */
};
struct rt_slab_chunk
{
struct rt_slab_chunk *c_next;
};
其中在初始化时会初始化page_list,相当于slab的内存池,每次分配都会从这个内存池当中进行分配。其中关于page的初始化、分配和释放和小内存管理算法是类似的,本质上都是使用数组和计算偏移的方式。具体可见rt_slab_page_init、rt_slab_page_alloc和rt_slab_page_free。
struct rt_slab_page
{
struct rt_slab_page *next; / *< next valid page /
rt_size_t page; / < number of page /
/ dummy */
char dummy[RT_MM_PAGE_SIZE - (sizeof(struct rt_slab_page *) + sizeof(rt_size_t))];
};
slab的初始化操作比较简单,仍然主要是对rt_slab结构进行初始化,以及初始化page_list以及memusage,memusage主要是用来标记page的大小以及类型。
内存分配器当中最主要的就是两种操作:
(1)内存分配
假设分配一个 32 字节的内存,slab 内存分配器会先按照 32 字节的值,从 zone array 链表表头数组中找到相应的 zone 链表。如果这个链表是空的,则向页分配器分配一个新的 zone,然后从 zone 中返回第一个空闲内存块。如果链表非空,则这个 zone 链表中的第一个 zone 节点必然有空闲块存在(否则它就不应该放在这个链表中),那么就取相应的空闲块。如果分配完成后,zone 中所有空闲内存块都使用完毕,那么分配器需要把这个 zone 节点从链表中删除。
总的来说,主要完成以下操作:
首先对于特大内存块(size >= slab->zone_limit)会单独进行处理,不分配进zone
其次就是计算当前size应该放入哪个zone,由zoneindex进行计算
如果这个zone存在
如果zone加上此次操作即会满,则移除出zone_array
如果当前chunk还没达到最大值,则直接分配一个chunk
否则就从freechunk当中进行分配
最后更新内存信息直接返回
如果不存在这个zone
如果存在zone_free,则直接分配出一个
如果不存在zone_free,zone_free本质上是还未使用的zone
分配一个新的page并设置memusage
初始化这个zone,然后分配一个chunk
void *rt_slab_alloc(rt_slab_t m, rt_size_t size)
{
struct rt_slab_zone *z;
rt_int32_t zi;
struct rt_slab_chunk *chunk;
struct rt_slab_memusage *kup;
struct rt_slab *slab = (struct rt_slab )m;
/ zero size, return RT_NULL /
if (size == 0)
return RT_NULL;
/
Handle large allocations directly. There should not be very many of
these so performance is not a big issue.
/
if (size >= slab->zone_limit)
{
size = RT_ALIGN(size, RT_MM_PAGE_SIZE);
chunk = rt_slab_page_alloc(m, size >> RT_MM_PAGE_BITS);
if (chunk == RT_NULL)
return RT_NULL;
/ set kup /
kup = btokup(chunk);
kup->type = PAGE_TYPE_LARGE;
kup->size = size >> RT_MM_PAGE_BITS;
RT_DEBUG_LOG(RT_DEBUG_SLAB,
("alloc a large memory 0x%x, page cnt %d, kup %dn",
size,
size >> RT_MM_PAGE_BITS,
((rt_ubase_t)chunk - slab->heap_start) >> RT_MM_PAGE_BITS));
/ mem stat /
slab->parent.used += size;
if (slab->parent.used > slab->parent.max)
slab->parent.max = slab->parent.used;
return chunk;
}
/
Attempt to allocate out of an existing zone. First try the free list,
then allocate out of unallocated space. If we find a good zone move
it to the head of the list so later allocations find it quickly
(we might have thousands of zones in the list).
Note: zoneindex() will panic of size is too large.
/
zi = zoneindex(&size);
RT_ASSERT(zi < RT_SLAB_NZONES);
RT_DEBUG_LOG(RT_DEBUG_SLAB, ("try to alloc 0x%x on zone: %dn", size, zi));
if ((z = slab->zone_array[zi]) != RT_NULL)
{
RT_ASSERT(z->z_nfree > 0);
/ Remove us from the zone_array[] when we become full /
if (--z->z_nfree == 0)
{
slab->zone_array[zi] = z->z_next;
z->z_next = RT_NULL;
}
/
No chunks are available but nfree said we had some memory, so
it must be available in the never-before-used-memory area
governed by uindex. The consequences are very serious if our zone
got corrupted so we use an explicit rt_kprintf rather then a KASSERT.
*/
if (z->z_uindex + 1 != z->z_nmax)
{
z->z_uindex = z->z_uindex + 1;
chunk = (struct rt_slab_chunk )(z->z_baseptr + z->z_uindex * size);
}
else
{
/ find on free chunk list /
chunk = z->z_freechunk;
/ remove this chunk from list /
z->z_freechunk = z->z_freechunk->c_next;
}
/ mem stats /
slab->parent.used += z->z_chunksize;
if (slab->parent.used > slab->parent.max)
slab->parent.max = slab->parent.used;
return chunk;
}
/
If all zones are exhausted we need to allocate a new zone for this
index.
At least one subsystem, the tty code (see CROUND) expects power-of-2
allocations to be power-of-2 aligned. We maintain compatibility by
adjusting the base offset below.
/
{
rt_uint32_t off;
if ((z = slab->zone_free) != RT_NULL)
{
/ remove zone from free zone list /
slab->zone_free = z->z_next;
-- slab->zone_free_cnt;
}
else
{
/ allocate a zone from page /
z = rt_slab_page_alloc(m, slab->zone_size / RT_MM_PAGE_SIZE);
if (z == RT_NULL)
{
return RT_NULL;
}
RT_DEBUG_LOG(RT_DEBUG_SLAB, ("alloc a new zone: 0x%xn",
(rt_ubase_t)z));
/ set message usage /
for (off = 0, kup = btokup(z); off < slab->zone_page_cnt; off ++)
{
kup->type = PAGE_TYPE_SMALL;
kup->size = off;
kup ++;
}
}
/ clear to zero /
rt_memset(z, 0, sizeof(struct rt_slab_zone));
/ offset of slab zone struct in zone /
off = sizeof(struct rt_slab_zone);
/
Guarentee power-of-2 alignment for power-of-2-sized chunks.
Otherwise just 8-byte align the data.
*/
if ((size | (size - 1)) + 1 == (size << 1))
off = (off + size - 1) & ~(size - 1);
else
off = (off + MIN_CHUNK_MASK) & ~MIN_CHUNK_MASK;
z->z_magic = ZALLOC_SLAB_MAGIC;
z->z_zoneindex = zi;
z->z_nmax = (slab->zone_size - off) / size;
z->z_nfree = z->z_nmax - 1;
z->z_baseptr = (rt_uint8_t *)z + off;
z->z_uindex = 0;
z->z_chunksize = size;
chunk = (struct rt_slab_chunk )(z->z_baseptr + z->z_uindex * size);
/ link to zone array /
z->z_next = slab->zone_array[zi];
slab->zone_array[zi] = z;
/ mem stats */
slab->parent.used += z->z_chunksize;
if (slab->parent.used > slab->parent.max)
slab->parent.max = slab->parent.used;
}
return chunk;
}
RTM_EXPORT(rt_slab_alloc);
(2)内存释放
分配器需要找到内存块所在的 zone 节点,然后把内存块链接到 zone 的空闲内存块链表中。如果此时 zone 的空闲链表指示出 zone 的所有内存块都已经释放,即 zone 是完全空闲的,那么当 zone 链表中全空闲 zone 达到一定数目后,系统就会把这个全空闲的 zone 释放到页面分配器中去。
首先找到当前要释放的内存块的memusage
如果是前面所述的特大内存,那就直接使用rt_slab_page_free释放。
根据memuage计算偏移找到zone和chunk,将chunk放入freechunk中,下次直接使用
如果当前的zone是完全空闲的
移除这个zone,并更新rt_slab的信息
并释放page
void rt_slab_free(rt_slab_t m, void *ptr)
{
struct rt_slab_zone *z;
struct rt_slab_chunk *chunk;
struct rt_slab_memusage *kup;
struct rt_slab *slab = (struct rt_slab )m;
/ free a RT_NULL pointer /
if (ptr == RT_NULL)
return ;
/ get memory usage /
#if RT_DEBUG_SLAB
{
rt_ubase_t addr = ((rt_ubase_t)ptr & ~RT_MM_PAGE_MASK);
RT_DEBUG_LOG(RT_DEBUG_SLAB,
("free a memory 0x%x and align to 0x%x, kup index %dn",
(rt_ubase_t)ptr,
(rt_ubase_t)addr,
((rt_ubase_t)(addr) - slab->heap_start) >> RT_MM_PAGE_BITS));
}
#endif / RT_DEBUG_SLAB /
kup = btokup((rt_ubase_t)ptr & ~RT_MM_PAGE_MASK);
/ release large allocation /
if (kup->type == PAGE_TYPE_LARGE)
{
rt_ubase_t size;
/ clear page counter /
size = kup->size;
kup->size = 0;
/ mem stats /
slab->parent.used -= size * RT_MM_PAGE_SIZE;
RT_DEBUG_LOG(RT_DEBUG_SLAB,
("free large memory block 0x%x, page count %dn",
(rt_ubase_t)ptr, size));
/ free this page /
rt_slab_page_free(m, ptr, size);
return;
}
/ zone case. get out zone. */
z = (struct rt_slab_zone *)(((rt_ubase_t)ptr & ~RT_MM_PAGE_MASK) -
kup->size * RT_MM_PAGE_SIZE);
RT_ASSERT(z->z_magic == ZALLOC_SLAB_MAGIC);
chunk = (struct rt_slab_chunk )ptr;
chunk->c_next = z->z_freechunk;
z->z_freechunk = chunk;
/ mem stats /
slab->parent.used -= z->z_chunksize;
/
- Bump the number of free chunks. If it becomes non-zero the zone
- must be added back onto the appropriate list.
/
if (z->z_nfree++ == 0)
{
z->z_next = slab->zone_array[z->z_zoneindex];
slab->zone_array[z->z_zoneindex] = z;
}
/ - If the zone becomes totally free, and there are other zones we
- can allocate from, move this zone to the FreeZones list. Since
- this code can be called from an IPI callback, do NOT try to mess
- with kernel_map here. Hysteresis will be performed at malloc() time.
*/
if (z->z_nfree == z->z_nmax &&
(z->z_next || slab->zone_array[z->z_zoneindex] != z))
{
struct rt_slab_zone *pz;
RT_DEBUG_LOG(RT_DEBUG_SLAB, ("free zone 0x%xn",
(rt_ubase_t)z, z->z_zoneindex));
/ remove zone from zone array list */
for (pz = &slab->zone_array[z->z_zoneindex]; z != *pz; pz = &(*pz)->z_next)
;
pz = z->z_next;
/ reset zone /
z->z_magic = RT_UINT32_MAX;
/ insert to free zone list /
z->z_next = slab->zone_free;
slab->zone_free = z;
++ slab->zone_free_cnt;
/ release zone to page allocator /
if (slab->zone_free_cnt > ZONE_RELEASE_THRESH)
{
register rt_uint32_t i;
z = slab->zone_free;
slab->zone_free = z->z_next;
-- slab->zone_free_cnt;
/ set message usage /
for (i = 0, kup = btokup(z); i < slab->zone_page_cnt; i ++)
{
kup->type = PAGE_TYPE_FREE;
kup->size = 0;
kup ++;
}
/ release pages */
rt_slab_page_free(m, z, slab->zone_size / RT_MM_PAGE_SIZE);
return;
}
}
}
memheap 管理算法
memheap管理算法适用于系统含有多个地址可不连续的内存堆。使用memheap内存管理可以简化系统存在多个内存堆时的使用:当系统中存在多个内存堆的时候,用户只需要在系统初始化时将多个所需的memheap初始化,并开启memheap功能就可以很方便地把多个memheap(地址可不连续)粘合起来用于系统的 heap 分配。
首先,RT-Thread的实现用rt_memheap来表示一个memheap,使用rt_memheap_item来表示堆中的一个节点或者说一个内存块。
除了包含基本信息外,rt_memheap当中主要包含着一个链接所有内存块的block_list和链接所有空闲内存块的free_list,而rt_memheap_item也主要围绕这两个结构,主要是指向前后两个块和前后两个空闲块。此外,rt_memheap还有用来处理并发的信号量。
struct rt_memheap_item
{
rt_uint32_t magic; / **< magic number for memheap /
struct rt_memheap pool_ptr; / < point of pool */
struct rt_memheap_item *next; / **< next memheap item /
struct rt_memheap_item prev; / < prev memheap item */
struct rt_memheap_item next_free; / < next free memheap item /
struct rt_memheap_item prev_free; / < prev free memheap item */
#ifdef RT_USING_MEMTRACE
rt_uint8_t owner_thread_name[4]; /< owner thread name /
#endif / RT_USING_MEMTRACE /
};
/
Base structure of memory heap object
*/
struct rt_memheap
{
struct rt_object parent; / **< inherit from rt_object /
void start_addr; / < pool start address and size */
rt_size_t pool_size; / *< pool size /
rt_size_t available_size; / < available size */
rt_size_t max_used_size; / **< maximum allocated size /
struct rt_memheap_item block_list; / < used block list */
struct rt_memheap_item *free_list; / *< free block list /
struct rt_memheap_item free_header; / < free block list header */
struct rt_semaphore lock; / *< semaphore lock /
rt_bool_t locked; / < External lock mark */
};
memheap 工作机制如下图所示,首先将多块内存加入 memheap_item 链表进行粘合。当分配内存块时,会先从默认内存堆去分配内存,当分配不到时会查找 memheap_item 链表,尝试从其他的内存堆上分配内存块。应用程序不用关心当前分配的内存块位于哪个内存堆上,就像是在操作一个内存堆。
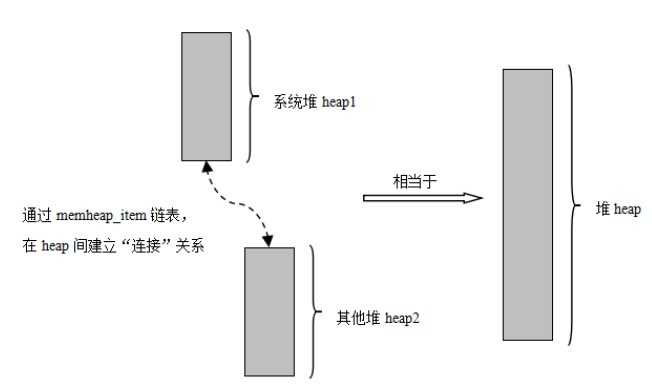
这在RT-Thread真正的实现当中,主要是依靠内核对象完成的。首先heap参数是由上层封装的另一个接口传入的系统heap(在后面会讲解),所以实现多内存堆主要依靠遍历内核对象(memheap在初始化会加入内存对象链表)获取每一个内存堆并尝试内存分配。
具体可见src/memheap.c的_memheap_alloc函数
对于memheap的初始化和前两个管理算法是类似的,都比较简单,主要是对rt_memheap的初始化和block_list和free_list的初始化,以及对内核对象的操作。
其中主要的同样还是内存的分配以及释放。
内存分配的主要操作是:
如果当前整个memheap的可用内存都不够大,则直接返回RT_NULL交由上层处理
首先先遍历free_list找到合适大小的内存块
如果这个内存块的大小超过了一个item结构+要求分配的内存大小+最小可分配的内存块大小
那么就切割这个内存块,主要就是对prev和next指针的链表操作。在free_list中删除新分配的内存块,并加入切割出来的内存块
并且会更新当前堆的信息
如果内存块大小不足的话,只会在free_list中删除新分配的内存块
void *rt_memheap_alloc(struct rt_memheap *heap, rt_size_t size)
{
rt_err_t result;
rt_size_t free_size;
struct rt_memheap_item header_ptr;
RT_ASSERT(heap != RT_NULL);
RT_ASSERT(rt_object_get_type(&heap->parent) == RT_Object_Class_MemHeap);
/ align allocated size */
size = RT_ALIGN(size, RT_ALIGN_SIZE);
if (size < RT_MEMHEAP_MINIALLOC)
size = RT_MEMHEAP_MINIALLOC;
RT_DEBUG_LOG(RT_DEBUG_MEMHEAP, ("allocate %d on heap:%8.s",
size, RT_NAME_MAX, heap->parent.name));
if (size < heap->available_size)
{
/ search on free list /
free_size = 0;
/ lock memheap /
if (heap->locked == RT_FALSE)
{
result = rt_sem_take(&(heap->lock), RT_WAITING_FOREVER);
if (result != RT_EOK)
{
rt_set_errno(result);
return RT_NULL;
}
}
/ get the first free memory block /
header_ptr = heap->free_list->next_free;
while (header_ptr != heap->free_list && free_size < size)
{
/ get current freed memory block size /
free_size = MEMITEM_SIZE(header_ptr);
if (free_size < size)
{
/ move to next free memory block /
header_ptr = header_ptr->next_free;
}
}
/ determine if the memory is available. /
if (free_size >= size)
{
/ a block that satisfies the request has been found. /
/ determine if the block needs to be split. */
if (free_size >= (size + RT_MEMHEAP_SIZE + RT_MEMHEAP_MINIALLOC))
{
struct rt_memheap_item new_ptr;
/ split the block. */
new_ptr = (struct rt_memheap_item *)
(((rt_uint8_t )header_ptr) + size + RT_MEMHEAP_SIZE);
RT_DEBUG_LOG(RT_DEBUG_MEMHEAP,
("split: block[0x%08x] nextm[0x%08x] prevm[0x%08x] to new[0x%08x]n",
header_ptr,
header_ptr->next,
header_ptr->prev,
new_ptr));
/ mark the new block as a memory block and freed. /
new_ptr->magic = (RT_MEMHEAP_MAGIC | RT_MEMHEAP_FREED);
/ put the pool pointer into the new block. /
new_ptr->pool_ptr = heap;
#ifdef RT_USING_MEMTRACE
rt_memset(new_ptr->owner_thread_name, ' ', sizeof(new_ptr->owner_thread_name));
#endif / RT_USING_MEMTRACE /
/ break down the block list /
new_ptr->prev = header_ptr;
new_ptr->next = header_ptr->next;
header_ptr->next->prev = new_ptr;
header_ptr->next = new_ptr;
/ remove header ptr from free list /
header_ptr->next_free->prev_free = header_ptr->prev_free;
header_ptr->prev_free->next_free = header_ptr->next_free;
header_ptr->next_free = RT_NULL;
header_ptr->prev_free = RT_NULL;
/ insert new_ptr to free list /
new_ptr->next_free = heap->free_list->next_free;
new_ptr->prev_free = heap->free_list;
heap->free_list->next_free->prev_free = new_ptr;
heap->free_list->next_free = new_ptr;
RT_DEBUG_LOG(RT_DEBUG_MEMHEAP, ("new ptr: next_free 0x%08x, prev_free 0x%08xn",
new_ptr->next_free,
new_ptr->prev_free));
/ decrement the available byte count. /
heap->available_size = heap->available_size -
size -
RT_MEMHEAP_SIZE;
if (heap->pool_size - heap->available_size > heap->max_used_size)
heap->max_used_size = heap->pool_size - heap->available_size;
}
else
{
/ decrement the entire free size from the available bytes count. /
heap->available_size = heap->available_size - free_size;
if (heap->pool_size - heap->available_size > heap->max_used_size)
heap->max_used_size = heap->pool_size - heap->available_size;
/ remove header_ptr from free list /
RT_DEBUG_LOG(RT_DEBUG_MEMHEAP,
("one block: block[0x%08x], next_free 0x%08x, prev_free 0x%08xn",
header_ptr,
header_ptr->next_free,
header_ptr->prev_free));
header_ptr->next_free->prev_free = header_ptr->prev_free;
header_ptr->prev_free->next_free = header_ptr->next_free;
header_ptr->next_free = RT_NULL;
header_ptr->prev_free = RT_NULL;
}
/ Mark the allocated block as not available. /
header_ptr->magic = (RT_MEMHEAP_MAGIC | RT_MEMHEAP_USED);
#ifdef RT_USING_MEMTRACE
if (rt_thread_self())
rt_memcpy(header_ptr->owner_thread_name, rt_thread_self()->parent.name, sizeof(header_ptr->owner_thread_name));
else
rt_memcpy(header_ptr->owner_thread_name, "NONE", sizeof(header_ptr->owner_thread_name));
#endif / RT_USING_MEMTRACE /
if (heap->locked == RT_FALSE)
{
/ release lock /
rt_sem_release(&(heap->lock));
}
/ Return a memory address to the caller. */
RT_DEBUG_LOG(RT_DEBUG_MEMHEAP,
("alloc mem: memory[0x%08x], heap[0x%08x], size: %dn",
(void *)((rt_uint8_t *)header_ptr + RT_MEMHEAP_SIZE),
header_ptr,
size));
return (void *)((rt_uint8_t )header_ptr + RT_MEMHEAP_SIZE);
}
if (heap->locked == RT_FALSE)
{
/ release lock /
rt_sem_release(&(heap->lock));
}
}
RT_DEBUG_LOG(RT_DEBUG_MEMHEAP, ("allocate memory: failedn"));
/ Return the completion status. */
return RT_NULL;
}
对于内存释放来说,主要操作如下:
首先会检查内存块的magic number,然后更新堆的信息
然后会判断前后两块内存块是否能够合并
如果能够合并则更新链表和内存块信息
如果没有和前一内存块进行合并,则需要重新放入free_list
遍历free_list,按照大小排序放入链表
void rt_memheap_free(void *ptr)
{
rt_err_t result;
struct rt_memheap *heap;
struct rt_memheap_item *header_ptr, new_ptr;
rt_bool_t insert_header;
/ NULL check /
if (ptr == RT_NULL) return;
/ set initial status as OK */
insert_header = RT_TRUE;
new_ptr = RT_NULL;
header_ptr = (struct rt_memheap_item *)
((rt_uint8_t )ptr - RT_MEMHEAP_SIZE);
RT_DEBUG_LOG(RT_DEBUG_MEMHEAP, ("free memory: memory[0x%08x], block[0x%08x]n",
ptr, header_ptr));
/ check magic /
if (header_ptr->magic != (RT_MEMHEAP_MAGIC | RT_MEMHEAP_USED) ||
(header_ptr->next->magic & RT_MEMHEAP_MASK) != RT_MEMHEAP_MAGIC)
{
RT_DEBUG_LOG(RT_DEBUG_MEMHEAP, ("bad magic:0x%08x @ memheapn",
header_ptr->magic));
RT_ASSERT(header_ptr->magic == (RT_MEMHEAP_MAGIC | RT_MEMHEAP_USED));
/ check whether this block of memory has been over-written. /
RT_ASSERT((header_ptr->next->magic & RT_MEMHEAP_MASK) == RT_MEMHEAP_MAGIC);
}
/ get pool ptr /
heap = header_ptr->pool_ptr;
RT_ASSERT(heap);
RT_ASSERT(rt_object_get_type(&heap->parent) == RT_Object_Class_MemHeap);
if (heap->locked == RT_FALSE)
{
/ lock memheap /
result = rt_sem_take(&(heap->lock), RT_WAITING_FOREVER);
if (result != RT_EOK)
{
rt_set_errno(result);
return ;
}
}
/ Mark the memory as available. /
header_ptr->magic = (RT_MEMHEAP_MAGIC | RT_MEMHEAP_FREED);
/ Adjust the available number of bytes. /
heap->available_size += MEMITEM_SIZE(header_ptr);
/ Determine if the block can be merged with the previous neighbor. /
if (!RT_MEMHEAP_IS_USED(header_ptr->prev))
{
RT_DEBUG_LOG(RT_DEBUG_MEMHEAP, ("merge: left node 0x%08xn",
header_ptr->prev));
/ adjust the available number of bytes. /
heap->available_size += RT_MEMHEAP_SIZE;
/ yes, merge block with previous neighbor. /
(header_ptr->prev)->next = header_ptr->next;
(header_ptr->next)->prev = header_ptr->prev;
/ move header pointer to previous. /
header_ptr = header_ptr->prev;
/ don't insert header to free list /
insert_header = RT_FALSE;
}
/ determine if the block can be merged with the next neighbor. /
if (!RT_MEMHEAP_IS_USED(header_ptr->next))
{
/ adjust the available number of bytes. /
heap->available_size += RT_MEMHEAP_SIZE;
/ merge block with next neighbor. /
new_ptr = header_ptr->next;
RT_DEBUG_LOG(RT_DEBUG_MEMHEAP,
("merge: right node 0x%08x, next_free 0x%08x, prev_free 0x%08xn",
new_ptr, new_ptr->next_free, new_ptr->prev_free));
new_ptr->next->prev = header_ptr;
header_ptr->next = new_ptr->next;
/ remove new ptr from free list */
new_ptr->next_free->prev_free = new_ptr->prev_free;
new_ptr->prev_free->next_free = new_ptr->next_free;
}
if (insert_header)
{
struct rt_memheap_item n = heap->free_list->next_free;;
#if defined(RT_MEMHEAP_BEST_MODE)
rt_size_t blk_size = MEMITEM_SIZE(header_ptr);
for (;n != heap->free_list; n = n->next_free)
{
rt_size_t m = MEMITEM_SIZE(n);
if (blk_size <= m)
{
break;
}
}
#endif
/ no left merge, insert to free list /
header_ptr->next_free = n;
header_ptr->prev_free = n->prev_free;
n->prev_free->next_free = header_ptr;
n->prev_free = header_ptr;
RT_DEBUG_LOG(RT_DEBUG_MEMHEAP,
("insert to free list: next_free 0x%08x, prev_free 0x%08xn",
header_ptr->next_free, header_ptr->prev_free));
}
#ifdef RT_USING_MEMTRACE
rt_memset(header_ptr->owner_thread_name, ' ', sizeof(header_ptr->owner_thread_name));
#endif / RT_USING_MEMTRACE /
if (heap->locked == RT_FALSE)
{
/ release lock */
rt_sem_release(&(heap->lock));
}
}
上层抽象
因为RT-Thread支持多种内存管理算法,所以必须有一个统一的上层抽象,其中主要由rtconfig.h以及中的宏来控制使用哪种算法
#define RT_PAGE_MAX_ORDER 11
#define RT_USING_MEMPOOL
#define RT_USING_SMALL_MEM
#define RT_USING_MEMHEAP
#define RT_MEMHEAP_FAST_MODE
#define RT_USING_SMALL_MEM_AS_HEAP
#define RT_USING_MEMTRACE
#define RT_USING_HEAP
最后在src/kservice.c当中将接口进行统一抽象,也就是统一为rt_malloc、rt_free和re_realloc等等
#define _MEM_INIT(_name, _start, _size)
system_heap = rt_smem_init(_name, _start, _size)
#define _MEM_MALLOC(_size)
rt_smem_alloc(system_heap, _size)
#define _MEM_REALLOC(_ptr, _newsize)
rt_smem_realloc(system_heap, _ptr, _newsize)
#define _MEM_FREE(_ptr)
rt_smem_free(_ptr)
#define _MEM_INFO(_total, _used, _max)
_smem_info(_total, _used, _max)
#elif defined(RT_USING_MEMHEAP_AS_HEAP)
static struct rt_memheap system_heap;
void *_memheap_alloc(struct rt_memheap *heap, rt_size_t size);
void _memheap_free(void *rmem);
void *_memheap_realloc(struct rt_memheap *heap, void *rmem, rt_size_t newsize);
#define _MEM_INIT(_name, _start, _size)
rt_memheap_init(&system_heap, _name, _start, _size)
#define _MEM_MALLOC(_size)
_memheap_alloc(&system_heap, _size)
#define _MEM_REALLOC(_ptr, _newsize)
_memheap_realloc(&system_heap, _ptr, _newsize)
#define _MEM_FREE(_ptr)
_memheap_free(_ptr)
#define _MEM_INFO(_total, _used, _max)
rt_memheap_info(&system_heap, _total, _used, _max)
#elif defined(RT_USING_SLAB_AS_HEAP)
static rt_slab_t system_heap;
rt_inline void _slab_info(rt_size_t *total,
rt_size_t *used, rt_size_t *max_used)
{
if (total)
*total = system_heap->total;
if (used)
*used = system_heap->used;
if (max_used)
*max_used = system_heap->max;
}
#define _MEM_INIT(_name, _start, _size)
system_heap = rt_slab_init(_name, _start, _size)
#define _MEM_MALLOC(_size)
rt_slab_alloc(system_heap, _size)
#define _MEM_REALLOC(_ptr, _newsize)
rt_slab_realloc(system_heap, _ptr, _newsize)
#define _MEM_FREE(_ptr)
rt_slab_free(system_heap, _ptr)
#define _MEM_INFO _slab_info
#else
#define _MEM_INIT(...)
#define _MEM_MALLOC(...) RT_NULL
#define _MEM_REALLOC(...) RT_NULL
#define _MEM_FREE(...)
#define _MEM_INFO(...)
#endif
rt_weak void *rt_malloc(rt_size_t size)
{
rt_base_t level;
void ptr;
/ Enter critical zone /
level = _heap_lock();
/ allocate memory block from system heap /
ptr = _MEM_MALLOC(size);
/ Exit critical zone /
_heap_unlock(level);
/ call 'rt_malloc' hook */
RT_OBJECT_HOOK_CALL(rt_malloc_hook, (ptr, size));
return ptr;
}
RTM_EXPORT(rt_malloc);
-
RT-Thread文档_线程管理2023-02-22 800
-
RT-Thread内存管理之内存池实现分析2022-10-17 2618
-
请问rt-thread的小内存管理算法能保证实时性吗?2022-09-09 1818
-
【RT-Thread学习笔记】用memwatch排除内存泄露2022-07-30 4193
-
RT-Thread记录(十一、UART设备—源码解析)2022-07-01 7471
-
RT-Thread记录(八、理解RT-Thread内存管理)2022-06-23 4027
-
关于RT-Thread的动态内存堆管理简析2022-04-06 4393
-
RT-Thread系统动态内存堆有哪几种管理算法呢2022-03-31 2923
-
关于RT-Thread内存、时钟与中断管理的学习总结2022-03-18 5440
-
灵动微课堂 (第134讲) | 基于MM32 MCU的OS移植与应用——RT-Thread 内存管理2020-08-28 2656
全部0条评论

快来发表一下你的评论吧 !
